CVPR-2020笔记 | 文末送书

目录
(.)中的数字表示数量。
教程(4)
获奖论文摘要(3)
可控图像合成(2)
不平衡样本处理(2)
多任务学习(1)
表示学习(2)
自我监督学习(2)
半监督学习(2)
弱监督学习(用于语义分割)(3)
目标检测(2)
知识提炼(三)
数据扩充(4)
优化(3)
评价与概括(3)
不确定度估计(3)
[Tutorial | Sun.] How to write a good paper? — Bill Freeman (MIT, Google)
视频:(https://www.youtube.com/watch?v=W1zPtTt43LI&t=467s)
题目:如何写一篇好论文
为什么它很重要?一篇有创意的,原创的,非常强的论文会比那些还可以的、糟糕的论文更影响你的职业生涯:让你的努力变得有价值。
陈述你的问题,让读者知道你解决的问题是什么;其他的解决方案是什么,为什么其它方案不行;解释你自己的解决方案以及为什么它更好;用简单的例子传达主要思想;在实验中进行合理的比较;最后总结一下你的成果会带来什么应用或贡献,或者它如何改变我们处理问题的方式;还有以“未来的工作”结束是个坏主意(即,我们想做,但未能在截止日期前及时做完)。
使你的论文易于阅读(在匆忙中仍能学到要点);写出简洁的句子(即,不要冗长!);数字和标题应该是独立的。
积极的语调-要和蔼可亲:不要过度推销,隐藏缺点和贬低他人的工作;诚实地指出局限性。
一个好标题很重要。
会议期刊拒绝论文的理由:没有兑现论文的承诺;遗漏重要参考文献;太多或令人难以置信的结果;写得不好;陈述不正确;写得很好但却枯燥乏味的论文;虽然新颖精彩容易指出缺点的论文。
好的写作就是重新写作。所以要早点开始写论文。
[Tutorial | Sun.] All You Need to Know About Self-Driving by Uber ATG
链接:(http://www.allaboutselfdriving.com/)
题目:由Uber ATG提供你想了解的关于自动驾驶的信息
本教程涵盖了自动驾驶管道中的主要技术组件,包括不同传感器模式的数据预处理、三维物体检测的感知、长期预测、行驶轨迹规划、转向和加速等控制以及车辆与车辆之间的通信。这里我只记录了传感器的形态和感知。
传感器模态和感知(3D物体检测)

激光雷达(3D):
-
点云表示,如3D体素(3D卷积有效的特征提取;昂贵的计算和内存消耗;CVPR'18的VoxelNet):https://arxiv.org/abs/1711.06396
距离视图(保留全范围信息;由于3D信息丢失而导致邻域不真实;CVPR'19的LaserNet):https://arxiv.org/abs/1903.08701
鸟瞰图(2D卷积的有效特征提取;内存消耗昂贵;CVPR'19的PointPillars):https://arxiv.org/abs/1812.04244
3D点集(精确定位;昂贵的计算和内存消耗;多尺度特征的次优关键点;CVPR'19的PointRCNN):https://arxiv.org/abs/1812.04244
这些表示大多是稀疏的,可以通过使用稀疏卷积网络或稀疏块网络(CVPR'18)来加速。:https://arxiv.org/abs/1801.02108
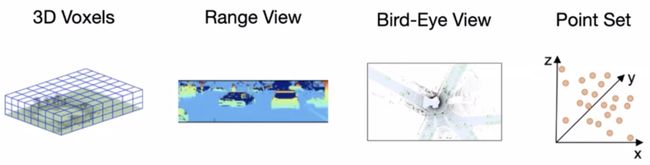
摄像机(2D):比激光雷达便宜。将2D输入/特征/输出转换为3D,然后使用现有的探测器。
-
转换为3D输出:2D关键点预测+3D盒子模板匹配=3D盒子输出(性能不理想);
转换3D输入:2D图像+深度估计=“伪激光雷达”(SoTA基于图像的3D感知;由于需要深度模型而产生的额外计算成本;ICLR'20的伪激光雷达++和CVPR'20的E2E伪激光雷达):https://arxiv.org/abs/1906.06310与https://arxiv.org/abs/2004.03080
转换到3D特征:根据相机内部特性将2D特征映射到3D(鸟眼)特征(无需深度估计;深度模糊导致的3D特征误差;BMVC'19的正交特征转换):https://arxiv.org/abs/1811.08188
传感器融合-激光雷达+摄像机:融合可以在输入/特征/输出中以级联或并行的方式发生。
传感器融合-雷达(几何结构)+摄像机(性能无法与基于激光雷达的系统相匹配);雷达(作为速度)+激光雷达。请参阅arXiv'20的“Exploiting Radar for Robust Perception of Dynamic Objects”。
高清地图:语义信息。主要用于运动规划系统。几何方面,请参见CoRL'18的HDNet(http://proceedings.mlr.press/v87/yang18b/yang18b.pdf?utm_source);作为rasters,请参阅WACV'20的Uncertainty-aware Short-term Motion Prediction of Traffic Actors for Autonomous Driving(https://arxiv.org/abs/1808.05819);作为车道图(更直观但更复杂的模型设计),请参见CVPR'20的VectorNet(https://arxiv.org/abs/2005.04259)。
[Workshop | Mon.] Scalability in Autonomous Driving
题目:自动驾驶的可扩展性
链接:https://sites.google.com/view/cvpr20-scalability

