Python数据分析—numpy操作本地数据及合并多个表格
numpy操作本地数据及合并多个表格
- 一、写入本地数据
- 二、读取本地数据
- 三、合并两个表格
- 四、合并多个表格
- 五、小练习
-
- 练习1
- 练习2
- 练习3
一、写入本地数据
np.savetxt(fname)
| 参数 | 意思 |
|---|---|
| fname | 文件路径 |
| delimiter | 分隔符 |
| fmt | 写入文件的格式,例如:%d,%.2f,%.18e |
| converters | 对数据预处理。{0:func}第0列进行func函数预处理 |
| header | 指定为表头 |
scores = np.random.randint(0,100,size=(40,2))
np.savetxt("scores.csv",scores,delimiter=",",fmt="%d",header="期中,期末",comments="")
# 如果直接加header默认会有#,添加comments指定为空字符串
二、读取本地数据
np.loadtxt(fname)
| 参数 | 意思 |
|---|---|
| fname | 文件路径 |
| dtype | 数据类型 |
| delimiter | 分隔符 |
| skiprows | 跳过行 |
| comment | 如果行的开头为 # 就会跳过该行 |
| usecols | 是指使用(0,2)两列 |
| unpack | 每一列当成一个向量输出,而不是合并在一起 |
| converters | 对数据预处理。{0:func}第0列进行func函数预处理 |
np.loadtxt("scores.csv",delimiter=",",dtype="object",skiprows=1)
三、合并两个表格
yao=np.loadtxt('D:\云南白药.csv',delimiter=',',dtype='object')
ye=np.loadtxt('D:\五粮液.csv',delimiter=',',dtype='object',skiprows=1)
print(yao.shape) # (156, 11)
print(ye.shape) # (155, 11)
垂直拼接
v_lian=np.vstack((yao,ye))
print(v_lian.shape) # (311, 11)
np.savetxt("v_lian.csv",v_lian,delimiter=",",fmt="%s")
注:
垂直拼接:np.vstack(()) 表格的列数需相同
水平拼接:np.hstack(()) 表格的行数需相同
四、合并多个表格

1、随机生成10行6列 0-100的整数写入十个表格,表头一致
import os
import numpy
for i in range(10):
score=np.random.randint(0,100,size=(10,6))
np.savetxt(f'D:\scores\score{i}.csv',score,delimiter=',',fmt='%d',header='语文,数学,英语,化学,生物,地理',comments='')
2、定义一个函数来实现
def biao(list):
# 单独取出第一个表格,保留表头
f0=np.loadtxt('D:\scores\score0.csv',delimiter=',',dtype='object')
# 遍历列表,如果是第一个表格则跳过,剩余表格去掉表头
for ff in list:
if ff=='score0.csv':
continue
else:
f1=np.loadtxt(f'D:\scores\{ff}',delimiter=',',dtype='object',skiprows=1)
# 垂直堆叠
f0=np.vstack((f0,f1))
print(f0.shape) # (101, 6)
#堆叠的数据写入文件
np.savetxt(f'D:\scores\score_total.csv',f0,delimiter=',',fmt='%s')
# 使用OS模块读取文件名称
list=os.listdir('D:\scores')
biao(list)
五、小练习

练习1
导入相关的库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
1、首先导入英国Youtube数据,因数据没有比表头,我们手动添加每列的表头
GB=pd.read_csv(r'D:\GB_video_data_numbers.csv',names=['点击','喜欢','不喜欢','评论'])
查看评论数据的最大小值,以确定数据分组范围
print(GB['评论'].max()) # 582505
print(GB['评论'].min()) # 0
利用pd.cut函数将评论数据划分范围
GB['评论范围']=pd.cut(GB['评论'],[-1,500,1001,2001,5001,1000000],labels=['5百以下','5百-1千','1千-2千','2千-5千','5千以上'])
GB['评论范围'].value_counts() # 统计每个范围的数量
# 5百以下 580
# 2千-5千 327
# 5千以上 244
# 1千-2千 241
# 5百-1千 208
绘制饼图
# 设置画布
plt.figure(figsize=(3,3),dpi=100)
la=['5百以下','5百-1千','1千-2千','2千-5千','5千以上']
da=[580/1600,208/1600,241/1600,327/1600,244/1600]
explode=[0.1,0,0,0,0]
res = plt.pie(da,labels=la,explode=explode,autopct="%.2f%%",shadow=True,textprops={"size":"smaller"},radius=1)
pathes,texts,autotexts = res
# 设置百分比文本的字体颜色以及大小粗细
plt.setp(autotexts, size=8, weight="bold", color="w")
plt.setp(texts, size=8, weight="bold", color="black")
# 添加图例
plt.legend(loc="upper right",bbox_to_anchor=(1,0,0.5,1))
plt.show()
500以下的评论数占比最大,为36.25%

