目标检测 CV-Object Detection 简述(ZJU报告)
目标检测的任务是对图像中的物体进行定位、并进一步完成识别和分类;目标检测对无人驾驶、视频监控、图文交互等任务提供了必要的信息。接下来,本文将对利用CNN进行目标检测的算法进行总数,对相关算法的发展脉络、优缺点进行分析。具体地,本文对目标检测的介绍分为三个部分,第一部分介绍基于候选区域的二阶段检测方法,主要有R-CNN系列算法;第二部分重点讨论单次检测器,包括SSD、YOLO系列、RetinaNet等模型;第三部分包含具体模型设计选择的相关内容。
1. 二阶段目标检测
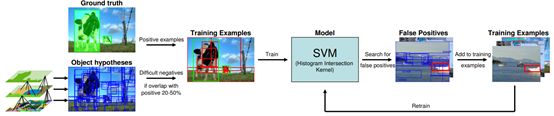
Selective Search[1]是传统目标检测算法的代表。其思路为二阶段检测算法的代表。在第一个阶段,将每个独立的像素作看作一组,然后,自底向上地将纹理两个最接近的组合并,直到所有区域都结合在一起。并基于最终得到的候选区域ROI对框内目标进行分类(使用SVM训练分类器),模型过程如图1所示。
1.1. 滑动窗口检测器
自从AlexNet[2]赢得2012 ILSVRC challenge的第一名,利用CNN进行图像分类成为行业主流。基于CNN强大的分类能力,人们提出使用CNN进行目标检测。一种暴力搜索的方法是使用滑动窗口,即从左到右,从上到下地在图片上滑动不同比例、不同尺度的窗口(见图2),并对窗口内部的图像区域进行分类。

具体地,在分类步骤,对于每一个候选窗口,人们使用CNN分类器提取4096-维的特征,并利用得到的特征进行框位置精确回归、以及训练一个SVM进行目标类别识别。
1.2. R-CNN
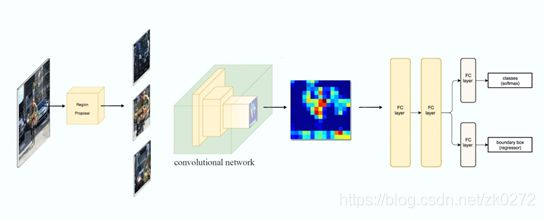
基于滑动窗口的候选框选取方法过于暴力,计算开销过大。因此,R-CNN[3]加入了一个Region Proposal的步骤,使用Selective Search先提取大约2000个感兴趣区域(ROI),这些区域被缩放为固定大小的图像,然后再使用CNN进行分类和框位置回归,R-CNN的流程如图3所示。
1.3. Fast R-CNN
R-CNN需要尽可能多的提出ROI来保证检测的准确度,且ROI之间的重叠现象十分常见。因此,R-CNN在训练和测试阶段的速度都较慢;值得注意的是,我们在同一图片中利用Region Proposal提出了2000个候选框,这些候选框对应的图像全部都要独立地通过CNN来提取特征,该过程中有大量的冗余计算。
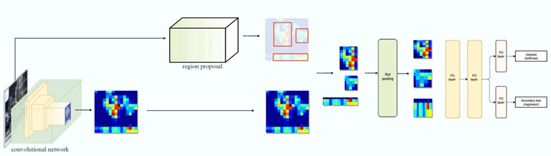
为了解决特征的复用问题,Fast R-CNN[4]提出使用一个CNN对整张图像进行特征提取,而后利用CNN保持空间特征位置的性质,在特征图上使用选择性搜索,生成ROI并利用对应的特征块进行后续的框回归以及分类任务。为了保持后续任务输入特征块分辨率的一致性,模型在选取ROI时使用了ROI池化操作来使特征块变为同一分辨率。得益于规避了重复的特征提取,Fast R-CNN明显地缩短了运行时间。模型流程如图4所示。
与图3对比可知,Fast R-CNN将特征提取过程抽出循环外。实验结果表明,Fast R-CNN在训练阶段比R-CNN快10倍,在测试阶段快150倍。
此外,Fast R-CNN将原本的SVM分类器更改为端到端的CNN分类器,从而可以端到端地进行多任务(框回归、分类)训练,这样的结构改变进一步提升了模型的准确性。
1.4. Faster R-CNN
Fast R-CNN整个框架中,仍有一个不可被端到端训练的模块——即候选框提取步骤,因此其模型准确度很大程度上取决于选择性搜索算法的性能;另一方面,传统的候选框提取算法不可并行在GPU上运行,因此速度较慢,成为整个模型的瓶颈。以Fast R-CNN为例,模型总运行时间为2.3秒,其中2秒花费在选取2000个候选区域步骤。

