R语言 类别数据可视化(1)
目录
一 条形图及其变种
1.简单条形图和帕累托图
(1)条形图
(2)帕累托图
2.并列条形图和堆叠条形图
3.不等宽条形图和脊形图
(1)不等宽条形图
(2)脊形图
二 树状图
1.条形树状图
2.矩形树状图
三 马赛克图及其变种
1.马赛克图
2.马赛克图变种
四 关联图和独立性检验的P值图
1.关联图
2. 独立性检验的P值图
一 条形图及其变种
1.简单条形图和帕累托图
(1)条形图
条形图(bar plot)是用一定宽度和高度的矩形表示各类别频数多少的图形
主要用于展示类别变量数据的频数分布
绘制条形图时,各类别可以放在X轴(横轴),也可以放在Y轴(纵轴)
类别放在X轴的条形图称为垂直条形图(vertical bar plot)或柱形图,类别放在Y轴的条形图称为水平条形图(horizontal bar plot)
data3_1 <- read.csv('./mydata/chap03/data3_1.csv')
attach(data3_1)
table1 <- table(性别)
table2 <- table(网购次数)
table3 <- table(满意度)
table1;table2;table3性别
男 女
840 1160
网购次数
1~2次 3~5次 6次以上
618 804 578
满意度
不满意 满意 中立
800 520 680
# 2000个被调查者网购情况的条形图
layout(matrix(c(1,2,3,3), 2, 2, byrow=T))
par(mai=c(0.6,0.6,0.4,0.1),cex=0.7) # 设置图形边距和字体大小
barplot(table1, xlab='人数', ylab='性别',horiz=T,
density = 30, angle = 0, col = c('grey80', 'grey50'), border='blue')
title(main=list('(a) 水平条形图', font=4))
barplot(table2, xlab='网购次数', ylab='人数', col=2:4,
density = 20, angle = 90, border='red', main='(b) 垂直条形图')
# cex.names(横轴标签大小)、cex.axis(纵轴标签大小)、cex.lab(坐标轴标题大小)
barplot(table3, xlab='满意度', ylab='人数', col=c('#DE2D26', '#31A354', '#3182BD'),
main='(c) 垂直条形图', cex.names=1.2, cex.lab=1.2)

#2000个被调查者满意度的条形图
library('sjPlot')
set_theme(axis.textsize=0.8, # 坐标轴刻度字体大小
axis.title.size=0.8, # 坐标轴标题字体大小
geom.label.size=2.5) # 图形标签字体大小
# 绘制条形图
plot_frq(data=data3_1,满意度,type='bar', # 绘制满意度的条形图
show.n=TRUE, show.prc=TRUE) # 显示类别频数和频数百分比
(2)帕累托图
帕累托图(Pareto plot)是是将各类别的频数降序排列后绘制的条形图
以意大利经济学家V.Pareto的名字命名的
帕累托图可以看作简单条形图的一个变种,利用该图很容易看出哪类频数出现得最多,哪类频数出现得最少
par(mfrow=c(1,1),mai=c(0.7,0.7,0.2,0.7),cex=0.7)
x<-sort(table(data3_1$满意度),decreasing=TRUE) # 生成一维表并将频数降序排列
