【序列标注】kaggle实战系列-序列标注
数据:来自于98年人民日报
NER语料
环境:TensorFlow 1.13.1
模型:BiLSTM-CRF
目录
- 一、任务描述
- 二、数据说明
- 三、模型架构概述
-
- 模型结构
- 模型实现细节
- 四、代码
一、任务描述
用seq_tag/data_path 中的数据训练模型,来完成序列标注任务(命名实体识别),识别出文本中的人名、地名和组织机构名。
二、数据说明
注:该数据集为小规模中文数据集,来自于98年人民日报NER语料
1.标签说明
{ B-PER:人名开始; I-PER:人名中间 ;B-LOC:地名开始, I-LOC:地名中间; B-ORG:机构名开始 ;I-ORG:机构名中间;O:其他 }
2.数据集格式说明
训练语料:
train_corpus.txt 文件为训练文本:

train_label.txt 文件为训练文本对应的每个字的标签:
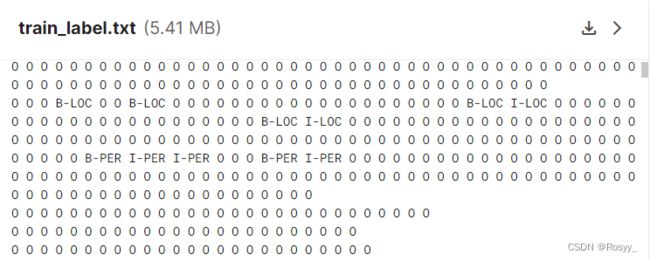
如“周恩来”这个人名实体对应的标签B-PER, I-PER, I-PER。
测试语料:
test_corpus.txt 文件为测试文本,test_label.txt 文件为对应的标签,格式同上。
3.评价指标
采用准确率、召回率以及F1值来进行模型评价。
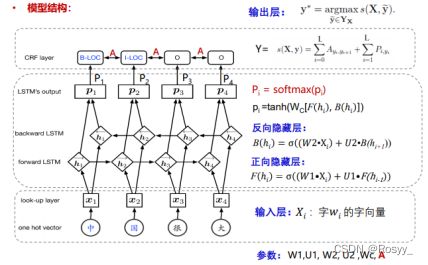
三、模型架构概述
输入层通过embedding获得词向量,表示层选择BiLSTM对词向量进行加工和表示,输出层未直接使用softmax来直接获得词对应的标签,而是通过CRF使得标注精度更高。

模型结构
模型实现细节
Word Embedding功能及完整思路:
1). 将训练数据集train_corpus.txt、train_label.txt进行遍历得到词典{字:[id, 出现次数]},id为字对应的标签: {“O”:0;“B-PER”:1; “I-PER”:2 ; “B-LOC”:3; “I-LOC”:4; “B-ORG”:5; “I-ORG”:6} ,将7种标签转化为对应数字类型,便于模型处理;
2)设定出现次数阈值,去除词典中的低频词,重新生成词典{字:id},这里丢弃低频词之后,出现次数便不再需要记录了;
3)对于训练数据中的每条语句,利用上一步生成的词典,将句子转化为id序列,再将所有的句子按照最长的一句话进行padding,得到句子的向量表示。
BiLSTM-CRF层功能及完整思路:
1). 功能:使用双向长短期记忆网络LSTM加条件随机场CRF的方式解决文本标注的问题,LSTM是RNN的加强版,主要解决RNN对距离较远文本之间关联较差的问题,其单向性也成为了相比于BiLSTM的不足之处。
2). BiLSTM模型更好地利用了文本上下文中的信息,相较于之前的模型LSTM,从上下文中获取了更多信息,从而减小了对词向量的依赖。但它也存在十分明显的缺点,其最终输出依赖于softmax输出概率最大的标签,使得相邻输出标签之间可能存在没有实际意义的连续标签。这个问题可以通用CRF来解决。
3). CRF计算整个标记序列的联合概率分布,优势是考虑了标签间的关系。
4). LSTM-CRF结合了上述两种模型。CRF将状态转移矩阵作为参数,并使用之前和之后的标签预测当前标签。
四、代码
环境配置:
!pip install tensorflow==1.13.1
如果环境有问题,kaggle终端使用conda init --user来初始化环境,再重新配置。
对应:data.py,kaggle支持markdown,可以依次输入代码块,无需导包。
import sys, pickle, os, random
import numpy as np
#第一步:数据处理
#pikle是一个将任意复杂的对象转成对象的文本或二进制表示的过程。
#同样,必须能够将对象经过序列化后的形式恢复到原有的对象。
#在 Python 中,这种序列化过程称为 pickle,
#可以将对象 pickle 成字符串、磁盘上的文件或者任何类似于文件的对象,
#也可以将这些字符串、文件或任何类似于文件的对象 unpickle 成原来的对象。
## tags, BIO
tag2label = {"O": 0,
"B-PER": 1, "I-PER": 2,
"B-LOC": 3, "I-LOC": 4,
"B-ORG": 5, "I-ORG": 6
}
#输入train_data文件的路径,读取训练集的语料,输出train_data
def read_corpus(corpus_path):
"""
read corpus and return the list of samples
:param corpus_path:
:return: data
"""
data = []
with open(corpus_path, encoding='utf-8') as fr:
'''lines的形状为['北\tB-LOC\n','京\tI-LOC\n','的\tO\n','...']总共有2220537个字及对应的tag'''
lines = fr.readlines()
sent_, tag_ = [], []
for line in lines:
if line != '\n':#每句话之间以换行符为区分
# char 与 label之间有个空格
# line.strip()的意思是去掉每句话句首句尾的空格
# .split()的意思是根据空格来把整句话切割成一片片独立的字符串放到数组中,同时删除句子中的换行符号\n
[char, label] = line.strip().split()
# 把一个个的字放进sent_
sent_.append(char)
# 把字后面的tag放进tag_
tag_.append(label)
else:#一句话结束了,添加到data
data.append((sent_, tag_))
sent_, tag_ = [], []
""" data的形状为[(['我',在'北','京'],['O','O','B-LOC','I-LOC'])...第一句话
(['我',在'天','安','门'],['O','O','B-LOC','I-LOC','I-LOC'])...第二句话
( 第三句话 ) ] 总共有50658句话"""
return data
#由train_data来构造一个(统计非重复字)字典{'第一个字':[对应的id,该字出现的次数],'第二个字':[对应的id,该字出现的次数], , ,}
#去除低频词,生成一个word_id的字典并保存在输入的vocab_path的路径下,
#保存的方法是pickle模块自带的dump方法,保存后的文件格式是word2id.pkl文件
def vocab_build(vocab_path, corpus_path, min_count):
"""
:param vocab_path:
:param corpus_path:
:param min_count:
:return:
"""
data = read_corpus(corpus_path)
word2id = {}
#sent_的形状为['我','在','北','京'],对应的tag_为['O','O','B-LOC','I-LOC']
for sent_, tag_ in data:
for word in sent_:
# 如果字符串只包含数字则返回 True 否则返回 False。
if word.isdigit():
word = ''
#A-Z:(\u0041-\u005a) a-z :\u0061-\u007a
elif ('\u0041' <= word <='\u005a') or ('\u0061' <= word <='\u007a'):
word = ''
if word not in word2id:#是新词
# [len(word2id)+1, 1]用来统计[位置标签,出现次数],第一次出现定为1
word2id[word] = [len(word2id)+1, 1]#[对应的id,出现的次数]