基于这一观察,Ren等人在Faster R-CNN[5]中提出了Region Proposal Network(RPN),即引入一个CNN网络完成选择候选框的任务。如图5所示,Faster R-CNN的模型结构与Fast R-CNN基本相同,区别是使用RPN替代了原有的候选框提取算法。
RPN的具体训练过程如下:在提取好的特征层上滑动一个的小卷积窗,通过一个轻量级的网络,分别预测出2k个类别得分(表示是否为物体)、4k个候选框位置坐标;对于特征层的一个特定位置,在其原图上选取不同尺度、不同比例的k个Anchor box(锚点框),然后与Ground Truth标注好的物体框进行比对,计算损失。RPN的示意图见图6.
由于引入了RPN,Faster R-CNN得以实现完整的端到端训练,同时,RPN可以在GPU上并行计算以加速整个模型。R-CNN系列模型的速度对比见图6.

至此,我们介绍完了目标检测领域的主流二阶段模型。后续二阶段检测工作如R-FCN[6]、Mask R-CNN[7]、FPN[8]等均在已有网络框架上进行修改,或使用全卷积、或加入多任务学习、或加入多尺度特征图以提升网络的泛化性能。
2. 单次目标检测器
接下来,我们将介绍单次目标检测器,包括SSD[9],YOLO(V1[10],V2[11],V3[12])。我们还将讨论多尺度特征图、不同损失函数设计对检测器准确率的影响。
二阶段检测算法大多包含ROI生成阶段、分类与框回归阶段,这样coarse-to-fine的流程有利于提升模型的准确性,但消耗了大量的计算资源,即便Faster R-CNN已经比原始R-CNN速度提升了数十倍,但在Pascal VOC[14]测试集上仍只能以7 FPS的速度运行。为了追求更快的速度,研究人员开始重新审视整个检测模型的流程。
2.1. YOLO(V1)
注意到RPN的实际运行时间很快,但其只输出大致的框位置以及二分类结果(该框内是否包含任一目标)。因此,一种思路是扩展RPN的分类器,使其不再只输出二分类的结果,而是包含对所有类别的预测,整个过程中为了避免选取ROI带来的速度损失,仍保留类似锚点的设置。这就是YOLO v1[10]的模型思路,其模型见图7.
YOLO的模型非常简洁,实际运行速度也比二阶段算法的速度快很多。但其精确度相较二阶段算法有明显的差距。YOLO难以检测出太远或太近的物体,如图7所示,YOLO未能检测出图像左下角近处的圣诞老人。

2.2. SSD
注意到YOLO对于多尺度物体检测效果较差,SSD[9]提出使用多个尺度的CNN特征层进行分类以及框回归,以期模型对不同尺度的目标有更高的敏感度。
具体地,SSD使用VGG-16[15]作为特征抽取器,在特征下采样的过程中,SSD直接使用VGG不同层(对应不同分辨率)的特征图进行框回归及分类。这样主要解决了卷积下采样过程中深层特征低分辨率、无法识别出较小物体的问题。SSD对多尺度特征层的利用如图8所示。

2.3. YOLO(V2, V3)
初版YOLO的模型设计较为简单,其特点我们已在2.1节介绍,该版本的主要贡献是为轻量级单次检测器的模型设计提供了基础思路。但受限于特征图分辨率单一、网络backbone性能较差等问题,其模型至今已缺少实用价值。
YOLO v2[12]加入了如Batch Normalization、维度先验、定位预测、多尺度等操作,使得模型在VOC测试集的准确率(mAP)由63.4提升至最高78.6。
YOLO v3[13]在之前工作的基础上换用了更新的CNN网络结构,使用Darknet-53作为网络backbone,加入了Depth-wise Separate卷积、类似ResNet的Skip Connection等模块,使CNN在保持轻量级的同时,提升了准确率。同时,v3版本中加入了下文中将介绍的特征金字塔网络FPN,极大提升了模型对小物体的识别率。图9展示了YOLO v2与其他多个检测模型在COCO检测数据集上的性能对比。