bar<-barplot(x,xlab="满意度",ylab="人数",col=c("#DE2D26","#31A354","#3182BD"),ylim=c(0,1000)) # 绘制条形图
text(bar,x,labels=x,pos=3,col="black") # 为条形图添加频数标签
y<-cumsum(x)/sum(x) # 计算累积频数
par(new=T) # 绘制一幅新图加在现有的图形上
plot(y,type="b",pch=15,axes=FALSE,xlab='',ylab='',main='') # 绘制累积频数折线
axis(side=4) # 在第4个边增加坐标轴
mtext("累积频率",side=4,line=3,cex=0.8) # 添加坐标轴标签
text(labels="累积分布曲线",x=2.4,y=0.95,cex=1) # 添加注释文本
2.并列条形图和堆叠条形图
绘制两个类别变量的条形图时,可以使用原始数据绘图,也可以先生成二维列联表再绘图
根据绘制方式不同有并列条形图(juxtaposed bar plot)和堆叠条形图(stacked bar plot)等
并列条形图中,一个类别变量作为坐标轴,另一个类别变量各类别频数的条形并列摆放:堆叠条形图中,一个类别变量作为坐标轴,另一个类别变量各类别的频数按比例堆叠在同一个条中
使用 barplot函数默认绘制堆叠条形图,设置参数 beside=TRUE可绘制并列条形图。使用 DescTools 包中的 BarText 函数、 plotrix 包中的 barlabels函数可以给条形图添加标签
tab1<-table(性别,网购次数) # 生成性别与网购次数的二维表
tab2<-table(性别,满意度) # 生成性别与满意度的二维表
tab3<-table(网购次数,满意度) # 生成网购次数与满意度的二维表
tab1;tab2;tab3网购次数
性别 1~2次 3~5次 6次以上
男 280 322 238
女 338 482 340
满意度
性别 不满意 满意 中立
男 360 160 320
女 440 360 360
满意度
网购次数 不满意 满意 中立
1~2次 239 171 208
3~5次 316 195 293
6次以上 245 154 179
# 性别、网购次数、满意度人数分布的条形图
library(DescTools) # 加载包
par(mfrow=c(2,2),mai=c(0.8,0.8,0.7,0.1),cex=0.7,cex.main=1)
b1<-barplot(tab1,beside=TRUE,xlab="网购次数",ylab="人数",
main="(a) 垂直并列",col=c("#66C2A5","#FC8D62"),legend=rownames(tab1),
args.legend=list(x=4,y=550,ncol=2,cex=0.8,box.col="grey80"))
BarText(tab1,b=b1,beside=TRUE,cex=1,pos='topout') # 添加标签
# pos='topout'|‘topin’|'mid'|'bottomin'
b2<-barplot(tab2,beside=TRUE,horiz=TRUE,xlab="人数",ylab="满意度",main="(b) 水平并列",
col=c("#66C2A5","#FC8D62"),legend=rownames(tab2),
args.legend=list(x=165,y=10.5,ncol=2,cex=0.8,box.col="grey80"))
BarText(tab2,b=b2,beside=TRUE,horiz=TRUE,cex=1,pos='topin') # 添加标签
