【paper-note9】Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting
论文作者:Haoyi Zhou Beihang University
收录:AAAI2021 best paper
前言
Transformer[1]模型在NLP领域提出之后,风靡众多领域,有大一统的模式。这篇论文就是对 transformer 进行改进,提出 Informer 模型应用在长时序预测领域。该模型设计合理精巧,利用长尾分布截取头部的attention点积对,提高运行效率、降低运行成本;同时模型结合长时序预测的特点,在输出阶段采用生成式的方法,一次性生成待预测的序列,避免了传统序列预测方法中串行生成的缺点。
核心思想
本文针对长时序预测任务(Long Sequence Time-series Forecasting, LSTF),提出了Informer模型,该模型最核心的思想是利用self-attention(SA)中点积对的长尾分布特性,只截取top u个点积对,把SA机制的时空复杂度从 O ( L 2 ) O(L^2) O(L2)降低至 O ( L l o g L ) O(L logL) O(LlogL)。也正是得益于这个 l o g L logL logL的复杂度,模型在预测阶段才可以采用生成式的方法,即经过一步迭代操作就能输出预测序列。

图1:Inofrmer模型框架,模型基本遵守Transformer的Encoder、Decoder结构。
主要贡献
- 本文提出了一个 P r o b S p a r s e ProbSparse ProbSparse self-attention mechanism(以下简称PSA),以此代替标准的SA机制,PSA的时空复杂度均为 O ( L l o g L ) O(LlogL) O(LlogL)。PSA分析了attention过程中的所有 { k i , q j } \{k_i, q_j\} {ki,qj}点积对,发现点积对服从长尾分布,大部分点积对产生较小的贡献,少数的点积对贡献非常大。可想而知,如果只计算贡献较大的哪些点积对,就可以降低模型的复杂度,但是如何在计算之前就知道哪些点积对贡献度大呢,这点就是本文最重要的内容,下文会详细阐述。
- 提出了一个自注意力蒸馏操作(self-attention distilling operation),该操作从PSA的特征图中抽取较大的值并保留下来,其实是一个 M a x P o o l \bf{MaxPool} MaxPool函数,通过该操作,模型的空间复杂度被进一步降低为 O ( ( 2 − ϵ ) L l o g L ) O((2-\epsilon)LlogL) O((2−ϵ)LlogL)。
- 在模型的预测阶段,作者使用一个全连接层直接输出想要预测的序列,如图1中右上角部分的模块,其中标黄色的元素是待预测数据,这种生成式(generative style)的预测方式只需要一步前馈迭代就可以得到整个待预测序列,避免了传统时序预测方法中逐步迭代带来的效率低下问题。
具体内容
问题描述
给定一个t时刻的输入序列 X t = { x 1 t , … , x L x t ∣ x i t ∈ R d x } X^t = \{x_1^t, \dots, x_{L_x}^t | x_i^t \in \mathbb{R}^{d_x} \} Xt={x1t,…,xLxt∣xit∈Rdx},希望得到预测输出序列 Y t = { y 1 t , … , y L y t ∣ y i t ∈ R d y } Y^t = \{y_1^t, \dots, y_{L_y}^t | y_i^t \in \mathbb{R}^{d_y}\} Yt={y1t,…,yLyt∣yit∈Rdy},其中 y i y_i yi不限于单一变量,即模型可以处理多变量问题。在LSTF任务中,作者希望能够预测尽量长的输出序列,即 L y L_y Ly尽可能大一点。
输入表征
在输入表征阶段,本文将全局位置信息(global positional context)和局部时序信息(local temporal context)融入到每个序列元素的表征中。

具体来说,全局位置信息将分,时,周,月,假日等信息编码并加入元素表征中,局部时序信息编码则是借鉴Transformer的位置编码方法,也是使用正余弦函数,得到每个元素的相对位置信息。
ProbSparse Self-attention Mechanism
标准 Self-attention
传统的标准 self-attention 定义如下:
A ( Q , K , V ) = S o f t m a x ( Q K T / d ) V \mathcal{A}(Q,K,V)=Softmax(QK^T/\sqrt{d})V A(Q,K,V)=Softmax(QKT/d)V
其中, Q ∈ R L Q × d , K ∈ R L K × d , V ∈ R L V × d Q\in\mathbb{R}^{L_Q \times d}, K\in\mathbb{R}^{L_K \times d}, V\in\mathbb{R}^{L_V \times d} Q∈RLQ×d,K∈RLK×d,V∈RLV×d,d代表输入向量的维度。
文献[2]提出第i个query q i q_i qi 的attention公式可以定义为一个带有内核平滑器的概率公式:
A ( q i , K , V ) = ∑ j k ( q i , k j ) ∑ l k ( q i , k l ) v j = E p ( k j ∣ q i ) [ v j ] \mathcal{A}(q_i, K, V) = \sum_j\frac{k(q_i, k_j)}{\sum_lk(q_i, k_l)}v_j = \mathbb{E}_{p(k_j|q_i)}[v_j] A(qi,K,V)=j∑∑lk(qi,kl)k(qi,kj)vj=Ep(kj∣qi)[vj]
