机器学习(二):基于XGBoost的分类与预测
XGBoost介绍
xgboost的安装、参数说明
XGBoost是2016年由华盛顿大学陈天奇老师带领开发的一个可扩展机器学习系统。严格意义上讲XGBoost并不是一种模型,而是一个可供用户轻松解决分类、回归或排序问题的软件包。它内部实现了梯度提升树(GBDT)模型,并对模型中的算法进行了诸多优化,在取得高精度的同时又保持了极快的速度,在一段时间内成为了国内外数据挖掘、机器学习领域中的大规模杀伤性武器。
更重要的是,XGBoost在系统优化和机器学习原理方面都进行了深入的考虑。毫不夸张的讲,XGBoost提供的可扩展性,可移植性与准确性推动了机器学习计算限制的上限,该系统在单台机器上运行速度比当时流行解决方案快十倍以上,甚至在分布式系统中可以处理十亿级的数据。
其主要优点:
- 简单易用。相对其他机器学习库,用户可以轻松使用XGBoost并获得相当不错的效果。
- 高效可扩展。在处理大规模数据集时速度快效果好,对内存等硬件资源要求不高。
- 鲁棒性强。相对于深度学习模型不需要精细调参便能取得接近的效果。
- XGBoost内部实现提升树模型,可以自动处理缺失值。
主要缺点:
- 相对于深度学习模型无法对时空位置建模,不能很好地捕获图像、语音、文本等高维数据。
- 在拥有海量训练数据,并能找到合适的深度学习模型时,深度学习的精度可以遥遥领先XGBoost。
XGBoost的重要参数
xgboost函数的主要调参参数
重要参数:
- num_round(最大迭代次数,没有默认值,必须要自己设定)
- seed(随机数种子,默认值为0)
- objective(任务目标,默认值为reg:linear)具体取值可查看help文档
- 二分类可设置为“binary:logistic”,其子模型为树,只是最后会将case的权重做Logistic变换以获得预测概率值
- 多分类可设置为“multi:softmax”,处理方式与二分类相同,只是用了softmax函数将权重转换为概率
- 回归可采用“reg:linear”
- max_depth(树的最大深度,默认值为6):越大则树模型越复杂、越容易过拟合
- min_child_weight(叶节点中所有观测权重和的阈值,默认值为1):小于该阈值时,树就不会再分裂;越大则模型越保守(不易过拟合)
- colsample_bytree(变量抽样比例,默认值为1):越大则计算越耗时、树模型精度越高(但也可能导致过拟合)
次重要参数:
- eta(学习率,默认值为0.3):为了防止过拟合,更新过程中用到的收缩步长。在每次提升计算之后,算法会直接获得新特征的权重, eta通过缩减特征的权重使提升计算过程更加保守。eta越大则模型越容易过拟合
- gamma(划分叶节点的损失变化量阈值,默认值为0) :越大则模型越保守
- lambda(L2正则项系数,默认值为1):越大则模型越保守
- alpha(L1正则项系数,默认值为0):越大则模型越保守
- scale_pos_weight(处理类别不平衡的参数,默认值为1)
- subsample(观测值的抽样比例,默认值为1):越大则模型越容易过拟合
若在scikit-learn框架下实现XGBoost时的重要参数
1.eta[默认0.3]
通过为每一颗树增加权重,提高模型的鲁棒性。
典型值为0.01-0.2。
2.min_child_weight[默认1]
决定最小叶子节点样本权重和。
这个参数可以避免过拟合。当它的值较大时,可以避免模型学习到局部的特殊样本。
但是如果这个值过高,则会导致模型拟合不充分。
3.max_depth[默认6]
这个值也是用来避免过拟合的。max_depth越大,模型会学到更具体更局部的样本。
典型值:3-10
4.max_leaf_nodes
树上最大的节点或叶子的数量。
可以替代max_depth的作用。
这个参数的定义会导致忽略max_depth参数。
5.gamma[默认0]
在节点分裂时,只有分裂后损失函数的值下降了,才会分裂这个节点。Gamma指定了节点分裂所需的最小损失函数下降值。 这个参数的值越大,算法越保守。这个参数的值和损失函数息息相关。
6.max_delta_step[默认0]
这参数限制每棵树权重改变的最大步长。如果这个参数的值为0,那就意味着没有约束。如果它被赋予了某个正值,那么它会让这个算法更加保守。
但是当各类别的样本十分不平衡时,它对分类问题是很有帮助的。
7.subsample[默认1]
这个参数控制对于每棵树,随机采样的比例。
减小这个参数的值,算法会更加保守,避免过拟合。但是,如果这个值设置得过小,它可能会导致欠拟合。
典型值:0.5-1
8.colsample_bytree[默认1]
用来控制每棵随机采样的列数的占比(每一列是一个特征)。
典型值:0.5-1
9.colsample_bylevel[默认1]
用来控制树的每一级的每一次分裂,对列数的采样的占比。
