机器学习笔记之玻尔兹曼机(一)基本介绍
机器学习笔记之玻尔兹曼机——基本介绍
- 引言
-
- 回顾:玻尔兹曼机的模型表示
- 模型参数的对数似然梯度
-
- 关于模型参数 W \mathcal W W的对数似然梯度
- 关于模型参数 L , J \mathcal L,\mathcal J L,J的对数似然梯度
引言
在受限玻尔兹曼机——模型表示(Representation)一节中以玻尔兹曼机为引,介绍了受限玻尔兹曼机。从本节开始,将正式介绍玻尔兹曼机。相比于它的表示和推断过程,我们更关注它在求解过程中出现的问题。
回顾:玻尔兹曼机的模型表示
玻尔兹曼机本质上是一个马尔可夫随机场(MArkov Random Field),该概率图中结点均表示离散型随机变量,并被限定为伯努利分布。
并且,概率图中结点之间的边是随意的,并没有具体约束。但如果想要描述更加复杂的函数,自然需要结点之间复杂的边作为支撑:
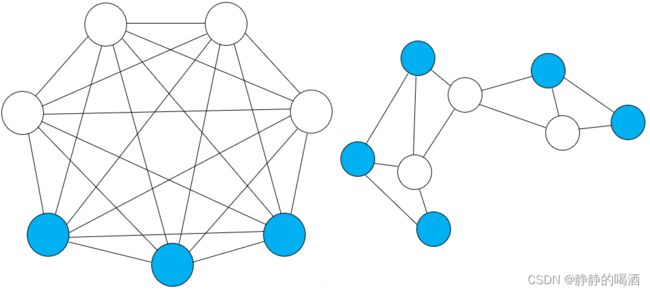
其中左图表示全连接玻尔兹曼机,无论是观测变量,还是隐变量,结点之间均存在边相连接;而右图同样表示玻尔兹曼机,只不过结点之间无明确约束,结点之间的边连接更加随意。
并且玻尔兹曼机并没有被严格要求一定有隐变量。也就是说,玻尔兹曼机可能是一个非隐变量模型,它的结点均由观测变量构成(Fully Observed Model);与之相对的,从生成模型的角度考虑,我们更关注观测变量与隐变量相混合的概率图结构。
依然以包含隐变量的玻尔兹曼机为例,假设某玻尔兹曼机中包含观测变量集合 v v v和隐变量集合 h h h,并且 v v v中的 D \mathcal D D个分量和 h h h中的 P \mathcal P P个分量均服从伯努利分布:
{ v = ( v 1 , v 2 , ⋯ , v D ) T ∈ { 0 , 1 } D h = ( h 1 , h 2 , ⋯ , h P ) T ∈ { 0 , 1 } P \begin{cases} v = (v_1,v_2,\cdots,v_{\mathcal D})^T \in \{0,1\}^{\mathcal D} \\ h = (h_1,h_2,\cdots,h_{\mathcal P})^T \in \{0,1\}^{\mathcal P} \end{cases} {v=(v1,v2,⋯,vD)T∈{0,1}Dh=(h1,h2,⋯,hP)T∈{0,1}P
关于结点之间边的权重,可以将其分成三类:
- 观测变量结点之间的边的权重表示:
L = [ L i j ] D × D \mathcal L = \left[\mathcal L_{ij}\right]_{\mathcal D \times \mathcal D} L=[Lij]D×D - 隐变量结点之间的边的权重表示:
J = [ J i j ] P × P \mathcal J = \left[\mathcal J_{ij}\right]_{\mathcal P \times \mathcal P} J=[Jij]P×P - 观测变量到隐变量结点之间的边的权重表示:
同理,隐变量到观测变量结点之间的权重表示为[ W j i ] P × D [\mathcal W_{ji}]_{\mathcal P \times \mathcal D} [Wji]P×D,两者之间仅差一个转置,信息并没有发生变化。
W = [ W i j ] D × P \mathcal W = \left[\mathcal W_{ij}\right]_{\mathcal D \times \mathcal P} W=[Wij]D×P
至此,结点与边权重均已确定,关于玻尔兹曼机中随机变量(结点)的概率密度函数表示为:
P ( v , h ) = 1 Z exp { − E ( v , h ) } \begin{aligned} \mathcal P(v,h) = \frac{1}{\mathcal Z} \exp \{- \mathbb E(v,h)\} \end{aligned} P(v,h)=Z1exp{−E(v,h)}
而能量函数 E ( v , h ) \mathbb E(v,h) E(v,h)可根据玻尔兹曼机的结构表示,有:
从能量的角度考虑,v i ⋅ W i j ⋅ h j v_i \cdot \mathcal W_{ij} \cdot h_j vi⋅Wij⋅hj表示结点v i v_i vi和结点h j h_j hj之间的能量表示。从概率角度考虑,无论是v i ⋅ W i j ⋅ h j v_i \cdot \mathcal W_{ij} \cdot h_j vi⋅Wij⋅hj还是v i ⋅ L i j ⋅ v j v_i \cdot \mathcal L_{ij} \cdot v_j vi⋅Lij⋅vj,还是h i ⋅ J i j ⋅ h j h_i \cdot \mathcal J_{ij} \cdot h_j hi⋅Jij⋅hj,它们的‘配分函数结果’均表示‘基于某结点的条件下,其他结点发生的概率结果’。观测变量v v v和隐变量h h h均需要乘以1 2 \frac{1}{2} 21是因为无向图模型,仅需要计算一次边对应的能量即可,但实际上每条边在执行运算过程中,均加重了一次。
