Hadoop编译源码
文章目录
-
- 第一章 Hadoop编译源码
-
- 1.1 前期准备工作
- 1.2 Jar包安装
-
- 配置maven的环境变量
- 在 mirrors节点中添加阿里云镜像
- 安装gcc make
- 配置环境变量
- 1.3编译源码
- 第二章 常见错误及解决方案
第一章 Hadoop编译源码
1.1 前期准备工作
1)CentOS联网
配置CentOS能连接外网。Linux虚拟机ping www.baidu.com 是畅通的
注意:采用root角色编译,减少文件夹权限出现问题
2)jar包准备(hadoop源码、JDK8、maven、ant 、protobuf)
(1)hadoop-3.1.3-src.tar.gz
(2)jdk-8u212-linux-x64.tar.gz
(3)apache-maven-3.6.3-bin.tar.gz
(4)protobuf-2.5.0.tar.gz(序列化的框架)
(5)cmake-3.13.1.tar.gz
1.2 Jar包安装
注意:所有操作必须在root用户下完成
1)上传软件包到指定的目录 ,例如 /opt/software/hadoop_source
[root@hadoop101 hadoop_source]$ pwd
/opt/software/hadoop_source
[root@hadoop101 hadoop_source]$ ll
总用量 55868
-rw-rw-r--. 1 atbigdata atbigdata 9506321 3月 28 13:23 apache-maven-3.6.3-bin.tar.gz
-rw-rw-r--. 1 atbigdata atbigdata 8614663 3月 28 13:23 cmake-3.13.1.tar.gz
-rw-rw-r--. 1 atbigdata atbigdata 29800905 3月 28 13:23 hadoop-3.1.3-src.tar.gz
-rw-rw-r--. 1 atbigdata atbigdata 2401901 3月 28 13:23 protobuf-2.5.0.tar.gz
2)解压软件包指定的目录,例如: /opt/module/Hadoop_source
[atbigdata@hadoop101 hadoop_source]$ tar -zxvf apache-maven-3.6.3-bin.tar.gz -C /opt/module/hadoop_source/
[atbigdata@hadoop101 hadoop_source]$ tar -zxvf cmake-3.13.1.tar.gz -C /opt/module/hadoop_source/
[atbigdata@hadoop101 hadoop_source]$ tar -zxvf hadoop-3.1.3-src.tar.gz -C /opt/module/hadoop_source/
[atbigdata@hadoop101 hadoop_source]$ tar -zxvf protobuf-2.5.0.tar.gz -C /opt/module/hadoop_source/
[atbigdata@hadoop101 hadoop_source]$ pwd
/opt/module/hadoop_source
[atbigdata@hadoop101 hadoop_source]$ ll
总用量 20
drwxrwxr-x. 6 atbigdata atbigdata 4096 3月 28 13:25 apache-maven-3.6.3
drwxr-xr-x. 15 root root 4096 3月 28 13:43 cmake-3.13.1
drwxr-xr-x. 18 atbigdata atbigdata 4096 9月 12 2019 hadoop-3.1.3-src
drwxr-xr-x. 10 atbigdata atbigdata 4096 3月 28 13:44 protobuf-2.5.0
3)确认Java已安装且配置好环境变量,安装完后验证
[atbigdata@hadoop101 hadoop_source]$ java -version
java version "1.8.0_212"
Java(TM) SE Runtime Environment (build 1.8.0_212-b10)
Java HotSpot(TM) 64-Bit Server VM (build 25.212-b10, mixed mode)
4)配置maven环境变量,maven镜像, 并验证