第一名的解决方案报告令人印象深刻,他们花了2个月才获得第一名。他们的系统中的许多组件似乎都得到了集中的优化,而且还应用了一些新的技巧。
[Keynote]Raquel Urtasun,Uber ATG的 Scalable Simulation for Self Driving
仿真可用于训练和安全评估。完整的模拟包括状态(参与者行为)、几何体(参与者和环境三维模型)和观察(自动驾驶汽车感知的激光雷达和摄像机表示)。
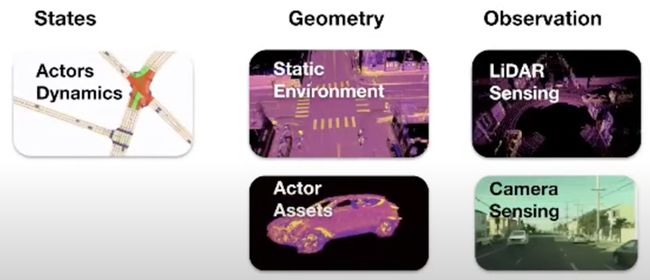
状态:ActorSim(http://makro.ink/actorsim/) (现实性和多样性)。
几何状态+激光雷达传感模拟:CARLA(https://carla.org/)(设计3D参与者资产耗时;环境多样性有限;不切实际;CoRL'17);Blensor(https://www.blensor.org/)(与CARLA的缺点相同;增强模拟激光雷达的真实感,但不是实时的,需要材料特性;ISVC'11);数据驱动方法(收集真实世界传感器数据和将渲染应用于模拟器的数据):越野激光雷达(ICLR'18,https://www.youtube.com/watch?v=t5a6nxE9N1k)和AADS(昂贵且规模有限,https://arxiv.org/abs/1811.07112);LiDARsim(解决上述缺点;Raquel等人的CVPR'2020,http://openaccess.thecvf.com/content_CVPR_2020/html/Manivasagam_LiDARsim_Realistic_LiDAR_Simulation_by_Leveraging_the_Real_World_CVPR_2020_paper.html)。
几何体状态+相机感测模拟:按模拟引擎分类,神经渲染(自动化但没有照片级真实感;仅单传感器视图;无几何体感知)和照片级真实感相机模拟(解决上述缺点;Rong等人的GeoSim,虽然尚未发布,但GeoSim的结果看起来很好)。
[Keynote] Andrej Karpathy, Tesla


在生产中部署“HydraNet”:8个摄像头连接着48个网络;1000个不同的预测;70000个GPU。
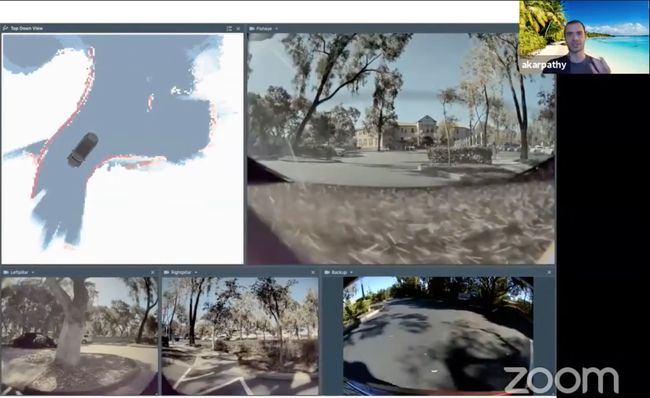


用端到端鸟瞰预测代替传统的图像拼接。
特斯拉的可扩展性挑战:在50多个标签上反复“大海捞针”(特殊情况);模型的不确定性仍然非常具有挑战性;驾驶时没有高清地图(不需要超时维护)。
Q:为什么不使用高清地图?它们不是为安全功能提供了强有力的先例吗?为什么要从头开始重建?
A:我们仍然使用高清地图,但长期来看是不可扩展的,如果高清地图没有及时更新,模型可能会做一些蠢事。
[Tutorial | Mon.]IBM Research的 Zeroth Order Optimization
题目:IBM Research的0阶优化
链接:https://sites.google.com/umich.edu/cvpr-2020-zoo

