(一)卡尔曼滤波器前述- α−β−(γ)滤波器
本文参考卡爾曼濾波
Kalman Filter in one dimension
一个预测的例子

雷达跟踪系统向目标方向发射一个笔尖型射束用于追踪目标。假设发射周期为5S,因此,雷达系统会在每5秒的时间后通过向目标方向发射专用的跟踪射束来定位目标。在发射射束之后,雷达系统会估算当前目标的位置和速度。与此同时,雷达系统也会预测下一个发射束应该发送到哪一个位置。
通过牛顿运动方程,我们能很容易计算出目标在下一个发射周期的位置:

将上述公式映射到三维空间,我们可以将牛顿运动方程作为系统的方程:

将x,y,z,vx,vy,vz,ax,ay,az记作为系统的状态方程。通过将当前系统状态代入到系统方程中,可以得到目标的下一个系统状态。上述的方程被成为动态模型(空间状态模型),是一种描述输入和输出关系的方法。
我们知道当我们有了当前系统状态和掌握系统的动态模型之后,我们就能很容易地预测出目标的下一个状态?
首先,雷达系统的测量数值不是完全可靠,它包含随机误差(或者这类型的不确定性)。这些随机错误的大小取决于很多因素,例如雷达自身的准确性,发射光束的宽度,返回信号强弱等等。这些测量误差被称为测量噪声。
因为有很多外部因素会做成干扰,目标运动并不是完全按着运动方程。例如:风向,空气流动,驾驶策略等等。这个动态模型误差被称为处理噪声。
在此类问题的应用上,使用卡尔曼滤波器是一个很普遍的解决方法。
在开始之前,我们将解释几个基本的术语,包括 variance,standard deviation, estimate(方差,标准差,正态分布,估计,准确度,精密度,均值,期望值和随机变量).
均值和期望值
均值 Mean 和 期望值 Expected Value 是两个相似但不相同的概念。


上述的结果并不是期望值,因为系统的状态(硬币的值)是可观测的, 并且我们用所有个体(全部的5枚硬币)来计算均值。
现在比方说一个人测量了5次体重,5次的结果分别是:79.8kg,80kg,80.1kg,79.8kg,和80.2kg。体重秤的随机测量误差导致每次的测量结果不同。我们无法知道体重的真实值,因为它是一个隐变量Hidden Variable,但我们可以通过平均多次测量值来估计体重。

估计的结果就叫做体重的期望值,均值通常用希腊字母 μ 表示,期望值通常用 E 表示。
方差和标准差
方差 Variance 用来衡量一组数据的离散程度。
标准差 Standard Deviation 是方差的算数平方根。标准差用希腊字母 σ(sigma)表示,方差即为 σ2。
方差用来衡量一组数据的离散程度,即个体数据与均值的偏差。第一步,用个体值减均值来计算个体值到均值的距离。
假设我们想比较两所高中篮球队的身高,各队队员的身高和平均身高如下表所示。

两队平均身高相同,我们可以进一步比较两队身高的标准差。
我们用 xx 表示身高,希腊字母 μ表示平均身高。个体值到平均值的距离为:

下表列出了每个个体值到平均值的距离。

为了去掉负值,第二步,求出离均值距离的平方:

最后,平均各队离均值距离的平方得到方差:

由于方差的单位是平方,因此使用标准差比较方便。标准差就是方差的算数平方根。

如果我们想计算所有高中全部队员身高的均值和方差,是非常困难的,我们需要收集所有高中球员的身高数据。不过,我们也可以先收集一个大数据集,通过计算这个数据集来估计所有队员身高的均值和方差。随机选取100个队员,获得的数据集足以进行准确的估计。
注意这时计算方差的方程略有不同。除数不是 N, 而是 N−1:

这个网站有上面公式的数学证明:Why divide the sample variance by N-1? - Computer vision for dummies
正态分布
研究表明,许多自然现象都遵循正态分布 Normal Distribution。
正态分布又名高斯分布(以数学家Carl Friedrich Gauss的名字命名), 其公式如下:

测量误差通常呈正态分布。因此,我们在设计卡尔曼滤波器的时候假设测量误差呈正态分布。
所有的测量值都是连续随机变量。
估计,准确度和精密度
估计 Estimate用来估算系统的不可见状态。飞机的真实位置对观察者来说是不可见的。我们可以用雷达等传感器估计飞机的位置,并通过使用多个传感器和高级估计及追踪算法(如卡尔曼滤波器)来显著地提升估计的准确度。测量或计算出的的参数都是估计值。
准确度 Accuracy表示测量值与真实值的接近程度。
精密度 Precision表示测量结果的再现性。估计需要考虑系统的准确性与精密性。

