AllenAI | 用GPT-3帮助增建数据,NLI任务直接提升十个点!?

文 | iven
编 | 小轶
用机器构建数据集,这件事可能比机器学习诞生的还要早,很多人做过很多工作。怎样让机器参与进来?前人的工作可以分成两类思路:一类是以远程监督为代表,让机器来标注,主要目的在于得到更多的数据;另一类是以主动学习为代表,机器在数据集中选出最难的样本,让人标注,主要目的在于得到更高质量的数据。
在大模型大数据的今天,前一类思路成为了主流:机器标注虽然质量不如人,但能以最低的成本标注最多的数据。数据中的噪声就依靠大模型的鲁棒性来消化,庞大的数据量似乎更有用。
近日,华盛顿大学 Yejin Choi 组的研究又对这个问题进行了反思。怎样才能在机器参与构建数据集的流程里,最好地发挥机器的效用呢?机器与人应该是互补的,而不是让机器代替人来标注。
人类在标注大规模数据的时候,很容易有这样一个局限:一个人设计数据时,经常只依赖几种重复的模板。这样尽管标注了大量的数据,但数据集会缺乏语言学上的多样性。相比于一个标注团队,GPT3 生成的语料则会丰富得多。而相比于机器,人的优势在于更高的标注准确率。
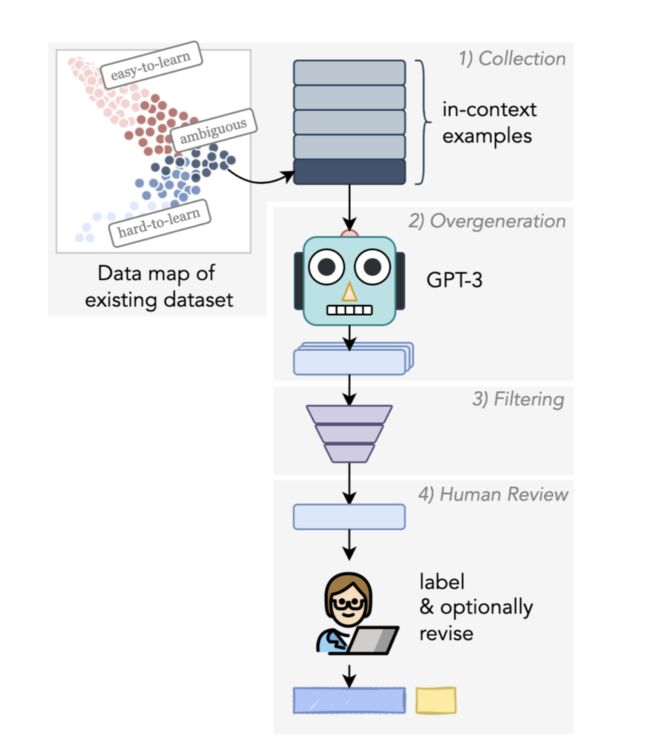
基于此,这篇文章提出了一个全新的构建数据集流程:基于一个现有的数据集,挑选出里面对机器困难的样本,让 GPT3 生成更多更丰富的同类困难样本,让人来检查和优化。
作者采用这套人机合作的数据构建方式,以较低的人力成本构建了超大规模的自然语言推断(NLI)新数据集 WANLI。实验表明,在 WANLI 数据集上训练的模型会有更好的性能。最突出的是,训练后模型所具备极强的跨领域迁移能力:迁移到十分内卷的 NLI 数据集 HANS 和 ANLI 上做测试,也都分别提升了 11% 和 9% 的准确率。
论文题目:
WANLI: Worker and AI Collaboration for Natural Language Inference Dataset Creation
论文链接:
https://swabhs.com/assets/pdf/wanli.pdf
 人机如何合作?
人机如何合作?
整个方法的流程可以分成四个部分:
找难的样本;
让 GPT3 生成困难样本的同类型样本;
机器自动过滤;
人工检查和优化。
整体很符合直觉,但是我们看到会有两个疑问:
1. 什么是困难的样本?
作者们之前的工作[1] 为数据集设计了一张 data map:
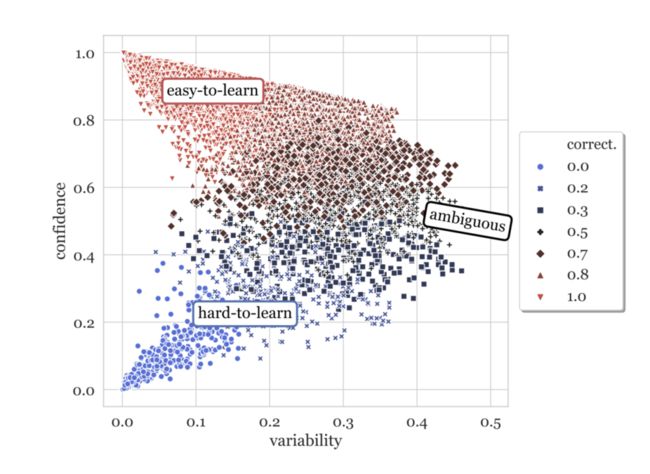
图中每个点代表一个样本:
纵坐标是模型预测 logits 的大小,表示了模型对预测结果的置信度(confidence);
横坐标是模型在不同 epoch 预测这个样本时的置信度方差;
点的颜色代表一个样本在不同 epoch 预测中正确率。蓝色正确率较低,红色较高。
直觉上,我们会认为“置信度低”的就是难以学习的样本。实际上,这些样本大多是标注错误的样本点。而“方差大”的样本才是真正对模型困难的。
作者在原始数据集中选了最困难的样本,作为后面生成数据的种子样本。
2. 怎样界定“同类型”样本?怎样让 GPT3 生成困难样本的同类型样本?
作者对于“同类型”样本的界定并不是说在语意层面的相似度出发,做一些数据增强。而是说,对于这一类“难题”,再给模型出一些在逻辑层面(reasoning)类型相同的难题,比如:
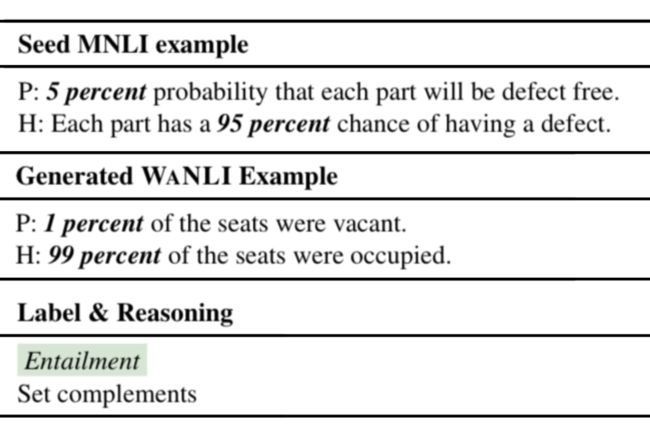
种子样本中,前提说“5% 没有 xxx”,假设说“95% 有 xxx”,两句话之间是数学上的互补关系,因此推断成立。我们要生成的样本也应该具有前提和假设的数学互补关系,这样才是同类困难的样本。
怎样生成同类困难样本?本文作者想到了 GPT3 的 in-context learning。前面给出几个同类的样本作为示例(prompt),后面就让 GPT3 自由生成同类的新样本。可问题又来了,怎样在原数据集里找到这些同类型的样本呢?
作者采取了非常简单的方法:如果两个样本 [CLS] 的表示是接近的,那么就认为这两个样本是上面定义的同类样本。对于每个种子样本,都在原来的数据集中找出同样标签最近的 k 个样本,作为输入 GPT3 的 prompts。
作者基于 MultiNLI 数据集,使用上面的方法生成了 WANLI 数据集。WANLI 数据集只取了 MultiNLI 中四分之一最难的样本作为种子样本,最终 WANLI 的规模也是 MultiNLI 的四分之一。
 用 WANLI 训练的效果?
用 WANLI 训练的效果?