基于arXiv'20的“A Primer on Zeroth-Order Optimization in Signal Processing and Machine Learning”:https://arxiv.org/abs/2006.06224
和它的名字一样,零阶意味着不能从模型中获取梯度信息,一阶(Jacobian)和二阶(Hessian)。
想法:ZOO使用“有限差分法”(或2点法来估计梯度),并使用现成的基于梯度的优化器来更新模型。
与贝叶斯优化(BayesOpt)相似的部分:都是处理黑箱优化问题的算法,而非可微的)。
与GPs的贝叶斯优化不同的是:GPs仍然需要一阶信息来更新其核心参数,而ZOO则不需要。
与强化学习相似(RL中使用的策略梯度):都使用估计的梯度来更新模型。
不同于强化学习的部分:强化学习仍然可以访问模型的一阶信息(即强化学习仍然需要模型的Jacobian更新其参数)。
使用ZOO的流行领域:对抗ML,如黑盒对抗攻击(“ZOO: Zeroth Order Optimization Based Black-box Attacks to Deep Neural Networks without Training Substitute"显示基于ZOO的黑盒攻击可以与MNIST、CIFAR-10和ImageNet上的白盒攻击一样有效)和模型预测解释(类似于攻击)。也可以作为超参数优化、RL策略搜索等算法的替代方案:https://arxiv.org/pdf/1708.03999.pdf
[Tutorial | Mon.] From NAS to HPO: Automated Deep Learning
[Tutorial | Mon.]从NAS到HPO:自动化深度学习
链接:https://hangzhang.org/CVPR2020/
介绍AutoGluon工具箱-张杭:https://youtu.be/XdaFprz3ECE

自动联合超参数和网络架构搜索(用户仍然需要定义搜索空间)。兼容其他DL库,如Pytorch!
工作流程:
-
(1)使用AutoGluon为网络、优化器等分配自定义搜索空间;
(2)将网络和优化器传递给训练函数。
(3) 把训练功能传递给调度器,就可以开始了。
内置的超参数优化(HPO)(BayesOpt with GP)/NAS(ENAS,ProxylessNAS)/早期停止算法。HPO/早期停止算法在Cedric Archambeau的教程“Automated Hyperparameter and Architecture Tuning”中有介绍:https://www.youtube.com/watch?v=pB1LmZWK_N8&feature=youtu.be
AutoML for TinyML with One for All Network(ICLR'20)
链接:https://www.youtube.com/watch?v=fptQ_eJ3Uc0&feature=youtu.be
设备感知的NAS挑战:工程的设计(为不同的硬件平台定制模型以达到最佳的准确性和效率的权衡可能相当昂贵)和昂贵的训练资源。
主要思想:将传统NAS的训练(内环)和搜索(外环)分离,搜索后无需再训练直接部署。


解决方案-“渐进收缩”(训练阶段):为了防止不同子网之间的“干扰”,它通过从全网到小子网逐步训练,跨越分辨率、核尺寸、深度和宽度四个维度。


渐进收缩是如何工作的?见下图和说明。
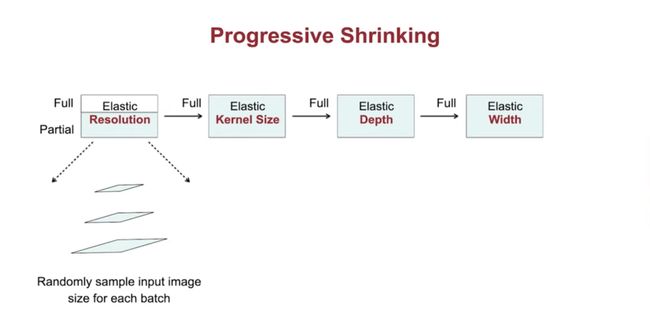
第一个图对不同分辨率的图像进行批量采样;第二个图先训练较大的核,然后再训练较小的核。5x5核函数由7x7核函数的5x5权值中心再通过25x25变换矩阵进行投影,然后通过9x9变换矩阵,从5x5内核的3x3权重中心投影到3x3的核。
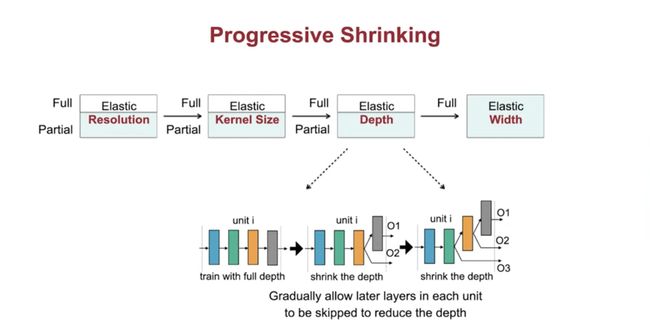
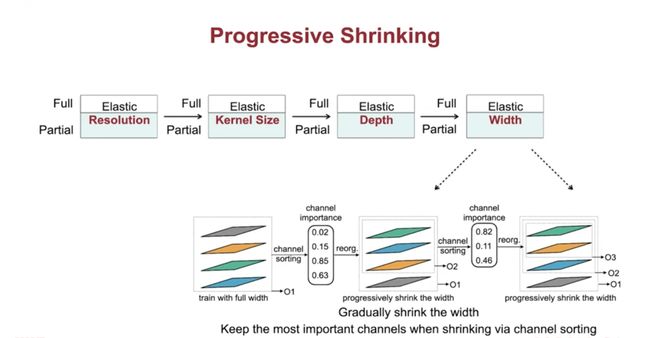
(第一个图)每块体系的深度由4逐渐缩小到2;(第二个图)逐渐缩小宽度
解——搜索阶段:训练阶段结束后,从训练后的全网络中迭代抽取子网络,对测试集进行推理,得到其准确度。他们使用的搜索算法是进化策略。