b3<-barplot(tab3,xlab="满意度",ylab="人数",main="(c) 垂直堆叠",
col=c("#66C2A5","#FC8D62","#E78AC3"),legend=rownames(tab3),
args.legend=list(x=2.9,y=950,ncol=3,cex=0.8,box.col="grey80"))
BarText(tab3,b=b3,cex=1,pos='mid') # 添加标签
b4<-barplot(tab3,horiz=TRUE,xlab="人数",ylab="满意度",main="(d) 水平堆叠",
col=c("#66C2A5","#FC8D62","#E78AC3"),legend=rownames(tab3),
args.legend=list(x=600,y=4.4,ncol=3,cex=0.8,box.col="grey80"))
BarText(tab3,b=b4,horiz=TRUE,col="black",cex=1,pos='mid') # 添加标签 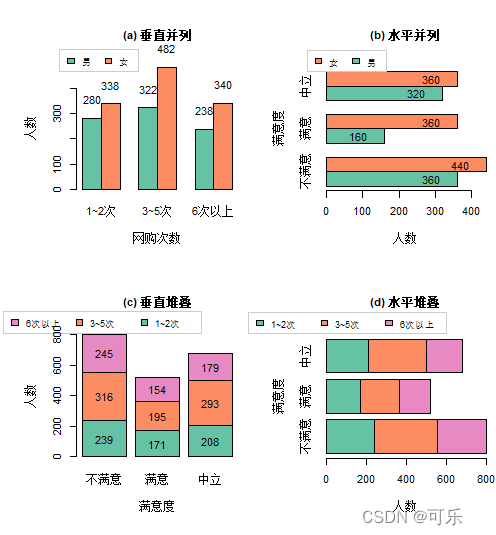
# 性别与满意度人数分布的并列条形图和堆叠条形图
library(sjPlot)
set_theme(title.size=0.8, # 设置图形标题字体大小
axis.title.size=0.8, # 设置坐标轴标题字体大小
axis.textsize=0.8, # 设置坐标轴字体大小
geom.label.size=2.5, # 设置图形标签字体大小
legend.size=0.8, # 设置图例字体大小
legend.title.size=0.8) # 设置图例标题主题大小
p1<-plot_xtab(data3_1$满意度,data3_1$性别,
bar.pos="dodge", # 绘制并列条形图
show.n=TRUE,show.prc=TRUE, # 显示频数和百分比
show.summary=TRUE, # 绘制出带有卡方检验统计量信息的摘要
vjust="center", # 调整频数标签摆放的垂直位置
show.total=FALSE, # 不绘制各类别总和的条
title="(a) 并列条形图") # 设置图形标题
p2<-plot_xtab(data3_1$满意度,data3_1$性别,
bar.pos="stack", # 绘制堆叠条形图
show.n=TRUE,show.prc=TRUE,
show.total=TRUE, # 绘制出各类别总和的条
vjust="middle",title="(b) 堆叠条形图")
library('gridExtra')
plot_grid(list(p1,p2),margin=c(0.3,0.3,0.3,0.3)) # 将图形p1和p2组合在一幅图中
# 性别与满意度的3D并列条形图
library(plotrix)
library(epade)
# dev.off() # 关闭当前的图形设备
par(mfrow=c(1,1))
bar.plot.ade(data3_1$性别,data3_1$满意度, # 绘制并列条形图(默认)
form="z",wall=4, # 设置3D条形式样和图形风格
prozent=TRUE, # 在条形上画出百分比
btext=TRUE, # 画出卡方检验的P值
xlab="满意度",ylab="人数",main="性别与满意度的条形图")
# 满意度与网购次数的3D堆叠条形图
bar.plot.ade(data3_1$满意度,data3_1$网购次数,beside=FALSE, # 绘制堆叠条形图