else:#不是新词
# word2id[word][1]实现对词频的统计,出现次数累加1
word2id[word][1] += 1
#其实前面统计词频的目的就是这里删除低频词,删除完之后也就不用统计词频了
#用来统计低频词
low_freq_words = []
for word, [word_id, word_freq] in word2id.items():
#寻找低于某个数字的低频词
if word_freq < min_count and word != '' and word != '' :
low_freq_words.append(word)
for word in low_freq_words:
# 把这些低频词从字典中删除
del word2id[word]
# 删除低频词后为每个字重新建立id,而不再统计词频
new_id = 1
for word in word2id.keys():
word2id[word] = new_id
new_id += 1
word2id['' ] = new_id
word2id['' ] = 0
print(len(word2id))
with open(vocab_path, 'wb') as fw:
# 序列化到名字为word2id.pkl文件
pickle.dump(word2id, fw)
#输入一句话,生成一个 sentence_id
'''sentence_id的形状为[1,2,3,4,...]对应的sent为['当','希','望','工',程'...]'''
def sentence2id(sent, word2id):
"""
:param sent:
:param word2id:
:return:
"""
sentence_id = []
for word in sent:
if word.isdigit():
word = ''
elif ('\u0041' <= word <= '\u005a') or ('\u0061' <= word <= '\u007a'):
word = ''
if word not in word2id:
word = ''
sentence_id.append(word2id[word])
return sentence_id
#通过pickle模块自带的load方法(反序列化方法)加载输出word2id
def read_dictionary(vocab_path):
"""
:param vocab_path:
:return:
"""
vocab_path = os.path.join(vocab_path)
with open(vocab_path, 'rb') as fr:
#反序列化方法加载输出
word2id = pickle.load(fr)
print('vocab_size:', len(word2id))
return word2id
'''word2id的形状为{'当': 1, '希': 2, '望': 3, '工': 4, '程': 5,。。'<UNK>': 3904, '<PAD>': 0}
总共3903个字'''
#输入vocab,vocab就是前面得到的word2id,embedding_dim=300
def random_embedding(vocab, embedding_dim):
"""
:param vocab:
:param embedding_dim:
:return:
"""
# 返回一个len(vocab)*embedding_dim=3905*300的矩阵(每个字投射到300维)作为初始值
#numpy.random.uniform(low,high,size)功能:从一个均匀分布[low,high)中随机采样,注意定义域是左闭右开,即包含low,不包含high.
# 参数介绍:
#
# low: 采样下界,float类型,默认值为0;
# high: 采样上界,float类型,默认值为1;
# size: 输出样本数目,为int或元组(tuple)
# 类型,例如,size = (m, n, k), 则输出m * n * k个样本,缺省时输出1个值。
#
# 返回值:ndarray类型,其形状和参数size中描述一致。
embedding_mat = np.random.uniform(-0.25, 0.25, (len(vocab), embedding_dim))
embedding_mat = np.float32(embedding_mat)
return embedding_mat
#padding,输入一句话,不够标准的样本用pad_mark来补齐
'''
输入:seqs的形状为二维矩阵,形状为[[33,12,17,88,50]-第一句话
[52,19,14,48,66,31,89]-第二句话
]
输出:seq_list为seqs经过padding后的序列
seq_len_list保留了padding之前每条样本的真实长度
seq_list和seq_len_list用来喂给feed_dict
'''
def pad_sequences(sequences, pad_mark=0):
"""
:param sequences:
:param pad_mark:
:return:
"""
# 返回一个序列中长度最长的那条样本的长度
max_len = max(map(lambda x : len(x), sequences))
seq_list, seq_len_list = [], []
for seq in sequences:
# 由元组格式()转化为列表格式[]
seq = list(seq)
# 不够最大长度的样本用0补上放到列表seq_list
seq_ = seq[:max_len] + [pad_mark] * max(max_len - len(seq), 0)
#seq_list为sequences经过padding后的序列
seq_list.append(seq_)
# seq_len_list用来统计每个样本的真实长度
seq_len_list.append(min(len(seq), max_len))
return seq_list, seq_len_list
#生成batch
''' seqs的形状为二维矩阵,形状为[[33,12,17,88,50....]...第一句话
[52,19,14,48,66....]...第二句话
]
labels的形状为二维矩阵,形状为[[0, 0, 3, 4]....第一句话
[0, 0, 3, 4]...第二句话
]
'''
def batch_yield(data, batch_size, vocab, tag2label, shuffle=False):
"""
:param data:
:param batch_size:
:param vocab:
:param tag2label:
:param shuffle:
:return:
"""
if shuffle:
random.shuffle(data)
seqs, labels = [], []
for (sent_, tag_) in data:#data形状[(['我',在'北','京'],['O','O','B-LOC','I-LOC']),...]
# sent_的形状为[33,12,17,88,50....]句中的字在Wordid对应的位置标签
# 如果tag_形状为['O','O','B-LOC','I-LOC'],对应的label_形状为[0, 0, 3, 4]
# 返回tag2label字典中每个tag对应的value值
'''sentence_id的形状为[1,2,3,4,...]对应的sent为['当','希','望','工',程'...]'''
sent_ = sentence2id(sent_, vocab)#返回id如[1,2,3,4,...]
