NLP中的预训练方法总结 word2vec、ELMO、GPT、BERT、XLNET
文章目录
-
- 一.文本的表示方法
-
- 基于one-hot的词向量
- 二.基于词向量的固定表征方法(词向量模型)
-
- 2.1 N-gram模型
- 2.2 NNLM
- 2.3 word2vec
-
- CBoW
- Skip-gram
- 层次Softmax
- 负采样
- 三.基于词向量的动态表征方法(预训练语言模型)
-
- 3.1 什么是预训练语言模型
- 3.2 预训练语言模型的优点
- 3.3 预训练语言模型的分类
-
- 自回归语言模型
- 自编码语言模型
- 排列语言模型
- 3.4 几种重要的预训练模型介绍
-
- 1. ELMO
- 2. GPT
- 3. BERT
-
- Task 1: MLM
- Task 2: NSP
- BERT的缺点
- 4. wwm-BERT
- 5. ERNIE
- 6. XLNET
-
- Two-Stream Self-Attention
- Transformer-XL
一.文本的表示方法
将一篇自然语言类文本用数学语言表示的方法有一下几种:
- 基于one-hot、tf-idf、textrank
- 基于词向量的固定表征:word2vec、fastText、glove
- 基于词向量的动态表征:ELMO、GPT、BERT
基于one-hot的词向量
one-hot向量是最简单的词向量表达方法。首先,构建一个输入文本中出现的所有词的词表,对每个词进行编号,假设词表的长度为n,则对于每一个词的表征向量均为一个n维向量,且只在其对应位置上的值为1,其他位置都是0,这就是one-hot形式的词向量,如下图所示:

one-hot向量将每个单词表示为完全独立的实体,这样的表征方法主要有以下几个问题:
- 有序性问题:它无法反映文本的有序性。因为语言并不是一个完全无序的随机序列。比如说,一个字之后只有接特定的字还能组成一个有意义的词,特定的一系列词按特定的顺序组合在一起才能组成一个有意义的句子。
- 语义鸿沟:其无法通过词向量来衡量相关词之间的距离关系,即这样的表征方法无法反映词之间的相似程度,因为任意两个向量的距离是相同的。
- 维度灾难:高维情形下将导致数据样本稀疏,距离计算困难,这对下游模型的负担是很重的。
二.基于词向量的固定表征方法(词向量模型)
由于one-hot形式的词向量有许多问题,所以语言模型被提了出来,最初的语言模型是N-gram模型及NNLM。
2.1 N-gram模型
语言模型想要解决的问题是求一段文本序列在某种语言下出现的概率。这个问题可以通过计算每个候选句作为答案的概率,然后选取概率最大的文本作为答案来解决。
统计语言模型给出了上述问题的一个基本解决框架。对于一段文本序列
![]()
要求出一段文本的联合概率,仅需要计算出每个词或者每段文本在给定previous words下的条件概率,由于其巨大的参数空间(或说过长的上文文本),这样一个原始的模型在实际中并没有什么用,比如文中的词与文档开头的词并没有什么相关性。所以更多的是仅用之前的n个文本来计算当前文本的条件概率,即我们常说的N-gram模型:
![]()
当假设一个词的出现不依赖于其他任何词时,称为unigram;当一个词的出现依赖于上一个词时,称为bigram。可以用最大似然法去求解Ngram模型的参数,即等价于去统计每个Ngram的条件词频。事实上,由于模型复杂度和预测精度的限制,很少会考虑N>3的模型。
2.2 NNLM