配置maven的环境变量
[root@hadoop101 hadoop_source]# vim /etc/profile
#MAVEN_HOME
MAVEN_HOME=/opt/module/hadoop_source/apache-maven-3.6.3
PATH=$PATH:$JAVA_HOME/bin:$MAVEN_HOME/bin
[root@hadoop101 hadoop_source]# source /etc/profile
#修改maven的镜像
[root@hadoop101 apache-maven-3.6.3]# vi conf/settings.xml
在 mirrors节点中添加阿里云镜像
<mirrors>
<mirror>
<id>nexus-aliyun</id>
<mirrorOf>central</mirrorOf>
<name>Nexus aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
</mirror>
</mirrors>
[root@hadoop101 hadoop_source]# mvn -version
Apache Maven 3.6.3 (cecedd343002696d0abb50b32b541b8a6ba2883f)
Maven home: /opt/module/hadoop_source/apache-maven-3.6.3
Java version: 1.8.0_212, vendor: Oracle Corporation, runtime: /opt/module/jdk1.8.0_212/jre
Default locale: zh_CN, platform encoding: UTF-8
OS name: "linux", version: "3.10.0-862.el7.x86_64", arch: "amd64", family: "unix"
5)安装相关的依赖(注意安装顺序不可乱,可能会出现依赖找不到问题)
安装gcc make
[root@hadoop101 hadoop_source]# yum install -y gcc* make
#安装压缩工具
[root@hadoop101 hadoop_source]# yum -y install snappy* bzip2* lzo* zlib* lz4* gzip*
#安装一些基本工具
[root@hadoop101 hadoop_source]# yum -y install openssl* svn ncurses* autoconf automake libtool
#安装扩展源,才可安装zstd
[root@hadoop101 hadoop_source]# yum -y install epel-release
#安装zstd
[root@hadoop101 hadoop_source]# yum -y install *zstd*
6)手动安装cmake
1.在解压好的cmake目录下,执行 ./bootstrap 进行编译,此过程需一小会时间耐心等待.
[atbigdata@hadoop101 cmake-3.13.1]$ pwd
/opt/module/hadoop_source/cmake-3.13.1
[atbigdata@hadoop101 cmake-3.13.1]$ ./bootstrap
2.执行安装
[atbigdata@hadoop101 cmake-3.13.1]$ make && make install
3.验证安装是否成功
[atbigdata@hadoop101 cmake-3.13.1]$ cmake -version
cmake version 3.13.1
CMake suite maintained and supported by Kitware (kitware.com/cmake).
- 安装protobuf ,进入到解压后的protobuf目录
[atbigdata@hadoop101 protobuf-2.5.0]$ pwd
/opt/module/hadoop_source/protobuf-2.5.0
#依次执行下列命令 --prefix 指定安装到当前目录
[atbigdata@hadoop101 protobuf-2.5.0]$ ./configure --prefix=/opt/module/hadoop_source/protobuf-2.5.0
[atbigdata@hadoop101 protobuf-2.5.0]$ make && make install
配置环境变量