# 如果tag_形状为['O','O','B-LOC','I-LOC'],对应的label_形状为[0, 0, 3, 4]
label_ = [tag2label[tag] for tag in tag_]
# 保证了seqs的长度为batch_size
if len(seqs) == batch_size:
yield seqs, labels
seqs, labels = [], []
seqs.append(sent_)#seqs如[[1,2,3,4],……]剧中词语的标号
labels.append(label_)#abel_形状为[0, 0, 3, 4]#剧中词语的标签
if len(seqs) != 0:
yield seqs, labels
#执行vocab_build
vocab_path = './word2id.pkl'
corpus_path = '../input/seq-tag/data_path/train_data.txt'
vocab_build(vocab_path, corpus_path, 3)
对应:utils.py
import logging, sys, argparse
#第二步
def str2bool(v):
# copy from StackOverflow
if v.lower() in ('yes', 'true', 't', 'y', '1'):
return True
elif v.lower() in ('no', 'false', 'f', 'n', '0'):
return False
else:
# 首先被内层IOError异常捕获,打印“inner exception”, 然后把相同的异常再抛出,
# 被外层的except捕获,打印"outter exception"
raise argparse.ArgumentTypeError('Boolean value expected.')
#根据输入的tag返回对应的字符
def get_entity(tag_seq, char_seq): #['B-PER', 'I-PER', 0, 0, 0, 0, 'B-LOC', 'I-LOC', 0, 'B-ORG', 'I-ORG', 'I-ORG', 'I-ORG'],['小', '明', '的', '大', '学', '在', '北', '京', '的', '北', '京', '大', '学']
PER = get_PER_entity(tag_seq, char_seq)
LOC = get_LOC_entity(tag_seq, char_seq)
ORG = get_ORG_entity(tag_seq, char_seq)
return PER, LOC, ORG
#输出PER对应的字符
def get_PER_entity(tag_seq, char_seq):
length = len(char_seq)#句子长度
PER = []
# 构成一个zip对象,形状类似[( 1, ),( 1, ),( 2, ),( 2, )]
# zip函数可以接受一系列的可迭代对象作为参数,将对象中对应的元素打包成一个个tuple(元组),
# 在zip函数的括号里面加上*号,则是zip函数的逆操作
for i, (char, tag) in enumerate(zip(char_seq, tag_seq)):#如小 B-PER
# tag里包含了O,B-PER,I-PER,B-LOCI-PER,B-ORG,I-PER
if tag == 'B-PER':
if 'per' in locals().keys():#把上一个名字加进去,这样才能继续往里面添加
PER.append(per)
del per
per = char
if i+1 == length:#说明这个名字就一个字
PER.append(per)
if tag == 'I-PER':
per += char
if i+1 == length:
PER.append(per)
if tag not in ['I-PER', 'B-PER']:
if 'per' in locals().keys():
PER.append(per)
del per
continue
return PER
#输出LOC对应的字符
def get_LOC_entity(tag_seq, char_seq):
length = len(char_seq)
LOC = []
for i, (char, tag) in enumerate(zip(char_seq, tag_seq)):
if tag == 'B-LOC':
if 'loc' in locals().keys():
LOC.append(loc)
del loc
loc = char
if i+1 == length:
LOC.append(loc)
if tag == 'I-LOC':
loc += char
if i+1 == length:
LOC.append(loc)
if tag not in ['I-LOC', 'B-LOC']:
if 'loc' in locals().keys():
LOC.append(loc)
del loc
continue
return LOC
#输出ORG对应的字符
def get_ORG_entity(tag_seq, char_seq):
length = len(char_seq)
ORG = []
for i, (char, tag) in enumerate(zip(char_seq, tag_seq)):
if tag == 'B-ORG':
if 'org' in locals().keys():
ORG.append(org)
del org
org = char
if i+1 == length:
ORG.append(org)
if tag == 'I-ORG':
org += char
if i+1 == length:
ORG.append(org)
if tag not in ['I-ORG', 'B-ORG']:
if 'org' in locals().keys():
ORG.append(org)
del org
continue
return ORG
#记录日志
def get_logger(filename):
logger = logging.getLogger('logger')
logger.setLevel(logging.DEBUG)
logging.basicConfig(format='%(message)s', level=logging.DEBUG)
handler = logging.FileHandler(filename)
handler.setLevel(logging.DEBUG)
handler.setFormatter(logging.Formatter('%(asctime)s:%(levelname)s: %(message)s'))
logging.getLogger().addHandler(handler)
return logger
对应:model.py
import numpy as np
import os, time, sys
import tensorflow as tf
from tensorflow.contrib.rnn import LSTMCell
from tensorflow.contrib.crf import crf_log_likelihood
from tensorflow.contrib.crf import viterbi_decode
# from data import pad_sequences, batch_yield
# from utils import get_logger
# from eval import conlleval
#第三步:设置模型
class BiLSTM_CRF(object):
def __init__(self, args, embeddings, tag2label, vocab, paths, config):
#批次大小
self.batch_size = args.batch_size
self.epoch_num = args.epoch
self.hidden_dim = args.hidden_dim
self.embeddings = embeddings
self.CRF = args.CRF#True
self.update_embedding = args.update_embedding
#drop操作参数
self.dropout_keep_prob = args.dropout
self.optimizer = args.optimizer#Adam
self.lr = args.lr
self.clip_grad = args.clip
self.tag2label = tag2label
self.num_tags = len(tag2label)
#tag2label = {"O": 0,
# "B-PER": 1, "I-PER": 2,
# "B-LOC": 3, "I-LOC": 4,
# "B-ORG": 5, "I-ORG": 6
# }
self.vocab = vocab
self.shuffle = args.shuffle
self.model_path = paths['model_path']
self.summary_path = paths['summary_path']
self.logger = get_logger(paths['log_path'])
self.result_path = paths['result_path']
self.config = config
def build_graph(self):
#占位符
self.add_placeholders()
self.lookup_layer_op()
self.biLSTM_layer_op()
self.softmax_pred_op()
#损失函数
self.loss_op()
self.trainstep_op()
#初始化所有变量
self.init_op()
def add_placeholders(self):
self.word_ids = tf.placeholder(tf.int32, shape=[None, None], name="word_ids")
#真实的标签序列
self.labels = tf.placeholder(tf.int32, shape=[None, None], name="labels")
#一个样本真实的序列长度
self.sequence_lengths = tf.placeholder(tf.int32, shape=[None], name="sequence_lengths")