这里取上述‘全连接玻尔兹曼机’中的观测变量内部连接为例。

观察上图,观测变量内部仅包含三条边,仅需要计算v 1 ⋅ L 12 ⋅ v 2 v_1 \cdot \mathcal L_{12} \cdot v_2 v1⋅L12⋅v2和v 3 ⋅ L 32 ⋅ v 2 v_3 \cdot \mathcal L_{32} \cdot v_2 v3⋅L32⋅v2和v 1 ⋅ L 13 ⋅ v 3 v_1 \cdot \mathcal L_{13} \cdot v_3 v1⋅L13⋅v3这三项即可。但实际上却加了9次:
∑ i = 1 3 ∑ j = 1 3 v i ⋅ L i j ⋅ v j = ( v 1 , v 2 , v 3 ) ( L 11 = 0 , L 12 , L 13 L 21 , L 22 = 0 , L 23 L 31 , L 32 , L 33 = 0 ) ( v 1 v 2 v 3 ) \sum_{i=1}^3\sum_{j=1}^3 v_i \cdot \mathcal L_{ij} \cdot v_j = (v_1,v_2,v_3)\begin{pmatrix} \mathcal L_{11} = 0,\mathcal L_{12},\mathcal L_{13} \\ \mathcal L_{21},\mathcal L_{22} = 0,\mathcal L_{23} \\ \mathcal L_{31},\mathcal L_{32},\mathcal L_{33} = 0 \end{pmatrix}\begin{pmatrix} v_1 \\ v_2 \\ v_3 \end{pmatrix} i=1∑3j=1∑3vi⋅Lij⋅vj=(v1,v2,v3) L11=0,L12,L13L21,L22=0,L23L31,L32,L33=0 v1v2v3
其中L \mathcal L L本身是实对称矩阵,对角线上包含3 3 3个零项;并且L i j = L j i ( i , j ∈ { 1 , 2 , 3 } ; i ≠ j ) \mathcal L_{ij} = \mathcal L_{ji}(i,j \in \{1,2,3\};i\neq j) Lij=Lji(i,j∈{1,2,3};i=j),因而剩余6 6 6项加重了三项,使用1 2 \frac{1}{2} 21将多加的项去掉。
E ( v , h ) = − [ ∑ i = 1 D ∑ j = 1 P v i ⋅ W i j ⋅ h j + 1 2 ∑ i = 1 D ∑ j = 1 D v i ⋅ L i j ⋅ v j + 1 2 ∑ i = 1 P ∑ j = 1 P h i ⋅ J i j ⋅ h j ] = − [ v T W ⋅ h + 1 2 v T L ⋅ v + 1 2 h T J ⋅ h ] \begin{aligned} \mathbb E(v,h) & = - \left[\sum_{i=1}^{\mathcal D}\sum_{j=1}^{\mathcal P} v_i \cdot \mathcal W_{ij} \cdot h_j + \frac{1}{2}\sum_{i=1}^{\mathcal D}\sum_{j=1}^{\mathcal D}v_i \cdot \mathcal L_{ij} \cdot v_j + \frac{1}{2}\sum_{i=1}^{\mathcal P}\sum_{j=1}^{\mathcal P} h_i \cdot \mathcal J_{ij} \cdot h_j\right]\\ & = - \left[v^T\mathcal W \cdot h + \frac{1}{2} v^T \mathcal L \cdot v + \frac{1}{2}h^T \mathcal J \cdot h \right] \end{aligned} E(v,h)=−[i=1∑Dj=1∑Pvi⋅Wij⋅hj+21i=1∑Dj=1∑Dvi⋅Lij⋅vj+21i=1∑Pj=1∑Phi⋅Jij⋅hj]=−[vTW⋅h+21vTL⋅v+21hTJ⋅h]
至此,对应需要学习的模型参数表示为:
θ = { W , L , J } \theta = \{\mathcal W,\mathcal L,\mathcal J\} θ={W,L,J}
模型参数的对数似然梯度