form="c",wall=1,prozent=TRUE,btext=TRUE,lhoriz=FALSE,
xlab="网购次数",ylab="人数")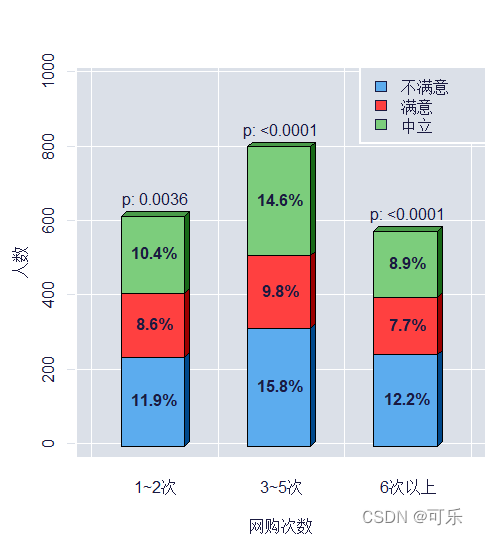
3.不等宽条形图和脊形图
(1)不等宽条形图
用一个变量各类别条形的宽度表示样本量,另一个类别变量的各类别以并列或堆叠的方式绘制条形图
# 满意度和网购次数的不等宽条形图
library(ggiraphExtra)
require(ggplot2)
library(gridExtra)
# 绘制图形p1和p2
p1<-ggSpine(data=data3_1,aes(x=满意度,fill=网购次数),
position="dodge",palette="Reds",labelsize=2.5) # 绘制并列条形图
theme(legend.position=c(0.52,0.88), # 设置图例位置
legend.direction="horizontal", # 图例水平排列
legend.title=element_text(size=7), # 设置图例标签字体大小
legend.text=element_text(size="5")) # 设置图例字体大小List of 4
$ legend.text :List of 11
..$ family : NULL
..$ face : NULL
..$ colour : NULL
..$ size : chr "5"
..$ hjust : NULL
..$ vjust : NULL
..$ angle : NULL
..$ lineheight : NULL
..$ margin : NULL
..$ debug : NULL
..$ inherit.blank: logi FALSE
..- attr(*, "class")= chr [1:2] "element_text" "element"
$ legend.title :List of 11
..$ family : NULL
..$ face : NULL
..$ colour : NULL
..$ size : num 7
..$ hjust : NULL
..$ vjust : NULL
..$ angle : NULL
..$ lineheight : NULL
..$ margin : NULL
..$ debug : NULL
..$ inherit.blank: logi FALSE
..- attr(*, "class")= chr [1:2] "element_text" "element"
$ legend.position : num [1:2] 0.52 0.88
$ legend.direction: chr "horizontal"
- attr(*, "class")= chr [1:2] "theme" "gg"
- attr(*, "complete")= logi FALSE
- attr(*, "validate")= logi TRUE
p2<-ggSpine(data=data3_1,aes(x=满意度,fill=网购次数),
position="stack",palette="Blues",labelsize=2.5,reverse=TRUE)
# 绘制堆叠条形图
grid.arrange(p1,p2,ncol=1) 
(2)脊形图
脊形图(spine plot)是根据各类别的比例绘制的一种条形图,它可以看作堆叠条形图的一个变种,也可以看作马赛克图的一个特例。绘制脊形图时,将某个类别各条的高度都设定为1或100%,条的宽度与观测频数(样本量)成比例,条内每一段的高度表示另一个类别变量各类别的频数比例