这张图是主实验的结果。作者使用同样的 RoBERTa-large 模型,在不同的数据集上训练和评测。表格纵坐标代表训练的数据集,横坐标代表测试的数据集。彩色的格子代表训练和测试在不同的数据集,即 out-of-domain 的情况。
整个表格分成了上中下三个部分:
上面的部分是只使用 MultiNLI 或者 WANLI 训练,四分之一的数据量训出了显著更好的结果;
中间的部分是用 MultiNLI 融合其它数据集训练。其中 + 指使用两个数据集的和,◇ 指用后面数据集随机替换前面数据集中的样本。结果表明,不是数据越多越好,而是越多困难样本,模型学习结果越好。甚至只用 WANLI 训练,效果是最好的;
下面的部分是 WANLI 和 Adversial NLI(ANLI)对比。ANLI 标注了在 MultiNLI、SNLI、FEVER-NLI 上训练的模型无法预测正确预测的例子。实验发现,本文生成数据集的思路也可以对 ANLI 构成补充。
为了验证生成的数据真的是“难题”,让模型学到了 NLI 需要的信息,而不是因为别的什么巧合提升了性能,作者设计了好几个实验,分别证实了:
不是因为前提中的某些 pattern 造成的性能提升;
不是因为生成的句子中某几个词影响了预测的结果;
不会是因为前提和假设语意相似度就能反应推断结果(即两句话越相似,就越有蕴含关系)。
于是我们大体上可以判定,这个生成数据集的方法是有效的。
 总结
总结
最近越来越多的工作打破了"数据越多越好"的迷信想法。这篇文章给出了一个靠谱的方法,借助 GPT3 生成比人类标注更难的数据,可以说是数据工程之路上的又一步前进。
但生成的样本仍有很多问题,比如会生成重复的话或者自相矛盾的话,有些生成的样本对于 NLI 任务也很难判断是否蕴含。另外,in-context learning 生成的样本大约有 15% 与 prompt 的类别是不一致的,这就不得不引入后续的人的标注。是否能引入约束,让机器同时做好"选择样本"和"标注样本"这两件事,将是后人工作的研究重点。不知道什么时候才能有方法,让机器构建数据集的两种思路统一。
萌屋作者:
在北大读研,目前做信息抽取,对低资源、图网络都非常感兴趣。希望大家在卖萌屋玩得开心 ヾ(=・ω・=)o
作品推荐
老板让我用少量样本 finetune 模型,我还有救吗?急急急,在线等!
谷歌:CNN 击败 Transformer,有望成为预训练界新霸主!LeCun 却沉默了...
中文 BERT 上分新技巧,多粒度信息来帮忙
恕我直言,很多小样本学习的工作就是不切实际的
你的 GNN,可能 99% 的参数都是冗余的
后台回复关键词【入群】
加入卖萌屋NLP/IR/Rec与求职讨论群
后台回复关键词【顶会】
获取ACL、CIKM等各大顶会论文集!

[1] Swabha Swayamdipta, et. al., Dataset Cartography: Mapping and Diagnosing Datasets with Training Dynamics, EMNLP 2020, https://aclanthology.org/2020.emnlp-main.746/