此时已经确定了玻尔兹曼机的概率密度函数,在模型参数的学习过程中,常用方法是极大似然估计。而对于玻尔兹曼机内部变量之间的复杂关系,可能没有办法去求解模型参数的精确解。因而,使用对目标函数求解梯度,通过梯度上升法对模型参数进行近似求解。
在实际求解过程中,仅知道观测变量的相关信息:通过具体样本。因而关于观测变量的边缘概率分布表示如下:
P ( v ) = ∑ h P ( v , h ) \mathcal P(v) = \sum_{h} \mathcal P(v,h) P(v)=h∑P(v,h)
这里定义 V \mathcal V V是样本集合,样本集合 V \mathcal V V中包含 N N N个独立同分布的样本:
V = { v ( 1 ) , v ( 2 ) , ⋯ , v ∣ V ∣ } ∣ V ∣ = N \mathcal V = \{v^{(1)},v^{(2)},\cdots,v^{|\mathcal V|}\} \quad |\mathcal V| = N V={v(1),v(2),⋯,v∣V∣}∣V∣=N
因此,关于 P ( v ) \mathcal P(v) P(v)的对数似然结果表示如下:
1 N \frac{1}{N} N1仅作为一个常数,对似然结果无影响。
P ( V ; θ ) = 1 N log ∏ i = 1 N P ( v ( i ) ; θ ) = 1 N ∑ i = 1 N log P ( v ( i ) ; θ ) \begin{aligned} \mathcal P(\mathcal V;\theta) & = \frac{1}{N} \log \prod_{i=1}^N \mathcal P(v^{(i)};\theta) \\ & = \frac{1}{N} \sum_{i=1}^N \log \mathcal P(v^{(i)};\theta) \end{aligned} P(V;θ)=N1logi=1∏NP(v(i);θ)=N1i=1∑NlogP(v(i);θ)
对模型参数 θ \theta θ求解梯度:
根据牛顿-莱布尼兹公式,将梯度符号与积分号(连加号)调换位置,并将常数 1 N \frac{1}{N} N1提到前面。
∂ P ( V ; θ ) ∂ θ = ∂ ∂ θ [ 1 N ∑ i = 1 N log P ( v ( i ) ; θ ) ] = 1 N ∑ i = 1 N ∂ ∂ θ [ log P ( v ( i ) ; θ ) ] \begin{aligned} \frac{\partial \mathcal P(\mathcal V;\theta)}{\partial \theta} & = \frac{\partial}{\partial \theta} \left[\frac{1}{N} \sum_{i=1}^N \log \mathcal P(v^{(i)};\theta)\right] \\ & = \frac{1}{N} \sum_{i=1}^N \frac{\partial }{\partial \theta}\left[\log \mathcal P(v^{(i)};\theta)\right] \end{aligned} ∂θ∂P(V;θ)=∂θ∂[N1i=1∑NlogP(v(i);θ)]=N1i=1∑N∂θ∂[logP(v(i);θ)]
通过观察发现,仅需要对各具体样本的对数似然结果的梯度进行求解,最后相加即可。
在受限玻尔兹曼机——基于含隐变量能量模型的对数似然梯度中介绍了关于含隐变量能量模型的对数似然梯度通式:
∂ ∂ θ [ log P ( v ( i ) ; θ ) ] = ∑ h ( i ) , v ( i ) { P ( h ( i ) , v ( i ) ) ⋅ ∂ ∂ θ [ E ( h ( i ) , v ( i ) ) ] } − ∑ h ( i ) { P ( h ( i ) ∣ v ( i ) ) ⋅ ∂ ∂ θ [ E ( h ( i ) , v ( i ) ) ] } \frac{\partial }{\partial \theta}\left[\log \mathcal P(v^{(i)};\theta)\right] = \sum_{h^{(i)},v^{(i)}} \left\{\mathcal P(h^{(i)},v^{(i)}) \cdot \frac{\partial}{\partial \theta} \left[\mathbb E(h^{(i)},v^{(i)})\right]\right\} - \sum_{h^{(i)}} \left\{\mathcal P(h^{(i)} \mid v^{(i)}) \cdot \frac{\partial}{\partial \theta} \left[\mathbb E(h^{(i)},v^{(i)})\right]\right\} ∂θ∂[logP(v(i);θ)]=h(i),v(i)∑{P(h(i),v(i))⋅∂θ∂[E(h(i),v(i))]}−h(i)∑{P(h(i)∣v(i))⋅∂θ∂[E(h(i),v(i))]}