结果:比EfficientNet快2.6倍;比MobileNetV3快1.5倍;新的SoTA在移动设置下的ImageNet精确度高达80%(<600 MACs)。50+OFA预训练模型和训练代码发布(https://github.com/mit-han-lab/once-for-all)!也有使用Jupyter Notebook的实践教程(https://github.com/zhanghang1989/AutoGluon-Tutorial-CVPR2020/blob/master/ofa-tutorial/ofa.ipynb)。
相关论文-新SoTA Backbones
RegNet: Designing Network Design Spaces(https://arxiv.org/abs/2003.13678)。该网络不是查找单个网络实例(如NAS),而是查找网络总体。其有一些发现与目前网络设计实践不符,但比gpu上的EfficientNet快5倍:https://arxiv.org/abs/2003.13678
ResNeSt: Split-Attention Networks(https://arxiv.org/abs/2004.08955)。在ImageNet上,81.1%的Top1准确率,比之前的最佳ResNet变体高出1%以上。通过简单地用ResNeSt-50替换ResNet-50主干,MS-COCO上FasterRCNN的MAP从39.3%提高到42.3%;ADE20K上DeeplabV3的mIOU从42.1%提高到45.1%。
FBNetV3: Joint Architecture-Recipe Search using Neural Acquisition Function(https://arxiv.org/pdf/2006.02049.pdf)。提出了一种联合搜索网络结构及其相应的超参数训练的联合算法。
会议结果


红色方框显示了今年相对较新的主题。
好论文=3D计算机视觉+图形+强劲成果
[最佳论文奖]牛津大学:Unsupervised Learning of Probably Symmetric Deformable 3D Objects from Images in the Wild(https://arxiv.org/abs/1911.11130)。其主要思想是以神经绘制方式学习表示(物理优先)。为了防止在渲染之前退化中间结果(深度,反照率),在生成中间结果时强制使用“对称性”。不需要监督,对测试图像和视频有着惊人的泛化。

[最佳学生论文奖] BSP-Net: Generating Compact Meshes via Binary Space Partitioning(https://www.youtube.com/watch?v=9-ixexpjN-8)。本文通过一个可微BSP树学习了一个表示三维形状的网络,因此与以前的方法相比,它们可以获得更紧凑(低多边形)的三维网格。
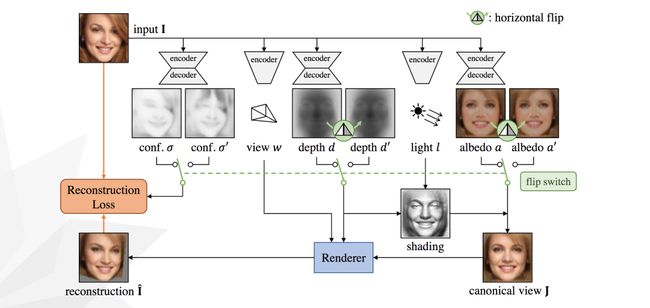
[最佳学生论文荣誉奖] DeepCap: Monocular Human Performance Capture using Weak Supervision(https://www.youtube.com/watch?v=C4eDrvJ9aBs)。重建整个三维人体,只需一个RGB视频输入。他们解决了以前的挑战,包括服装,深度模糊和时间不一致。这些研究结果看起来很有希望在电影业、增强现实和自由视点渲染中实现令人兴奋的应用。该方法依赖于多视图图像、二维监控(如2D姿态+前景遮罩)和参数化三维人体模型模板。
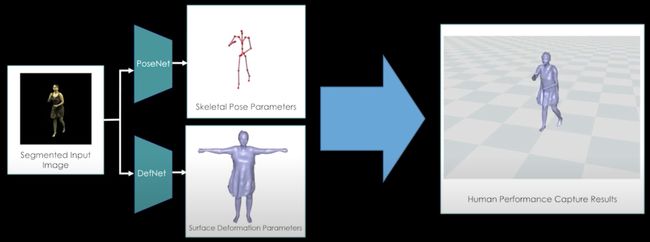
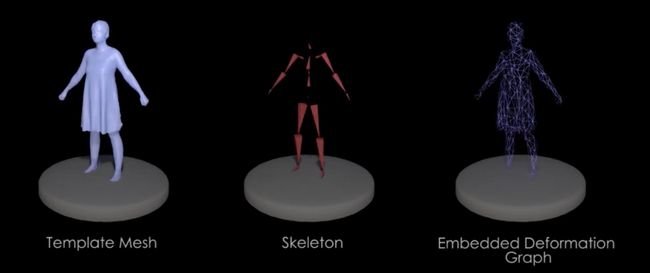
DeepCap。(上)方法概述;(下)三维人体模型的三个组成部分。


