【嵌入式】AI落地部署技能
- 针对不同平台对生成的模型进行转换,也就是俗称的parse、convert,即前端解释器
- 针对转化后的模型进行优化
- 在特定的平台(嵌入端或者服务端)成功运行已经转化好的模型
- 在模型可以运行的基础上,保证模型的速度、精度和稳定性
- 用C++、cuda写算子(预处理、op、后处理等等)去实现一些独特的算子
- 调bug、联合编译、动态静态库混搭
- 好用的开源推理框架:Caffe、
NCNN、MNN、TVM(移动端首选)、OpenVino(libtorch)、libtorch、PaddlePaddle- 好用的半开源推理框架:TensorRT(GPU服务器首选)
- 好用的开源服务器框架:triton-inference-server
- 基础知识:计算机原理、编译原理等
1. 模型结构
- 使用现有的网络结构
- 模型重参化: 训练时采用多分支的网络进行训练,尽可能利用多分支结构的优势来提升模型性能,而在使用时先进行一个等价转换,将多分支网络转换为一个单路网络,然后再进行推理使用,利用单路网络的优势提升推理的速度,从而实现高性能和高速度的平衡。
2. 剪枝
- yolov3-channel-and-layer-pruning[16]
- YOLOv3-model-pruning[17]
- centernet_prune[18]
- ResRep[19]
3. 蒸馏
- centerX[20]
4. 稀疏化训练
- 稀疏化就是随机将Tensor的部分元素置为0,类似于我们常见的dropout,附带正则化作用的同时也减少了模型的容量,从而加快了模型的推理速度。
def prune(model, amount=0.3):
# Prune model to requested global sparsity
import torch.nn.utils.prune as prune
print('Pruning model... ', end='')
for name, m in model.named_modules():
if isinstance(m, nn.Conv2d):
prune.l1_unstructured(m, name='weight', amount=amount) # prune
prune.remove(m, 'weight') # make permanent
print(' %.3g global sparsity' % sparsity(model))
5. 量化训练QTA(Quantization Aware Training)
-
量化后的模型在特定CPU或者GPU上相比FP32、FP16有更高的速度和吞吐,也是部署提速方法之一。
-
量化训练是在模型训练中量化的,与PTQ(训练后量化)不同, 这种量化方式对模型的精度影响不大,量化后的模型速度基本与量化前的相同(另一种量化方式PTQ,TensorRT或者NCNN中使用交叉熵进行校准量化的方式,在一些结构中会对模型的精度造成比较大的影响)。
-
Pytorch->ONNX->trt onnx2trt
-
NVIDIA 方案: r=s*q+b; r,s,b是浮点数,q是int8 类型定点数。b可以去掉而没有明显精度损失; r=s * q
-
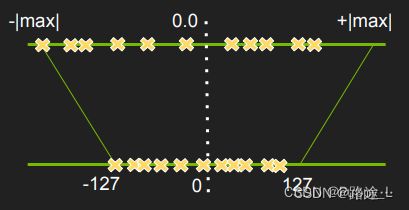
Google 方案: r=S(q-Z);S是scaling factor,浮点数;Z是零点,是一个定点数; 为求得scaling factor,我们需要知道r rr的最大值与最小值,分别记为r m a x r_{max}rmax和r m i n r_{min}rmin。同样地,q qq也有最大值与最小值,记为q m a x q_{max}qmax和q m i n q_{min}qmin。q qq的位宽虽然是8比特,但是可能是有符号形式或者无符号形式,因此取值范围不同。对于无符号形式,取值范围为[ q m i n , q m a x ] = [ 0 , 255 ] [q_{min},q_{max}]=[0,255][qmin,qmax]=[0,255];无符号形式有[ q m i n , q m a x ] = [ − 128 , 127 ] [q_{min},q_{max}]=[-128,127][qmin,qmax]=[−128,127]。
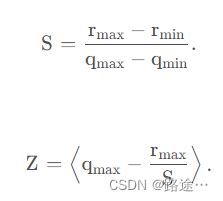
1. pytorch量化-Dynamic quantization
- 动态量化是对权重进行线下量化,即拿到训练好的浮点模型后量化权重。但是对于activation,是根据推理过程中activation的取值范围进行量化,这意味着同一个模型在处理不同输入图片时,activation采用的量化参数很可能是不一样的。
- 系统自动选择最合适的scale (标度)和 zero_point(零点位置),不需要自定义。量化后的模型,可以推理运算,但不能训练(不能反向传播)

import torch
# define a floating point model
class M(torch.nn.Module):
def __init__(self):
super().__init__()
self.fc = torch.nn.Linear(4, 4)
def forward(self, x):
x = self.fc(x)
return x
# create a model instance
model_fp32 = M()
# create a quantized model instance
model_int8 = torch.quantization.quantize_dynamic(
model_fp32, # the original model
{torch.nn.Linear}, # a set of layers to dynamically quantize
dtype=torch.qint8) # the target dtype for quantized weights
# run the model
input_fp32 = torch.randn(4, 4, 4, 4)
res = model_int8(input_fp32)
# import the modules used here in this recipe
import torch
import torch.quantization
import torch.nn as nn
import copy
import os
import time
