007利用癫痫脑电图数据检测癫痫发作和特征频率的深度卷积神经网络方法-2021
A Deep Convolutional Neural Network Method to Detect Seizures and Characteristic Frequencies Using Epileptic Electroencephalogram (EEG) Data
Abstract
背景:脑电(EEG)结合深度学习计算方法诊断癫痫发作近年来备受关注。然而,到目前为止,深度学习技术在癫痫发作检测中的应用还没有得到有效的利用,原因是分类器设计不够优化,以及对时域信号的表示不正确。方法:在这项研究中,我们重点设计和评估了基于深度卷积神经网络的癫痫发作检测分类器。提出了一种信号-图像转换方法,将时域脑电信号转换为时频表示的图像,为输入数据的分类做准备。我们提出并评估了由五个分类器组成的三种分类方法,以确定哪种方法对癫痫发作检测更准确。然后将精确度数据与之前对同一数据集的研究进行比较。结果:我们发现我们提出的模型和信号-图像转换方法在大多数情况下都优于以往的研究。提出的FT-VGG16分类器的平均分类正确率最高,达到99.21%。此外,采用Shapley加性解释(Shap)分析方法来发现EEG中对提高分类精度贡献最大的特征频率。据我们所知,这是第一次计算频率成分对目标癫痫分类的贡献;因此,与正常脑电测量相比,可以识别与癫痫相关的不同的脑电频率成分。
结论:所建立的深卷积神经网络模型可用于从患者脑电数据中检测癫痫发作和特征频率,该模型可用于临床癫痫发作的自动检测。
I. INTRODUCTION
癫痫是一种慢性神经系统疾病,全世界约有5000万人受到影响,每年约有240万人新诊断[1]。脑电(EEG)是一种广泛使用的非侵入性技术,用于测量脑电活动和诊断癫痫。脑电数据的分析和解释通常是由神经科医生通过人工视觉检查进行的。然而,目视检查脑电痕迹是耗时的,给治疗医生带来了沉重的负担。这些问题促使人们在应用自动癫痫检测技术方面做出了重大努力,以帮助神经科医生加快诊断过程,从而提高准确性。此外,研究癫痫发作数据中的频率特征对于我们从根本上理解癫痫发作的脑电轨迹具有重要意义。
许多研究报道了机器学习在癫痫发作自动检测中的应用。例如,几种浅层机器学习技术,包括神经系统和支持向量机(SVM)方法已被用于癫痫分类[2];然而,仍然需要开发改进的算法来实现更高的分类精度,以便为临床应用开发自动化的人工智能系统和工具。
将机器学习的应用,特别是新兴的深度学习领域,扩展到自动癫痫检测中的脑电图信号分类,有相当大的需求。深度学习在疾病诊断中的应用总体上正在增长,已经发表了一些研究,但性能有限[3]-[5]。近年来,利用机器和深度学习技术对癫痫性和非癫痫性脑电图信号[6]-[14]进行了具体分类问题的研究。然而,基于深度学习的疾病自动分类方法仍有很大的改进空间。
最近的一项癫痫检测研究使用13层深度1D CNN和波恩大学的数据库,达到了88.67%的分类准确率[9]。基于CNN的模型还使用Freiburg和CHB-MIT数据库用于癫痫发作检测,分别获得了96.7%和97.5%的高精度结果[15]。
在另一项研究中,使用波恩大学数据库提出了一个用于二元(癫痫发作与非癫痫发作)分类的金字塔一维CNN模型[7]。利用TUH数据库的深度CNN模型,获得了30.83%的敏感性和96.86%的特异性[16]。除了基于CNN的模型,许多研究使用基于熵的脑电图特征进行癫痫检测[17]-[19]。支持向量机和多层感知器也用于癫痫发作的检测[17],[20]。
为了提高结果,一些研究使用基于cnn的脑电信号分类器的频谱图像。
Bi和Wang[21]使用时域信号的光谱图像作为CNN模型的输入,用于疾病诊断。一项研究[22]使用基于傅立叶时频表示的STFT进行基于深度学习的癫痫分类,VGG16获得了79.71%的准确率。Raghu等人[14]利用天普大学医院数据库脑电图记录,提出了深度CNNs和脑电图谱图,准确率最高,达到84.06%。利用CNN和剧情脑电图图像输入对癫痫发作和非癫痫发作脑电图活动进行分类,真阳性率为74.0%[23]。基于图像的脑电图谱图表示被用作基于CNN的癫痫检测分类器[24]的输入。