subsample参数和colsample_bytree参数可以起到相同的作用,一般用不到。
10.lambda[默认1]
权重的L2正则化项。(和Ridge regression类似)。
这个参数是用来控制XGBoost的正则化部分的。虽然大部分数据科学家很少用到这个参数,但是这个参数在减少过拟合上还是可以挖掘出更多用处的。
11.alpha[默认1]
权重的L1正则化项。(和Lasso regression类似)。
可以应用在很高维度的情况下,使得算法的速度更快。
12.scale_pos_weight[默认1]
在各类别样本十分不平衡时,把这个参数设定为一个正值,可以使算法更快收敛。
ps:必须处理定性变量!进行独热编码。不必处理缺失值。
算法实战
参考链接
基于天气数据集的XGBoost分类实战
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
data = pd.read_csv('train.csv')
数据的各个特征描述如下:
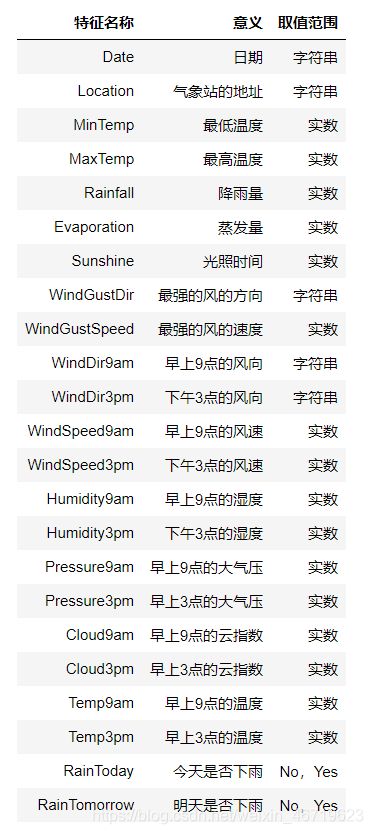
## 进行简单的数据查看,我们可以利用 .head() 头部.tail()尾部
data.head()
data = data.fillna(-1)#发现有缺失值,对缺失值用-1填充
## 利用value_counts函数查看训练集标签的数量
pd.Series(data['RainTomorrow']).value_counts()##发现数据不平衡
简单可视化
## 选取三个特征与标签组合的散点可视化
sns.pairplot(data=data[['Rainfall',
'Evaporation',
'Sunshine'] + ['RainTomorrow']], diag_kind='hist', hue= 'RainTomorrow')
plt.show()
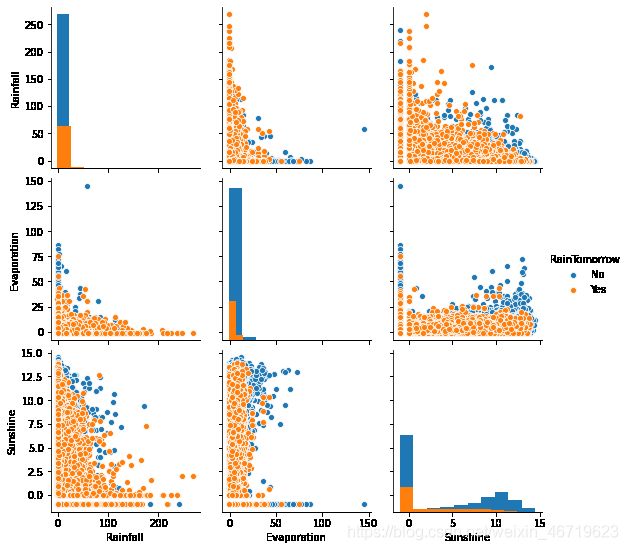
从上图可以发现,在2D情况下不同的特征组合对于第二天下雨与不下雨的散点分布,以及大概的区分能力。相对的Sunshine与其他特征的组合更具有区分能力
for col in data[numerical_features].columns:
if col != 'RainTomorrow':
sns.boxplot(x='RainTomorrow', y=col, saturation=0.5, palette='pastel', data=data)
plt.title(col)
plt.show()
利用箱型图我们也可以得到不同类别在不同特征上的分布差异情况。我们可以发现Sunshine,Humidity3pm,Cloud9am,Cloud3pm的区分能力较强。
tlog = {}
for i in category_features:
tlog[i] = data[data['RainTomorrow'] == 'Yes'][i].value_counts()
flog = {}
for i in category_features:
flog[i] = data[data['RainTomorrow'] == 'No'][i].value_counts()
plt.figure(figsize=(10,10))
plt.subplot(1,2,1)
plt.title('RainTomorrow')
sns.barplot(x = pd.DataFrame(tlog['Location']).sort_index()['Location'], y = pd.DataFrame(tlog['Location']).sort_index().index, color = "red")
plt.subplot(1,2,2)
plt.title('Not RainTomorrow')
sns.barplot(x = pd.DataFrame(flog['Location']).sort_index()['Location'], y = pd.DataFrame(flog['Location']).sort_index().index, color = "blue")
plt.show()

从上图可以发现不同地区降雨情况差别很大,有些地方明显更容易降雨。
plt.figure(figsize=(10,2))
plt.subplot(1,2,1)
plt.title('RainTomorrow')
sns.barplot(x = pd.DataFrame(tlog['RainToday'][:2]).sort_index()['RainToday'], y = pd.DataFrame(tlog['RainToday'][:2]).sort_index().index, color = "red")
