Transformer模型简介
简介
Transformer 是 Google 团队在 17 年 6 月提出的 NLP 经典之作,
由 Ashish Vaswani 等人在 2017 年发表的论文 Attention Is All You Need 中提出。
Transformer 在机器翻译任务上的表现超过了 RNN,CNN,只用 encoder-decoder 和 attention 机制就能达到很好的效果,最大的优点是可以高效地并行化。
Transformer 整体结构
首先介绍 Transformer 的整体结构,下图是 Transformer 用于中英文翻译的整体结构:
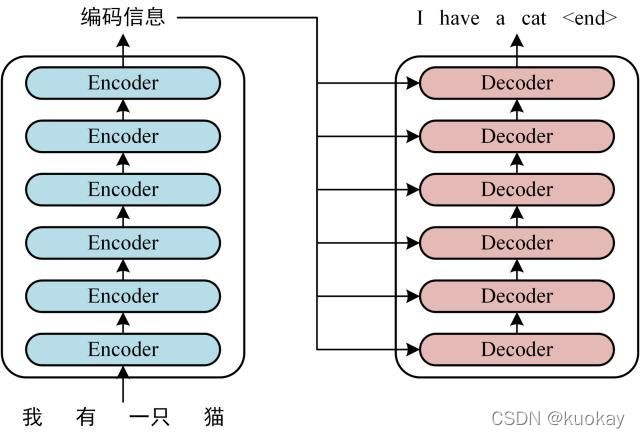
可以看到 Transformer 由 Encoder 和 Decoder 两个部分组成,Encoder 和 Decoder 都包含 6 个 block。Transformer 的工作流程大体如下:
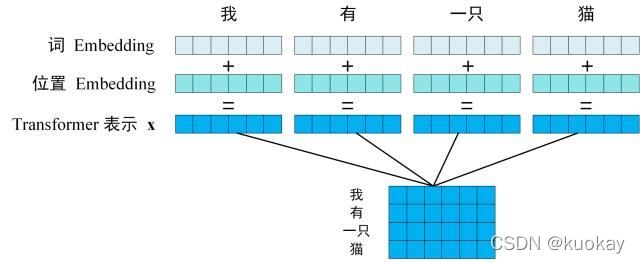
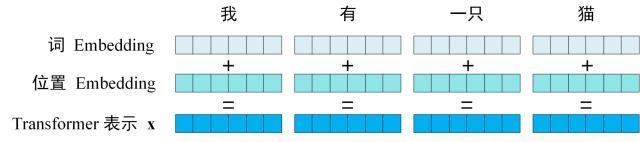
第一步:获取输入句子的每一个单词的表示向量 X,X由单词的 Embedding(Embedding就是从原始数据提取出来的Feature) 和单词位置的 Embedding 相加得到。
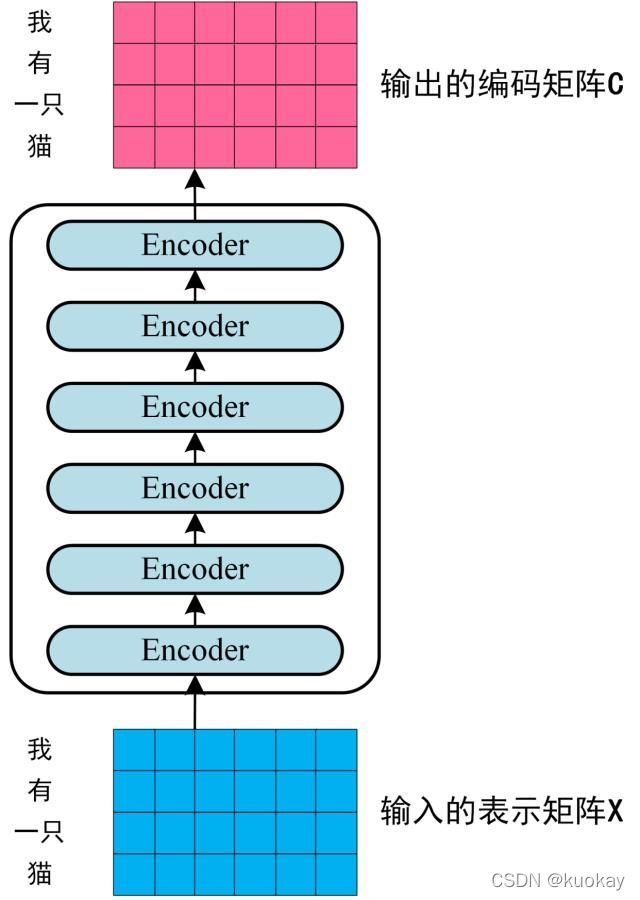
第二步:将得到的单词表示向量矩阵 (如上图所示,每一行是一个单词的表示 x) 传入 Encoder 中,经过 6 个 Encoder block 后可以得到句子所有单词的编码信息矩阵 C,如下图。单词向量矩阵用 [公式] 表示, n 是句子中单词个数,d 是表示向量的维度 (论文中 d=512)。每一个 Encoder block 输出的矩阵维度与输入完全一致。
第三步:将 Encoder 输出的编码信息矩阵 C传递到 Decoder 中,Decoder 依次会根据当前翻译过的单词 1~ i 翻译下一个单词 i+1,如下图所示。在使用的过程中,翻译到单词 i+1 的时候需要通过 Mask (掩盖) 操作遮盖住 i+1 之后的单词。