从上述研究可以明显看出,深度学习模型在基于图像的癫痫检测应用中是有用的。然而,据我们所知,目前还没有有效的利用EEG时频图像数据的深度学习模型用于癫痫检测。
除了获得较高的分类精度外,了解对分类贡献最大的输入数据的特征通常也很重要。一种很有前途的技术叫做SHAP (SHapley Additive exPlanation)[25],它使用SHapley值通过计算特征的重要性来解释预测。通过使用SHAP,我们可以了解输入时频待测脑电图图像的显著频率特征。这些特征不同于其他类的输入,因为每个输入都为特定的预测分配了一个值。
在本研究中,我们提出了一种利用连续小波变换(CWT)进行时域信号到时频图像转换的方法,为深度学习模型准备输入数据。我们还提出了三种不同的分类方法,其中一个分类器由4个卷积层组成(方法1)。方法2和方法3采用了两种深度学习模型VGG16和ResNet50。所有方法都用CWT频谱图和STFT谱图进行了测试。我们还使用了SHAP和基于梯度的模型解释器来寻找脑电图发作与正常脑电图不同的特征频率,从而提高了分类精度。
II. MATERIALS AND METHODS
A. DATA 数据
我们使用了来自波恩大学资料库的脑电数据[26]。整个数据库由五个集合(A-E)组成,每个集合包含100个单通道EEG片段,持续时间为23.6秒。在视觉检查的基础上,已经从收集的数据中去除了肌肉活动和眼动伪影。脑电记录基于标准化的电极放置技术进行。
A组包含从五名清醒状态的健康受试者中收集的表面脑电记录,这些受试者睁眼。组B包含从相同受试者闭眼时获得的脑电。其他数据集(C、D和E)是在五名癫痫患者的术前诊断工作中收集的。组C包含脑电记录,这些记录是在无癫痫发作间隔期间从对侧大脑半球的海马结构记录的。组D包括在无癫痫发作期间从患者大脑癫痫区内收集的脑电信号。最后一组(E组)包含患者在癫痫发作活动期间的脑电记录。经12位A/D转换后的脑电信号采样率为173.61 Hz。
B. PREPROCESSING 预处理
虽然有许多一维CNN模型用于对时域信号进行分类,但二维CNN模型在分类问题中仍占有重要地位。由于时间域脑电信号可以被转换成二维(RGB)图像,因此我们选择了二维神经网络作为分类任务。我们将脑电信号分割成长度为1.47秒的片段,然后对每个片段进行信号到图像的转换。我们还考虑了脑电信号的时频转换的颜色(RGB)表示。本研究采用了短时傅里叶变换和连续小波变换这两种广泛使用的方法。
1) STFT
短时傅立叶变换(STFT)是一种广泛使用的时频分析方法[27]。短时傅立叶变换确定一段信号的局部部分的频率和相位。该分割通过使用帧来执行。由于帧随时间变化,STFT在基于时间的表示和基于频率的表示之间起到权衡的作用。因此,短时傅立叶变换能够在相应的时间点显示信号中包含的频率。使用以u为中心的移动窗口g(T)获取信号的短片段,并对这些片段执行傅里叶变换。最常见的是,汉明窗用于短时傅立叶变换。将长时间段f(T)的STFT定义为:
![]()
频谱图(短时傅里叶变换的能量面分布)计算如下:
![]()
我们在每个相应的时间得到不同的光谱,这些光谱的总和就是谱图。
2) CWT
连续小波变换被认为是对非平稳信号进行时频分析的有效方法。
实信号 ![]() 具有平移参数
具有平移参数![]() 、尺度参数 s>0 和小波函数ψ(T)的连续小波变换
、尺度参数 s>0 和小波函数ψ(T)的连续小波变换
![]()
这里,平移的时移τ可以被解释为分析信号所围绕的时间瞬间。
当s值较小时,连续小波变换在时刻τ附近提供信号的详细信息,即高频成分;而当连续小波变换较大时,连续小波变换在时刻附近提供较低频率成分。
被称为标量图的二维图像用于表示连续小波变换![]() 。由于所分析的信号是数字信号,因此计算连续小波变换
。由于所分析的信号是数字信号,因此计算连续小波变换![]() 的离散近似[28]。分别具有表示不同比例s和平移参数τ的行和列的矩阵被用来可视化近似的标量图。然而,在时频表示中,频率比尺度更传统。当f=1s时,我们将标度转换为频率。
的离散近似[28]。分别具有表示不同比例s和平移参数τ的行和列的矩阵被用来可视化近似的标量图。然而,在时频表示中,频率比尺度更传统。当f=1s时,我们将标度转换为频率。
