【学习】自监督学习2、GPT、PLM
李宏毅机器学习
- 一、自监督学习
-
- 1、GPT模型
-
- 怎么使用GPT?
- 2、pre-trained language models 的最近发展
-
- pre-trained language models的背景
- 3、解决方法
-
- (1)prompt tuning(数据高效微调:即时调优)
- 2、few-shot learning(数据高效微调:少量学习)
- 3、semi-supervised learning(数据高效微调:半监督学习)
- 4、模式开发训练pattern -exploiting training(PET)
- 5、数据高效微调——zero-shot
- 数据高效微调:摘要
- 模型太大的解决方法
- (1)adapter(参数高效微调:适配器)
- (2)LoRA(高效参数微调)
- (3)prefix tuning(参数高效微调:前缀调优)
- (4)soft prompting(参数高效微调)
- 摘要
- (5)early exit
- 总结
一、自监督学习
1、GPT模型
GPT做的是类似于self attention里面的,他会预测接下来出现的token是什么。假如我们的训练资料是“台湾大学”,那么在一句话输入之前,会先输入这个代表一句话开始的符号。把输入到模型里面,会输出一个embedding h1。然后这个h1经过一些处理之后能预测接下来输入的字token是“台”。然后我们分别输入“台湾大”到模型里面,经过处理之后输出的分别是湾“大学”。实际上我们会用很多句子来训练这个模型,GPT用了很多数据来构造一个巨大的模型。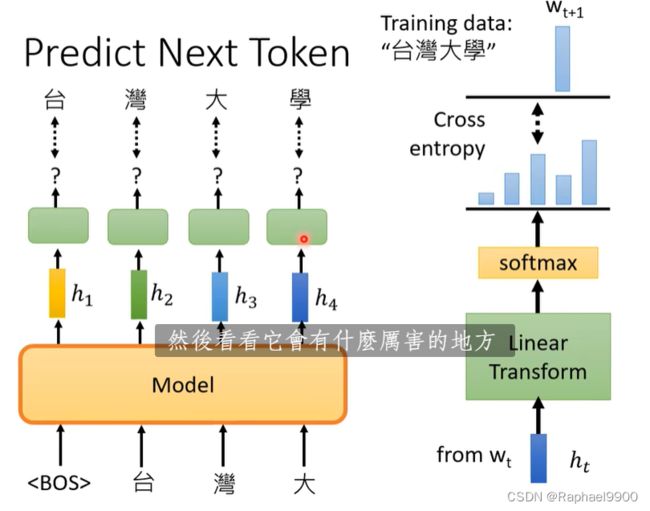
GPT的模型有点像transformer decoder,要做的attention。

GPT可以从token预测下一个字,那就可以无限生成。

怎么使用GPT?
GPT太大了,可能都不能做到微调。
在GPT的论文里面有一个few-shot learning,他是这样描述的:我们给机器一个任务描述,然后再给一点事例让机器学习,最后让他补充之前没有出现过的例子。在这里他并没有做gradient descent,在GPT的文献里面给这种方法赋予了一种新名字叫in-context learning。或者说我们只给一个例子,让GPT去完成后面的句子补充,这种方法叫one-shot learning。或者说我们不给示例力,直接让他补充后面的句子,这种方法叫zero-shot learning。如果能够实现,那就很惊人了!

GPT不是完全不能做到,他也是能完成某些例子的,但是它的正确率低。有些任务能完全答对,而有些完全无法处理。

在自监督学习上面还有很多:

也可以把BERT用在语音上:

在语音上,目前还没有标准的语音资料库,但是李老师他们做了一个SUPERB。语音除了内容之外还有别的东西,比如说话人,语气、情感等等。
在toolkit里面包含很多自监督学习的模型:

自监督学习还有很大的发展前景!
2、pre-trained language models 的最近发展
pre-trained language models的背景
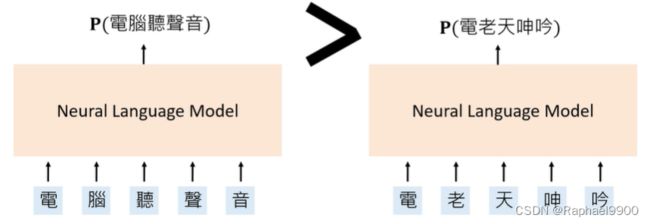
神经语言模型Neural Language Models:定义单词序列概率的神经网络。
把两个发音很像的句子放到模型里面训练,左边的句子概率比较大。
他是怎么训练的呢?给它一个不完整的句子,让机器预测剩下的句子。
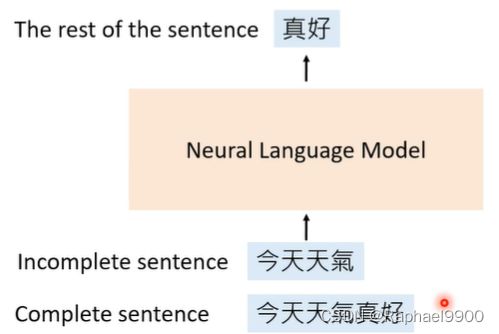
不完整的句子怎么构造?构造不完整的句子有很多种方法,而我们根据不同的构造方法把它分为不同的模型:
(1)autoregressive language model
第一种方法是autoregressive language model,他的任务是要给定前半段句子,完成后半段句子。假设我们的完整句子是“今天天气真好”。我们给定第一个字“今”,然后输入到模型里面,输出一个概率分布。这个概率分布预测“天”的可能性最大,而其他的可能性小,我们做取样的时候就会取出“天”。
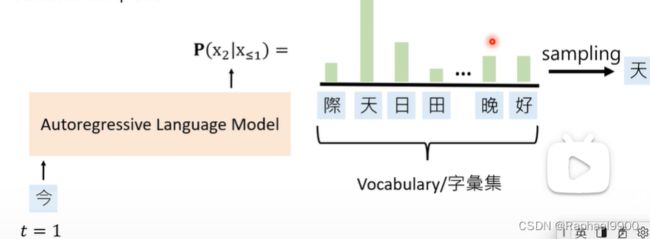
假如我们输入“今天”到模型里面,输出的概率分布虽然是“好”最大,但是我们做取样的时候是取出“天”。没有限制最大概率。
他的结构有很多种,这里介绍用transformer堆叠的结构。
transformer -based ALMs
我们把一句话和他前面的代表一句话的开始的token([BOS])放到输入里面,然后经过一个embedding layer之后输出一个向量序列。这个embedding layer要做的就是把离散的token转换为连续的向量。 然后把这些连续的向量经过多层的transformer layer之后,输出最终的向量。如果我们想要知道“气”这个字的预测值,那么就可以把最终的向量经过language model head(LM head,其实就是一个linear layer),那么就会给出第五个token的概率(给定四个token)。

self-supervised learning
language model其实就是一个self-supervised learning,给定其他部分预测任何部分。

masked language models
给定没有掩码的输入,预测掩码了的部分。

预训练语言模型(PLMs)
预训练:使用大型语料库训练神经语言模型预训练。
①自回归预训练:GPT系列(GPT、GPT 2、GPT 3)
②MLM-based 的预训练:BERT系列(BERT,RoBERTa,ALBERT)
我们相信,经过预训练后,PLM会学到一些知识,这些知识编码在隐藏的表示(hidden representation)中,可以转移到下游任务中。经过预训练之后的模型和隐藏表示用在下游任务的时候会表现都比较好。

(标准)微调:使用PLM的预训练权重来初始化下游任务的模型。
当我们要分辨某个数据是正面的还是负面的时候,可以用以下的分类器进行处理,而这个分类器的权重是使用经过预训练的PLM的权重。

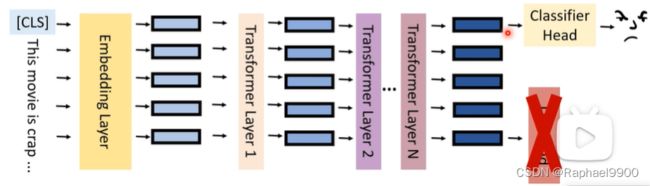
虽然这些参数是从预训练模型来的,但是它在微调的时候还是会跟着模型训练。这种方法在很多模型里面得到了很好的表现:可以看出BERT表现的很好
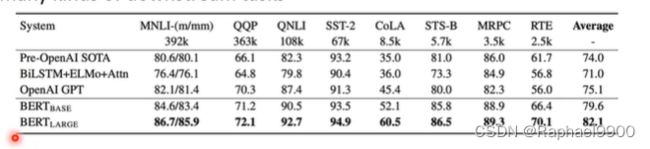
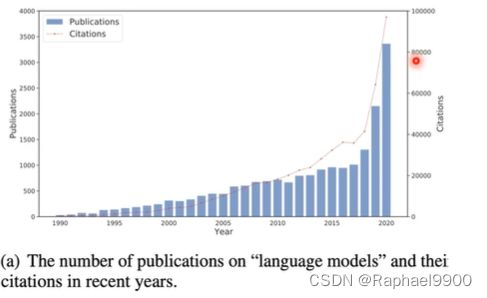
PLMs在NLP的各种基准数据集上取得了巨大成功。下一个目标是让PLM适合现实生活中的使用案例。如今PLMs有多不现实?
问题1:下游任务中的数据稀缺
对于每个下游任务,不容易获得大量标记数据