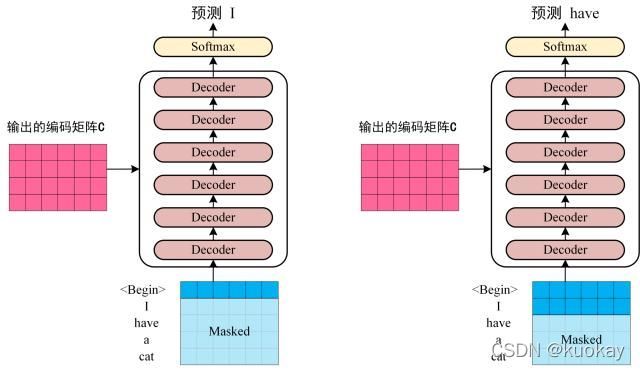
上图 Decoder 接收了 Encoder 的编码矩阵 C,然后首先输入一个翻译开始符 “”,预测第一个单词 “I”;然后输入翻译开始符 “” 和单词 “I”,预测单词 “have”,以此类推。这是 Transformer 使用时候的大致流程,接下来是里面各个部分的细节。
Transformer 的输入
Transformer 中单词的输入表示 x由单词 Embedding 和位置 Embedding (Positional Encoding)相加得到。
单词 Embedding
单词的 Embedding 有很多种方式可以获取,例如可以采用 Word2Vec、Glove 等算法预训练得到,也可以在 Transformer 中训练得到。
位置 Embedding
Transformer 中除了单词的 Embedding,还需要使用位置 Embedding 表示单词出现在句子中的位置。因为 Transformer 不采用 RNN 的结构,而是使用全局信息,不能利用单词的顺序信息,而这部分信息对于 NLP 来说非常重要。所以 Transformer 中使用位置 Embedding 保存单词在序列中的相对或绝对位置。
位置 Embedding 用 PE表示,PE 的维度与单词 Embedding 是一样的。PE 可以通过训练得到,也可以使用某种公式计算得到。在 Transformer 中采用了后者,计算公式如下:
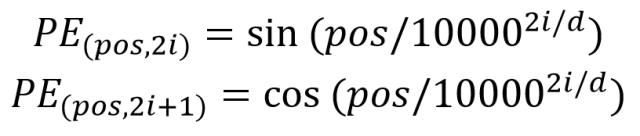
其中,pos 表示单词在句子中的位置,d 表示 PE的维度 (与词 Embedding 一样),2i 表示偶数的维度,2i+1 表示奇数维度 (即 2i≤d, 2i+1≤d)。使用这种公式计算 PE 有以下的好处:
- 使 PE 能够适应比训练集里面所有句子更长的句子,假设训练集里面最长的句子是有 20 个单词,突然来了一个长度为 21 的句子,则使用公式计算的方法可以计算出第 21 位的 Embedding。