# define a very, very simple LSTM for demonstration purposes
# in this case, we are wrapping nn.LSTM, one layer, no pre or post processing
# inspired by
# https://pytorch.org/tutorials/beginner/nlp/sequence_models_tutorial.html, by Robert Guthrie
# and https://pytorch.org/tutorials/advanced/dynamic_quantization_tutorial.html
class lstm_for_demonstration(nn.Module):
"""Elementary Long Short Term Memory style model which simply wraps nn.LSTM
Not to be used for anything other than demonstration.
"""
def __init__(self,in_dim,out_dim,depth):
super(lstm_for_demonstration,self).__init__()
self.lstm = nn.LSTM(in_dim,out_dim,depth)
def forward(self,inputs,hidden):
out,hidden = self.lstm(inputs,hidden)
return out, hidden
torch.manual_seed(29592) # set the seed for reproducibility
#shape parameters
model_dimension=8
sequence_length=20
batch_size=1
lstm_depth=1
# random data for input
inputs = torch.randn(sequence_length,batch_size,model_dimension)
# hidden is actually is a tuple of the initial hidden state and the initial cell state
hidden = (torch.randn(lstm_depth,batch_size,model_dimension), torch.randn(lstm_depth,batch_size,model_dimension))
torch.quantization.quantize_dynamic()
# here is our floating point instance
float_lstm = lstm_for_demonstration(model_dimension, model_dimension,lstm_depth)
# this is the call that does the work
quantized_lstm = torch.quantization.quantize_dynamic( #在这里调用函数不一样
float_lstm, {nn.LSTM, nn.Linear}, dtype=torch.qint8
)
def print_size_of_model(model, label=""):
torch.save(model.state_dict(), "temp.p")
size=os.path.getsize("temp.p")
print("model: ",label,' \t','Size (KB):', size/1e3)
os.remove('temp.p')
return size
# compare the sizes
f=print_size_of_model(float_lstm,"fp32")
q=print_size_of_model(quantized_lstm,"int8")
print("{0:.2f} times smaller".format(f/q))
out1, hidden1 = float_lstm(inputs, hidden)
mag1 = torch.mean(abs(out1)).item()
print('mean absolute value of output tensor values in the FP32 model is {0:.5f} '.format(mag1))
# run the quantized model
out2, hidden2 = quantized_lstm(inputs, hidden)
mag2 = torch.mean(abs(out2)).item()
print('mean absolute value of output tensor values in the INT8 model is {0:.5f}'.format(mag2))
# compare them
mag3 = torch.mean(abs(out1-out2)).item()
print('mean absolute value of the difference between the output tensors is {0:.5f} or {1:.2f} percent'.format(mag3,mag3/mag1*100))
- https://pytorch.org/docs/stable/quantization.html#post-training-dynamic-quantization
- https://pytorch.org/tutorials/recipes/recipes/dynamic_quantization.html
2. pytorch量化-Static quantization
- 量化后的模型,不能训练(不能反向传播),也不能推理,需要解量化后,才能进行运算
- 量化与反量化模块的添加:QuantStub(),DeQuantStub()
- 加法以及concatenate单元的量化替换
- 模块融合
# original model
# all tensors and computations are in floating point
previous_layer_fp32 -- linear_fp32 -- activation_fp32 -- next_layer_fp32
/