关于模型参数 W \mathcal W W的对数似然梯度
以求解 W \mathcal W W为例,求解 W \mathcal W W的梯度:
这里依然需要一些‘矩阵论’中的矩阵求导 -> ∇ W [ E ( v , h ) ] = ∇ W [ − v T W ⋅ h ] = − v h T \nabla_{\mathcal W} \left[\mathbb E(v,h)\right] = \nabla_{\mathcal W} \left[-v^T \mathcal W \cdot h\right] = -vh^T ∇W[E(v,h)]=∇W[−vTW⋅h]=−vhT
∇ W [ log P ( v ( i ) ; θ ) ] = ∂ ∂ W [ log P ( v ( i ) ; θ ) ] = ∑ h ( i ) , v ( i ) P ( h ( i ) , v ( i ) ) ⋅ [ − v ( i ) ( h ( i ) ) T ] − ∑ h ( i ) P ( h ( i ) ∣ v ( i ) ) ⋅ [ − v ( i ) ( h ( i ) ) T ] = ∑ h ( i ) P ( h ( i ) ∣ v ( i ) ) ⋅ [ v ( i ) ( h ( i ) ) T ] − ∑ h ( i ) , v ( i ) P ( h ( i ) , v ( i ) ) ⋅ [ v ( i ) ( h ( i ) ) T ] \begin{aligned} \nabla_{\mathcal W}\left[\log \mathcal P(v^{(i)};\theta)\right] & = \frac{\partial}{\partial \mathcal W} \left[\log \mathcal P(v^{(i)};\theta)\right] \\ & = \sum_{h^{(i)},v^{(i)}} \mathcal P(h^{(i)},v^{(i)}) \cdot \left[-v^{(i)}(h^{(i)})^T\right] -\sum_{h^{(i)}} \mathcal P(h^{(i)} \mid v^{(i)}) \cdot \left[-v^{(i)}(h^{(i)})^T\right] \\ & = \sum_{h^{(i)}} \mathcal P(h^{(i)} \mid v^{(i)}) \cdot \left[v^{(i)}(h^{(i)})^T\right] - \sum_{h^{(i)},v^{(i)}} \mathcal P(h^{(i)},v^{(i)}) \cdot \left[v^{(i)}(h^{(i)})^T\right] \end{aligned} ∇W[logP(v(i);θ)]=∂W∂[logP(v(i);θ)]=h(i),v(i)∑P(h(i),v(i))⋅[−v(i)(h(i))T]−h(i)∑P(h(i)∣v(i))⋅[−v(i)(h(i))T]=h(i)∑P(h(i)∣v(i))⋅[v(i)(h(i))T]−h(i),v(i)∑P(h(i),v(i))⋅[v(i)(h(i))T]
因而关于模型参数 W \mathcal W W的对数似然梯度可表示为:
1 N ∑ i = 1 N ∂ ∂ W [ log P ( v ( i ) ; θ ) ] = 1 N ∑ i = 1 N ∇ W [ log P ( v ( i ) ; θ ) ] = 1 N ∑ i = 1 N { ∑ h ( i ) P ( h ( i ) ∣ v ( i ) ) ⋅ [ v ( i ) ( h ( i ) ) T ] − ∑ h ( i ) , v ( i ) P ( h ( i ) , v ( i ) ) ⋅ [ v ( i ) ( h ( i ) ) T ] } = 1 N ∑ i = 1 N ∑ h ( i ) P ( h ( i ) ∣ v ( i ) ) ⋅ [ v ( i ) ( h ( i ) ) T ] − 1 N ∑ i = 1 N ∑ h ( i ) , v ( i ) P ( h ( i ) , v ( i ) ) ⋅ [ v ( i ) ( h ( i ) ) T ] \begin{aligned} \frac{1}{N} \sum_{i=1}^N \frac{\partial}{\partial \mathcal W} \left[\log \mathcal P(v^{(i)};\theta)\right] & = \frac{1}{N} \sum_{i=1}^N\nabla_{\mathcal