问题2:PLM太大,而且还在变大
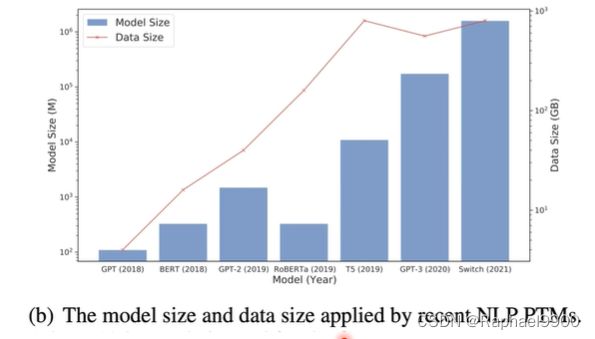
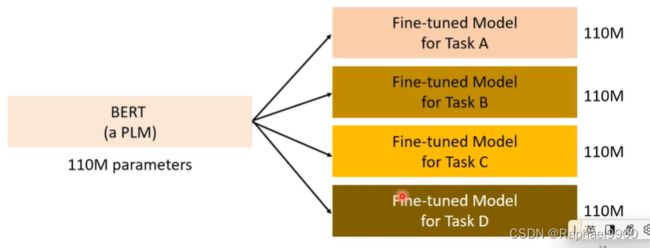
如果我们想把一个预训练语言模型用在任务A上,我们就要对这个模型进行微调,那么我们就需要微调跟这个模型一样大。每个任务都要这样大微调,推理时间太长,占用太多空间!
3、解决方法
标记数据稀缺→数据高效微调
PLM过于庞大→减少参数数量
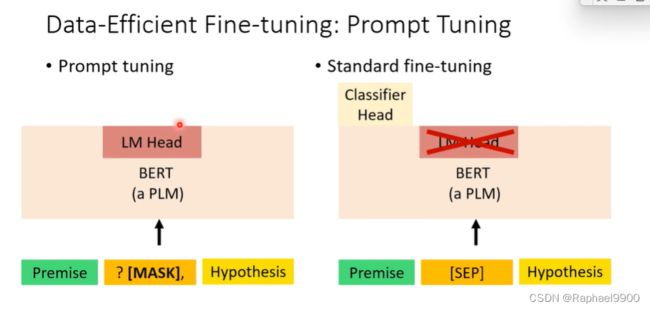
(1)prompt tuning(数据高效微调:即时调优)
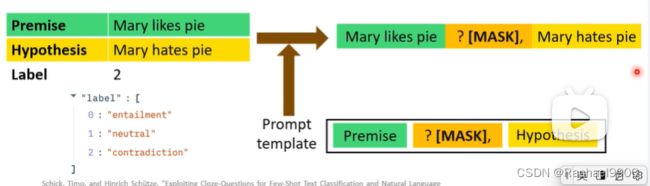
自然语言推理模型
在这模型里面,我们有两个句子,一个是前提,另一个是假设,我们要判断两个句子是什么关系(neutral、contradiction、entailment)。

当我们减少数据的时候,可能没办法判断。

当我们给了少量的句子的时候,希望它能判断:

通过将数据集中的数据点转换为自然语言提示prompt,模型可能更容易知道它应该做什么。

将下游任务格式化为语言建模任务,将预定义的模板格式化为自然语言提示。
在 prompt tuning里面需要三个东西

在即时调优 prompt tuning中需要什么?
1.提示模板:将数据点转换成自然语言提示
把两个句子中间用掩码相接,让模型预测中间掩码应该是什么字。
2.PLM:执行语言建模
PLM模型输入刚才的提示模板,输出的是一个概率分布(整个字符数据集)。
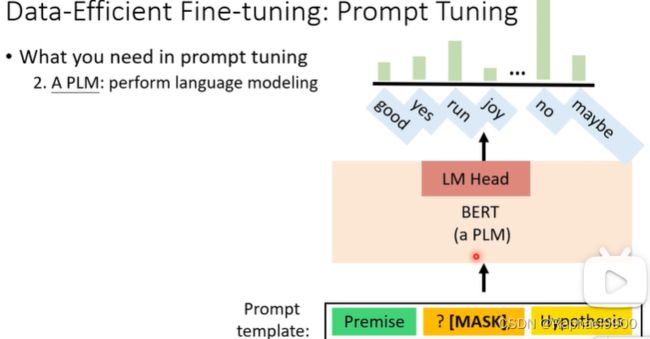
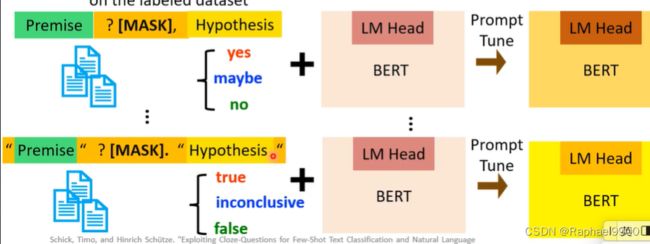
3.描述器:标签和词汇之间的映射
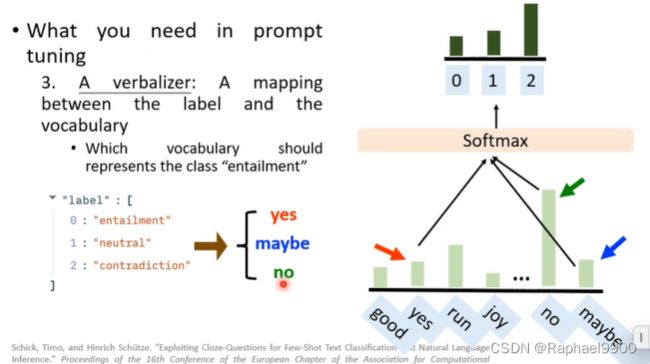
比如:哪个词汇表示类“entailment”,比如说下面把三个单词分别用yes、maybe、no表示,我们需要找这个三个词,通过softmax之后得到一个概率分布(2概率高,判断为2表示的单词)。
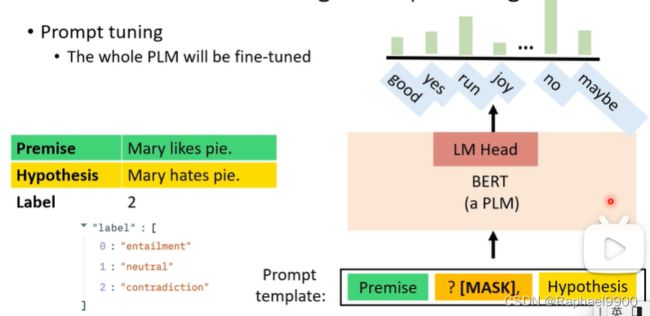
这整个PLM模型会一起微调。
区别
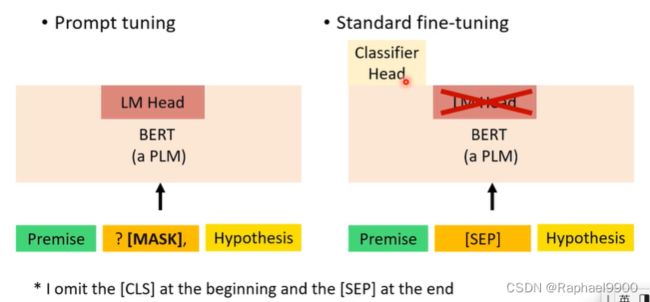
即时调优在数据稀缺的情况下具有更好的性能,因为它融入了人类知识它没有引入新的参数。在训练数据少的时候,prompt tuning比标准微调好很多,但是训练数据少的时候跟标准微调差不多。classifier head的参数量也很大,所以在少量数据的时候标准微调难调。prompt tuning保留了原本模型的机制,也不增加新的参数。
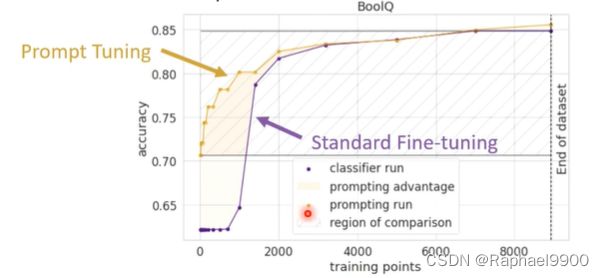
prompt tuning如果在数据量更少的时候怎么做?
让我们看看在不同的数据稀缺程度下,提示是如何帮助我们的

2、few-shot learning(数据高效微调:少量学习)
少量学习:我们有一些带标签的训练数据
一些达约等于10几笔
好消息:GPT-3可以用于few-shot setting
坏消息:GPT-3不是免费提供的,它包含175B个参数
few-shot:除了任务描述之外,模型还会看到一些任务示例。不执行梯度更新。
我们希望找到比GPT3更小的模型来用。
能不能用小一点的PLMs,并使他们在few-shot learning中表现良好?LM-BFF(better few-shot fine-tuning of language models)核心理念:提示+示范(prompt + demonstration)。

LM-BFF
即时调整:微调期间不会引入新参数
自动模板搜索

3、semi-supervised learning(数据高效微调:半监督学习)
半监督学习:我们有少量已标记的训练数据和大量未标记的数据

4、模式开发训练pattern -exploiting training(PET)
步骤1:使用不同的提示和描述器来提示调整标记数据集上的不同PLM
将标记数据进行训练(微调)
第2步:预测未标记的数据集,并结合不同模型的预测
无标签的数据经过模型输出soft-labeled 数据。
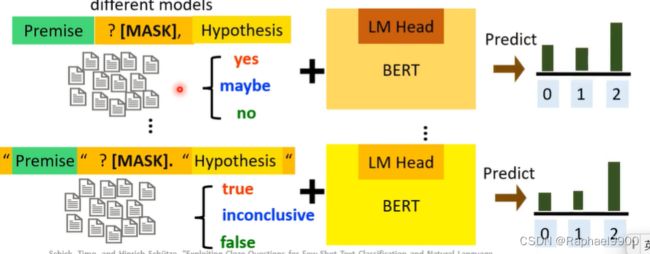
步骤3:使用带有分类器头的PLM对软标签数据集进行训练
我们使用上面生成的软标签数据和无标签数据进行输入,使用标准的PLM模型(含有分类器头),进行微调。

5、数据高效微调——zero-shot
zero-shot推理:在没有任何训练数据的情况下,对下游任务的推理。
如果你没有训练数据,那么我们需要一个能够对下游任务进行zero-shot推理的模型。
GPT-3表明zero-shot(带任务描述)是可能的,除非你的模型足够大。
该模型只给定任务的自然语言描述来预测答案。不执行梯度更新。