上式中的 p ( k j ∣ q i ) = k ( q i , k j ) ∑ l k ( q i , k l ) p(k_j|q_i) = \frac{k(q_i, k_j)}{\sum_lk(q_i, k_l)} p(kj∣qi)=∑lk(qi,kl)k(qi,kj),其中 k ( q i , k j ) k(q_i, k_j) k(qi,kj)是非对称指数核函数: e x p ( q i k j T / d ) exp(q_i{k_j}^T/\sqrt{d}) exp(qikjT/d)。
以上就是传统的self-attention的计算方式,可以看到,其时间复杂度是 O ( N 2 ) O(N^2) O(N2)的,在长时序预测任务中,平方复杂度是非常不理想的,因此本文主要考虑解决该问题。
稀疏性分析
本文首先抽取出self-attention中的两张特征图,并对softmax的分数进行统计及可视化,如图2,可以发现self-attention层中的点积对呈现非常明显的长尾分布,即少数的点积对得到非常大的softmax值,在SA中起重要作用,而大部分点积对可以直接被忽视,并不影响SA的计算。

图2:self-attention特征图中的softmax分数呈现稀疏性,横坐标是点积对的数量,纵坐标是该点积对算出来的softmax值
由此可以想到我们只需要计算贡献度大的那部分点积对,能够大大减少计算的次数,加快计算的效率,那么如何在计算SA之前区分哪些点积对贡献度比较高,而哪些点积对没有贡献呢,这就需要引入一个稀疏性度量方法。
稀疏性度量(Query Sparsity Measurement)
上述公式中, p ( k j ∣ q i ) p(k_j|q_i) p(kj∣qi)用概率形式表示第i个查询(query)和每个键(key)的相似度;从概率角度来看, p ( k j ∣ q i ) p(k_j|q_i) p(kj∣qi)表示针对特定的 q i q_i qi, k j k_j kj能获得更高attention值的概率,其本质是通过softmax计算k和q的相似度。
我们希望一个优秀的attention模型应该能找到序列中较为相似的部分,当出现类同项时, p ( k j ∣ q i ) p(k_j|q_i) p(kj∣qi)应该远远大于其他 { k e y , q u e r y } \{key, query\} {key,query}对;从概率分布角度来看, p ( k j ∣ q i ) p(k_j|q_i) p(kj∣qi)应该要远离均匀分布,因为如果 p ( k j ∣ q i ) p(k_j|q_i) p(kj∣qi)接近均匀分布 q ( k j ∣ q i ) = 1 L K q(k_j|q_i)=\frac{1}{L_K} q(kj∣qi)=LK1时,self-attention就变成了对value的算数平均,无意义。
衡量两个分布的差异性,最容易想到的就是采用KL散度,:
K L ( p ∣ ∣ q ) = ∑ i = 1 N p ( x i ) ( l o g p ( x i ) − l o g q ( x i ) ) KL(p||q) =\sum_{i=1}^Np(x_i)(logp(x_i)-logq(x_i)) KL(p∣∣q)=i=1∑Np(xi)(logp(xi)−logq(xi))
其中p和q分别为两个分布的概率密度函数。接下来要衡量SA模型中 p ( k j ∣ q i ) p(k_j|q_i) p(kj∣qi)和均匀分布 q ( k j ∣ q i ) q(k_j|q_i) q(kj∣qi)的概率分布差异性,为了计算方便,把q分布放在前面,计算过程如下:

由于上式括号内第一项和第三项时常量,故括号前的 ∑ j = 1 L K 1 L K \sum_{j=1}^{L_K}\frac{1}{L_K} ∑j=1LKLK1可以抵消掉,得到如下结果:
K L ( q ∣ ∣ p ) = l n ∑ l = 1 L K e x p ( q i k l T / d ) − 1 L K ∑ j = 1 L K q i k j T / d − l n L K KL(q||p) = ln\sum_{l=1}^{L_K}exp(q_i{k_l}^T/\sqrt{d})-\frac{1}{L_K}\sum_{j=1}^{L_K}q_i{k_j}^T/\sqrt{d}-lnL_K KL(q∣∣p)=lnl=1∑LKexp(qiklT/d)−LK1j=1∑LKqikjT/d−lnLK
去掉第三个常量后,可以得到一个衡量第i个query的稀疏性度量函数 M M M:
M ( q i , K ) = l n ∑ j = 1 L K e q i k j T d − 1 L K ∑ j = 1 L K q i k j T d M(q_i, K) = ln\sum_{j=1}^{L_K}e^{\frac{q_i{k_j}^T}{\sqrt{d}}}-\frac{1}{L_K}\sum_{j=1}^{L_K}\frac{q_i{k_j}^T}{\sqrt{d}} M(qi,K)=lnj=1∑LKedqikjT−LK1j=1∑LKdqikjT
M M M越大,代表query i和每个key做attention的概率更具有差异性,并有更大概率包含有效的点积对。通过论文附录的进一步证明(证明过程这里不展开了,有兴趣的可以去阅读论文),得到简化后的稀疏性度量函数:
M ‾ ( q i , K ) = m a x j { q i k j T d } − 1 L K ∑ j = 1 L K q i k j T d \overline{M}(q_i, K)=max_j\{\frac{q_i{k_j}^T}{\sqrt{d}}\} - \frac{1}{L_K}\sum_{j=1}^{L_K}\frac{q_i{k_j}^T}{\sqrt{d}} M(qi,K)=maxj{dqikjT}−LK1j=1∑LKdqikjT
在长尾分布下,我们只需要随机采样 U = L K l n L Q U=L_KlnL_Q U=LKlnLQ个点积对来计算 M ‾ \overline{M} M;然后选取 M ‾ \overline{M} M值最大的Top-u个点积对中的query构造 Q ‾ \overline{Q} Q,在具体实践中,通常把query和key的长度设为相等,即 L Q = L k = L L_Q=L_k=L LQ=Lk=L,所以该模型的时空复杂度降为 O ( L l n L ) O(LlnL) O(LlnL)。
编码器
相对于上一节的内容,编解码器的结构就相对简单,编码器的框架如图3。
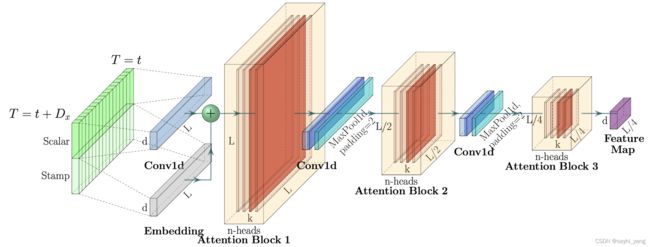
图3:编码器框架
从左到右分别是
-
输入序列的编码,包含元素表征编码和时序信息编码;
-
Embedding嵌入过程,通过一维卷积进行嵌入;
-
黄色部分就是multi-head的attention层,称之为
attention block,这里的attention采用上一节提出的ProbSparse Self-attention方法,图3中有3个attention block堆叠起来,每一块的特征图尺寸都是上一层的一半(下面maxpool的步长为2),模块个数为超参,可以根据需要调节; -
紧跟在attention block后面的蓝色模块称为自注意力蒸馏操作(Self-attention Distilling),蒸馏过程如下:
X j + 1 t = M a x P o o l ( E L U ( C o n v 1 d ( [ X j t ] A B ) ) ) X_{j+1}^t = MaxPool(ELU(Conv1d([X_j^t]_{AB}))) Xj+1t=MaxPool(ELU(Conv1d([Xjt]AB)))
其中一维卷积模块对时间维度进行卷积操作,卷积核大小为3,可以看出,蒸馏操作就是对attention后的特征图进行了最大池化(maxpool),步长为2,在抽取并保留特征图中较大的值的同时减半输入的时间维度。这样做的好处是在堆叠模型的同时保证内存使用率仍较低,通过这个操作,空间复杂度变为 O ( ( 2 − ϵ ) L l o g L ) O((2-\epsilon)LlogL) O((2−ϵ)LlogL),其中 ϵ \epsilon ϵ是一个很小的数值。
解码器
解码器结构可以见图1的右半部分,其中的attention结构和上面介绍的ProbSparse Self-attention Mechanism一致,mask操作也和Transformer一致,值得一提的是,解码器采用生成的方式预测输出序列。
-
输入阶段:将原始输入序列编码 X t o k e n t X_{token}^t Xtokent和零向量 X 0 t X_0^t X0t拼接到一起,得到解码器的输入 X d e t X_{de}^t Xdet:
X d e t = C o n c a t ( X t o k e n t , X 0 t ) ∈ R ( L t o k e n + L y ) × d m o d e l X_{de}^t = Concat(X_{token}^t, X_0^t)\in\mathbb{R}^{(L_{token}+L_y)\times d_{model}} Xdet=Concat(Xtokent,X0t)∈R(Ltoken+Ly)×dmodel
其中 X t o k e n t ∈ R L t o k e n × d m o d e l X_{token}^t \in \mathbb{R}^{L_{token}\times d_{model}} Xtokent∈RLtoken×dmodel是原始输入序列的编码,和encoder的输入一致,其序列长度 L t o k e n L_{token} Ltoken是一个超参, X 0 t X_0^t X0t是占位符,除了元素内容是零向量之外, X 0 t X_0^t X0t还包含时序信息的编码。 -
输出阶段:在attention模块后面接一个全连接网络,一步前馈就能够生成对应的预测序列。
也就是说解码器根据已有序列元素 X t o k e n X_{token} Xtoken,对后面占位符对应的元素预测。文章中有个简单的例子,已知前五天的数据,要预测接下来两天的数据,则 X d e = { X 5 d , X 0 } X_{de} = \{X_{5d}, X_0\} Xde={X5d,X0}, X 0 X_0 X0包含了需要预测的那两天的时间信息。
参考文献
[1] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Advances in neural information processing systems. 2017: 5998-6008.
[2] Tsai Y H H, Bai S, Yamada M, et al. Transformer Dissection: A Unified Understanding of Transformer’s Attention via the Lens of Kernel[J]. arXiv preprint arXiv:1908.11775, 2019.