DeepCap的三维人体在遮挡部分工作得很好!一旦3D实体被重建,我们就可以将纹理添加到3D实体中作为AR用例。
手工挑选的会议文件
在这里,我将重点放在对各种问题有普遍性、简单性和有效性的想法上,此外还选取了一些具体应用的论文。
可控图像合成
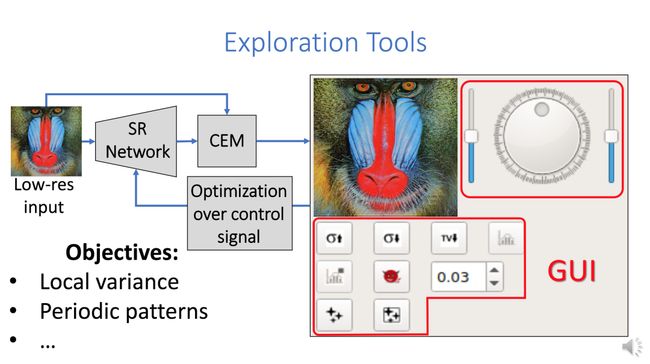
Explorable Super Resolution(https://www.youtube.com/watch?v=RE9VVzSLHV4)允许用户对给定的低分辨率输入探索无限可能的高分辨率解决方案,其核心贡献是一致性增强模块(CEM),它使得在低分辨率输入下采样时,几个可能的高分辨率输出是一致的。CEM不需要任何训练,可以应用于任何SR模型,以提高一致性。


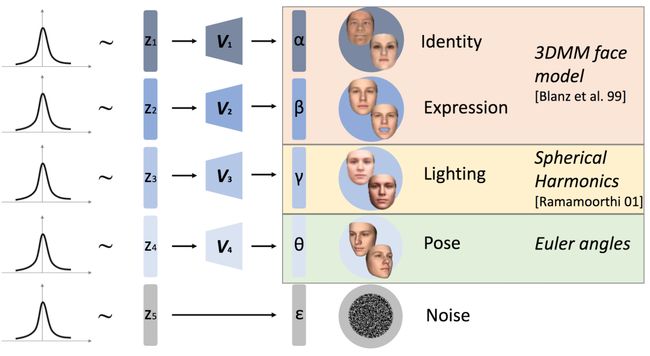
Disentangled and Controllable Face Image Generation via 3D Imitative-Contrastive Learning(https://www.youtube.com/watch?v=l1KCgjJ2Bcc)。对比学习是今年的热门话题,大多数的对比学习方法都是在图像分类任务中进行自监督学习的,然而,该论文提出使用对比学习通过增强去纠缠表示来生成人脸:改变一个潜在变量而保持其他变量不变,并强调生成的人脸图像上的差异只与该潜在变量有关。


处理不平衡数据
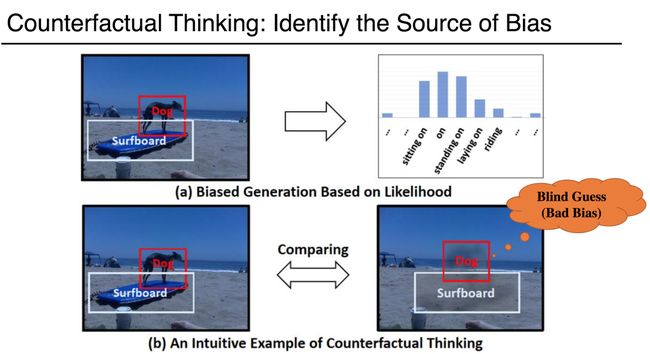
Unbiased Scene Graph Generation From Biased Training (Oral).(https://www.youtube.com/watch?v=hqDB45bRv54)。传统学习受到数据偏差的影响,本文提出了一种基于反事实思维的无偏推理,即使训练仍然存在数据偏差,但无偏预测可以通过减去盲预测和非盲预测之间的概率分布得到。