这种zero-shot能力从何而来?
假设:在预训练期间,训练数据集隐含地包含不同任务的混合。

假设:多任务训练能够实现zero-shot概括
为什么不在一堆数据集上训练一个具有多任务学习的模型?
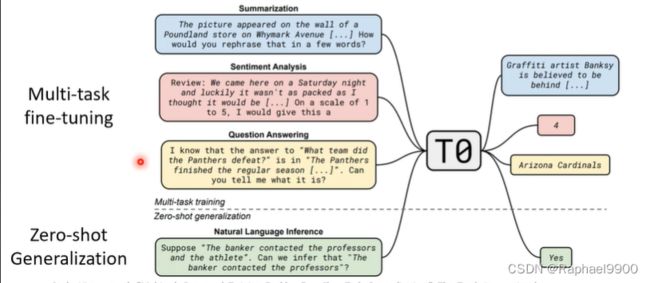
使用PLM进行多任务微调
将任务转换成自然语言提示
示例:自然语言推理

微调某些类型的zero-shot任务和对其他类型任务的推断
有以下任务,他们分为两类:黄色的任务在微调的时候看过,绿色的任务在微调的时候没有,在zero-shot里面有。
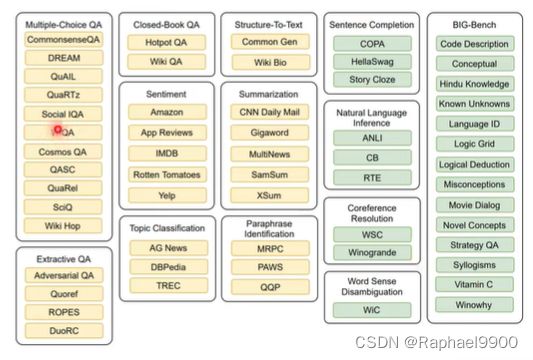
在只有11B个参数的时候,表现的比GPT-3(175B参数)好

数据高效微调:摘要
使用自然语言提示并添加特定场景设计

模型太大的解决方法
问题:PLM太大(就参数数量、模型大小和存储模型所需的存储空间而言)
如果使用小模型,这是不行的,因为大的模型确实会比小的模型训练的比较好。
解决方案:减少使用的参数的数量,比如说较小的预训练模型,可以实现吗?
(1)减少参数的数量
预先训练一个大模型,但对下游任务使用一个较小的模型。
以下有两个做法:
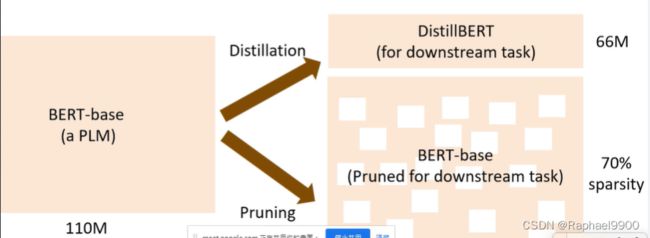
distillation的方法可以让参数量变少的同时也能让模型推演变快。pruning方法因为sparsity比较高,所以需要存储的空间就少点。
(2)在transformer层之间共享参数
在BERT里面,不同的transformer层的参数是不一样的,所以他的参数量很大;但是在ALBERT里面,因为不同的transformer层的参数是一样的,所以他的参数量很小。
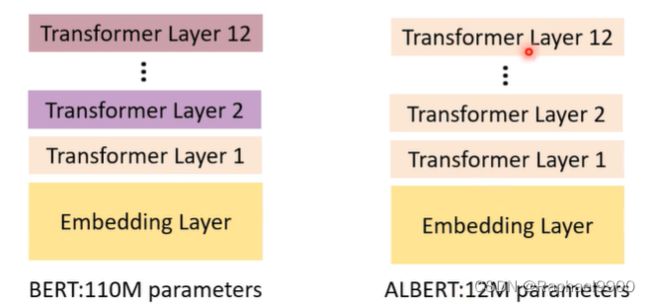
(3)parameter-efficient fine tuning
希望在微调的时候用少的参数。
我们希望微调的时候用特有的参数,那这些下游任务就能共有一个BERT。