鉴于Ngram等模型的不足,2003年,Bengio等人提出了NNLM模型,NNLM模型的基本思想可以概括如下:
- 假定词表中的每一个word都对应着一个连续的特征向量;
- 假定一个连续平滑的概率模型,输入一段词向量的序列,可以输出这段序列的联合概率;
- 同时学习词向量的权重和Ngram概率模型里的参数。
值得注意的一点是,这里的词向量也是要学习的参数,也就是说词向量是在训练的过程中自动生成的。在03年的论文里,Bengio等人采用了一个简单的前向反馈神经网络 f ( w t − n + 1 , . . . , w t ) f(w_{t−n+1},...,w_t) f(wt−n+1,...,wt)来拟合一个词序列的条件概率 p ( w t ∣ w 1 , w 2 , . . . , w t − 1 ) p(w_t|w_1,w_2,...,w_{t−1}) p(wt∣w1,w2,...,wt−1)。整个模型的网络结构为一个三层神经网络。第一层为映射层,第二层为隐藏层,第三层为输出层见下图:
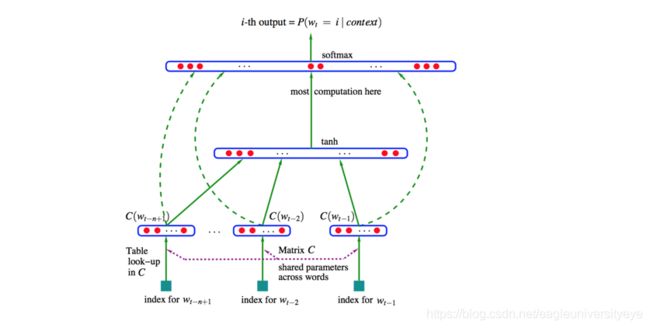
这个模型解决了两个问题:
- 统计语言模型里关注的条件概率 p ( w t ∣ c o n t e x t ) p(w_t|context) p(wt∣context)的计算
- 向量空间模型里关注的词向量的表达
但NNLM模型仍然存在一系列问题:
- 由于NNLM模型使用的是全连接神经网络,因此只能处理定长的序列
- 巨大的参数空间,使NNLM的训练过程太慢了,需要一些提速手段
2.3 word2vec
NNLM模型由于有上述的两个问题,所以在实际使用过程中效果不佳,于是许多人提出了改进方案。首先,针对第一个问题,Mikolov等人在2010年提出了一种RNNLM模型,用递归神经网络代替原始模型里的前向反馈神经网络,并将Embedding层与RNN里的隐藏层合并,从而解决了变长序列的问题。对于第二个问题,同样是Mikolov,他提出了一个计算词向量的工具,大大增加了NNLM模型的效率,这就是word2vec。
word2vec主要内容包括两个模型 + 两个提速手段,两个模型分别是CBoW(Continues Bag-of-Words Model)和Skip-gram,两个提速手段分别是层次Softmax(Hierarchical Softmax)和负采样(Nagative Sampling)。使用层次Softmax和负采样的原因是,在NNLM中每当计算一个词的概率都要对词典里的V个词计算相似度,然后进行归一化,这使得计算过程的效率非常低,因此有必要使用一些提速手段。
CBoW
CBoW与之前的NNLM非常相似,简单概括其思路就是:输入中间词前后共 C C C个词,预测中间词,在这个过程中训练出我们需要的词向量矩阵。其模型结构如下图所示:
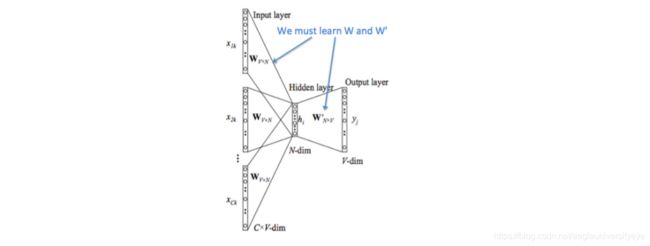
CBoW的计算过程:
- 图中 [ x 1 k , . . . , x C k ] [x_{1k},...,x_{Ck}] [x1k,...,xCk]表示第 k k k个中心词的前后 C C C个上下文的 one-hot 向量
- 将 one-hot 向量输入存放词向量的矩阵 W V × N W_{V×N} WV×N进行查表, V V V为词表的大小, N N N为词向量的维度
- 将查表得到的上下文向量直接进行求和,再通过一个 N × V N×V N×V的矩阵映射到输出层