C. CONVOLUTIONAL NEURAL NETWORKS (CNN)
一般来说,人工神经网络由三层组成,即输入层、隐含层和输出层。它被认为是一种信息处理范式,其灵感来自于人类大脑中生物神经系统的复杂网络结构。人工神经网络由称为节点或人工神经元的连通元素的集合组成。
这些人工神经元将来自上一层其他节点的输入信号整合在一起,并将其传递给下一层神经元。接收神经元通过将其在前一层中连接到的所有神经元的加权信号相加来产生其输出。在网络中,第一层是输入层,最后一层是输出层。
本研究采用了一种新的增强神经网络,称为卷积神经网络(Convolutional neural network, CNN)。基本CNN由四种类型的层组成,即卷积层、激活层、池化层和全连接层。卷积、激活和池化层旨在学习输入的特征表示,而第四个是执行分类的完全连接层。卷积层之后的非线性激活层负责捕获输入信号更复杂的特性。
卷积层由几个卷积核组成。每个内核负责计算不同的特征映射。该层的每个神经元只与上一层的一小部分局部区域相连,类似于人类视觉系统中的感受野。每层 l 有M个特征映射,每个大小为(Mx, My)。通过滑动一个大小为(Kx, Ky )在输入数据的有效区域上。跳过因子Sx和Sy,也称为步幅大小,定义了过滤器/内核在后续卷积之间在x和y方向上跳过多少像素。计算出的特征图的大小定义为:
![]()
![]()
其中 l 定义网络中的层,层 l 中的每个特征映射最多与层 l−1 中的 ![]() 映射相关联。内核由输入的所有空间位置共享,以生成特征映射。这种内核共享的优点是可以降低模型的复杂性,使网络训练更容易。
映射相关联。内核由输入的所有空间位置共享,以生成特征映射。这种内核共享的优点是可以降低模型的复杂性,使网络训练更容易。
不同的内核产生完整的特征映射。第l层(i, j)位置的第k个特征图 ![]() 计算为:
计算为:
![]()
其中![]() 为第 l 层位置 (i, j) 为中心的输入值,
为第 l 层位置 (i, j) 为中心的输入值, 和
和![]() 分别为第 l 层第 k 个滤波器的权向量和偏置项。
分别为第 l 层第 k 个滤波器的权向量和偏置项。
通过使用激活函数来实现对多层网络所需的输入非线性特征的检测。用 a(.) 表示的非线性激活函数产生卷积特征 ![]() 的激活值
的激活值![]() 为
为
![]()
池化层用于通过聚合小的矩形值子集来减少特征映射的体积。
使用两种类型的池,即Max和Average,分别用最大值或平均值替换输入值。对于每个特征映射![]() 池化函数p(.)的输出为
池化函数p(.)的输出为
![]()
其中 Rij 是位置(i, j)附近的一个本地社区。
在卷积/池化层之上的分类网络通常包含一组顺序的完全连接层,并由具有各种激活函数的节点组成。完全连接的层通常用作模型的最后几层。最后一个池化层的输出被压平,并被馈送给前馈神经网络,用于对输入进行分类。在完全连接的层之后,使用一个分类器来计算每个实例属于每个类的概率。最后一层被设计成具有与标签一样多的输出。输出层被softmax激活。对于给定的输入样本X, softmax函数预测第c类的概率为:
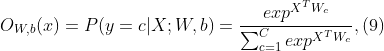
其中c是当前被评估的类,c是所有类,X是输入向量,W表示网络权重。
1) ResNet50
我们还使用残差神经网络(ResNet)对分类结果进行了比较。ResNet是由He等人在2015年ILSVRC竞赛中首次提出的。Resnet有一个短的连接结构,通过绕过输入信息直接到输出来防止梯度消失的问题。ResNet是一种网络中网络(NIN)体系结构,由堆叠许多剩余模块组成。这些剩余单元用于构建深度ResNet50体系结构。剩余单元由卷积、池化和层组成。ResNet50使用全局平均池而不是完全连接的层。我们采用并定制了ResNet50[29]深度CNN架构,去掉了全连接层和输出层,增加了两个全连接层;一个退出层,和两个类的输出层。我们在卷积层之后使用了与4L-CNN相同的密集层网络。
2) VGG16
视觉几何组(VGG)网络架构最初是由Simonyan和Zisserman[30]在2014年为ImageNet挑战赛提出的。所采用的基于VGG16的分类模型由16个卷积层、一个平均池化层、两个密集层、一个辍学层和输出层组成。