# 性别与满意度、网购次数与满意度的脊形图
par(mfrow=c(1,2),mai=c(1,1,1,0.4),cex=0.7)
data3_1$性别 = as.factor(data3_1$性别)
spineplot(factor(性别)~factor(满意度),data=data3_1,col=c("#FB8072","#80B1D3"),
xlab="满意度",ylab="性别", main='(a) 性别与满意度')
spineplot(factor(网购次数)~factor(满意度),data=data3_1,col=c("#7FC97F","#BEAED4","#FDC086"),
xlab="满意度",ylab="网购次数", main='(b) 网购次数与满意度')
# 按性别分面的满意度与网购次数的脊形图
library("ggiraphExtra")
require(ggplot2)
ggSpine(data=data3_1,aes(x=满意度,fill=网购次数,facet=性别),
palette="Reds",labelsize=3,reverse=TRUE) 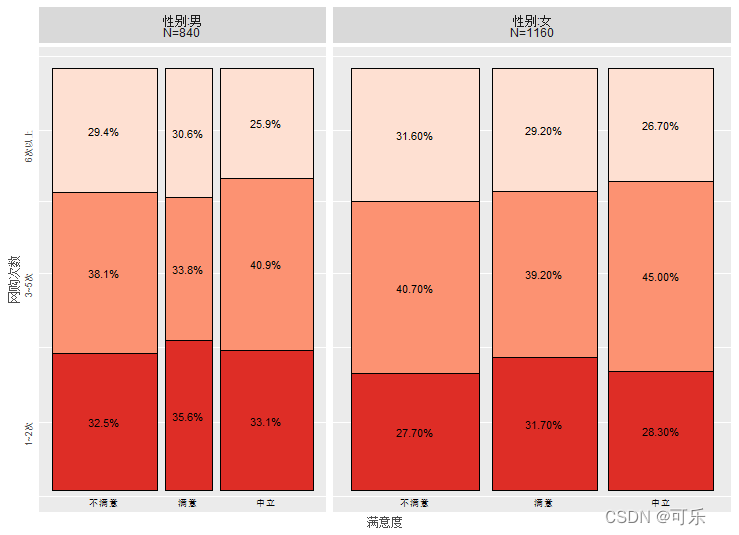
二 树状图
将各类别的层次结构画成树状图的形式,称为树状图(dendrogram)或分层树状图
有条形树状图和矩形树状图,可以看做是条形图的另一个变种
主要用来展示各类别变量之间的层次结构关系,尤其适合展示3个及3个以上类别变量的情形(也可以用于展示两个类别变量)
1.条形树状图
# 性别、网购次数、满意度的大小树状图
data3_1<-read.csv("./mydata/chap03/data3_1.csv")
library(plotrix)
cols<-list(c("#FDD0A2","#FD8D3C"),c("#C6DBEF","#9ECAE1","#6BAED6"),c("#C7E9C0","#A1D99B","#74C476")) # 设置颜色列表
sizetree(data3_1,col=cols,
showval=TRUE,showcount=TRUE,stacklabels=TRUE, # 显示类别标签、频数、变量名称
border="black",base.cex=0.7) # 设置矩形边框的颜色和标签字体的大小
# 女性的网购次数和满意度的大小树状图
sizetree(data3_1[data3_1$性别=='女', ],col=cols,
showval=TRUE,showcount=TRUE,stacklabels=TRUE, # 显示类别标签、频数、变量名称
border="black",base.cex=0.7) # 设置矩形边框的颜色和标签字体的大小
2.矩形树状图
# 以性别、网购次数、满意度为索引的矩形树状图
library(treemap)
data3_1<-read.csv("./mydata/chap03/data3_1.csv")
# 生成带有交叉频数的数据框
tab<-ftable(data3_1) # 生成列联表(也可以使用table函数生成列联表)
tab满意度 不满意 满意 中立
性别 网购次数
男 1~2次 117 57 106
3~5次 137 54 131
6次以上 106 49 83
女 1~2次 122 114 102
3~5次 179 141 162
6次以上 139 105 96
d<-as.data.frame(tab) # 将列联表转换成带有类别频数的数据框
df<-data.frame(d[,-4],频数=d$Freq) # 将Freq修改为频数
df性别 网购次数 满意度 频数
1 男 1~2次 不满意 117
2 女 1~2次 不满意 122
