【异常检测-论文阅读】(CVPR 2022)Self-Supervised Predictive Convolutional Attentive Block for Anomaly Detection
来源:
Ristea N C, Madan N, Ionescu R T, et al. Self-supervised predictive convolutional attentive block for anomaly detection[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022: 13576-13586.
文章地址:https://arxiv.org/abs/2111.09099
code:GitHub - ristea/sspcab
本文的创新之处:
本文提出将基于重构的功能整合到一个新颖的自监督预测架构模块中。提出的自监督模块是通用的,可以很容易地被纳入各种最先进的异常检测方法。
We propose to integrate the reconstruction-based functionality into a novel self-supervised predictive architectural building block. The proposed self-supervised block is generic and can easily be incorporated into various state-of-the-art anomaly detection methods.
引入了一种新的神经块SSPCAB(Self-Supervised Predictive Convolutional Attentive Block),该神经块由一个掩码卷积层和一个通道注意模块组成,用于预测卷积接受域中的一个掩码区域。
- 我们引入了一种新的自我监督预测卷积注意块,它本身就具有执行异常检测的能力。
- 我们将该块集成到多个最先进的神经模型[18,34,37,39,49,79]中进行异常检测,在多个模型和基准测试中显示出显著的性能改进。
包括了 image 和 video 的异常检测
[18] Mariana Iuliana Georgescu, Radu Ionescu, Fahad Shahbaz Khan, Marius Popescu, and Mubarak Shah. A Background-Agnostic Framework with Adversarial Training for Abnormal Event Detection in Video. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021.
[34] Chun-Liang Li, Kihyuk Sohn, Jinsung Yoon, and Tomas Pfister. CutPaste: Self-Supervised Learning for Anomaly Detection and Localization. In Proceedings of CVPR, pages 9664–9674, 2021.
[37] Wen Liu, Weixin Luo, Dongze Lian, and Shenghua Gao. Future Frame Prediction for Anomaly Detection – A New Baseline. In Proceedings of CVPR, pages 6536–6545, 2018
[39] Zhian Liu, Yongwei Nie, Chengjiang Long, Qing Zhang, and Guiqing Li. A Hybrid Video Anomaly Detection Framework via Memory-Augmented Flow Reconstruction and FlowGuided Frame Prediction. In Proceedings of ICCV, pages 13588–13597, 2021.
[49] Hyunjong Park, Jongyoun Noh, and Bumsub Ham. Learning Memory-guided Normality for Anomaly Detection. In Proceedings of CVPR, pages 14372–14381, 2020.
[79] Vitjan Zavrtanik, Matej Kristan, and Danijel Skocaj.DRAEM – A Discriminatively Trained Reconstruction Embedding for Surface Anomaly Detection. In Proceedings of ICCV, pages 8330–8339, 2021.
methods
CNN 是由具有核的卷积层构成的,这些卷积层学习对区分性局部模式进行激活,以解决所需的任务。从这个学习过程中,出现了一系列特征,从低级特征(角落、边缘等)到高级特征(车轮、鸟头等)[80]。正如 Sabour [60等人所指出的那样,尽管这种特征层次结构非常强大,但是 CNN 缺乏理解这种局部特征的全局排列的能力。
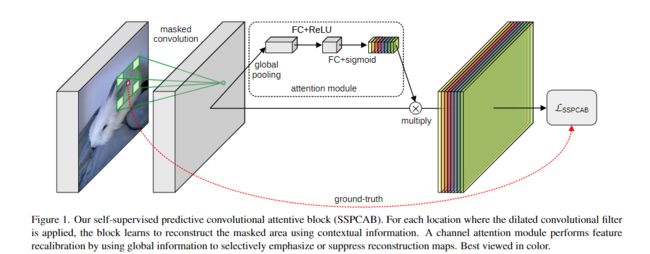
本文提出了一种新的自监督预测卷积注意块(SSPCAB)【结构图如图1】 ,用于学习利用上下文信息预测(或重构)被掩盖的信息。为了获得高度精确的重建结果,我们的块被迫学习发现的局部模式的全局结构。因此,它解决了[60]中指出的问题,即CNN不能把握局部特征的全局排列,因为它们不能推广到新的视点或仿射变换。
为了实现这种行为,我们将块设计为一个带有扩张的屏蔽过滤器的卷积层(Masked convolution),后面跟着一个通道注意模块(SE Channel attention)。该模块具有自己的损失函数,目的是最小化掩蔽输入与预测输出之间的重构误差。
SSPCAB可以集成到几乎任何CNN架构中,能够学习重建掩蔽信息,同时提供用于后续神经层的有用特征。
Masked convolution
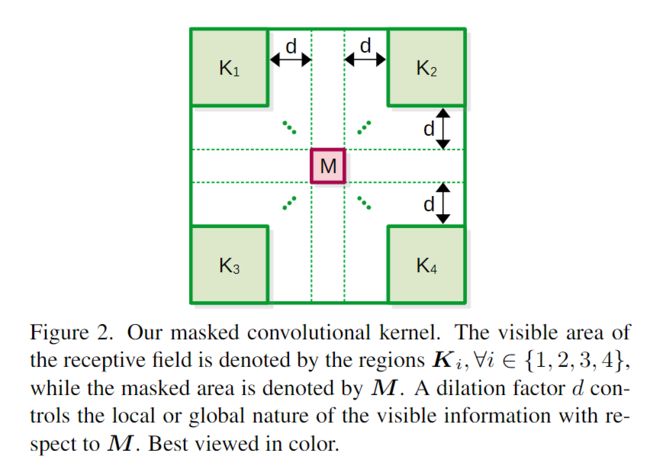
我们的卷积滤波器的感受野如图2所示。
其中,
M 就是被掩蔽的区域(感受野的中心,文章中设定大小为1),K1~K4 就是四个子卷积,d指的是 dilation rate(膨胀率,即每个子卷积到M的距离)。k' 为子卷积K1~K4 的卷积核大小。
我们的感受野的空间大小k可以计算如下:
![]()
- 在输入X的某个位置使用我们的自定义内核执行的卷积操作只考虑来自子内核Ki所在位置的输入值,其他信息将被忽略。
- 四个sub-kernal的输出求和 作为M位置(mask)的输出,输出是一个单值。(这里不管M的大小多少,只能从掩码向量M中预测当前位置的一个值)。
- 为了预测M中每个通道的值,我们引入了许多c个掩码卷积滤波器,每个都预测来自不同通道的掩码信息。(感觉也就表明了后面为什么加上通道注意力)
- 执行卷积过后 保持大小不变(宽高不变),需要卷积前在输入周围k' + d像素执行零填充,并设置stride为1,保证输入中的每个像素都被用作掩码信息。(因为我们的目标是学习和预测输入的每个空间位置的重建)
Channel attention module
可以自行查阅 Squeeze-and-Excitation Networks(SENet)相关知识。
也可以转到:学习--注意力机制_不喝可乐不快乐的博客-CSDN博客_常见注意力机制
Reconstruction loss
G表示 SSPCAB 块,也就是SSPCAB的输出结果 与 输入 的均方误差(MSE)。
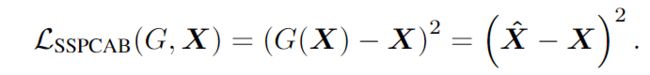
F 表示一个整合了SSPCAB块的神经网络模型,![]() 表示原始模型的损失。
表示原始模型的损失。