- 可以让模型容易地计算出相对位置,对于固定长度的间距 k,PE(pos+k) 可以用 PE(pos) 计算得到。因为 Sin(A+B) = Sin(A)Cos(B) + Cos(A)Sin(B), Cos(A+B) = Cos(A)Cos(B) - Sin(A)Sin(B)。
将单词的词 Embedding 和位置 Embedding 相加,就可以得到单词的表示向量 x,x 就是 Transformer 的输入。
Attention
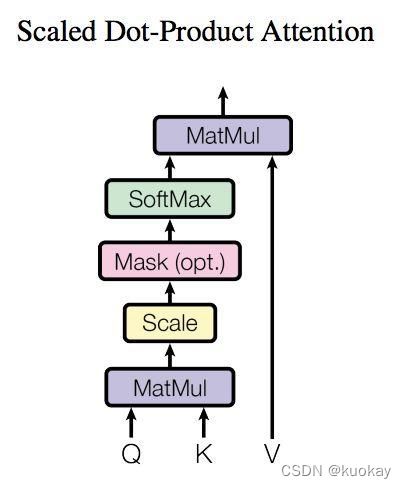
Scaled dot-product attention
“Scaled dot-product attention”如下图所示,其输入由维度为d的查询(Q)和键(K)以及维度为d的值(V)组成,所有键计算查询的点积,并应用softmax函数获得值的权重。
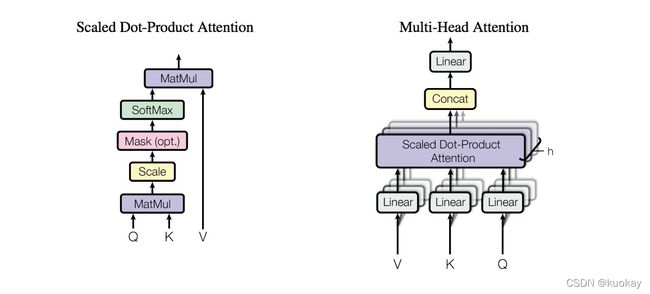
“Scaled dot-product attention”具体的操作有三个步骤:
- 每个query-key 会做出一个点乘的运算过程,同时为了防止值过大除以维度的常数
- 最后会使用softmax 把他们归一化
- 再到最后会乘以V (values) 用来当做attention vector
数学公式表示如下:

在论文中, 这个算法是通过queries, keys and values 的形式描述的,非常抽象。这里用了一张CMU NLP课里的图来进一步解释, Q(queries), K (keys) and V(Values), 其中 Key and values 一般对应同样的 vector, K=V 而Query vecotor 是对应目标句子的 word vector。如下图所示。
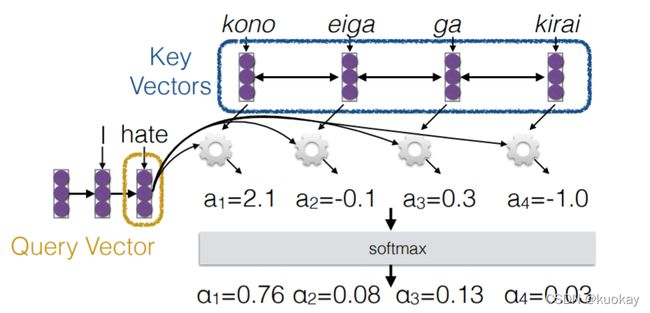
Multi-head attention