3 男 3~5次 不满意 137
4 女 3~5次 不满意 179
5 男 6次以上 不满意 106
6 女 6次以上 不满意 139
7 男 1~2次 满意 57
8 女 1~2次 满意 114
9 男 3~5次 满意 54
10 女 3~5次 满意 141
11 男 6次以上 满意 49
12 女 6次以上 满意 105
13 男 1~2次 中立 106
14 女 1~2次 中立 102
15 男 3~5次 中立 131
16 女 3~5次 中立 162
17 男 6次以上 中立 83
18 女 6次以上 中立 96
treemap(df,index=c("性别","网购次数","满意度"), # 设置聚合索引的列名称
vSize="频数", # 指定矩形大小的列名称
type="index", # 确定矩形的着色方式
fontsize.labels=9, # 设置标签字体大小
position.legend="bottom", # 设置图例位置
title="") 
# 用频数着色的矩形树状图
treemap(df,index=c("性别","网购次数","满意度"), # 设置聚合索引的列名称
vSize="频数", # 设置指定矩形大小的列名称
vColor="频数", # 确定矩形颜色的列名称
type="value", # 确定矩形的着色方式
fontsize.labels=9, # 设置标签字体大小
title="") 
三 马赛克图及其变种
马赛克图是用矩形表示列联表中对应频数的一种图形
图中嵌套矩形的面积与列联表相应单元格的频数成比例
也可以用于二维表的可视化,可视为条形图的一个变种
其变种形式有:筛网图、瓦片图、双层图等
1.马赛克图
# 性别、网购次数、满意度的马赛克图
data3_1<-read.csv("./mydata/chap03/data3_1.csv")
par(mfrow=c(1,2),mai=c(0.3,0.3,0.1,0.1),cex=0.7)
mosaicplot(~性别+网购次数+满意度,data=data3_1,col=c("#E41A1C","#377EB8","#4DAF4A"),
cex.axis=0.7,off=8,dir=c("v","h","v"),main="") # 简单马赛克图
mosaicplot(~性别+网购次数+满意度,data=data3_1,shade=TRUE,
cex.axis=0.7,off=8,dir=c("v","h","v"),main="") 
2.马赛克图变种
# 带有观测频数和期望频数的马赛克图
library(vcd)
tab<-structable(data3_1) # 生成多维列联表(或用table或ftable生成列联表)
tab网购次数 1~2次 3~5次 6次以上
性别 满意度
男 不满意 117 137 106
满意 57 54 49
中立 106 131 83
女 不满意 122 179 139
满意 114 141 105
中立 102 162 96
p1<-mosaic(tab,shade=TRUE,
labeling=labeling_values, # 生成频数标签
return_grob=TRUE) 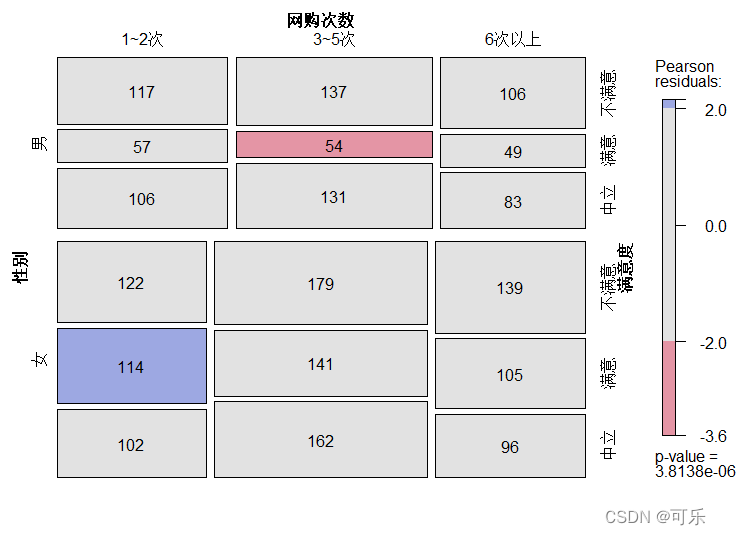
p2<-mosaic(tab,shade=TRUE,labeling=labeling_values,
value_type="expected", # 绘制期望频数标签
return_grob=TRUE)
mplot(p1,p2,cex=0.5,layout=c(1,2)) # 按1行2列组合p1和p2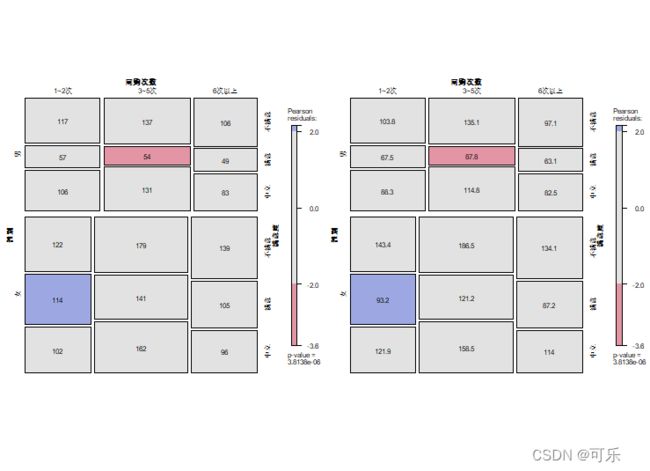