VGG16体系结构由五个卷积层块和一些完全连接的层组成。为了保持层间特征映射的相同空间维度,在卷积层中使用3 × 3核,步幅为1,填充为1。通过在卷积层之后使用校正线性单元(ReLU)激活函数,并在每个块结束后执行最大池化操作,减少了特征映射的空间维数。使用一个最大池化层,其内核为2 × 2,步幅为2,使激活映射的空间维度为前一层的一半。
D. PROPOSED METHODOLOGY方法
基于所采用的CNN模型,我们提出了三种脑电发作分类方法。在第一种方法,方法1(4L-CNN)中,我们从头开始训练一个基于CNN的模型。在方法2(仅转移学习或TL)中,我们冻结预先训练好的深层CNN从训练中分离出来,并利用预先训练好的网络的输出特征只训练顶层密集层。方法3(Fine-Tuning或FT)包括两个步骤:首先利用预先训练的网络的输出特征进行顶部致密层的微调,然后通过初始化ImageNet上的预先训练的权值来微调深层(深层CNN模型)。
1)方法1(4L-CNN):从头开始训练浅层模型
方法-1包括从头开始训练一个基于CNN的浅层模型用于癫痫发作分类,如图1所示。简单的四层卷积CNN(4L-CNN)由4个卷积层、两个完全连通的层、一个丢弃层和一个用于癫痫发作或非癫痫发作分类的输出层组成。在经过四个连续的卷积层之后,使用四个全连通的层来构建密集层网络。第一全连接层由256个REU激活的节点组成,并接收网络的卷积部分的平坦输出。第二个完全连接的层也被重新激活,并且包含从前一层的输出接收256维矢量的512个神经元。第三个完全连接的层由512个节点组成,是具有50%丢弃的丢弃层。通过使用Dropout来避免过拟合,Dropout在训练中随机忽略一些神经元。最后,dropout层的输出被馈送到Softmax激活的输出,该输出为每个类别分配概率。
2)方法2(TL):仅训练所采用的网络的顶层致密层
在方法2 (TL)中,采用迁移学习技术来加载模型的权重。将脑电信号的时频图像作为输入输入预先训练的修正深度CNN模型,得到输出特征。
这些输出特征来自FC层之前的深层CNN模型的最后一层,然后只用于训练完全连接的层。全连接层的架构与方法1 (4L-CNN)中描述的顶级FC层相同。在该方法中,如图1所示,加载VGG16和ResNets。
3) method-3(微调或ft):分两步对所采用的网络进行微调
在方法3(微调或FT)中,加载深度CNN模型(VGG16或ResNet50)的卷积层(如图1所示)与顶级FC层一起进行微调。由于ImageNet中的图像与EEG的时频表示图像之间存在差异,我们对所有层进行了微调,目的是提高准确性。微调是迁移学习的一种高级实践。该方法的实现需要几个步骤。首先,使用深度CNN模型构建网络的顶层,并将预先训练好的模型权重加载到ImageNet上。其次,将卷积层和其他层冻结到第一个FC层,并使用从深层CNN提取的特征只训练最后几个FC层;就像方法2中的模型训练一样。最后,我们冻结FC层,只训练深度CNN模型。
在本文中,我们将方法1中基于cnn的浅模型称为4L-CNN,方法2中基于vgg16的模型称为TL-VGG16,方法2中基于resnet50的分类器称为TL-ResNet50,方法3中基于vgg16的模型称为FT-VGG16,方法3中基于resnet50的模型称为FT-ResNet50。
E. FEATURE IMPORTANCE CALCULATION USING SHAP
利用形状计算特征重要性
在准确性、敏感性和特异性方面的评价指标,并不总是给我们一个如何做出分类决策的完整画面。当测试一个分类模型时,我们有时感兴趣的是解释为什么会产生输出;也就是说,哪些输入特征主要负责这个决策。此外,了解更多的分类可以帮助我们了解更多的数据。尽管解释深度学习模型的输出通常具有挑战性,SHapley Additive explained (SHAP)[25]工具可以帮助我们根据特征的重要性解释输出。SHAP提供了一种方法来估计每个特征对模型输出的贡献。综合梯度法计算特征值i的重要度分数为:
![]()
其中,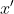 是某个任意基线输入,x是当前输入,f是模型函数。