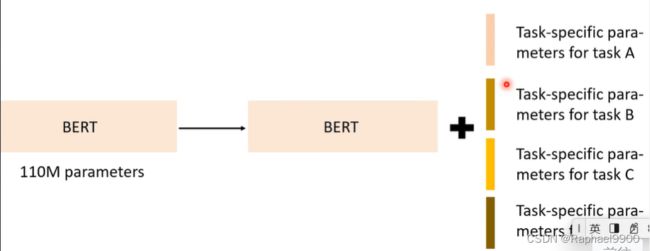
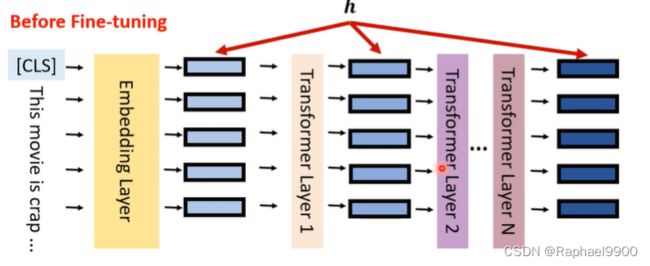
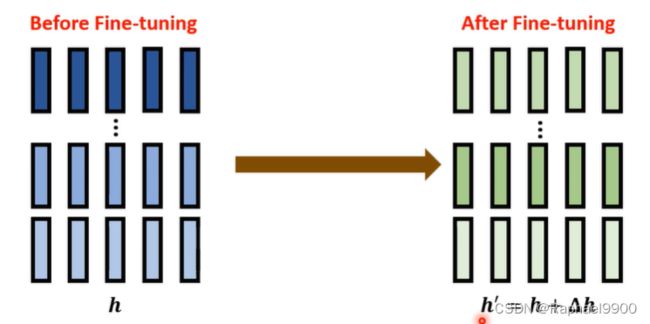
标准微调到底在做什么?
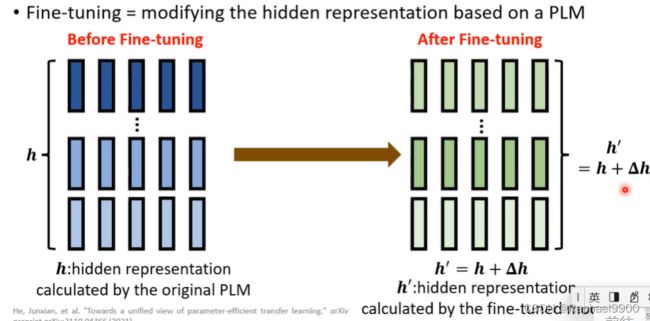
修改PLM的隐藏表示(h ),使其能够很好地执行下游任务。
我们经过微调之后,得到了新的隐藏表示(h’),就能应用在不同的下游任务。

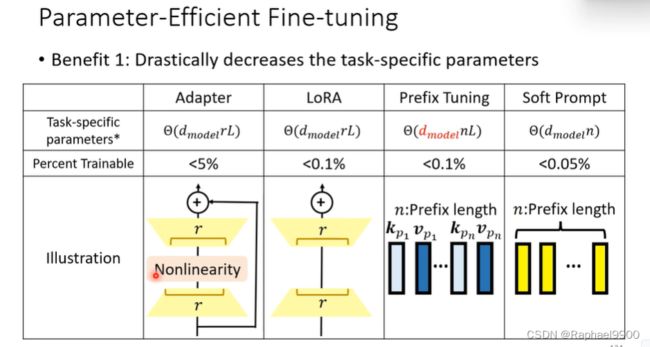
(1)adapter(参数高效微调:适配器)
使用特殊的子模块修改隐藏的表示!
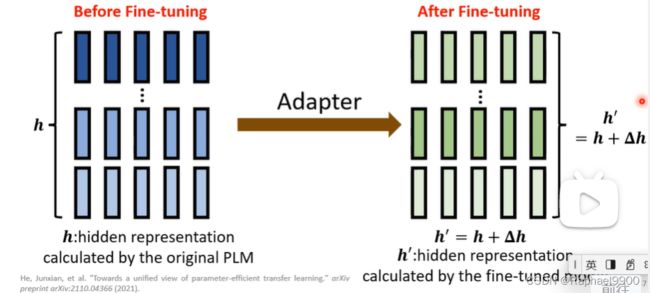
adapters:插入transformer的小型可训练子模块。
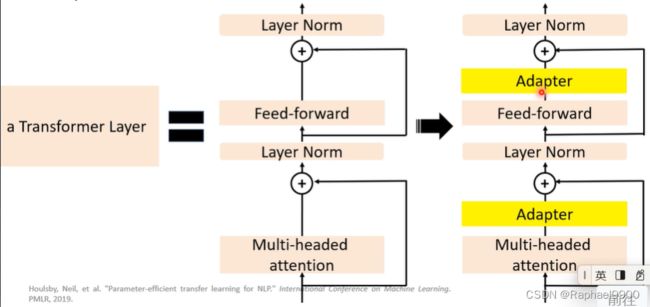
这个adapter其实是个NLP。当一个隐藏的表示输入之后,把它降维,然后又升维度。产生的h’可以让下游任务利用。

我们只会更新adapter,adapter的参数是很少的。
在微调的时候,我们只更新classifier head 和adapter的参数就可以了。
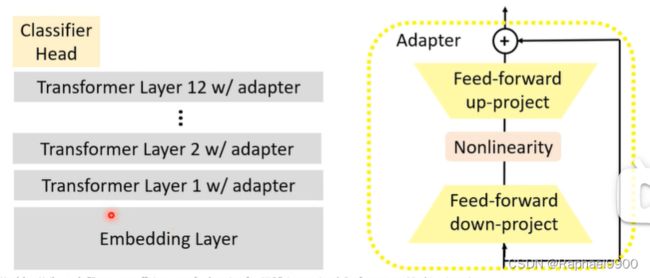
(2)LoRA(高效参数微调)
使用特殊的子模块来修改隐藏的表示!