#dropout
self.dropout_pl = tf.placeholder(dtype=tf.float32, shape=[], name="dropout")
#学习率
self.lr_pl = tf.placeholder(dtype=tf.float32, shape=[], name="lr")
def lookup_layer_op(self):
with tf.variable_scope("words"):
_word_embeddings = tf.Variable(self.embeddings,#3905*300的矩阵,矩阵元素均在-0.25到0.25之间
dtype=tf.float32,
trainable=self.update_embedding,#默认是True,如果为True,则会默认将变量添加到图形集合GraphKeys.TRAINABLE_VARIABLES中。此集合用于优化器Optimizer类优化的的默认变量列表【可为optimizer指定其他的变量集合】,可就是要训练的变量列表。这样的话在训练的过程中就会改变值
name="_word_embeddings")
word_embeddings = tf.nn.embedding_lookup(params=_word_embeddings,#
ids=self.word_ids,
name="word_embeddings")
# params: 表示完整的嵌入张量,或者除了第一维度之外具有相同形状的P个张量的列表,表示经分割的嵌入张量
#
# ids: 一个类型为int32或int64的Tensor,包含要在params中查找的id
#
# partition_strategy: 指定分区策略的字符串,如果len(params) > 1,则相关。当前支持“div”和“mod”。 默认为“mod”
#
# name: 操作名称(可选)
#
# validate_indices: 是否验证收集索引
#
# max_norm: 如果不是None,嵌入值将被l2归一化为max_norm的值
#
#
#
# tf.nn.embedding_lookup()
# 函数的用法主要是选取一个张量里面索引对应的元素
#
# tf.nn.embedding_lookup(tensor, id):即tensor就是输入的张量,id
# 就是张量对应的索引
#更完整的信息 https://blog.csdn.net/yangfengling1023/article/details/82910951
self.word_embeddings = tf.nn.dropout(word_embeddings, self.dropout_pl)
print('model 93行:')
print(self.word_embeddings.shape)
print('model 97:')
print(self.word_ids)
def biLSTM_layer_op(self):
#关于tf.variable_scope和tf.get_variable:https://blog.csdn.net/zSean/article/details/75057806
with tf.variable_scope("bi-lstm"):
cell_fw = LSTMCell(self.hidden_dim)#隐藏层神经元,默认300
cell_bw = LSTMCell(self.hidden_dim)
# def bidirectional_dynamic_rnn(
# cell_fw, # 前向RNN
# cell_bw, # 后向RNN
# inputs, # 输入
# sequence_length=None, # 输入序列的实际长度(可选,默认为输入序列的最大长度)
# initial_state_fw=None, # 前向的初始化状态(可选)
# initial_state_bw=None, # 后向的初始化状态(可选)
# dtype=None, # 初始化和输出的数据类型(可选)
# parallel_iterations=None,
# swap_memory=False,
# time_major=False,
# # 决定了输入输出tensor的格式:如果为true, 向量的形状必须为 `[max_time, batch_size, depth]`.
# # 如果为false, tensor的形状必须为`[batch_size, max_time, depth]`.
# scope=None
# )
#outputs为(output_fw, output_bw),是一个包含前向cell输出tensor和后向cell输出tensor组成的二元组。
# 如果time_major == False(默认值), 则output_fw将是形状为[batch_size, max_time, cell_fw.output_size]
# 的张量, 则output_bw将是形状为[batch_size, max_time, cell_bw.output_size]
# 的张量;
# 如果time_major == True, 则output_fw将是形状为[max_time, batch_size, cell_fw.output_size]
# 的张量;output_bw将会是形状为[max_time, batch_size, cell_bw.output_size]
# 的张量.
# 与bidirectional_rnn不同, 它返回一个元组而不是单个连接的张量.如果优选连接的, 则正向和反向输出可以连接为tf.concat(outputs, 2).
# output_states为(output_state_fw, output_state_bw),包含了前向和后向最后的隐藏状态的组成的二元组。
# output_state_fw和output_state_bw的类型为LSTMStateTuple。
# LSTMStateTuple由(c,h)组成,分别代表memory
# cell和hidden(即c,h矩阵)
# state。
(output_fw_seq, output_bw_seq), _ = tf.nn.bidirectional_dynamic_rnn(
cell_fw=cell_fw,
cell_bw=cell_bw,
inputs=self.word_embeddings,## 输入 [batch_szie, max_time, depth]depth=self.hidden_dim=300,max_time可以为句子的长度(一般以最长的句子为准,短句需要做padding),depth为输入句子词向量的维度
sequence_length=self.sequence_lengths,# 输入序列的实际长度(可选,默认为输入序列的最大长度)
dtype=tf.float32)
print('model 137')
print(self.word_embeddings)
print('model 143')
print(output_fw_seq.shape)
print(output_bw_seq.shape)
#则output_fw将是形状为[batch_size, max_time, cell_fw.output_size],
# 的张量, 则output_bw将是形状为[batch_size, max_time, cell_bw.output_size]
# 维持行数不变,后面的行接到前面的行后面 示例程序在tt.py
output = tf.concat([output_fw_seq, output_bw_seq], axis=-1)#[batch_size, max_time, 600]-1是按行的意思
print('model 151')
print(output.shape)
# model 143
# (?, ?, 300)
# (?, ?, 300)
# model 151
# (?, ?, 600)
#经过droupput处理
output = tf.nn.dropout(output, self.dropout_pl)
with tf.variable_scope("proj"):
W = tf.get_variable(name="W",
shape=[2 * self.hidden_dim, self.num_tags],#[600,7]
# 该函数返回一个用于初始化权重的初始化程序 “Xavier” 。
# 这个初始化器是用来保持每一层的梯度大小都差不多相同
initializer=tf.contrib.layers.xavier_initializer(),
dtype=tf.float32)
b = tf.get_variable(name="b",
shape=[self.num_tags],#[7]
# tf.zeros_initializer(),也可以简写为tf.Zeros()
initializer=tf.zeros_initializer(),
dtype=tf.float32)
# output的形状为[batch_size,steps,cell_num]批次大小,步长,神经元个数=600
s = tf.shape(output)
#print(output.shape)
# reshape的目的是为了跟w做矩阵乘法
output = tf.reshape(output, [-1, 2*self.hidden_dim])#-1就是未知值,是批次大小
pred = tf.matmul(output, W) + b#[batch_size,self.num_tags]
# s[1]=batch_size
self.logits = tf.reshape(pred, [-1, s[1], self.num_tags])#[-1,batch_size,7]
print("******************************************************************************")
print(self.logits.shape)
def loss_op(self):
if self.CRF:
# crf_log_likelihood作为损失函数
# inputs:unary potentials,就是每个标签的预测概率值
# tag_indices,这个就是真实的标签序列了
# sequence_lengths,一个样本真实的序列长度,为了对齐长度会做些padding,但是可以把真实的长度放到这个参数里
# transition_params,转移概率,可以没有,没有的话这个函数也会算出来
# 输出:log_likelihood:标量;transition_params,转移概率,如果输入没输,它就自己算个给返回
log_likelihood, self.transition_params = crf_log_likelihood(inputs=self.logits,