Skip-gram
Skip-gram的思路是:输入中间词,预测中间词的上下文 C C C个词,训练出我们需要的词向量矩阵。

层次Softmax
Hierarchical Softmax是word2vec中的一项关键技术,简单来说,其通过构造一个Huffman树,将复杂的归一化概率问题转化为一系列二分类的条件概率相乘的形式。
负采样
由于训练词向量模型的目标不是为了得到一个多么精准的语言模型,而是为了获得它的副产物——词向量。所以要做到的不是在几万几十万个token中艰难计算softmax获得最优的那个词(就是预测的对于给定词的下一词),而只需能做到在几个词中找到对的那个词就行,这几个词包括一个正例(即直接给定的下一词),和随机产生的噪声词(采样抽取的几个负例),就是说训练一个sigmoid二分类器,只要模型能够从中找出正确的词就认为完成任务。
三.基于词向量的动态表征方法(预训练语言模型)
3.1 什么是预训练语言模型
预训练语言模型是通过自监督学习的方法,将大量的无监督文本送入到模型中进行学习训练得到的。NLP领域中无监督文本数据非常多,而且采用更大的数据、更强大的炼丹炉可以不断提高模型性能表现,至少目前看来还没有达到上限。这一类工作为NLP研发者趟通并指明了一条光明大道:就是通过自监督学习,把大量非监督的文本充分利用起来,并将其中的语言知识编码,对各种下游NLP任务产生巨大的积极作用。
3.2 预训练语言模型的优点
预训练语言模型相比预训练词向量,效果要好很多,原因可以总结为:
word2vec等词向量模型训练出来的都是静态的词向量,即同一个词,在任何的上下文当中,其向量表征是相同的,显然,这样的一种词向量是无法体现一个词在不同语境中的不同含义的。
预训练模型能够对上下文中的词提取符合其语境的词表征,该词表征向量为一个动态向量,即不同上下文输入预训练模型后,同一个词的词表征向量在两个上下文中的词表征是不同的。
3.3 预训练语言模型的分类
预训练语言模型可以分为两类,分别为自回归语言模型和自编码语言模型
自回归语言模型
通过给定文本的上文,对当前字进行预测,训练过程要求对数似然函数最大化:
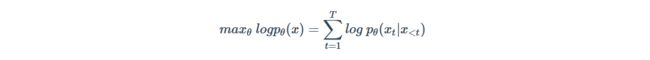
自回归语言模型对文本序列联合概率的密度估计进行建模,使得该模型更适用于一些生成类的NLP任务,因为这些任务在生成内容的时候就是从左到右的,这和自回归的模式天然匹配。但是联合概率是按照文本序列从左至右进行计算的,因此无法得到包含上下文信息的双向特征表征,在利用上下文信息方面不如自编码语言模型。
自回归语言模型主要有:ELMO,GPT
自编码语言模型
自编码语言模型通过随机mask掉一些单词,在训练过程中根据上下文对这些单词进行预测,使预测概率最大化:

自编码语言模型本质为去噪自编码模型,加入的 [MASK] 即为噪声,模型对 [MASK] 进行预测即为去噪。自编码语言模型能够利用上下文信息得到双向特征表示,但是其引入了独立性假设,即每个 [MASK] 之间是相互独立的,这使得该模型是对语言模型的联合概率的有偏估计;另外,由于预训练中 [MASK] 的存在,使得模型预训练阶段的数据与微调阶段的不匹配,使其难以直接用于生成任务。
自编码语言模型主要有:BERT、ERNIE
排列语言模型