[atbigdata@hadoop101 protobuf-2.5.0]$ vim /etc/profile
PROTOC_HOME=/opt/module/hadoop_source/protobuf-2.5.0
PATH=$PATH:$JAVA_HOME/bin:$MAVEN_HOME/bin:$PROTOC_HOME/bin
#验证
[atbigdata@hadoop101 protobuf-2.5.0]$ source /etc/profile
[atbigdata@hadoop101 protobuf-2.5.0]$ protoc --version
libprotoc 2.5.0
8)到此,软件包安装配置工作完成。
1.3编译源码
1)进入解压后的hadoop源码目录下
[atbigdata@hadoop101 hadoop-3.1.3-src]$ pwd
/opt/module/hadoop_source/hadoop-3.1.3-src
#开始编译
[atbigdata@hadoop101 hadoop-3.1.3-src]$ mvn clean package -DskipTests -Pdist,native -Dtar
等等等……等待,第一次编译需要下载很多依赖jar包,编译时间会很久,预计1小时 左右,最终成功是全部SUCCESS,爽!!! 如图1-1

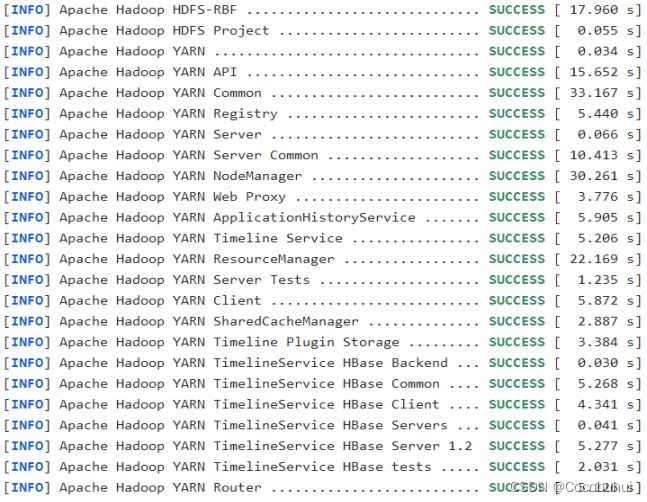
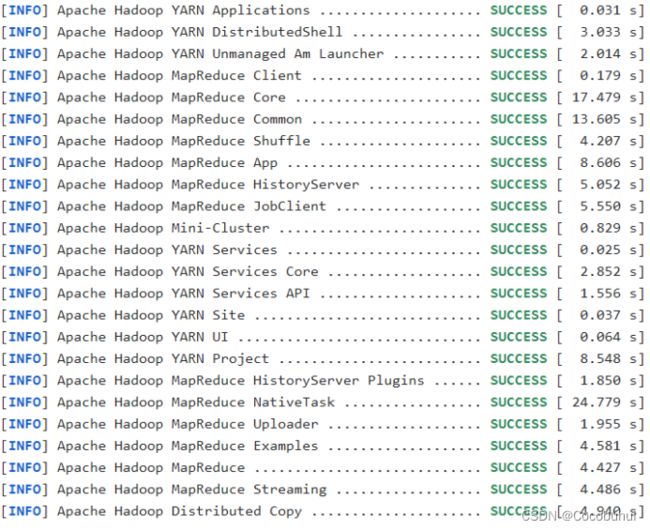
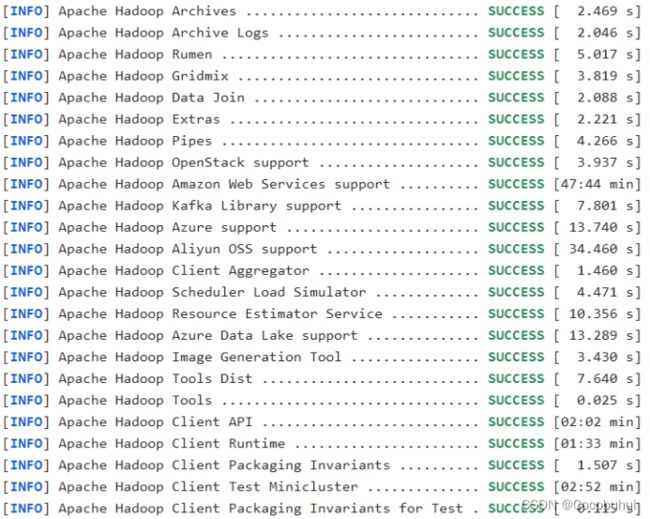

2)成功的64位hadoop包在/opt/hadoop-3.1.3-src/hadoop-dist/target下
[root@hadoop101 target]# pwd
/opt/hadoop-3.1.3-src/hadoop-dist/target
第二章 常见错误及解决方案
1)防火墙没关闭、或者没有启动YARN
INFO client.RMProxy: Connecting to ResourceManager at hadoop108/192.168.10.108:8032
2)主机名称配置错误
3)IP地址配置错误
4)ssh没有配置好
5)root用户和atbigdata两个用户启动集群不统一
6)配置文件修改不细心
7)未编译源码
Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/05/22 15:38:58 INFO client.RMProxy: Connecting to ResourceManager at hadoop108/192.168.10.108:8032
8)不识别主机名称
java.net.UnknownHostException: hadoop102: hadoop102
at java.net.InetAddress.getLocalHost(InetAddress.java:1475)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:146)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1290)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1287)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
解决办法:
(1)在/etc/hosts文件中添加192.168.1.102 hadoop102
(2)主机名称不要起hadoop hadoop000等特殊名称
9)DataNode和NameNode进程同时只能工作一个。
10)执行命令不生效,粘贴word中命令时,遇到-和长–没区分开。导致命令失效
解决办法:尽量不要粘贴word中代码。
11)jps发现进程已经没有,但是重新启动集群,提示进程已经开启。原因是在linux的根目录下/tmp目录中存在启动的进程临时文件,将集群相关进程删除掉,再重新启动集群。
12)jps不生效。
原因:全局变量hadoop java没有生效。解决办法:需要source /etc/profile文件。
13)8088端口连接不上
[atbigdata@hadoop102 桌面]$ cat /etc/hosts
注释掉如下代码
#127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
#::1 hadoop102