plt.subplot(1,2,2)
plt.title('Not RainTomorrow')
sns.barplot(x = pd.DataFrame(flog['RainToday'][:2]).sort_index()['RainToday'], y = pd.DataFrame(flog['RainToday'][:2]).sort_index().index, color = "blue")
plt.show()

# 把所有的相同类别的特征编码为同一个值
def get_mapfunction(x):
mapp = dict(zip(x.unique().tolist(),
range(len(x.unique().tolist()))))
def mapfunction(y):
if y in mapp:
return mapp[y]
else:
return -1
return mapfunction
for i in category_features:
data[i] = data[i].apply(get_mapfunction(data[i]))
进行训练与预测
# 为了正确评估模型性能,将数据划分为训练集和测试集,并在训练集上训练模型,在测试集上验证模型性能。
from sklearn.model_selection import train_test_split
## 选择其类别为0和1的样本 (不包括类别为2的样本)
data_target_part = data['RainTomorrow']
data_features_part = data[[x for x in data.columns if x != 'RainTomorrow']]
## 测试集大小为20%, 80%/20%分
x_train, x_test, y_train, y_test = train_test_split(data_features_part, data_target_part, test_size = 0.2, random_state = 2020)
from xgboost.sklearn import XGBClassifier
## 定义 XGBoost模型
clf = XGBClassifier()
# 在训练集上训练XGBoost模型
clf.fit(x_train, y_train)
# 在训练集和测试集上分布利用训练好的模型进行预测
train_predict = clf.predict(x_train)
test_predict = clf.predict(x_test)
from sklearn import metrics
## 利用accuracy(准确度)【预测正确的样本数目占总预测样本数目的比例】评估模型效果
print('The accuracy of the Logistic Regression is:',metrics.accuracy_score(y_train,train_predict))
print('The accuracy of the Logistic Regression is:',metrics.accuracy_score(y_test,test_predict))
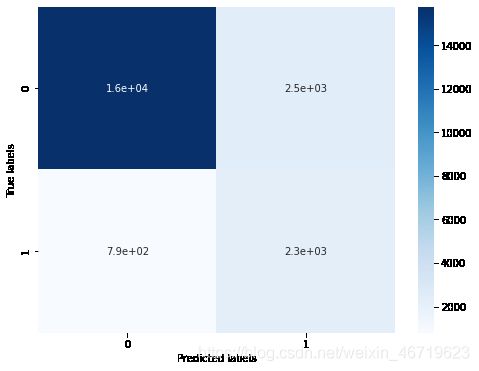
## 查看混淆矩阵 (预测值和真实值的各类情况统计矩阵)
confusion_matrix_result = metrics.confusion_matrix(test_predict,y_test)
print('The confusion matrix result:\n',confusion_matrix_result)
# 利用热力图对于结果进行可视化
plt.figure(figsize=(8, 6))
sns.heatmap(confusion_matrix_result, annot=True, cmap='Blues')
plt.xlabel('Predicted labels')
plt.ylabel('True labels')
plt.show()
利用XGBoost进行特征选择
sns.barplot(y=data_features_part.columns, x=clf.feature_importances_)
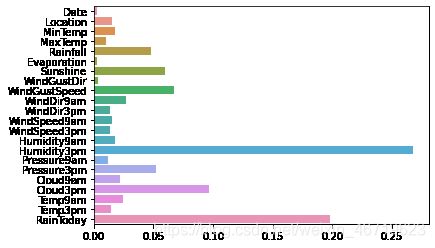
从图中我们可以发现下午3点的湿度与今天是否下雨是决定第二天是否下雨最重要的因素。
除此之外,我们还可以使用XGBoost中的下列重要属性来评估特征的重要性。
- weight:是以特征用到的次数来评价
- gain:当利用特征做划分的时候的评价基尼指数
- cover:利用一个覆盖样本的指标二阶导数(具体原理不清楚有待探究)平均值来划分。
- total_gain:总基尼指数
- total_cover:总覆盖