tag_indices=self.labels,
sequence_lengths=self.sequence_lengths)
self.loss = -tf.reduce_mean(log_likelihood)
else:
# 交叉熵做损失函数
losses = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=self.logits,
labels=self.labels)
#张量变换函数
mask = tf.sequence_mask(self.sequence_lengths)
#tf.boolean_mask https://blog.csdn.net/qq_29444571/article/details/84574526
losses = tf.boolean_mask(losses, mask)
self.loss = tf.reduce_mean(losses)
#添加标量统计结果
tf.summary.scalar("loss", self.loss)
def softmax_pred_op(self):
if not self.CRF:
self.labels_softmax_ = tf.argmax(self.logits, axis=-1)#-1表示按行取值最大的索引
self.labels_softmax_ = tf.cast(self.labels_softmax_, tf.int32)
def trainstep_op(self):
with tf.variable_scope("train_step"):
self.global_step = tf.Variable(0, name="global_step", trainable=False)
if self.optimizer == 'Adam':
optim = tf.train.AdamOptimizer(learning_rate=self.lr_pl)
elif self.optimizer == 'Adadelta':
optim = tf.train.AdadeltaOptimizer(learning_rate=self.lr_pl)
elif self.optimizer == 'Adagrad':
optim = tf.train.AdagradOptimizer(learning_rate=self.lr_pl)
elif self.optimizer == 'RMSProp':
optim = tf.train.RMSPropOptimizer(learning_rate=self.lr_pl)
elif self.optimizer == 'Momentum':
optim = tf.train.MomentumOptimizer(learning_rate=self.lr_pl, momentum=0.9)
elif self.optimizer == 'SGD':
optim = tf.train.GradientDescentOptimizer(learning_rate=self.lr_pl)
else:
optim = tf.train.GradientDescentOptimizer(learning_rate=self.lr_pl)
#minimize()实际上包含了两个步骤,即compute_gradients和apply_gradients,前者用于计算梯度,后者用于使用计算得到的梯度来更新对应的variable
grads_and_vars = optim.compute_gradients(self.loss)
grads_and_vars_clip = [[tf.clip_by_value(g, -self.clip_grad, self.clip_grad), v] for g, v in grads_and_vars]
self.train_op = optim.apply_gradients(grads_and_vars_clip, global_step=self.global_step)
def init_op(self):
self.init_op = tf.global_variables_initializer()
def add_summary(self, sess):
"""
:param sess:
:return:
"""
self.merged = tf.summary.merge_all()
self.file_writer = tf.summary.FileWriter(self.summary_path, sess.graph)
def train(self, train, dev):#下面的train=train_data, dev=test_data
""" train_data的形状为[(['我',在'北','京'],['O','O','B-LOC','I-LOC'])...第一句话
(['我',在'天','安','门'],['O','O','B-LOC','I-LOC','I-LOC'])...第二句话
( 第三句话 ) ] 总共有50658句话"""
"""
:param train:
:param dev:
:return:
"""
saver = tf.train.Saver(tf.global_variables())
with tf.Session(config=self.config) as sess:
sess.run(self.init_op)
self.add_summary(sess)
#epoch_num=40
for epoch in range(self.epoch_num):
self.run_one_epoch(sess, train, dev, self.tag2label, epoch, saver)
def test(self, test):
saver = tf.train.Saver()
with tf.Session(config=self.config) as sess:
self.logger.info('=========== testing ===========')
saver.restore(sess, self.model_path)
label_list, seq_len_list = self.dev_one_epoch(sess, test)
self.evaluate(label_list, seq_len_list, test)
#用模型测试一个句子
def demo_one(self, sess, sent):
"""
:param sess:
:param sent:
:return:
"""
label_list = []
for seqs, labels in batch_yield(sent, self.batch_size, self.vocab, self.tag2label, shuffle=False):
# print('model 268行:')
# print(seqs)
# print(labels)
# model 268 行:以 小明的大学在北京的北京大学 为例
# [[841, 37, 8, 55, 485, 73, 87, 74, 8, 87, 74, 55, 485]]可见batch_yield就是把输入的句子每个字的id返回,以及每个标签转化为对应的tag2label的值
# [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]
label_list_, _ = self.predict_one_batch(sess, seqs)#得到了预测值
# print('model 275行')
# print(label_list_)
# print(_)
# model 275 行
# [[1, 2, 0, 0, 0, 0, 3, 4, 0, 5, 6, 6, 6]]
# [13]
label_list.extend(label_list_)
label2tag = {}
for tag, label in self.tag2label.items():
label2tag[label] = tag if label != 0 else label#
print('model 304')
print(label2tag)
tag = [label2tag[label] for label in label_list[0]]
print('model 307')
print(tag)
# model 304
# {0: 0, 1: 'B-PER', 2: 'I-PER', 3: 'B-LOC', 4: 'I-LOC', 5: 'B-ORG', 6: 'I-ORG'}
# model 307
# ['B-PER', 'I-PER', 0, 0, 0, 0, 'B-LOC', 'I-LOC', 0, 'B-ORG', 'I-ORG', 'I-ORG', 'I-ORG']
return tag
def run_one_epoch(self, sess, train, dev, tag2label, epoch, saver):
"""
:param sess:
:param train:
:param dev:
:param tag2label:
:param epoch:
:param saver:
:return:
"""
# 计算出多少个batch,计算过程:(50658+64-1)//64=792
num_batches = (len(train) + self.batch_size - 1) // self.batch_size
# 记录开始训练的时间
start_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
# 产生每一个batch
batches = batch_yield(train, self.batch_size, self.vocab, self.tag2label, shuffle=self.shuffle)
for step, (seqs, labels) in enumerate(batches):
# sys.stdout 是标准输出文件,write就是往这个文件写数据
sys.stdout.write(' processing: {} batch / {} batches.'.format(step + 1, num_batches) + '\r')
