vit 中的 cls_token 与 position_embed 理解
1. cls_token()
Class Token
假设我们将原始图像切分成共9个小图像块,最终的输入序列长度却是10,也就是说我们这里人为的增加了一个向量进行输入,我们通常将人为增加的这个向量称为 Class Token。那么这个 Class Token 有什么作用呢?
我们可以想象,如果没有这个向量,也就是将9个向量(1~9)输入 Transformer 结构中进行编码,我们最终会得到9个编码向量,可对于图像分类任务而言,我们应该选择哪个输出向量进行后续分类呢?
因此,ViT算法提出了一个可学习的嵌入向量 Class Token( 向量0),将它与9个向量一起输入到 Transformer 结构中,输出10个编码向量,然后用这个 Class Token 进行分类预测即可。
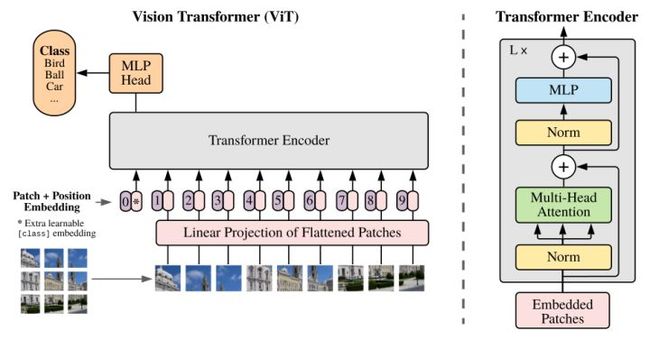
1.1 原理
类似于BERT中的[class] token,ViT引入了class token机制,其目的:因为transformer输入为一系列的patch embedding,输出也是同样长的序列patch feature,但是最后要总结为一个类别的判断,简单方法可以用avg pool,把所有的patch feature都考虑算出image feature。
但是作者没有用这种方式,而是引入一个类似flag的class token,其输出特征加上一个线性分类器就可以实现分类。
其中训练的时候,class token的embedding被随机初始化并与pos embedding相加,因此从图可以看到输入transformer的时候, 0 处补上一个新embedding,最终输入长度N+1.
# 随机初始化
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
# Classifier head
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
# 具体forward过程
B = x.shape[0]
x = self.patch_embed(x)
cls_tokens = self.cls_token.expand(B, -1, -1) # stole cls_tokens impl from Phil Wang, thanks
x = torch.cat((cls_tokens, x), dim=1)
x = x + self.pos_embed
一些问题:
ViT做分类时取出第n+1个token作为分类的特征,这样做的原理在哪里?有人说这样是为了避免对输入的某一个token有偏向性,那么我将前n个token做平均作为要分类的特征是否可行呢?
首先不存在n+1这个意思奥,论文里面是class token是放在首位,也就是第0个位置,
答案:
题主所说的第n+1个token(class embedding)的主要特点是:
(1)不基于图像内容;
(2)位置编码固定。
这样做有以下好处:
1、该token随机初始化,并随着网络的训练不断更新,它能够编码整个数据集的统计特性;
2、该token对所有其他token上的信息做汇聚(全局特征聚合),并且由于它本身不基于图像内容,因此可以避免对sequence中某个特定token的偏向性;
3、对该token使用固定的位置编码能够避免输出受到位置编码的干扰。ViT中作者将class embedding视为sequence的头部而非尾部,即位置为0。
这样即使sequence的长度n发生变化,class embedding的位置编码依然是固定的,因此,更准确的来说class embedding应该是第0个而非第n+1个token。
另外题主说的“将前n个token做平均作为要分类的特征是否可行呢”,这也是一种全局特征聚合的方式,但它相较于采用attention机制来做全局特征聚合而言表达能力较弱。
因为采用attention机制来做特征聚合,能够根据query和key之间的关系来自适应地调整特征聚合的权重,而采用求平均的方式则是对所有的key给了相同的权重,这限制了模型的表达能力。
2. Positional Encoding
按照 Transformer 结构中的位置编码习惯,这个工作也使用了位置编码。不同的是,ViT 中的位置编码没有采用原版 Transformer 中的 s i n c o s sincos sincos 编码,而是直接设置为可学习的 Positional Encoding。对训练好的 Positional Encoding 进行可视化,如 图9 所示。我们可以看到,位置越接近,往往具有更相似的位置编码。此外,出现了行列结构,同一行/列中的 patch 具有相似的位置编码。