2、导入美国Youtube数据,因数据没有比表头,我们手动添加每列的表头
US=pd.read_csv(r'D:\US_video_data_numbers.csv',names=['点击','喜欢','不喜欢','评论'])
查看评论数据的最大小值,以确定数据分组范围
print(US['评论'].max()) # 582624
print(US['评论'].min()) # 0
利用pd.cut函数将评论数据划分范围
US['评论范围']=pd.cut(US['评论'],[-1,500,1000,2000,5000,600000],labels=['5百以下','5百-1千','1千-2千','2千-5千','5千以上'])
US['评论范围'].value_counts()
# 5百以下 566
# 2千-5千 335
# 5千以上 315
# 1千-2千 262
# 5百-1千 210
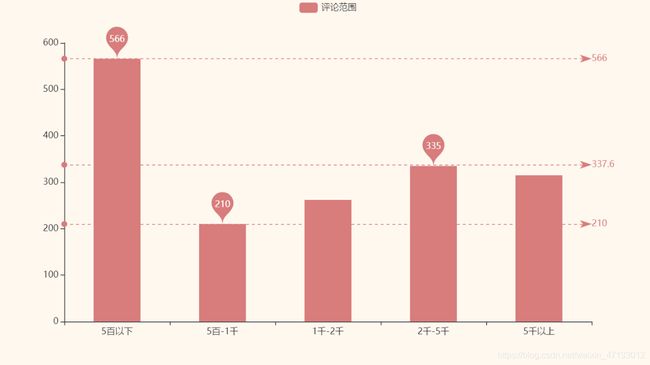
pyecharts绘制柱状图
from pyecharts.charts import Bar
from pyecharts import options as opts
from pyecharts.globals import ThemeType # 修改主题
x=['5百以下','5百-1千','1千-2千','2千-5千','5千以上']
y=[566,210,262,335,315]
bar=(Bar(opts.InitOpts(theme=ThemeType.VINTAGE))
.add_xaxis(x)
.add_yaxis('评论范围',y,category_gap=80)
.set_global_opts(title_opts=opts.TitleOpts(title=''))
.set_series_opts(
label_opts=opts.LabelOpts(is_show=False),
# 标记点
markpoint_opts=opts.MarkPointOpts(
data=[
opts.MarkPointItem(type_='min',name='最小值'),
opts.MarkPointItem(type_='max',name='最大值'),
opts.MarkPointItem(type_='average',name='平均值'),]),
# 标记线
markline_opts=opts.MarkLineOpts(
data=[
opts.MarkLineItem(type_='min',name='最小值'),
opts.MarkLineItem(type_='max',name='最大值'),
opts.MarkLineItem(type_='average',name='平均值'),])
))
bar.render_notebook()
从左往右标记点依次是最大值、最小值、平均数,500以下的评论数还是最多,有566个
练习2
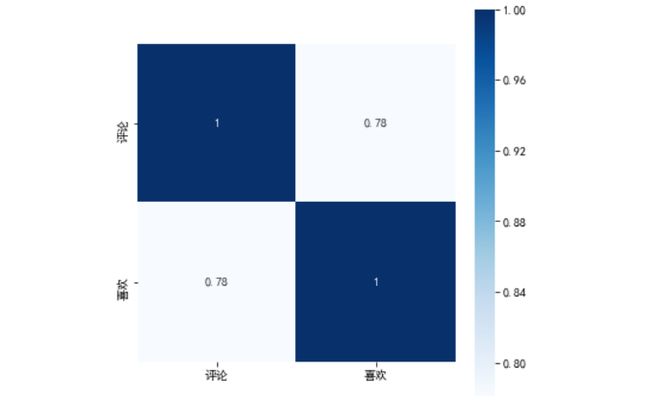
为探究英国Youtube评论数和喜欢数的关系,我们先计算“评论”和“喜欢”两列的相关系数,用相关系数热力图呈现。
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
# 计算评论与喜欢的相关系数
r=GB.loc[:,['评论','喜欢']].corr()
# 创建画布
plt.figure(figsize=(6,6))
sns.heatmap(r, annot=True, vmax=1, square=True, cmap="Blues")
plt.show()
评论数和喜欢数之间的相关系数为0.78,呈较高的正相关
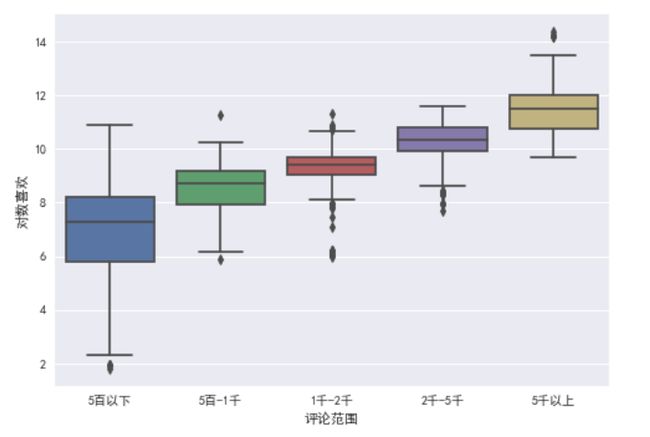
做评论范围与对数喜欢之间的箱线图
import seaborn as sns
plt.style.use('seaborn') # 修改主题样式
# 对“喜欢”数取对数
log_y=np.log(np.array(GB['喜欢']))
sns.boxplot(x=GB['评论范围'],y=log_y)
plt.ylabel('对数喜欢')
plt.show()
随着评论范围数的增加,喜欢的数量也在增加
练习3
拼接全为0的数组标识为英国
import numpy as np
# numpy导入文件
gb=np.loadtxt(r'D:\GB_video_data_numbers.csv',delimiter=',')
gb.shape # (1600, 4)
# 创建一个1600行1列全为0的数组
z=np.zeros((1600,1))
# 将两个数据水平拼接
gb_h=np.hstack((gb,z))
gb_h.shape # (1600, 5)
拼接全为1的数组标识为美国
us=np.loadtxt(r'D:\US_video_data_numbers.csv',delimiter=',')
us.shape # (1688, 4)
# 创建一个1688行1列全为1的数组
o=np.ones((1688,1))
# 将两个数据水平拼接
us_h=np.hstack((us,o))
us_h.shape # (1688, 5)
将两个国家的数据拼接
# 垂直拼接
two=np.vstack((gb_h,us_h))
two.shape # (3288, 5)