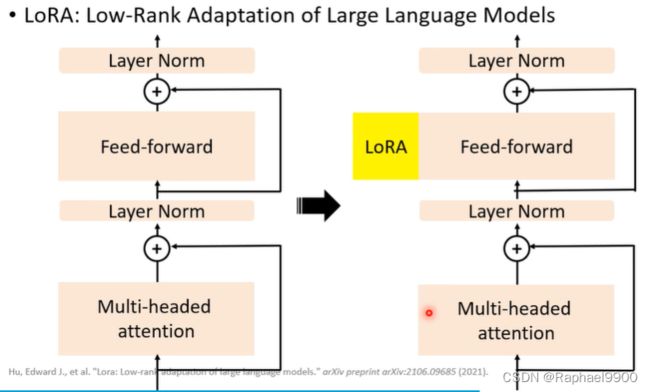
feed-forward其实是两层的NLP。把低维向量up-project之后放到高维空间,然后经过经过非线性转换和down-project还原回低维空间。LoRA就是经过平行运算后加到feed-forward里面的。
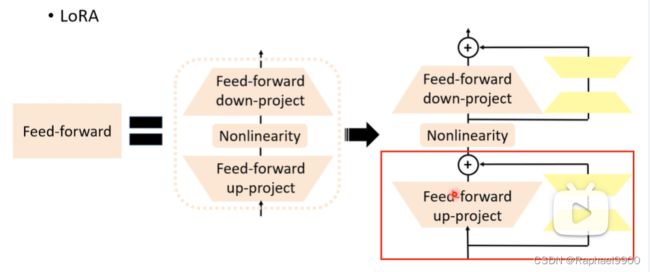
LoRA中间会产生一个更低维度的向量r。
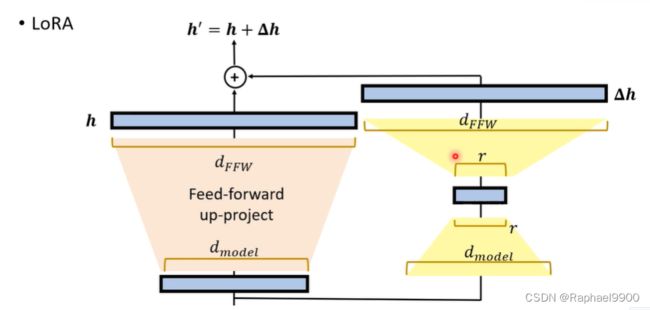
LoRA:所有下游任务共享PLM;每层中的LoRA和分类器头是特定于任务的模块。更新分类器头和LoRA的参数,其他地方不变。

上面两个哪个更好呢?
adapter能让网络增加,时间增长;LoRA是跟feed-forward平行运算的。LoRA能把参数量压的很小,但是他们两个是差不多的东西。
(3)prefix tuning(参数高效微调:前缀调优)
使用特殊的子模块修改隐藏的表示!
原本的自注意力模型是这样的: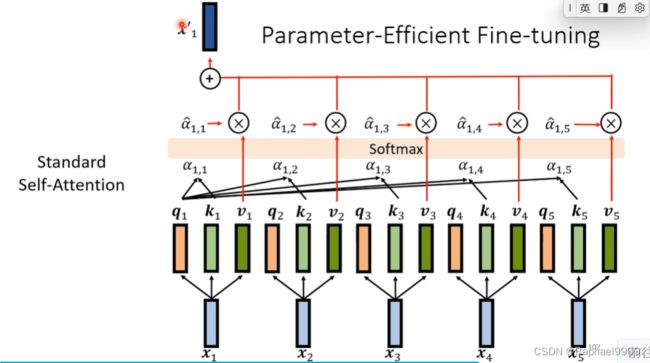
prefix tuning在前面插入了东西,(p1,p2,p3),他们没有query 向量,他们只会被别人query。然后对prefix tuning做self-attention,prefix tuning跟自注意力模型的NLP是不一样的,但是self-attention做法类似。

以上是预训练的模型,在我们要用的时候就把p向量丢弃,只要kp和kv。
这个方法会在每个transformer 层里面插入一个前缀。
前缀调整:在微调期间,仅更新前缀(键k和值v)。
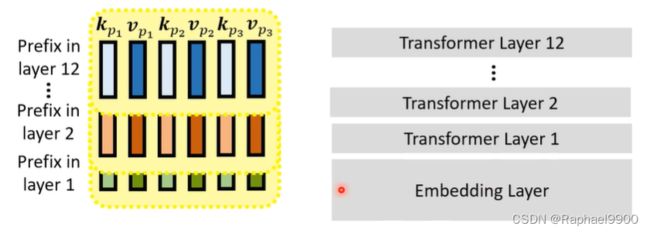
(4)soft prompting(参数高效微调)
soft prompting:在输入层预先考虑前缀嵌入,只在插入一次到transformer之前。
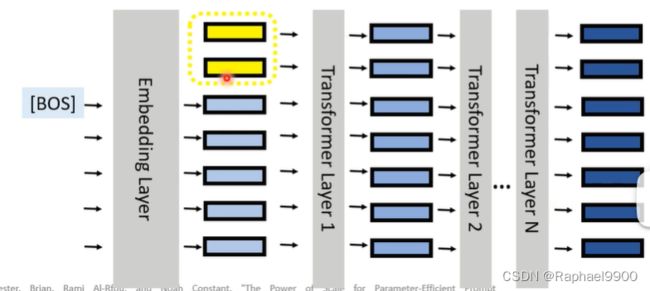
软提示soft prompting可以被认为是提示的软化版本,可以只调soft prompting输入的向量。
(硬)提示:在输入句子中添加单词(在修复提示时微调模型)
软提示:向量(可以从一些单词嵌入中初始化,新单词)
(硬)提示:单词(最初在词汇表中)