Experiments and Results
主要看了一下视频异常检测部分。在Avenue和ShanghaiTech 两个数据集上做了验证。
验证指标包括:area under the curve (AUC),he region-based detection criterion (RBDC) and track-based detection criterion (TBDC)。
文中指出 超参数λ = 0.1 (除了【39】 λ减小到0.01)
1.Preliminary Results
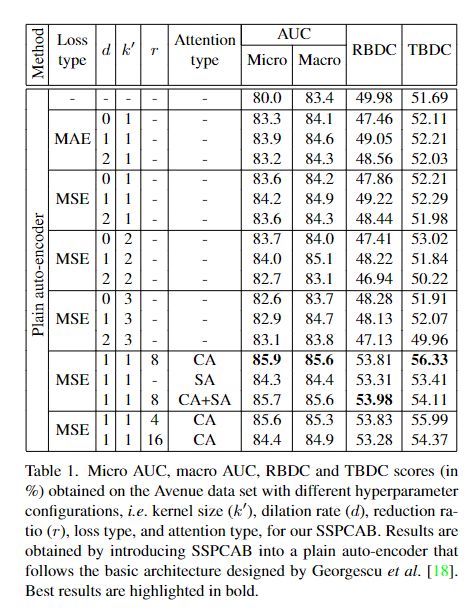
- 使用 Mean Absolute Error (MAE) and Mean Squared Error(MSE) 两种不同损失函数的对比
- 不同的 子卷积核大小k' 与 dilation rate (d)的对比
- 使用空间注意力 (spatial attention (SA))与 通道注意力 (channel attention (CA))以及 SA+CA 的对比
- 通道注意力 中不同比例的reduction rates (r默认 8)的对比
结论 :
MSE +(d = 1) + (k' = 1) + (CA) + (r =8) 总体性能更好
2.Abnormal Event Detection in Video
选择了四种最近引入的方法[18、37、39、49](前面有给出具体那几篇),它们在视频异常检测中达到了最先进的性能水平,作为整合SSPCAB的候选方法。
具体的结果对比如下表。