linear_weight_fp32
# statically quantized model
# weights and activations are in int8
previous_layer_int8 -- linear_with_activation_int8 -- next_layer_int8
/
linear_weight_int8
import torch
# define a floating point model where some layers could be statically quantized
class M(torch.nn.Module):
def __init__(self):
super().__init__()
# QuantStub converts tensors from floating point to quantized
self.quant = torch.quantization.QuantStub()
self.conv = torch.nn.Conv2d(1, 1, 1)
self.relu = torch.nn.ReLU()
# DeQuantStub converts tensors from quantized to floating point
self.dequant = torch.quantization.DeQuantStub()
def forward(self, x):
# manually specify where tensors will be converted from floating
# point to quantized in the quantized model
x = self.quant(x)
x = self.conv(x)
x = self.relu(x)
# manually specify where tensors will be converted from quantized
# to floating point in the quantized model
x = self.dequant(x)
return x
# create a model instance
model_fp32 = M()
# model must be set to eval mode for static quantization logic to work
model_fp32.eval()
# attach a global qconfig, which contains information about what kind
# of observers to attach. Use 'fbgemm' for server inference and
# 'qnnpack' for mobile inference. Other quantization configurations such
# as selecting symmetric or assymetric quantization and MinMax or L2Norm
# calibration techniques can be specified here.
model_fp32.qconfig = torch.quantization.get_default_qconfig('fbgemm')
# Fuse the activations to preceding layers, where applicable.
# This needs to be done manually depending on the model architecture.
# Common fusions include `conv + relu` and `conv + batchnorm + relu`
model_fp32_fused = torch.quantization.fuse_modules(model_fp32, [['conv', 'relu']])
# Prepare the model for static quantization. This inserts observers in
# the model that will observe activation tensors during calibration.
model_fp32_prepared = torch.quantization.prepare(model_fp32_fused)
# calibrate the prepared model to determine quantization parameters for activations
# in a real world setting, the calibration would be done with a representative dataset
input_fp32 = torch.randn(4, 1, 4, 4)
model_fp32_prepared(input_fp32)
# Convert the observed model to a quantized model. This does several things:
# quantizes the weights, computes and stores the scale and bias value to be
# used with each activation tensor, and replaces key operators with quantized
# implementations.
model_int8 = torch.quantization.convert(model_fp32_prepared)
# run the model, relevant calculations will happen in int8
res = model_int8(input_fp32)
- https://pytorch.org/docs/stable/quantization.html#post-training-static-quantization
from torch.quantization import QuantStub, DeQuantStub
def _make_divisible(v, divisor, min_value=None):
"""
This function is taken from the original tf repo.