随机测量误差会导致方差,高精密度系统的方差较小(不确定度低),而低精密度系统的方差较大(不确定度高)。
低精度系统被称为有偏 biased系统,因为其测量值都存在一个固有的系统性误差(偏差)。
对测量值进行平均或平滑处理可以显著降低方差的影响。例如,如果我们使用带有随机测量误差的温度计来测量温度,随机的误差将导致一些测量值高于真实值,一些低于真实值。我们可以进行多次测量并对其求平均值,这个估计值会接近真实值,测量次数越多,估计值就越接近。

测量值的均值和真实值的差名为偏差 bias 或 系统误差 systematic measurement error,用来表明测量精度 measurements accuracy。
分布的离散程度就是测量值的精密度 precision,又名测量噪声 measurement noise或随机测量误差 random measurement error或测量不确定性 measurement uncertainty。
在这个例子中,我们要估计静态系统的状态。静态系统是指在相当一段时间内不改变状态的系统。
例子1 – 金条重量
在本例中,我们将估计金条的重量。我们将使用一个无偏秤,也就是说,它没有系统误差,但有随机噪声。

系统是金条,系统的状态就是金条的重量。假设金条的重量在短时间内不发生变化,即系统的动态模型是恒定的。 为了估计系统的状态(金条的重量),可以进行多次测量并求平均值。

经过n次测量,估计值x^n,n是所有测量值的平均值:


本例中的动态模型是定值,所以![]()
想要估计第n次的值 ,我们需要记住所有历史测量数据。假设我们没有笔和纸来记录,也不能凭的记忆记下所有的历史测量数据。但我们可以仅用上一次的估计值和一点小小的调整(在现实生活的应用中,我们想节省计算机内存),以及一个数学小技巧来做到这一点:

上述方程是卡尔曼滤波五个方程之一,名为状态更新 State Update Equation。其含义为:

系数 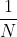 对于这个例子是特定的。稍后我们将讨论这个系数的重要作用,在卡尔曼滤波中,这个系数叫做 卡尔曼增益 Kalman Gain,记作 Kn ,脚标 n 表示卡尔曼增益随每次迭代而变化。
对于这个例子是特定的。稍后我们将讨论这个系数的重要作用,在卡尔曼滤波中,这个系数叫做 卡尔曼增益 Kalman Gain,记作 Kn ,脚标 n 表示卡尔曼增益随每次迭代而变化。
在我们深入学习卡尔曼滤波器前,会使用希腊字母 ![]() 来代替
来代替![]() .因此状态更新方程为:
.因此状态更新方程为:
![]()
![]() 称为观测残差,叫做更新innovation。
称为观测残差,叫做更新innovation。
本例中, 随着 N的增加而减少。这意味着刚开始时权重值没有足够的信息,因此估计基于 测量结果。随着迭代的继续,一直减小,每一次的测量值在估算中的权重越来越小。迭代足够多后,新的测量值对估计值的影响可以忽略不记。
让我们继续看这个例子,在进行第一次测量前,可以通过金条上的图章来猜测(或粗略估计)金条的重量。这个初始猜测 Initial Guess也就是第一个估计值。后面会讲到,卡尔曼滤波器需要预设一个初始猜测值,这个值不用很精准。
估计算法

数值案例:
第0次迭代:初始化
我们对金条重量的初步估计是1000克。滤波器初始化操作仅需一次,不会用在下一次迭代中。
![]()
预测:
金条的重量是不变的,因此系统的动态模型是静态的,状态的下一个估计值(预测值)等于初始值:
![]()
第一次迭代:
步骤1
第一次秤重: ![]()
步骤2
计算增益,在本例中![]() ,
,
![]() ,用状态更新方程计算当前估计值:
,用状态更新方程计算当前估计值:
![]()
步骤3
系统的动态模型是静态的,因此金条的重量不会改变,状态的下一个估计值(预测值)等于当前的估计值:![]()


如图所示,估计算法对测量值有平滑效果,估计值会趋近真实值。
例子2 – 在一维空间中追踪匀速飞行器
在这个例子中,我们用α-β 滤波器在一维空间中追踪匀速飞行的飞行器。
假设在一个一维空间,有一架飞行器正在向远离雷达(或朝向雷达)的方向飞行。在一维空间中,雷达的角度不变,飞行器的高度不变,如下图所示。

 代表飞行器在n时刻的位置,
代表飞行器在n时刻的位置,
![]()
雷达以恒定频率向目标方向发射追踪波束,周期为 .
.
假设飞行器速度恒定,系统的动态模型可以用两个运动方程来描述:

 滤波器
滤波器
若雷达的跟踪周期为5秒,假设在n-1时,无人机的估计位置为30000米,估计速度为40m/s
使用状态外推方程:可以预测在n时的位置为:
![]()
速度为匀速
![]()
但在n时刻,雷达的测量位置为:30110m,并不是预测的30200m。预期(预测)航程和测量航程之间有90m的偏差,造成这种偏差的可能原因有两个:
- 雷达测量不精确
- 飞行器速度改变了。新速度为:

速度的状态更新方程:
![]()
系数 β 的值取决于雷达的精确程度。假设1 的精度为20m,更有可能是飞行器速度的变化导致预测距离和测量距离之间的90米的偏差。在这种情况下,我们将系数β 调高,将β 设为0.9,则估计的速度为
的精度为20m,更有可能是飞行器速度的变化导致预测距离和测量距离之间的90米的偏差。在这种情况下,我们将系数β 调高,将β 设为0.9,则估计的速度为
![]()
假设1的精度为150m,则倾向于雷达的测量误差造成了90米的偏差。在这种情况下,将系数β 调低,将β 设为0.1,则估计的速度为
![]()
飞行器位置的状态更新方程与上一个例子中推导的方程类似:
![]()
与上一个例子不同的是,上一个例子中每次迭代需要重新计算系数 α,而在这个例子中系数 α是常数。
α的大小取决于雷达测量精度。对于高精度雷达,我们将选择高 α ,这将给测量带来很高的权重,如果 α=1,则估计位置等于测量位置。α=0,则测量没有意义。
我们得到了雷达追踪器的状态更新方程组,它们也被称为α-β轨迹更新方程α−β track update equations,或者称为α-β轨迹滤波方程α−β track filtering equations。
 使用α=0.2,β =0.1,如下图所示
使用α=0.2,β =0.1,如下图所示

估计值具有平滑的作用
使用高的α=0.8,β =0.5

估计值非常接近测量值,预测的误差比较大。
总结:α,β 的值应当取决于测量的精度,如果使用高精度设备,如激光radar,我们更相信测量值,选择高的α,β。在本例中,滤波器将会快速的响应目标速度的变化。另一方面,若测量的精度很低,则选择更小的α,β,在这种情况下,滤波器平滑测量中的不确定(误差),但是滤波器对目标速度的反映并不快。
例子3 – 在一维空间中追踪加速飞行器
现在来看一架战斗机,它先以50m/s的恒定速度飞行15秒,然后以8m/s2的加速度匀加速飞行35秒。下图显示了目标航程、速度、加速度随时间的变化。

从这张图中可以看出,前15秒内飞行器的速度是不变的,在15秒之后呈线性增长。前15秒内距离的增长是线性的,随后呈平方增长。用的α-β滤波来追踪这个飞行器。
α−βα−β 滤波器的参数分别是:
- α=0.2
- β=0.1
雷达追踪周期为5秒。
第0次迭代:初始化

n=1,


可以看到真实值或测量值与估计值之间存在一个固定的差值,这个差值被称为滞后误差lag error。滞后误差的其他常见名称有:
- 系统误差 Systematic error
- 动态误差 Dynamic error
- 偏移误差 Bias error
- 截断误差 Truncation error
恒定加速度会导致滞后误差。
包含加速度动态模型的 α−β−γ滤波器可以追踪匀加速运动的目标,并且消除滞后误差。
α−β−(γ)滤波器总结
α−β−(γ) 滤波器有许多类型,它们基于相同的原理:
- 当前状态估计基于状态更新方程;
- 状态的下一个估计值(预测值)基于动态模型方程;
这些滤波器之间的主要区别在于加权系数 α−β−(γ)的选择。有些滤波器使用恒定的加权系数,有些则需要在每次迭代(循环)时计算加权系数。
最常用的 α−β−(γ)α−β−(γ) 滤波器有:
- Wiener Filter 维纳滤波
- Bayes Filter 贝叶斯滤波
- Fading-memory polynomial Filter
- Expanding-memory (or growing-memory) polynomial Filter
- Least-squares Filter 最小二乘法滤波
- Benedict–Bordner Filter
- Lumped Filter
- Discounted least-squares α−βα−β Filter
- Critically damped α−βα−β Filter
- Growing-memory Filter
- Kalman Filter 卡尔曼滤波
- Extended Kalman Filter 扩展卡尔曼滤波
- Unscented Kalman Filter 无迹卡尔曼滤波
- Particle Filter 粒子滤波器