3. 模型设计与选择
3.1. FPN与多尺度特征
检测不同尺度的物体,尤其是小物体,是单次、二阶段目标检测算法共同的难点。为此,FPN[8]设计了更好的多尺度特征提取模型。FPN主要改进了特征提取器(Feature Extractor),在原有CNN基础上设计了金字塔结构的特征图,如图10所示,FPN包含bottom-up以及top-down两条特征通路。Bottom-up通路由普通CNN构成,用于特征提取,随着层数加深,特征图的分辨率降低,其包含的语义信息增多;为了增加底层高分辨率特征图的语义信息,FPN设计了Top-down通路,进行高分辨率特征图的重建,并加入Skip Connection,保留了一定局部的空间信息。
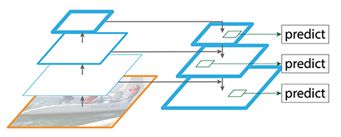
FPN作为一种特征提取器,被广泛应用于各种单次、二阶段检测器、甚至其他视觉任务中,对提升准确度起到重要作用。
3.2. RetinaNet与Focal Loss
在各种视觉任务中,不同类别样本的数据不平衡对于模型准确性的影响很大。为此,RetinaNet[13]提出采用Focal loss,即在训练时对于识别准确率较高的类别,动态地减少其类别的损失权重。从而达到相对均衡的训练过程。
3.3. 特征提取器
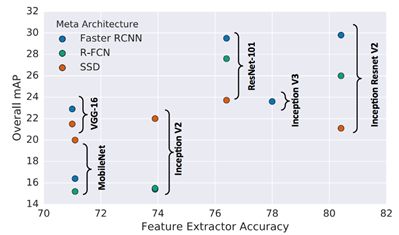
不同的特征提取器对于最终目标检测的准确率影响会非常大。图11展示了不同CNN Backbone对于检测器精度的影响。在具体任务中,需要根据实际需求对速度和准确率进行平衡,选取对应的特征提取器。
4. 总结与趋势
我们介绍了多种不同的目标检测模型,包括更精确的二阶段检测算法、速度更快的单次目标检测器,它们之间的联系,以及一些模型设计的技巧,这些算法均有着广泛的实际应用场景。近来,人们开始着重研究Anchor-Free的单次目标检测器,试图在不提取ROI的情况下得到更高的检测准确率,未来,研究将继续 朝着将二者统一的方向发展,以求达到准确率与速度的平衡。
参考文献
[1] Van de Sande, Koen EA, et al. “Segmentation as selective search for object recognition.” ICCV. Vol. 1. No. 2. 2011.
[2] Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. “Imagenet classification with deep convolutional neural networks.” Advances in neural information processing systems. 2012.
[3] Girshick, Ross, et al. “Rich feature hierarchies for accurate object detection and semantic segmentation.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2014.
[4] Girshick, Ross. “Fast r-cnn.” Proceedings of the IEEE international conference on computer vision. 2015.
[5] Ren, Shaoqing, et al. “Faster r-cnn: Towards real-time object detection with region proposal networks.” Advances in neural information processing systems. 2015.
[6] Dai, Jifeng, et al. “R-fcn: Object detection via region-based fully convolutional networks.” Advances in neural information processing systems. 2016.
[7] He, Kaiming, et al. “Mask r-cnn.” Proceedings of the IEEE international conference on computer vision. 2017.
[8] Lin, Tsung-Yi, et al. “Feature pyramid networks for object detection.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017.
[9] Liu, Wei, et al. “Ssd: Single shot multibox detector.” European conference on computer vision. Springer, Cham, 2016.
[10] Redmon, Joseph, et al. “You only look once: Unified, real-time object detection.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
[11] Redmon, Joseph, and Ali Farhadi. “YOLO9000: better, faster, stronger.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2017.
[12] Redmon, Joseph, and Ali Farhadi. “Yolov3: An incremental improvement.” arXiv preprint arXiv:1804.02767 (2018).
[13] Lin, Tsung-Yi, et al. “Focal loss for dense object detection.” Proceedings of the IEEE international conference on computer vision. 2017.
[14] Everingham, Mark, et al. “The pascal visual object classes (voc) challenge.” International journal of computer vision 88.2 (2010): 303-338.
he IEEE international conference on computer vision. 2017.
[14] Everingham, Mark, et al. “The pascal visual object classes (voc) challenge.” International journal of computer vision 88.2 (2010): 303-338.
[15] Simonyan, Karen, and Andrew Zisserman. “Very deep convolutional networks for large-scale image recognition.” arXiv preprint arXiv:1409.1556 (2014).