It ensures that all layers have a channel number that is divisible by 8
It can be seen here:
https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
:param v:
:param divisor:
:param min_value:
:return:
"""
if min_value is None:
min_value = divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_v < 0.9 * v:
new_v += divisor
return new_v
class ConvBNReLU(nn.Sequential):
def __init__(self, in_planes, out_planes, kernel_size=3, stride=1, groups=1):
padding = (kernel_size - 1) // 2
super(ConvBNReLU, self).__init__(
nn.Conv2d(in_planes, out_planes, kernel_size, stride, padding, groups=groups, bias=False),
nn.BatchNorm2d(out_planes, momentum=0.1),
# Replace with ReLU
nn.ReLU(inplace=False)
)
class InvertedResidual(nn.Module):
def __init__(self, inp, oup, stride, expand_ratio):
super(InvertedResidual, self).__init__()
self.stride = stride
assert stride in [1, 2]
hidden_dim = int(round(inp * expand_ratio))
self.use_res_connect = self.stride == 1 and inp == oup
layers = []
if expand_ratio != 1:
# pw
layers.append(ConvBNReLU(inp, hidden_dim, kernel_size=1))
layers.extend([
# dw
ConvBNReLU(hidden_dim, hidden_dim, stride=stride, groups=hidden_dim),
# pw-linear
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup, momentum=0.1),
])
self.conv = nn.Sequential(*layers)
# Replace torch.add with floatfunctional
self.skip_add = nn.quantized.FloatFunctional()
def forward(self, x):
if self.use_res_connect:
return self.skip_add.add(x, self.conv(x))
else:
return self.conv(x)
class MobileNetV2(nn.Module):
def __init__(self, num_classes=1000, width_mult=1.0, inverted_residual_setting=None, round_nearest=8):
"""
MobileNet V2 main class
Args:
num_classes (int): Number of classes
width_mult (float): Width multiplier - adjusts number of channels in each layer by this amount
inverted_residual_setting: Network structure
round_nearest (int): Round the number of channels in each layer to be a multiple of this number
Set to 1 to turn off rounding
"""
super(MobileNetV2, self).__init__()
block = InvertedResidual
input_channel = 32
last_channel = 1280
if inverted_residual_setting is None:
inverted_residual_setting = [
# t, c, n, s
[1, 16, 1, 1],
[6, 24, 2, 2],
[6, 32, 3, 2],
[6, 64, 4, 2],
[6, 96, 3, 1],
[6, 160, 3, 2],
[6, 320, 1, 1],
]
# only check the first element, assuming user knows t,c,n,s are required
if len(inverted_residual_setting) == 0 or len(inverted_residual_setting[0]) != 4:
raise ValueError("inverted_residual_setting should be non-empty "
"or a 4-element list, got {}".format(inverted_residual_setting))
# building first layer
input_channel = _make_divisible(input_channel * width_mult, round_nearest)
self.last_channel = _make_divisible(last_channel * max(1.0, width_mult), round_nearest)
features = [ConvBNReLU(3, input_channel, stride=2)]
# building inverted residual blocks
for t, c, n, s in inverted_residual_setting:
output_channel = _make_divisible(c * width_mult, round_nearest)
for i in range(n):
stride = s if i == 0 else 1
features.append(block(input_channel, output_channel, stride, expand_ratio=t))
input_channel = output_channel
# building last several layers
features.append(ConvBNReLU(input_channel, self.last_channel, kernel_size=1))
# make it nn.Sequential
self.features = nn.Sequential(*features)
self.quant = QuantStub()
self.dequant = DeQuantStub()
# building classifier
self.classifier = nn.Sequential(
nn.Dropout(0.2),
nn.Linear(self.last_channel, num_classes),
)
# weight initialization
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.BatchNorm2d):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.zeros_(m.bias)