摘要
好处1:大大减少了特定任务的参数
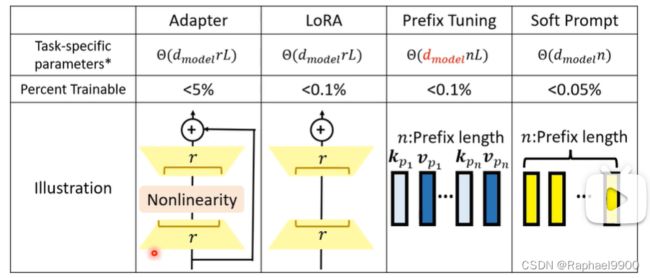
LoRA跟adapter虽然结构类似,但是lora的r能到1或者2,而adapter能到15或者16。soft prompt需要的模型比较大,其他不一定需要大模型。
好处2:不太容易在训练数据上过度拟合;更好的域外out-of-domain性能
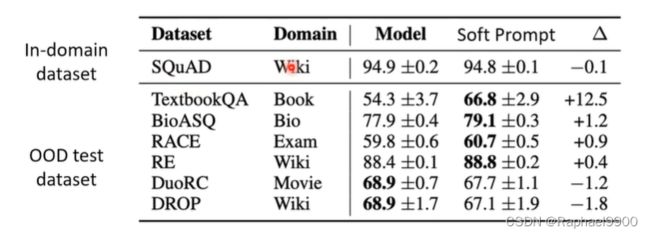
好处三:需要微调的参数更少;在使用小数据集训练时,这是一个很好的选择

(5)early exit
问题:PLM太大,推理耗时太长
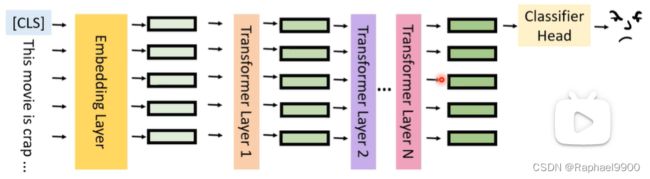
使用整个模型进行推断花费的时间太长,那就不用整个模型!
更简单的数据可能需要更少的努力来获得答案,那就不需要所有的层数来预测。
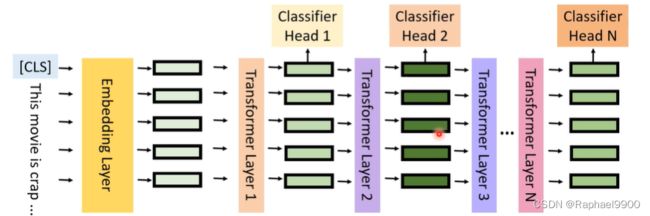
做法:在每一层都加一个classifier。问题:我怎么要拿哪一层来用?使用一个confidence predictor
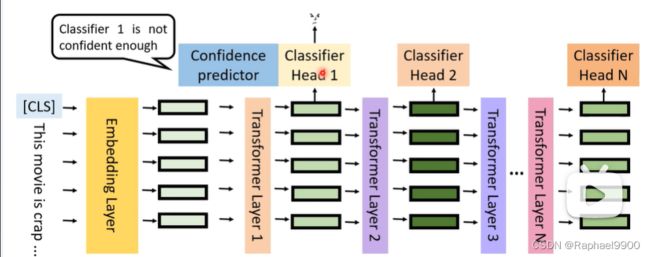
如果检测第一层不行
那就检测第二层和,可以用!那就不用后面的步骤了!
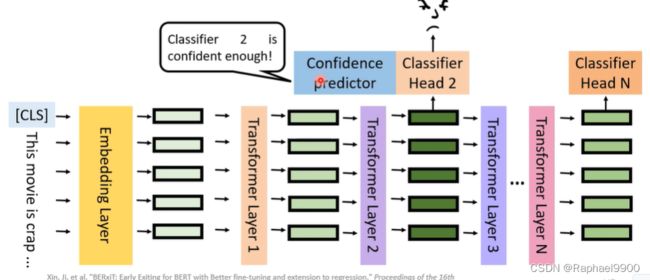
提前退出减少了推理时间,同时保持了性能

参数高效微调:减少下游任务中特定于任务的参数
early exit:减少推断过程中涉及的模型
总结
主要涉及使PLM更小、更快、参数效率更高;当下游任务中的标记数据不足时,部署PLM。
这些问题还没有完全解决。我们讨论的问题只是PLMs问题的一小部分:为什么自我监督的预培训会有效;模型预测的可解释性;领域适应;持续学习/终身学习(参数更新);安全和隐私(会泄露预训练的资料)。