# step_num=epoch*792+step+1
step_num = epoch * num_batches + step + 1
feed_dict, _ = self.get_feed_dict(seqs, labels, self.lr, self.dropout_keep_prob)
_, loss_train, summary, step_num_ = sess.run([self.train_op, self.loss, self.merged, self.global_step],
feed_dict=feed_dict)
if step + 1 == 1 or (step + 1) % 300 == 0 or step + 1 == num_batches:#开头后每相隔300记录一次,最后再记录一次
self.logger.info(
'{} epoch {}, step {}, loss: {:.4}, global_step: {}'.format(start_time, epoch + 1, step + 1,
loss_train, step_num))
#可视化
self.file_writer.add_summary(summary, step_num)
if step + 1 == num_batches:
# 训练的最后一个batch保存模型
saver.save(sess, self.model_path, global_step=step_num)
self.logger.info('===========validation / test===========')
label_list_dev, seq_len_list_dev = self.dev_one_epoch(sess, dev)#将test_data传过去
self.evaluate(label_list_dev, seq_len_list_dev, dev, epoch)
#占位符赋值
def get_feed_dict(self, seqs, labels=None, lr=None, dropout=None):
"""
:param seqs:
:param labels:
:param lr:
:param dropout:
:return: feed_dict
"""
# seq_len_list用来统计每个样本的真实长度
# word_ids就是seq_list,padding后的样本序列
word_ids, seq_len_list = pad_sequences(seqs, pad_mark=0)
feed_dict = {self.word_ids: word_ids,
self.sequence_lengths: seq_len_list}
if labels is not None:
# labels经过padding后,喂给feed_dict
labels_, _ = pad_sequences(labels, pad_mark=0)
feed_dict[self.labels] = labels_
if lr is not None:
feed_dict[self.lr_pl] = lr
if dropout is not None:
feed_dict[self.dropout_pl] = dropout
# seq_len_list用来统计每个样本的真实长度
return feed_dict, seq_len_list
def dev_one_epoch(self, sess, dev):
"""
:param sess:
:param dev:
:return:
"""
label_list, seq_len_list = [], []
#获取一个批次的句子中词的id以及标签
for seqs, labels in batch_yield(dev, self.batch_size, self.vocab, self.tag2label, shuffle=False):
label_list_, seq_len_list_ = self.predict_one_batch(sess, seqs)
label_list.extend(label_list_)
seq_len_list.extend(seq_len_list_)
return label_list, seq_len_list
def predict_one_batch(self, sess, seqs):
"""
:param sess:
:param seqs:
:return: label_list
seq_len_list
"""
# seq_len_list用来统计每个样本的真实长度
feed_dict, seq_len_list = self.get_feed_dict(seqs, dropout=1.0)
if self.CRF:
# transition_params代表转移概率,由crf_log_likelihood方法计算出
logits, transition_params = sess.run([self.logits, self.transition_params],
feed_dict=feed_dict)
# print('model 405')
# print(logits.shape)#1*13*7
# print(transition_params)#7*7矩阵
label_list = []
# 打包成元素形式为元组的列表[(logit,seq_len),(logit,seq_len),( ,),]
#print(logits)
# print('model 411')
# print(seq_len_list)
# model 411
# [13] =小明的大学在北京的北京大学的长度
for logit, seq_len in zip(logits, seq_len_list):#如果是demo情况下,输入句子,那么只有一个句子,所以只循环一次,训练模式下就不会
#对logits解析得到一个数
viterbi_seq, _ = viterbi_decode(logit[:seq_len], transition_params)
label_list.append(viterbi_seq)
print('*-*******************************************************')
# print(label_list)#对logit按行解析返回的值[[1, 2, 0, 0, 0, 0, 3, 4, 0, 5, 6, 6, 6]]#这就是预测结果,对应着tag2label里的值
return label_list, seq_len_list
else:#如果不用CRF,就是把self.logits每行取最大的
label_list = sess.run(self.labels_softmax_, feed_dict=feed_dict)
return label_list, seq_len_list
def evaluate(self, label_list, seq_len_list, data, epoch=None):
"""
:param label_list:
:param seq_len_list:
:param data:
:param epoch:
:return:
"""
label2tag = {}
for tag, label in self.tag2label.items():
# tag2label = {"O": 0,
# "B-PER": 1, "I-PER": 2,
# "B-LOC": 3, "I-LOC": 4,
# "B-ORG": 5, "I-ORG": 6
# }
label2tag[label] = tag if label != 0 else label
model_predict = []
for label_, (sent, tag) in zip(label_list, data):
tag_ = [label2tag[label__] for label__ in label_]
sent_res = []
if len(label_) != len(sent):
print(sent)
print(len(label_))
print(tag)
for i in range(len(sent)):
sent_res.append([sent[i], tag[i], tag_[i]])
model_predict.append(sent_res)
epoch_num = str(epoch+1) if epoch != None else 'test'
label_path = os.path.join(self.result_path, 'label_' + epoch_num)
metric_path = os.path.join(self.result_path, 'result_metric_' + epoch_num)
for _ in conlleval(model_predict, label_path, metric_path):
self.logger.info(_)
对应:eval.py,这里只进行评测过程的定义。在实际执行中,应该放在model.py之前。实际测试过程是在model.py中执行的。
import os
#第四步
#使用conlleval.pl对CRF测试结果进行评价的方法
def conlleval(label_predict, label_path, metric_path):
"""
:param label_predict:
:param label_path:
:par am metric_path:
:return:
"""
eval_perl = "../input/seq-tag/conlleval_rev.pl"
with open(label_path, "w") as fw:
line = []
for sent_result in label_predict:
for char, tag, tag_ in sent_result:
tag = '0' if tag == 'O' else tag
char = char.encode("utf-8")
line.append("{} {} {}\n".format(char, tag, tag_))
line.append("\n")
fw.writelines(line)
os.system("perl {} < {} > {}".format(eval_perl, label_path, metric_path))
with open(metric_path) as fr:
metrics = [line.strip() for line in fr]