是某个任意基线输入,x是当前输入,f是模型函数。
从公式10我们可以看到,它累积了在当前图像和基线图像之间内插的图像上的梯度。然而,使用梯度计算特征重要性会受到阈值处理的影响。使用一种新的特征属性方法,称为期望梯度[31]来计算Shap值。梯度形状也称为预期梯度[32],它解释了任意选择参考输入(基线输入)的模型预测与当前预测之间的差异。期望梯度法避免使用任意的参考输入。使用基础训练数据分布来计算参考输入。
III. EXPERIMENTAL SETUPS AND RESULTS 实验装置和结果
本节重点介绍实验的设置和结果的展示。首先,我们描述了实验的设置,即系统配置和实现细节。
A.实验装置
本文使用Windows游戏计算机,配备Intel(R) Core (TM) i7-7700HQ (2.80 GHz, 2808 Mhz, 4核和8逻辑处理器)CPU, 16gb RAM, NVIDIA GeForce GTX 1060 6GB图形处理器(GPU), CUDA 9.0在Windows 10 64位系统上运行GPU加速。实验采用Matlab (R2018a)和Python编程语言进行。
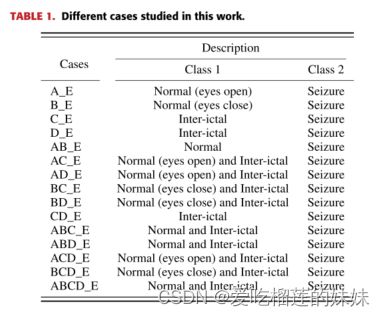
利用Matlab软件进行脑电信号分割和时频表示。使用Keras[33]库进行模型训练和测试以及模型决策解释。为了克服过拟合,我们采用了两种策略。第一个是数据增强,第二个是dropout。减少过拟合的最简单和最流行的方法如表1所示。本工作研究了不同的案例。
对图像数据是使用标签保留变换人工扩大数据集[34]。数据增强是将原始图像进行变换后生成的图像,计算非常简单,而且增强后的图像不需要存储在磁盘上。在本研究中,我们通过翻译增强图像以减少测试误差。解决过拟合问题的另一个策略是退出技术[35]。Dropout设置每个隐藏神经元产生零输出的概率为0.5。通过这种方式,被“丢弃”的神经元在训练过程中不参与向前和向后传递。我们在输出层之前的层中使用dropout。我们使用均方根传播优化器(RMSprop)[36],批次大小为10个样本,学习率为0.00001。我们将图像缩放到224 × 224的尺寸,每个输入有3个(RGB)通道。
本研究使用了五组EEG数据集(A、B、C、D、E)。在所有提出的方法中,第一步是使用信像转换技术(STFT和CWT)从EEG信号中获得时频(t-f)表示的图像。图2是一段脑电图信号的STFT谱图和CWT尺度图。一旦t-f图像的生产完成,它们就被分成训练集、验证集和测试集。每个数据集有1600个t-f图像。训练数据集包含总图像的80%,测试数据集包含总图像的10%,验证数据集包含总图像的10%。在所有建议的训练、验证和测试分类器的方法中都使用相同的训练、验证和测试集。所研究的实验案例如表1所示,涉及二元分类。共测试了15例二元病例,以便将癫痫从正常脑电图中分类。我们比较了从提出的方法获得的准确性、敏感性和特异性的结果。
B. RESULTS
首先,本文提出的方法对脑电图癫痫进行了准确的分类。从A、B、C、D、E 5个脑电信号数据集中,共测试了15例二元分类病例。将时域脑电图信号转换为时频图像,以准确地从正常脑电图中识别癫痫发作。两种不同类型的信号到图像转换技术,STFT和CWT已经被应用,它们显示了分类器性能的差异。由于CWT谱图比STFT谱图表现出更好的性能,因此在癫痫分类问题中,CWT谱图被选为更好的EEG信号时频表示。在3种方法的5个分类器中,方法3中的FT-VGG16结合CWT尺度图分类结果较好,15例病例的平均准确率为99.21%,灵敏度为99.04%,特异性为99.38%。并与现有的FT-VGG16方法进行了比较。在大多数情况下,与现有文献中的传统方法相比,所提出的FT-VGG16具有最高的准确性。此外,利用FT-VGG16分类器确定了对癫痫发作脑电图预测准确性贡献最大的频带。发作性脑电图频率越高,分类器越能从正常脑电图和间歇脑电图中正确预测发作性脑电图。据我们所知,这是同类研究中首次使用基于CWT的脑电图时频表示和非常深入的CNN模型进行癫痫检测,以及识别特征频率,从而实现精确的自动脑电图癫痫预测。