排列语言模型的思想就是在自回归和自编码的方式中间额外添加一个步骤,即可将两者完美统一起来,具体的就是希望语言模型从左往右预测下一个字符的时候,不仅要包含上文信息,同时也要能够提取到对应字符的下文信息,且不需要引入Mask符号。即在保证位置编码不变的情况下,将输入序列的顺序打乱,然后预测的顺序还是按照原始的位置编码顺序来预测的,但是相应的上下文就是按照打乱顺序的上下文来看了,这样以来,预测对象词的时候,可以随机的看到上文信息和下文信息。另外,假设序列长度为 T T T,则我们如果遍历 T ! T! T!种分解方法,并且模型参数是共享的,PLM就一定可以学习到预测词的所有上下文信息。但显然,遍历 T ! T! T!种上下文计算量是十分大的,在具体实施的过程中,排列语言模型的代表XLNet,采用的是一个部分预测的方法(Partial Prediction),为了减少计算量,只对随机排列后的末尾几个词进行预测,并使得如下期望最大化:

排列语言模型主要有:XLNET
3.4 几种重要的预训练模型介绍
1. ELMO
ELMo为一个典型的自回归预训练模型,其包括两个独立的单向LSTM实现的单向语言模型进行自回归预训练,不使用双向的LSTM进行编码的原因正是因为在预训练任务中,双向模型将提前看到上下文表征而对预测结果造成影响。因此,ELMo在本质上还是属于一个单向的语言模型,因为其只在一个方向上进行编码表征,只是将其拼接了而已。对于每一个字符,每一层的ELMo表征均为输入词向量与该层的双向编码表征拼接而成:

对于下游任务而言,需要把所有层的ELMo表征整合为一个单独的向量,最简单的方式是只用最上层的表征,也可以采用对所有层的ELMo表征采取加权和的方式进行处理:
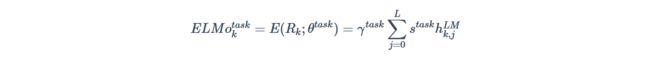
2. GPT
GPT是“Generative Pre-Training”的简称,是一个自回归语言模型,采用多层Transformer Decoder作为特征抽取器。由于Transformer不像LSTM那样从左到右进行特征抽取,所以会在预测当前词的时候看见之后的词,GPT采用Mask Multi-Head Attention的方式来避免这种情况,使Transformer只使用一侧的词作为输入,这种Transformer又被称作单向Transformer。
GPT首次将Transformer应用于预训练模型,预测的方式就是将position-wise的前向反馈网络的输出直接送入分类器进行预测。在微调阶段,对于带有标签y的监督数据 [ x 1 , . . . , x m ] [x_1,...,x_m] [x1,...,xm],直接将其输入到已经完成预训练的模型中,然后利用最后一个位置的输出对标签进行预测:
![]()
其中, W y W_y Wy为分类器的参数, h l m h^m_l hlm为最后一层最后一个位置的输出。则最大化优化目标即为:

3. BERT
BERT 的特征抽取结构为双向的 Transformer,相比于GPT,把Transformer由单向的变为双向的。ELMO、GPT、BERT三者对比:
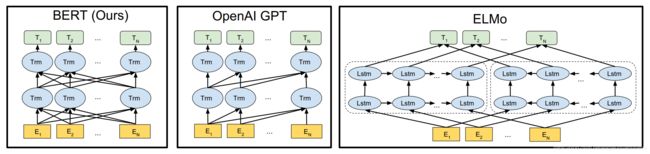
由于BERT的特征抽取结构采用双向Transformer,所以BERT无法适用于自回归语言模型的预训练方式,因此,BERT提出了两种预训练任务来对其模型进行预训练。
Task 1: MLM
由于BERT需要通过上下文信息,来预测中心词的信息,同时又不希望模型提前看见中心词的信息,因此提出了一种 Masked Language Model 的预训练方式,即随机从输入预料上 mask 掉一些单词,然后通过的上下文预测该单词,类似于一个完形填空任务。