上面介绍的scaled dot-product attention, 看起来还有点简单,网络的表达能力还有一些简单所以提出了多头注意力机制(multi-head attention)。multi-head attention则是通过h个不同的线性变换对Q,K,V进行投影,最后将不同的attention结果拼接起来,self-attention则是取Q,K,V相同。

Self-Attention
因为 Self-Attention是 Transformer 的重点,所以我们重点关注 Multi-Head Attention 以及 Self-Attention,首先详细了解一下 Self-Attention 的内部逻辑。
结构
上图是 Self-Attention 的结构,在计算的时候需要用到矩阵Q(查询),K(键值),V(值)。在实际中,Self-Attention 接收的是输入(单词的表示向量x组成的矩阵X) 或者上一个 Encoder block 的输出。而Q,K,V正是通过 Self-Attention 的输入进行线性变换得到的。
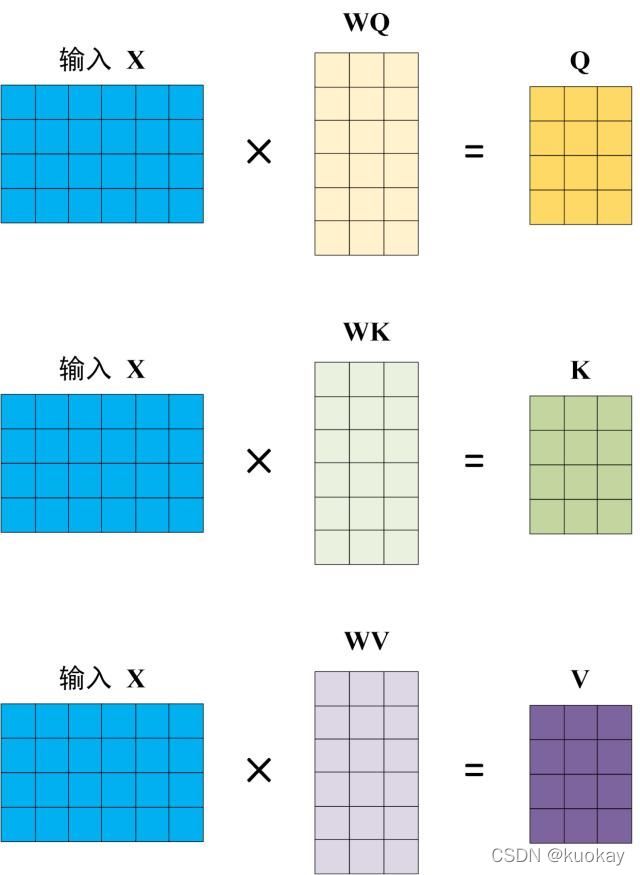
Q, K, V 的计算
Self-Attention 的输入用矩阵X进行表示,则可以使用线性变阵矩阵WQ,WK,WV计算得到Q,K,V。计算如下图所示,注意 X, Q, K, V 的每一行都表示一个单词。
Self-Attention 的输出
得到矩阵 Q, K, V之后就可以计算出 Self-Attention 的输出了,计算的公式如下:

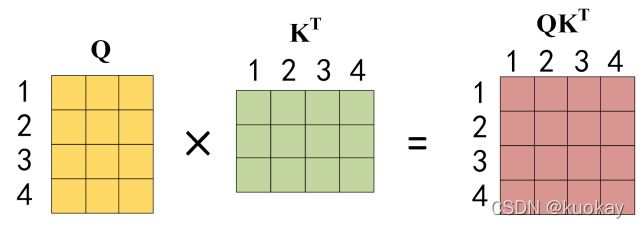
公式中计算矩阵Q和K每一行向量的内积,为了防止内积过大,因此除以 [公式] 的平方根。Q乘以K的转置后,得到的矩阵行列数都为 n,n 为句子单词数,这个矩阵可以表示单词之间的 attention 强度。下图为Q乘以 [公式] ,1234 表示的是句子中的单词。
得到QKt之后,使用 Softmax 计算每一个单词对于其他单词的 attention 系数,公式中的 Softmax 是对矩阵的每一行进行 Softmax,即每一行的和都变为 1.