def forward(self, x):
x = self.quant(x)
x = self.features(x)
x = x.mean([2, 3])
x = self.classifier(x)
x = self.dequant(x)
return x
# Fuse Conv+BN and Conv+BN+Relu modules prior to quantization
# This operation does not change the numerics
def fuse_model(self):
for m in self.modules():
if type(m) == ConvBNReLU:
torch.quantization.fuse_modules(m, ['0', '1', '2'], inplace=True)
if type(m) == InvertedResidual:
for idx in range(len(m.conv)):
if type(m.conv[idx]) == nn.Conv2d:
torch.quantization.fuse_modules(m.conv, [str(idx), str(idx + 1)], inplace=True)
- 在forward中添加了量化和反量化函数
- 将浮点模型的加法x + self.conv(x)替换为skip_add.add(x, self.conv(x))
3. pytorch量化-Quantization aware quantization
- 系统自动选择最合适的scale (标度)和 zero_point(零点位置),不需要自定义。但这是一种伪量化,量化后的模型权重仍然是32位浮点数,但大小和8位定点数权重的大小相同。伪量化后的模型可以进行训练。虽然是以32位浮点数进行的训练,但结果与8位定点数的结果一致。

import torch
# define a floating point model where some layers could benefit from QAT
class M(torch.nn.Module):
def __init__(self):
super().__init__()
# QuantStub converts tensors from floating point to quantized
self.quant = torch.quantization.QuantStub()
self.conv = torch.nn.Conv2d(1, 1, 1)
self.bn = torch.nn.BatchNorm2d(1)
self.relu = torch.nn.ReLU()
# DeQuantStub converts tensors from quantized to floating point
self.dequant = torch.quantization.DeQuantStub()
def forward(self, x):
x = self.quant(x)
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
x = self.dequant(x)
return x
# create a model instance
model_fp32 = M()
# model must be set to eval for fusion to work
model_fp32.eval()
# attach a global qconfig, which contains information about what kind
# of observers to attach. Use 'fbgemm' for server inference and
# 'qnnpack' for mobile inference. Other quantization configurations such
# as selecting symmetric or assymetric quantization and MinMax or L2Norm
# calibration techniques can be specified here.
model_fp32.qconfig = torch.quantization.get_default_qat_qconfig('fbgemm')
# fuse the activations to preceding layers, where applicable
# this needs to be done manually depending on the model architecture
model_fp32_fused = torch.quantization.fuse_modules(model_fp32,
[['conv', 'bn', 'relu']])
# Prepare the model for QAT. This inserts observers and fake_quants in
# the model needs to be set to train for QAT logic to work
# the model that will observe weight and activation tensors during calibration.
model_fp32_prepared = torch.quantization.prepare_qat(model_fp32_fused.train())
# run the training loop (not shown)
training_loop(model_fp32_prepared)
# Convert the observed model to a quantized model. This does several things:
# quantizes the weights, computes and stores the scale and bias value to be
# used with each activation tensor, fuses modules where appropriate,
# and replaces key operators with quantized implementations.
model_fp32_prepared.eval()
model_int8 = torch.quantization.convert(model_fp32_prepared)
# run the model, relevant calculations will happen in int8
res = model_int8(input_fp32)
- https://pytorch.org/docs/stable/quantization.html#quantization-aware-training-for-static-quantization
6. 算子融合
- 算子拆解、算子聚合、算子重建,以便达到在硬件设备上更好的性能。
- 比如常见Conv+ReLu的两个算子,因为Conv需要做大量卷积计算,需要密集的计算单元支持,而Relu几乎不需要计算,如果Relu算子单独运算,则不仅需要一个计算单元支持其实不需要怎么计算的算子,同时又要对前端的数据进行一次读操作,很浪费资源和增加I/O操作; 此时,可以将Conv和Relu合并融合成一个算子,可以节省I/O访问和带宽开销,也可以节省计算单元。
7. 计算图优化
- 在计算图中,存在某些算子是串行依赖,而某些算子是不依赖性;这些相互独立的子计算图,就可以进行并行计算,提高推理速度,这就是计算图的调度。
8. 底层优化
.1. 内存优化
- 静态内存分配:比如一些固定的算子在整个计算图中都会使用,此时需要再模型初始化时一次性申请完内存空间,在实际推理时不需要频繁申请操作,提高性能
- 动态内存分配:对于中间临时的内存需求,可以进行临时申请和释放,节省内存使用,提高模型并发能力
- 内存复用:对于同一类同一个大小的内存形式,又满足临时性,可以复用内存地址,减少内存申请。