在预训练任务中,15%的 Word Piece 会被mask,这15%的 Word Piece 中,80%的时候会直接替换为 [Mask] ,10%的时候将其替换为其它任意单词,10%的时候会保留原始Token
-
没有100%mask的原因
如果句子中的某个Token100%都会被mask掉,那么在fine-tuning的时候模型就会有一些没有见过的单词
-
加入10%随机token的原因
Transformer要保持对每个输入token的分布式表征,否则模型就会记住这个[mask]是token ’hairy‘
另外编码器不知道哪些词需要预测的,哪些词是错误的,因此被迫需要学习每一个token的表示向量
-
另外,每个batchsize只有15%的单词被mask的原因,是因为性能开销的问题,双向编码器比单项编码器训练要更慢
Task 2: NSP
仅仅一个MLM任务是不足以让 BERT 解决阅读理解等句子关系判断任务的,因此添加了额外的一个预训练任务,即 Next Sequence Prediction。
具体任务即为一个句子关系判断任务,即判断句子B是否是句子A的下文,如果是的话输出’IsNext‘,否则输出’NotNext‘。训练数据的生成方式是从平行语料中随机抽取的连续两句话,其中50%保留抽取的两句话,它们符合IsNext关系,另外50%的第二句话是随机从预料中提取的,它们的关系是NotNext的。这个关系保存在图4中的[CLS]符号中
BERT的缺点
BERT难以适应生成式任务,这是因为BERT采用了双向的特征抽取器,使得其预训练过程与中的数据与微调的数据不匹配。
BERT没有考虑预测被[MASK]的token之间的相关性,是对语言模型联合概率的有偏估计。这在处理中文语料时不太合适,因为中文的字可以组成词,所以中文的字之间是由相关性的,之后的wwm-BERT就针对这一点做了改进。
4. wwm-BERT
wwm的全称是Whole Word Masking ,暂翻译为全词Mask或整词Mask,是哈工大讯飞联合实验室提出的BERT中文预训练模型的升级版本,主要更改了原预训练阶段的训练样本生成策略。 简单来说,原有基于WordPiece的分词方式会把一个完整的词切分成若干个子词,在生成训练样本时,这些被分开的子词会随机被mask。
在全词Mask中,如果一个完整的词的部分WordPiece子词被mask,则同属该词的其他部分也会被mask,即全词Mask。这样的做法强制模型预测整个的词,而不是词的一部分,即对同一个词不同字符的预测将使得其具有相同的上下文,这将加强同一个词不同字符之间的相关性,或者说引入了先验知识,使得BERT的独立性假设在同一个词的预测上被打破,但又保证了不同的词之间的独立性。
作者将全词Mask的方法应用在了中文中,使用了中文维基百科(包括简体和繁体)进行训练,并且使用了哈工大LTP作为分词工具,即对组成同一个词的汉字全部进行Mask。这样一个简单的改进,使得同样规模的模型,在中文数据上的表现获得了全方位的提升
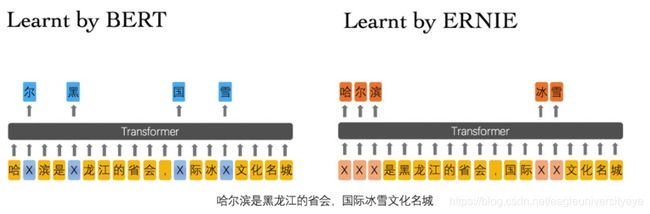
5. ERNIE
BERT在中文文本中的MLM预训练模型很容易使得模型提取到字搭配这种低层次的语义信息,而对于短语以及实体层次的语义信息抽取能力是较弱的。因此ERNIE将外部知识引入大规模预训练语言模型中,提高在知识驱动任务上的性能。具体有如下三个层次的预训练任务:
- Basic-Level Masking: 跟bert一样对单字进行mask,很难学习到高层次的语义信息;