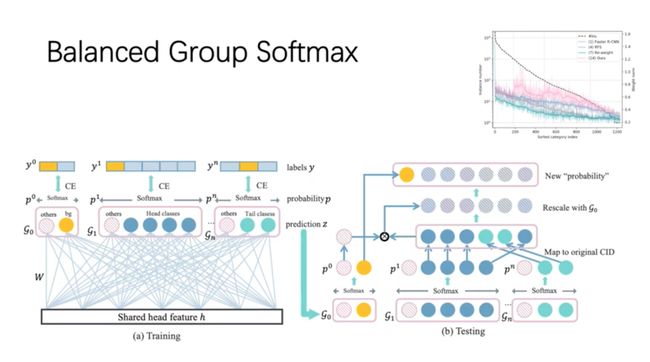
Overcoming Classifier Imbalance for Long-tail Object Detection with Balanced Group Softmax(https://www.youtube.com/watch?v=Lp72nHceTZQ)。在长尾数据集上简单地训练一个对象检测器将导致性能的显著下降。作者观察到,对于每个对象类,特征抽取器中的权重范数与训练实例数呈正相关性(即尾类的权重范数较小)。权重不平衡的影响主要是由标准的softmax引起的,因此,他们建议将训练实例数相近的类进行分组,并开发一个“分组”的softmax,这样尾类的权重范数不受头类的影响。这个想法很直观,很好,但是我们能不能把这种“离散”的群体过程变成更“连续”的过程(比如focal损失)?

多任务学习
LSM: Learning Subspace Minimization for Low-level Vision (Oral)(https://www.youtube.com/watch?v=4zOMGz38vBo)。许多低层次视觉任务可以表述为最小化数据项和正则项,然而正则化术语通常是特定于任务的。为了统一它们,该论文建议将解表示为基向量的线性组合,并求解组合系数(直觉:PCA的“特征面”)。该框架实现了参数完全共享的多任务学习,它们在四个低级任务(交互式图像分割、视频分割、立体匹配和光流)上实现SoTA,具有更小的模型尺寸、更快的训练收敛速度、实时的推理时间以及在不可见的领域更多的泛化。

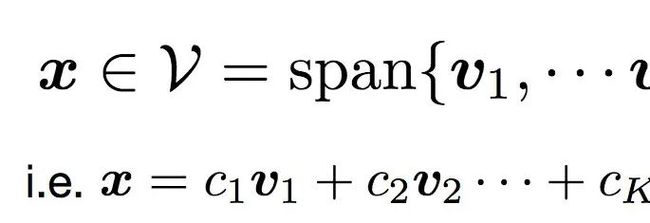

表示学习
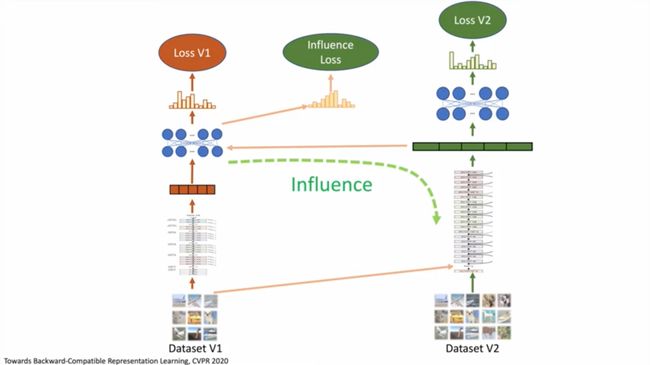
Towards Backward-Compatible Representation Learning (Oral)(https://www.youtube.com/watch?v=hnexF0rrDUE)解决了后向兼容问题,以基于嵌入的图像检索为例,在更改DNNs的新版本时,需要在离线会话期间重新计算图像嵌入量,然而当图像数量达到数十亿时,处理它可能需要一周的时间。我们可以在不重新计算嵌入的情况下切换到DNNs的新版本吗?答案是肯定的。论文建议使用:1)旧版本的分类器和旧版本的数据一起训练新版本的嵌入;2)同时使用新版本的数据训练新版本的分类器,它比从旧版本的嵌入中提取特征要好。
Circle Loss: A Unified Perspective of Pair Similarity Optimization (Oral).(http://openaccess.thecvf.com/content_CVPR_2020/papers/Sun_Circle_Loss_A_Unified_Perspective_of_Pair_Similarity_Optimization_CVPR_2020_paper.pdf)作者简单地给出了三重态损失中正对和负对的两个权值(超参数),从数学上证明了这种简单的修改可以在人脸识别、reID和图像检索等需要学习相似性的任务上获得更好的性能。