# 带有观测频数和期望频数的筛网图
p3<-vcd::sieve(tab,shade=TRUE,labeling=labeling_values,
return_grob=TRUE,main="(a) 显示观察频数")
p4<-vcd::sieve(tab,shade=TRUE,
labeling=labeling_values,value_type="expected",
return_grob=TRUE,main="(b) 显示期望频数") 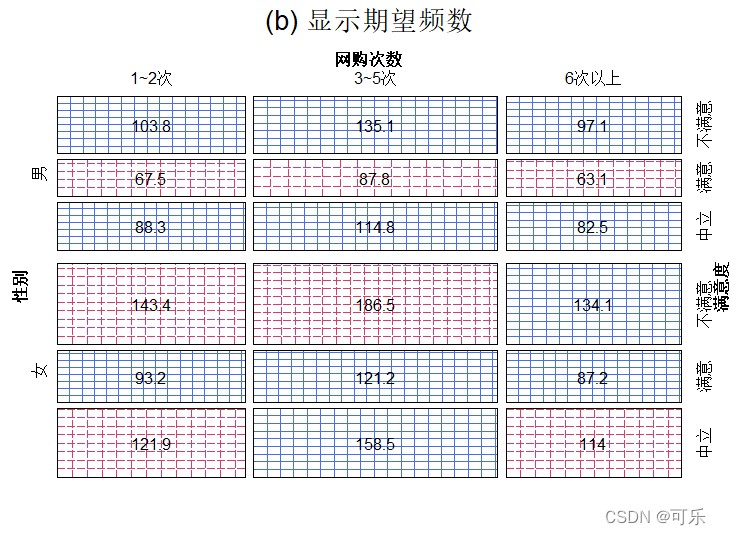
mplot(p3,p4,cex=0.5,layout=c(1,2)) # 按1行2列组合p3和p4 
# 性别、网购次数、满意度的瓦片图和双层图
p5<-vcd::tile(tab,shade=TRUE,tile_type="area", # 用面积表示矩形大小
squared_tiles=FALSE, # 不显示行或列中的空白
labeling=labeling_values,
return_grob=TRUE)
p6<-vcd::doubledecker(tab,abeling=labeling_values,
return_grob=TRUE)
mplot(p5,p6,cex=0.5,layout=c(1,2)) 
# 以性别作为条件变量绘制的马赛克图
tab<-structable(性别~网购次数+满意度,data=data3_1) # 生成多维列联表
cotabplot(tab,labeling=labeling_values) # 显示相应单元格的频数
四 关联图和独立性检验的P值图
1.关联图
分析列联表中行变量和列变量关系的两种图形
关联图就是展示行变量和列变量差异的图形。它将图形以 RxC的形式布局,列联表中每一个单元格的观测频数和期望频数用一个矩形表示
如果一个单元格的观察频数大于期望频数,矩形将高于基线;如果一个单元格的观察频数小于期望频数时,矩形则低于基线
# 满意度与性别、网购次数与满意度的关联图
data3_1<-read.csv("./mydata/chap03/data3_1.csv")
attach(data3_1)
par(mfrow=c(1,2),mai=c(0.7,0.7,0.1,0.1),cex=0.7)
assocplot(table(满意度,性别),col=c("black","red"))
box(col="grey50")
assocplot(table(网购次数,满意度),col=c("black","red"))
box(col="grey50")
# 性别、网购次数和满意度的关联图
library(vcd)
tab<-structable(data3_1) # 生成多维列联表(也可使用table或ftable生成列联表)
assoc(tab,shade=TRUE,labeling=labeling_values) # 绘图关联图,并为矩形增加相应单元格的观测频数
2. 独立性检验的P值图
关联图只是大概判断两个类别变量是否独立,难以得出确切的结论。对于多个类别变量,如果要分析任意两个变量之间是否独立,可以使用 Pearson卡方检验
该检验的原假设是:二维列联表中的行变量与列变量独立。如果检验的P值较小足以拒绝原假设,则表示行变量与列变量不独立,或者说二者之间具有相关性
独立性检验的P值图则列出 Pearson 卡方检验的P值
# 性别、网购次数、满意度的Pearson卡方独立性检验的P值矩阵
library(sjPlot)
sjp.chi2(data3_1,show.legend=TRUE,legend.title="P值色标",title="Pearson卡方独立性检验") # 绘制出图例和标题