- Phrase-Level Masking: 输入仍然是单字级别的,mask连续短语;
- Entity-Level Masking: 首先进行实体识别,然后将识别出的实体进行mask。
6. XLNET
传统的自回归语言模型天然适合处理生成任务,但是无法对双向上下文进行表征;而自编码语言模型虽然可以实现双向上下文进行表征,但是自编码语言模型的代表BERT系列模型引入独立性假设,没有考虑预测[MASK]之间的相关性;而且MLM预训练目标的设置造成预训练过程和生成过程不一致,导致在文本生成任务中自编码语言模型效果不佳。
XLNet是一种排列语言模型,它综合了自回归模型和自编码模型的优点,同时避免了他们的缺点。XLNet将输入序列的顺序打乱,然后预测的顺序还是按照原始的位置编码顺序来预测的,但是相应的上下文就是按照打乱顺序的上下文来看了,这样一来,预测对象词的时候,可以随机的看到上文信息和下文信息。
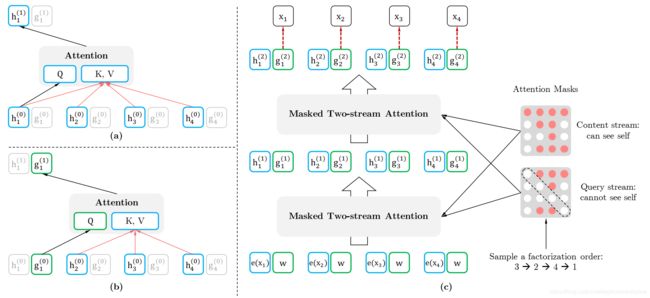
直接用标准的Transformer来建模PLM,会出现没有目标(target)位置信息的问题。即在打乱顺序之后,并不知道下一个要预测的词是一个什么词,这将导致用相同上文预测不同目标的概率是相同的。XLNet引入了双流自注意力机制(Two-Stream Self-Attention)来解决这个问题。
Two-Stream Self-Attention
Two-Stream Self-Attention有两个分离的Self-Attention信息流:
- Query Stream 就为了找到需要预测的当前词,这个信息流的Self-Attention的Query输入是仅包含预测词的位置信息,而Key和Value为上下文中包含内容信息和位置信息的输入,表明我们无法看见预测词的内容信息,该信息是需要我们去预测的;
- Content Stream 主要为 Query Stream 提供其它词的内容向量,其Query输入为包含预测词的内容信息和位置信息,Value和Key的输入为选中上下文的位置信息和内容信息;
两个信息流的输出同样又作为对应的下一层的双信息流的输入。而随机排列机制实际上是在内部用Mask Attention的机制实现的。
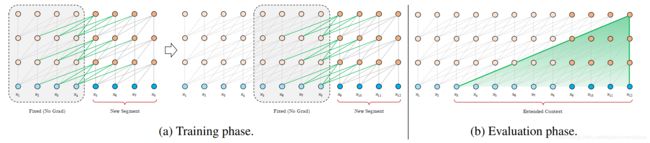
另外,XLNET没有直接使用Transformer作为特征抽取器,而是采用了Transformer的改进版Transformer-XL,其相比于传统的Transformer能捕获更长距离的单词依赖关系。
Transformer-XL
原始的Transformer的主要缺点在于,其在语言建模中会受到固定长度上下文的限制,从而无法捕捉到更长远的信息。Transformer-XL采用片段级递归机制(segment-level recurrence mechanism)和相对位置编码机制(relative positional encoding scheme)来对Transformer进行改进:
- 片段级递归机制:指的是当前时刻的隐藏信息在计算过程中,将通过循环递归的方式利用上一时刻较浅层的隐藏状态,这使得每次的计算将利用更大长度的上下文信息,大大增加了捕获长距离信息的能力。
- 相对位置编码:Transformer本身引入了三角函数向量作为位置编码向量。而Transformer-XL复用了上文的信息,这就导致位置编码出现重叠,因此采用了训练的方式得到相对位置编码向量。