自我监督学习
Momentum Contrast for Unsupervised Visual Representation Learning(https://paperswithcode.com/paper/momentum-contrast-for-unsupervised-visual)。目前,自我监督表示学习的领域主要是基于对比的方法(本文就是其中之一,由Facebook提出),然而,还有一些其他的论文,如SimCLR、BYOL和最近的SwAV(在视图之间交换任务;也是由Facebook提出的)都胜过这种方法(但是它们的思想是相似的)。
PULSE: Self-Supervised Photo Upsampling via Latent Space Exploration of Generative Models(https://paperswithcode.com/paper/pulse-self-supervised-photo-upsampling-via)。最近,这篇文章在Twitter上被广泛讨论,低分辨率奥巴马的面部图像会被提升为白人的面部图像(反映数据集偏差或“ML公平性”问题)。可以参阅本文:https://thegradient.pub/pulse-lessons/。
半监督学习
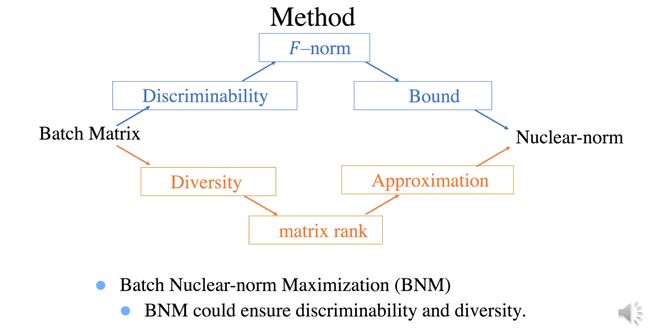
Towards Discriminability and Diversity: Batch Nuclear-norm Maximization under Label Insufficient Situations (https://arxiv.org/abs/2003.12237)。提出了一个对未标记数据进行区分性和多样性预测的正则化项,通过最大化批处理矩阵的Frobenius范数等价于最大化其核范数(近似于矩阵秩)。该方法改进了半监督学习,实现了开放域识别问题的SoTA,简单有效!
Self-training with Noisy Student improves ImageNet classification(https://paperswithcode.com/paper/self-training-with-noisy-student-improves):ImageNet上的新SoTA。
弱监督学习(用于语义分割)
弱监督学习的一个典型任务是语义分割。常用的方法是利用图像分类器产生的类激活映射(CAM)作为语义分割的伪标签,然而,主要的挑战是这些凸轮通常是物体的小鉴别部分。让我们看看下面的文章是如何应对这一挑战的。
Self-supervised Equivariant Attention Mechanism for Weakly Supervised Semantic Segmentation (Oral)(https://arxiv.org/abs/2004.04581)。该方法通过对具有不同变换(如重缩放、图像翻转、旋转和平移)的同一图像的CAM关注点之间的等变一致性,在弱监督语义分割基准(如PASCAL VOC 2012)上取得了较好的性能。

Weakly-Supervised Semantic Segmentation via Sub-Category Exploration (Poster)(https://openaccess.thecvf.com/content_CVPR_2020/papers/Chang_Weakly-Supervised_Semantic_Segmentation_via_Sub-Category_Exploration_CVPR_2020_paper.pdf)。在阅读本文时,我发现之前的SoTA-FickleNet(CVPR'19)也很有趣,他们用一种无需训练的方法来解决上述问题,该方法使用随机推理将对象的多个判别部分结合起来。
基于图像标签的单阶段语义分割。
目标检测
Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection(https://paperswithcode.com/paper/bridging-the-gap-between-anchor-based-and)
Revisiting the Sibling Head in Object Detector(https://paperswithcode.com/paper/revisiting-the-sibling-head-in-object)
知识提炼
Revisiting Knowledge Distillation via Label Smoothing Regularization
What It Thinks Is Important Is Important: Robustness Transfers Through Input Gradients(http://openaccess.thecvf.com/content_CVPR_2020/html/Chan_What_It_Thinks_Is_Important_Is_Important_Robustness_Transfers_Through_CVPR_2020_paper.html)我们经常看到,教师模式可以通过知识提炼转化为学生模式,然而,本文首次表明,在跨任务和跨体系结构的情况下,对抗性鲁棒性也可以被转移!这个想法是使用对抗性损失来匹配教师和学生模型之间的输入梯度。