from sklearn.metrics import accuracy_score
from xgboost import plot_importance
def estimate(model,data):
#sns.barplot(data.columns,model.feature_importances_)
ax1=plot_importance(model,importance_type="gain")
ax1.set_title('gain')
ax2=plot_importance(model, importance_type="weight")
ax2.set_title('weight')
ax3 = plot_importance(model, importance_type="cover")
ax3.set_title('cover')
plt.show()
def classes(data,label,test):
model=XGBClassifier()
model.fit(data,label)
ans=model.predict(test)
estimate(model, data)
return ans
ans=classes(x_train,y_train,x_test)
pre=accuracy_score(y_test, ans)
print('acc=',accuracy_score(y_test,ans))


调参
# 从sklearn库中导入网格调参函数
from sklearn.model_selection import GridSearchCV
## 定义参数取值范围
learning_rate = [0.1, 0.3, 0.6]
subsample = [0.8, 0.9]
colsample_bytree = [0.6, 0.8]
max_depth = [3,5,8]
parameters = { 'learning_rate': learning_rate,
'subsample': subsample,
'colsample_bytree':colsample_bytree,
'max_depth': max_depth}
model = XGBClassifier(n_estimators = 50)
## 进行网格搜索
clf = GridSearchCV(model, parameters, cv=3, scoring='accuracy',verbose=1,n_jobs=-1)
clf = clf.fit(x_train, y_train)
clf.best_params_##网格搜索后的最优参数
# 在训练集和测试集上分布利用最好的模型参数进行预测
## 定义带参数的 XGBoost模型
clf = XGBClassifier(colsample_bytree = 0.6, learning_rate = 0.3, max_depth= 8, subsample = 0.9)
# 在训练集上训练XGBoost模型
clf.fit(x_train, y_train)
train_predict = clf.predict(x_train)
test_predict = clf.predict(x_test)
## 利用accuracy(准确度)【预测正确的样本数目占总预测样本数目的比例】评估模型效果
print('The accuracy of the Logistic Regression is:',metrics.accuracy_score(y_train,train_predict))
print('The accuracy of the Logistic Regression is:',metrics.accuracy_score(y_test,test_predict))
## 查看混淆矩阵 (预测值和真实值的各类情况统计矩阵)
confusion_matrix_result = metrics.confusion_matrix(test_predict,y_test)
print('The confusion matrix result:\n',confusion_matrix_result)
# 利用热力图对于结果进行可视化
plt.figure(figsize=(8, 6))
sns.heatmap(confusion_matrix_result, annot=True, cmap='Blues')
plt.xlabel('Predicted labels')
plt.ylabel('True labels')
plt.show()

原本有2470 + 790个错误,现在有 2112 + 939个错误,带来了明显的正确率提升。但是该调参只是简单的尝试,从结果来看错误率仍然比较高,因此可以考虑扩大调参范围或者进行特征工程来增加变量以提高模型的预测效果。