return metrics
对应:main.py
import tensorflow as tf
from tensorflow.python.framework import ops
ops.reset_default_graph()
# import tensorflow.compat.v1 as tf
# tf.disable_v2_behavior()
# import tensorflow.compat.v1 as tf
# tf.compat.v1.disable_eager_execution()
import numpy as np
import os, argparse, time, random
# from model import BiLSTM_CRF
# from utils import str2bool, get_logger, get_entity
# from data import read_corpus, read_dictionary, tag2label, random_embedding
# 第五步运行
## Session configuration
# 在python代码中设置使用的GPU
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # default: 0
# 记录设备指派情况:tf.ConfigProto(log_device_placement=True)
# 设置tf.ConfigProto()中参数log_device_placement = True ,
# 可以获取到 operations 和 Tensor 被指派到哪个设备(几号CPU或几号GPU)上运行,
# 会在终端打印出各项操作是在哪个设备上运行的。
# config = tf.ConfigProto()
config=tf.compat.v1.ConfigProto()
config.gpu_options.allow_growth = True
config.gpu_options.per_process_gpu_memory_fraction = 0.2 # need ~700MB GPU memory
## hyperparameters超参数设置
# 使用argparse的第一步就是创建一个解析器对象,并告诉它将会有些什么参数。
# 那么当你的程序运行时,该解析器就可以用于处理命令行参数
parser = argparse.ArgumentParser(description='BiLSTM-CRF for Chinese NER task')
# 方法add_argument(name or flags...[, action][, nargs][, const][, default][, type][, choices][, required][, help][, metavar][, dest])
# 其中:
# name or flags:命令行参数名或者选项,如上面的address或者-p,--port.
# 其中命令行参数如果没给定,且没有设置defualt,则出错。但是如果是选项的话,则设置为None
# nargs:命令行参数的个数,
# 一般使用通配符表示,其中,'?'表示只用一个,'*'表示0到多个,'+'表示至少一个
# default:默认值
# type:参数的类型,默认是字符串string类型,还有float、int等类型
# help:和ArgumentParser方法中的参数作用相似,出现的场合也一致
# 最常用的地方就是这些,其他的可以参考官方文档。
parser.add_argument('--train_data', type=str, default='../input/seq-tag/data_path', help='train data source')
parser.add_argument('--test_data', type=str, default='../input/seq-tag/data_path', help='test data source')
parser.add_argument('--batch_size', type=int, default=64, help='#sample of each minibatch')
parser.add_argument('--epoch', type=int, default=5, help='#epoch of training')
parser.add_argument('--hidden_dim', type=int, default=300, help='#dim of hidden state')
parser.add_argument('--optimizer', type=str, default='Adam', help='Adam/Adadelta/Adagrad/RMSProp/Momentum/SGD')
parser.add_argument('--CRF', type=str2bool, default=True, help='use CRF at the top layer. if False, use Softmax')
parser.add_argument('--lr', type=float, default=0.001, help='learning rate')
parser.add_argument('--clip', type=float, default=5.0, help='gradient clipping')
parser.add_argument('--dropout', type=float, default=0.5, help='dropout keep_prob')
parser.add_argument('--update_embedding', type=str2bool, default=True, help='update embedding during training')
parser.add_argument('--pretrain_embedding', type=str, default='random',
help='use pretrained char embedding or init it randomly')
parser.add_argument('--embedding_dim', type=int, default=300, help='random init char embedding_dim')
parser.add_argument('--shuffle', type=str2bool, default=True, help='shuffle training data before each epoch')
parser.add_argument('--mode', type=str, default='test', help='train/test/demo')
parser.add_argument('--demo_model', type=str, default='1669192178', help='model for test and demo')
# 传递参数送入模型中解析
args = parser.parse_args(args=[])
## get char embeddings
'''word2id的形状为{'当': 1, '希': 2, '望': 3, '工': 4, '程': 5,。。'<UNK>': 3904, '<PAD>': 0}
train_data总共3903个去重后的字'''
word2id = read_dictionary('./word2id.pkl')
# os.path.join('', args.train_data, 'word2id.pkl')) # .\args.train_data\word2id.pkl #提前执行vocab_build
# 通过调用random_embedding函数返回一个len(vocab)*embedding_dim=3905*300的矩阵(矩阵元素均在-0.25到0.25之间)作为初始值
if args.pretrain_embedding == 'random':
embeddings = random_embedding(word2id, args.embedding_dim)
else:
embedding_path = 'pretrain_embedding.npy'
embeddings = np.array(np.load(embedding_path), dtype='float32')
## read corpus and get training data
if args.mode != 'demo':
# 设置train_path的路径为data_path下的train_data文件
train_path = os.path.join('.', args.train_data, 'train_data.txt') # .\args.train_data(默认值data_path)\train_data
# 设置test_path的路径为data_path下的test_path文件
test_path = os.path.join('.', args.test_data, 'test_data.txt') # .\args.train_data(默认值data_path)\test_data
# 通过read_corpus函数读取出train_data
""" train_data的形状为[(['我',在'北','京'],['O','O','B-LOC','I-LOC'])...第一句话
(['我',在'天','安','门'],['O','O','B-LOC','I-LOC','I-LOC'])...第二句话
( 第三句话 ) ] 总共有50658句话"""
train_data = read_corpus(train_path)
test_data = read_corpus(test_path)
test_size = len(test_data)
## paths setting
paths = {}
# 时间戳就是一个时间点,一般就是为了在同步更新的情况下提高效率之用。
# 就比如一个文件,如果他没有被更改,那么他的时间戳就不会改变,那么就没有必要写回,以提高效率,
# 如果不论有没有被更改都重新写回的话,很显然效率会有所下降。
# 如果是训练就获取最新时间,否则就=args.demo_model
timestamp = str(int(time.time())) if args.mode == 'train' else args.demo_model