Conclusion
我们介绍了SSPCAB,一种由掩蔽卷积层和通道注意模块组成的新型神经块,用于预测卷积感受野中的掩蔽区域。我们的神经块以自监督的方式训练,通过其自身的重建损失。为了展示在异常检测中使用SSPCAB的好处,我们将我们的块集成到一系列图像和视频异常检测方法中[18、34、37、39、49、79]。我们的实证结果表明,SSPCAB在几乎所有情况下都带来了性能改进。初步结果表明,掩蔽卷积和通道注意力都有助于性能增益。此外,在SSPCAB的帮助下,我们能够在Avenue和ShanghaiTech获得最新水平。我们认为这是一项重大成就。
Supplementary
Ablation Study
1. 对比 在不同的位置 使用SSPCAB 的结果
当SSPCAB集成到更接近输出时,改进似乎更大

2.为了研究增加M尺寸的效果,我们在Avenue上用普通自动编码器测试了3×3的尺寸。
当将结果与1×1或3×3的掩蔽核进行比较时,没有观察到显著差异。

Inference Time
评估SSPCAB增加的额外时间
报告的时间显示,两种框架的时间扩展均低于0.3毫秒。因此,我们认为SSPCAB带来的精度增益超过了表6中给出的运行时间扩展。

Discussion
必须注意的一个重要方面是,由于掩蔽卷积,我们的块将不完全重建输入。除了输入是常数的退化情况外,这种情况不应该发生在现实世界中,这意味着SSPCAB进行的重建不是微不足道的。然而,我们对SSPCAB有用性的最重要直觉是不同的:我们的块对正常卷积特征提供了比异常卷积特征更好的重建。如果在神经结构的任何一层,正常和异常示例的特征是不同的,那么在该结构的最终输出中就会产生更大的差异。表4所示的实验也支持这一想法。
进一步查看表4所示的结果,我们观察到,当块放置在输入附近时,SSPCAB并没有带来显著的增益。我们的目标是在未来的工作中进一步研究这一局限性。除了这个小问题,我们在实验中没有观察到SSPCAB的其他局限性。