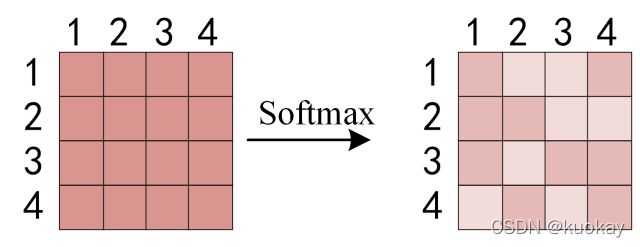
得到 Softmax 矩阵之后可以和V相乘,得到最终的输出Z。
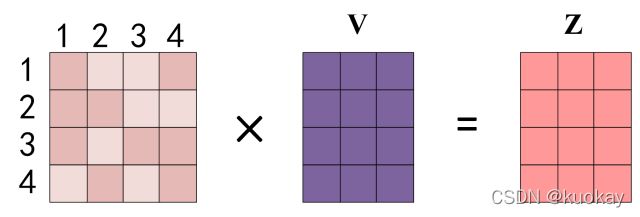
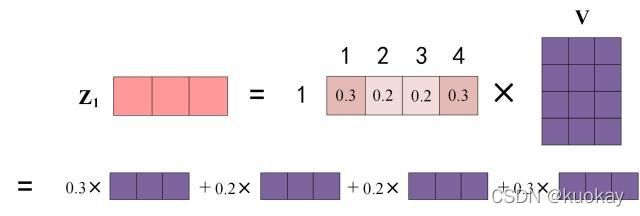
上图中 Softmax 矩阵的第 1 行表示单词 1 与其他所有单词的 attention 系数,最终单词 1 的输出 Z1等于所有单词 i 的值 Vi根据 attention 系数的比例加在一起得到,如下图所示:
Encoder 结构和Decoder 结构
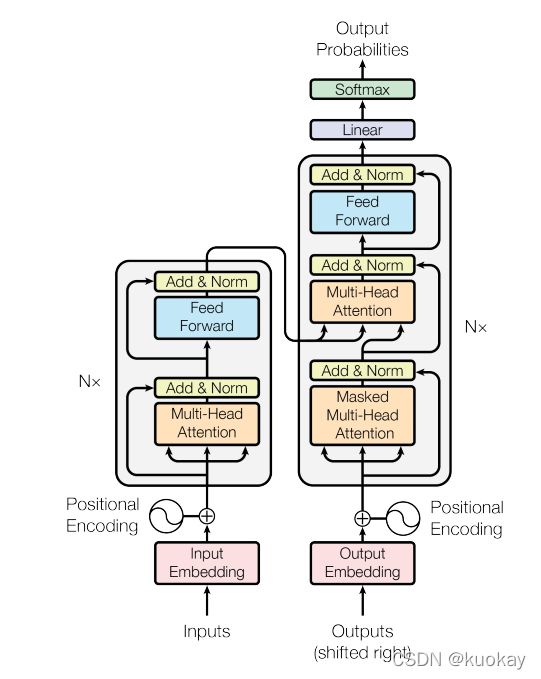
如图所示是谷歌提出的transformer 的架构。这其中左半部分是 encoder 右半部分是 decoder。
-
Encoder: 由N=6个相同的layers组成, 每一层包含两个sub-layers. 第一个sub-layer 就是多头注意力层(multi-head attention layer)然后是一个简单的全连接层。 其中每个sub-layer都加了residual connection(残差连接)和normalisation(归一化)。
-
Decoder: 由N=6个相同的Layer组成,但这里的layer和encoder不一样, 这里的layer包含了三个sub-layers, 其中有一个self-attention layer, encoder-decoder attention layer 最后是一个全连接层。前两个sub-layer 都是基于multi-head attention layer。这里有个特别点就是masking, masking 的作用就是防止在训练的时候 使用未来的输出的单词。比如训练时,第一个单词是不能参考第二个单词的生成结果的。Masking就会把这个信息变成0,用来保证预测位置 i 的信息只能基于比 i 小的输出。