# 输出地址,默认是./data_path_save/时间戳
output_path = os.path.join('./', 'data_path_save', timestamp) #./data_path_save/时间
# '.', args.train_data + "_save", timestamp)#./data_path_save/时间
# 如果地址不存在就新建
if not os.path.exists(output_path): os.makedirs(output_path)
# ./data_path_save/时间戳/summaries
summary_path = os.path.join(output_path, "summaries")#./data_path_save/时间/summaries
paths['summary_path'] = summary_path
# 如果地址不存在就新建
if not os.path.exists(summary_path): os.makedirs(summary_path)
# ./data_path_save/时间戳/checkpoints/
model_path = os.path.join(output_path, "checkpoints/")##./data_path_save/时间/checkpoints/
if not os.path.exists(model_path): os.makedirs(model_path)
# ./data_path_save/时间戳/checkpoints/model
ckpt_prefix = os.path.join(model_path, "model")#./data_path_save/时间/checkpoints/model
paths['model_path'] = ckpt_prefix
# 如果不存在就新建
if not os.path.exists(ckpt_prefix): os.makedirs(ckpt_prefix)
# ./data_path_save/时间戳/results
result_path = os.path.join(output_path, "results")##./data_path_save/时间/results
paths['result_path'] = result_path
# 如果不存在就新建
if not os.path.exists(result_path): os.makedirs(result_path)
log_path = os.path.join(result_path, "log.txt")
paths['log_path'] = log_path
# 把调用的函数及各个参数写入日志文件
# 2019-07-26 08:45:40,081:INFO: Namespace(CRF=True, batch_size=64, clip=5.0, demo_model='1521112368', dropout=0.5, embedding_dim=300, epoch=40, hidden_dim=300, lr=0.001, mode='demo', optimizer='Adam', pretrain_embedding='random', shuffle=True, test_data='data_path', train_data='data_path', update_embedding=True)
get_logger(log_path).info(str(args))
## training model
if args.mode == 'train':
# 引入第二步建立的模型
model = BiLSTM_CRF(args, embeddings, tag2label, word2id, paths, config=config)
# 创建节点,无返回值
# tf.reset_default_graph()
model.build_graph()
## hyperparameters-tuning, split train/dev
# dev_data = train_data[:5000]; dev_size = len(dev_data)
# train_data = train_data[5000:]; train_size = len(train_data)
# print("train data: {0}\ndev data: {1}".format(train_size, dev_size))
# model.train(train=train_data, dev=dev_data)
## train model on the whole training data
print("train data: {}".format(len(train_data)))
# 训练
model.train(train=train_data, dev=test_data) # use test_data as the dev_data to see overfitting phenomena
## testing model
elif args.mode == 'test':
ckpt_file = tf.train.latest_checkpoint(model_path)
print(ckpt_file)
paths['model_path'] = ckpt_file
model = BiLSTM_CRF(args, embeddings, tag2label, word2id, paths, config=config)
model.build_graph()
print("test data: {}".format(test_size))
# 测试
model.test(test_data)
## demo
elif args.mode == 'demo':
ckpt_file = tf.train.latest_checkpoint(model_path)
print(ckpt_file)
paths['model_path'] = ckpt_file
model = BiLSTM_CRF(args, embeddings, tag2label, word2id, paths, config=config)
model.build_graph()
saver = tf.train.Saver()
with tf.Session(config=config) as sess:
print('============= demo =============')
saver.restore(sess, ckpt_file) # 读入已经训练好的模型
while (1):
print('Please input your sentence:')
demo_sent = input()
if demo_sent == '' or demo_sent.isspace():
print('See you next time!')
break
else:
demo_sent = list(demo_sent.strip()) # ['小', '明', '的', '大', '学', '在', '北', '京', '的', '北', '京', '大', '学']
demo_data = [(demo_sent, ['O'] * len(
demo_sent))] # 如[(['小', '明', '的', '大', '学', '在', '北', '京', '的', '北', '京', '大', '学'], ['O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O'])]
# 用模型测试一个句子
print('main 172行:')
print(demo_data)
# main 172行:
# [(['小', '明', '的', '大', '学', '在', '北', '京', '的', '北', '京', '大', '学'], ['O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O'])]
tag = model.demo_one(sess,
demo_data) ## ['B-PER', 'I-PER', 0, 0, 0, 0, 'B-LOC', 'I-LOC', 0, 'B-ORG', 'I-ORG', 'I-ORG', 'I-ORG']
PER, LOC, ORG = get_entity(tag, demo_sent)
print('PER: {}\nLOC: {}\nORG: {}'.format(PER, LOC, ORG))
打包模型和预测结果:
import os
import zipfile
import datetime
def file2zip(packagePath, zipPath):
zip = zipfile.ZipFile(zipPath, 'w', zipfile.ZIP_DEFLATED)
for path, dirNames, fileNames in os.walk(packagePath):
fpath = path.replace(packagePath, '')
for name in fileNames:
fullName = os.path.join(path, name)
name = fpath + '\\' + name
zip.write(fullName, name)
zip.close()
if __name__ == "__main__":
# 文件夹路径
packagePath = '/kaggle/working/'
zipPath = '/kaggle/working/output.zip'
if os.path.exists(zipPath):
os.remove(zipPath)
file2zip(packagePath, zipPath)
print("打包完成")
print(datetime.datetime.utcnow())
执行完生成以下文件:
在/kaggle/working/data_path_save/1669192178/results目录下存储了模型训练及测试时输出的数据;
outpu.zip为模型及评测结果的打包文件。
/1669192178/results中保存训练过程及测试过程的评测结果,其中result_metric_1~5为训练过程中的输出指标,result_metrix_label存储训练好的模型在测试数据及上的评测指标。

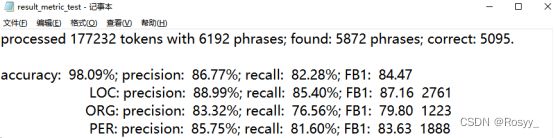
,
代码实现借鉴:BiLSTM+CRF完成命名实体识别