W}\left[\log \mathcal P(v^{(i)};\theta)\right] \\ & = \frac{1}{N} \sum_{i=1}^N \left\{\sum_{h^{(i)}} \mathcal P(h^{(i)} \mid v^{(i)}) \cdot \left[v^{(i)}(h^{(i)})^T\right] - \sum_{h^{(i)},v^{(i)}} \mathcal P(h^{(i)},v^{(i)}) \cdot \left[v^{(i)}(h^{(i)})^T\right]\right\} \\ & = \frac{1}{N} \sum_{i=1}^N \sum_{h^{(i)}} \mathcal P(h^{(i)} \mid v^{(i)}) \cdot \left[v^{(i)}(h^{(i)})^T\right] - \frac{1}{N} \sum_{i=1}^N \sum_{h^{(i)},v^{(i)}} \mathcal P(h^{(i)},v^{(i)}) \cdot \left[v^{(i)}(h^{(i)})^T\right] \end{aligned} N1i=1∑N∂W∂[logP(v(i);θ)]=N1i=1∑N∇W[logP(v(i);θ)]=N1i=1∑N⎩ ⎨ ⎧h(i)∑P(h(i)∣v(i))⋅[v(i)(h(i))T]−h(i),v(i)∑P(h(i),v(i))⋅[v(i)(h(i))T]⎭ ⎬ ⎫=N1i=1∑Nh(i)∑P(h(i)∣v(i))⋅[v(i)(h(i))T]−N1i=1∑Nh(i),v(i)∑P(h(i),v(i))⋅[v(i)(h(i))T]
观察第二项, ∑ h ( i ) , v ( i ) P ( h ( i ) , v ( i ) ) ⋅ [ v ( i ) ( h ( i ) ) T ] \sum_{h^{(i)},v^{(i)}} \mathcal P(h^{(i)},v^{(i)}) \cdot \left[v^{(i)}(h^{(i)})^T\right] ∑h(i),v(i)P(h(i),v(i))⋅[v(i)(h(i))T]中 h ( i ) , v ( i ) h^{(i)},v^{(i)} h(i),v(i)被积分掉了,因而该式和 i i i无关。因此有:
将第二项表示为期望形式,并且该期望基于的分布是 P ( h ( i ) , v ( i ) ) \mathcal P(h^{(i)},v^{(i)}) P(h(i),v(i)),即模型自身所有结点的联合概率分布。
1 N ∑ i = 1 N ∑ h ( i ) , v ( i ) P ( h ( i ) , v ( i ) ) ⋅ [ v ( i ) ( h ( i ) ) T ] = 1 N ⋅ N ⋅ ∑ h ( i ) , v ( i ) P ( h ( i ) , v ( i ) ) ⋅ [ v ( i ) ( h ( i ) ) T ] = ∑ h ( i ) , v ( i ) P ( h ( i ) , v ( i ) ) ⋅ [ v ( i ) ( h ( i ) ) T ] = E P m o d e l [ v ( i ) ( h ( i ) ) T ] P m o d e l ⇒ P m o d e l ( h ( i ) , v ( i ) ) \begin{aligned} \frac{1}{N} \sum_{i=1}^N \sum_{h^{(i)},v^{(i)}} \mathcal P(h^{(i)},v^{(i)}) \cdot \left[v^{(i)}(h^{(i)})^T\right] & = \frac{1}{N} \cdot N \cdot \sum_{h^{(i)},v^{(i)}} \mathcal P(h^{(i)},v^{(i)}) \cdot \left[v^{(i)}(h^{(i)})^T\right] \\ & = \sum_{h^{(i)},v^{(i)}} \mathcal P(h^{(i)},v^{(i)}) \cdot \left[v^{(i)}(h^{(i)})^T\right] \\ & = \mathbb E_{\mathcal P_{model}} \left[v^{(i)}(h^{(i)})^T\right] \quad \mathcal P_{model} \Rightarrow \mathcal P_{model}(h^{(i)},v^{(i)}) \end{aligned} N1i=1∑Nh(i),v(i)∑P(h(i),v(i))⋅[v(i)(h(i))T]=N1⋅N⋅h(i),v(i)∑P(h(i),v(i))⋅[v(i)(h(i))T]=h(i),v(i)∑P(h(i),v(i))⋅[v(i)(h(i))T]=EPmodel[v(i)(h(i))T]Pmodel⇒Pmodel(h(i),v(i))