Distilling Effective Supervision from Severe Label Noise(https://paperswithcode.com/paper/ieg-robust-neural-network-training-to-tackle)
数据增强
Learn to Augment: Joint Data Augmentation and Network Optimization for Text Recognition(https://paperswithcode.com/paper/learn-to-augment-joint-data-augmentation-and).
Rethinking Data Augmentation for Image Super-resolution: A Comprehensive Analysis and a New Strategy(https://paperswithcode.com/paper/rethinking-data-augmentation-for-image-super).
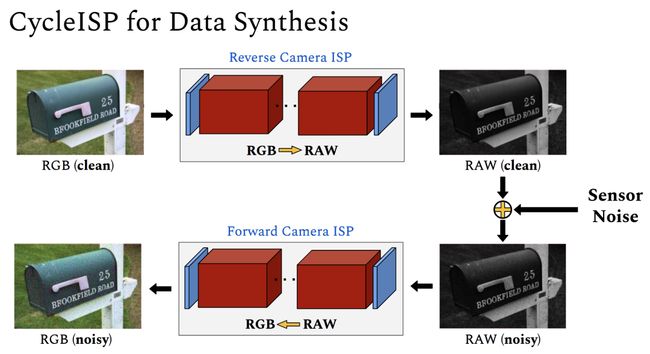
CycleISP: Real Image Restoration via Improved Data Synthesis(https://arxiv.org/abs/2003.07761)。提出了一种更真实的噪声合成方法,即通过模拟摄像机成像管道来训练单个图像去噪模型。该方法可以在原始空间和sRGB空间中生成噪声和干净的图像对。他们在真实的相机基准数据集上实现了SoTA。
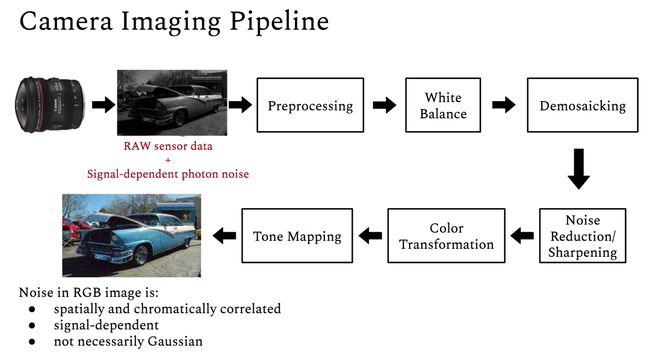
A Physics-Based Noise Formation Model for Extreme Low-Light Raw Denoising(https://www.youtube.com/watch?v=DMDKPRozdeo)。在极低光照条件下合成逼真的噪声图像。该论文提出了一种适用于不同摄像机的噪声参数标定方法,是一个优于使用真实世界配对数据训练的方法。


优化
Hardware-in-the-Loop End-to-End Optimization of Camera Image Processing Pipelines(http://cvpr20.com/event/hardware-in-the-loop-end-to-end-optimization-of-camera-image-processing-pipelines-2/)。利用无梯度优化方法,通过调整ISP黑盒来优化ISP下游任务的性能。
Optimizing Rank-Based Metrics With Blackbox Differentiation(https://www.youtube.com/watch?v=UtOG3utfd5s)。优化基于排名的指标(如平均精确度和召回率)是很困难的,因为它们是分段函数(score)且所有地方都具有零梯度。论文提出了最直观的方法:“平滑”这些损失,并使其可微。

Filter Response Normalization Layer: Eliminating Batch Dependence in the Training of Deep Neural Networks.。该论文提出的将规范化和激活作为一个单一的层,其性能击败了从小批量到大批量设置的所有SoTA规范化技术。
评价与概括
Computing the Testing Error Without a Testing Set(https://www.youtube.com/watch?v=XuDU--076VA)。在ImageNet测试中获得高精度并不意味着识别问题得到了解决。DNNs的泛化能力随标记测试集的不同而不同。前一篇文章可以看到,一般化的dnn具有特定的连接模式。本文提出用拓扑描述符来度量连通模式,他们发现这种测量方法与泛化差距有很好的相关性。


High-Frequency Component Helps Explain the Generalization of Convolutional Neural Networks(https://www.youtube.com/watch?v=8H0QQbMFb-k)
Dataless Model Selection With the Deep Frame Potential.
不确定度估计
On the uncertainty of self-supervised monocular depth estimation。比较了自监督单目深度估计的几种不确定度估计方法,提出了一种将自监督与数据不确定度相结合的新方法。
Scalable Uncertainty for Computer Vision With Functional Variational Inference .
Uncertainty-Aware CNNs for Depth Completion: Uncertainty from Beginning to End.
参考链接:https://medium.com/@howardyclo/cvpr-2020-notes-9b3bbd357b2d
留言送书福利
为了感谢大家长期以来的支持,小编会在每次发送课程文的第二天做一次”送书”活动!
本次小编精心挑选了《深度学习之人脸图像处理》送给3位粉丝。本书从基本的人脸数据集发展历史和人脸检测开始,分别讲述在此基础上进行的人脸图像处理的相关技术与应用,涉及身份识别、安全认证、人机交互和娱乐社交等领域。
在本文文末留言即可参与活动,留言内容需为主题相关,多多留言会提升中奖概率哟~~
/ 留言主题 /
你怎么看待昨天发的《彻底掌握机器学习的6个主流模型,是什么水平?》,对你有帮助么?有什么建议?
本次“留言送书”活动截至到9月2号,抽留言走心的粉丝3名 免费赠送1本书籍(走心留言将经过筛选)。届时会公布中奖者评论截图及福利领取方式~
☆ END ☆
如果看到这里,说明你喜欢这篇文章,请转发、点赞。微信搜索「uncle_pn」,欢迎添加小编微信「 mthler」,每日朋友圈更新一篇高质量博文。
↓扫描二维码添加小编↓