对应的,第一项可表示为:
根据蒙特卡洛方法的逆推过程,可以将其理解成‘期望的期望’,而 ∑ i = 1 N \sum_{i=1}^N ∑i=1N可以看作是从‘真实分布’ P d a t a \mathcal P_{data} Pdata中抽取出的 N N N个样本。
1 N ∑ i = 1 N ∑ h ( i ) P ( h ( i ) ∣ v ( i ) ) ⋅ [ v ( i ) ( h ( i ) ) T ] = 1 N ∑ i = 1 N { E P ( h ( i ) ∣ v ( i ) ) [ v ( i ) ( h ( i ) ) T ] } ≈ E P d a t a ( v ( i ) ∈ V ) { E P ( h ( i ) ∣ v ( i ) ) [ v ( i ) ( h ( i ) ) T ] } \begin{aligned} & \quad \frac{1}{N} \sum_{i=1}^N \sum_{h^{(i)}} \mathcal P(h^{(i)} \mid v^{(i)}) \cdot \left[v^{(i)}(h^{(i)})^T\right] \\ & = \frac{1}{N} \sum_{i=1}^N \left\{\mathbb E_{\mathcal P(h^{(i)} \mid v^{(i)})} \left[v^{(i)}(h^{(i)})^T\right]\right\} \\ & \approx \mathbb E_{\mathcal P_{data}(v^{(i)} \in \mathcal V)} \left\{\mathbb E_{\mathcal P(h^{(i)} \mid v^{(i)})} \left[v^{(i)}(h^{(i)})^T\right]\right\}\end{aligned} N1i=1∑Nh(i)∑P(h(i)∣v(i))⋅[v(i)(h(i))T]=N1i=1∑N{EP(h(i)∣v(i))[v(i)(h(i))T]}≈EPdata(v(i)∈V){EP(h(i)∣v(i))[v(i)(h(i))T]}
最终使用一个符号 P d a t a \mathcal P_{data} Pdata进行表示。其中 P ( h ( i ) ∣ v ( i ) ) \mathcal P(h^{(i)} \mid v^{(i)}) P(h(i)∣v(i))表示某样本 v ( i ) v^{(i)} v(i)对应模型中隐变量的后验概率,因而它是基于模型产生的概率分布。因为在样本分布中, h ( i ) h^{(i)} h(i)无法被观测,是不存在的。
E P d a t a ( v ( i ) ∈ V ) { E P ( h ( i ) ∣ v ( i ) ) [ v ( i ) ( h ( i ) ) T ] } = E P d a t a [ v ( i ) ( h ( i ) ) T ] P d a t a ⇒ P d a t a ( v ( i ) ∈ V ) ⋅ P m o d e l ( h ( i ) ∣ v ( i ) ) \begin{aligned} & \mathbb E_{\mathcal P_{data}(v^{(i)} \in \mathcal V)} \left\{\mathbb E_{\mathcal P(h^{(i)} \mid v^{(i)})} \left[v^{(i)}(h^{(i)})^T\right]\right\} = \mathbb E_{\mathcal P_{data}} \left[v^{(i)}(h^{(i)})^T\right] \\ & \mathcal P_{data} \Rightarrow \mathcal P_{data}(v^{(i)} \in \mathcal V) \cdot \mathcal P_{model}(h^{(i)} \mid v^{(i)}) \end{aligned} EPdata(v(i)∈V){EP(h(i)∣v(i))[v(i)(h(i))T]}=EPdata[v(i)(h(i))T]Pdata⇒Pdata(v(i)∈V)⋅Pmodel(h(i)∣v(i))
终上,模型参数 W \mathcal W W的对数似然梯度可表示为:
1 N ∑ i = 1 N ∇ W [ log P ( v ( i ) ; θ ) ] = E P d a t a [ v ( i ) ( h ( i ) ) T ] − E P m o d e l [ v ( i ) ( h ( i ) ) T ] { P d a t a = P d a t a ( v ( i ) ∈ V ) ⋅ P m o d e l ( h ( i ) ∣ v ( i ) ) P m o d e l = P m o d e l ( h ( i ) , v ( i ) ) \frac{1}{N} \sum_{i=1}^N \nabla_{\mathcal W} \left[\log \mathcal P(v^{(i)};\theta)\right] = \mathbb E_{\mathcal P_{data}} \left[v^{(i)}(h^{(i)})^T\right] - \mathbb E_{\mathcal P_{model}} \left[v^{(i)}(h^{(i)})^T\right] \\ \begin{cases} \mathcal P_{data} = \mathcal P_{data}(v^{(i)} \in \mathcal V) \cdot \mathcal P_{model}(h^{(i)} \mid v^{(i)}) \\ \mathcal P_{model} = \mathcal P_{model}(h^{(i)},v^{(i)}) \end{cases} N1i=1∑N∇W[logP(v(i);θ)]=EPdata[v(i)(h(i))T]−EPmodel[v(i)(h(i))T]{Pdata=Pdata(v(i)∈V)⋅Pmodel(h(i)∣v(i))Pmodel=Pmodel(h(i),v(i))
关于模型参数 L , J \mathcal L,\mathcal J L,J的对数似然梯度
关于模型参数 L , J \mathcal L,\mathcal J L,J和 W \mathcal W W的求解过程完全相同,只不过针对不同的参数项进行求导而已,这里就不再描述过程了。对应梯度表示如下:
关于 L \mathcal L L的项 ∇ L [ E ( v , h ) ] = ∇ L [ v T L ⋅ v ] = v v T \nabla_{\mathcal L} [\mathbb E(v,h)] = \nabla_{\mathcal L} \left[v^T\mathcal L\cdot v\right] = vv^T ∇L[E(v,h)]=∇L[vTL⋅v]=vvT
关于 J \mathcal J J的项 ∇ J [ E ( v , h ) ] = ∇ J [ h T J ⋅ h ] = h h T \nabla_{\mathcal J} [\mathbb E(v,h)] = \nabla_{\mathcal J} \left[h^T\mathcal J \cdot h\right] = hh^T ∇J[E(v,h)]=∇J[hTJ⋅h]=hhT
1 N ∑ i = 1 N ∇ L [ log P ( v ( i ) ; θ ) ] = E P d a t a [ v ( i ) ( v ( i ) ) T ] − E P m o d e l [ v ( i ) ( v ( i ) ) T ] 1 N ∑ i = 1 N ∇ J [ log P ( v ( i ) ; θ ) ] = E P d a t a [ h ( i ) ( h ( i ) ) T ] − E P m o d e l [ h ( i ) ( h ( i ) ) T ] \begin{aligned} \frac{1}{N} \sum_{i=1}^N \nabla_{\mathcal L} \left[\log \mathcal P(v^{(i)};\theta)\right] & = \mathbb E_{\mathcal P_{data}} \left[v^{(i)}(v^{(i)})^T\right] - \mathbb E_{\mathcal P_{model}} \left[v^{(i)}(v^{(i)})^T\right] \\ \frac{1}{N} \sum_{i=1}^N \nabla_{\mathcal J} \left[\log \mathcal P(v^{(i)};\theta)\right]& = \mathbb E_{\mathcal P_{data}} \left[h^{(i)}(h^{(i)})^T\right] - \mathbb E_{\mathcal P_{model}} \left[h^{(i)}(h^{(i)})^T\right] \end{aligned} N1i=1∑N∇L[logP(v(i);θ)]N1i=1∑N∇J[logP(v(i);θ)]=EPdata[v(i)(v(i))T]−EPmodel[v(i)(v(i))T]=EPdata[h(i)(h(i))T]−EPmodel[h(i)(h(i))T]
下一节将介绍基于马尔科夫链蒙特卡洛方法(MCMC)求解各参数的梯度,从而实现随机梯度上升过程。
相关参考:
(系列二十八)玻尔兹曼机1-介绍
(系列二十八)玻尔兹曼机2-log似然的梯度