机器学习之波士顿房价预测
机器学习之波士顿房价预测
Boston house prices dataset
Data Set Characteristics:
:Number of Instances: 506
:Number of Attributes: 13 numeric/categorical predictive. Median Value (attribute 14) is usually the target.
:Attribute Information (in order):
- CRIM per capita crime rate by town
- ZN proportion of residential land zoned for lots over 25,000 sq.ft.
- INDUS proportion of non-retail business acres per town
- CHAS Charles River dummy variable (= 1 if tract bounds river; 0 otherwise)
- NOX nitric oxides concentration (parts per 10 million)
- RM average number of rooms per dwelling
- AGE proportion of owner-occupied units built prior to 1940
- DIS weighted distances to five Boston employment centres
- RAD index of accessibility to radial highways
- TAX full-value property-tax rate per $10,000
- PTRATIO pupil-teacher ratio by town
- B 1000(Bk - 0.63)^2 where Bk is the proportion of blacks by town
- LSTAT % lower status of the population
- MEDV Median value of owner-occupied homes in $1000's
:Missing Attribute Values: None
:Creator: Harrison, D. and Rubinfeld, D.L.
CRIM:城镇人均犯罪率
ZN:住宅用地超过25000 sq.ft.的比例
INDUS:城镇非零售商用土地的比例
CHAS:边界是河流为1,否则0
NOX: 一氧化氮浓度
RM:住宅平均房间数
AGE: 1940年之前建成的自用房屋比例
DIS:到波士顿5个中心区域的加权距离
RAD:辐射性公路的靠近指数
TAX:每10000美元的全值财产税率
PTRATIO:城镇师生比例
LSTAT:人口中地位低下者的比例
MEDV:自住房的平均房价,单位:千美元
This is a copy of UCI ML housing dataset.
https://archive.ics.uci.edu/ml/machine-learning-databases/housing/
This dataset was taken from the StatLib library which is maintained at Carnegie Mellon University.
The Boston house-price data of Harrison, D. and Rubinfeld, D.L. ‘Hedonic
prices and the demand for clean air’, J. Environ. Economics & Management,
vol.5, 81-102, 1978. Used in Belsley, Kuh & Welsch, ‘Regression diagnostics
…’, Wiley, 1980. N.B. Various transformations are used in the table on
pages 244-261 of the latter.
The Boston house-price data has been used in many machine learning papers that address regression
problems.
… topic:: References
- Belsley, Kuh & Welsch, ‘Regression diagnostics: Identifying Influential Data and Sources of Collinearity’, Wiley, 1980. 244-261.
- Quinlan,R. (1993). Combining Instance-Based and Model-Based Learning. In Proceedings on the Tenth International Conference of Machine Learning, 236-243, University of Massachusetts, Amherst. Morgan Kaufmann.
波士顿房价预测各各参数与target的关系图
CRIM
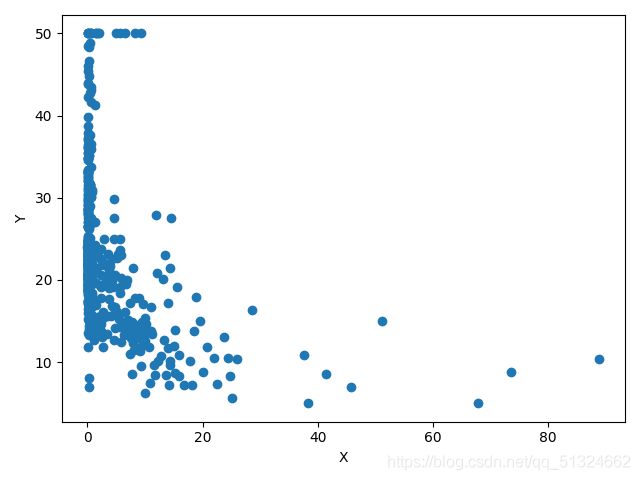
ZN
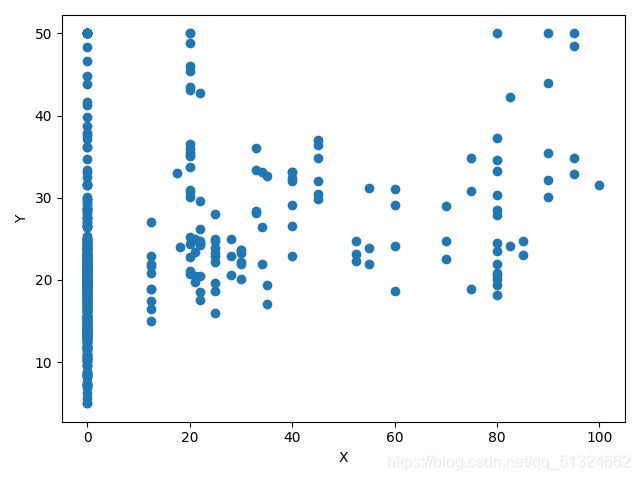
INDUS
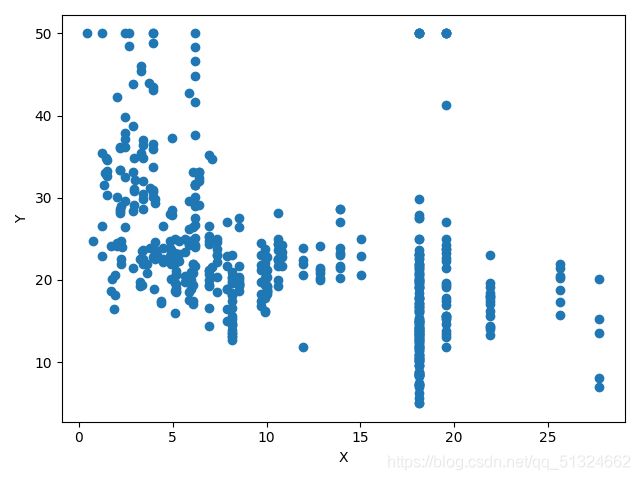
CHAS
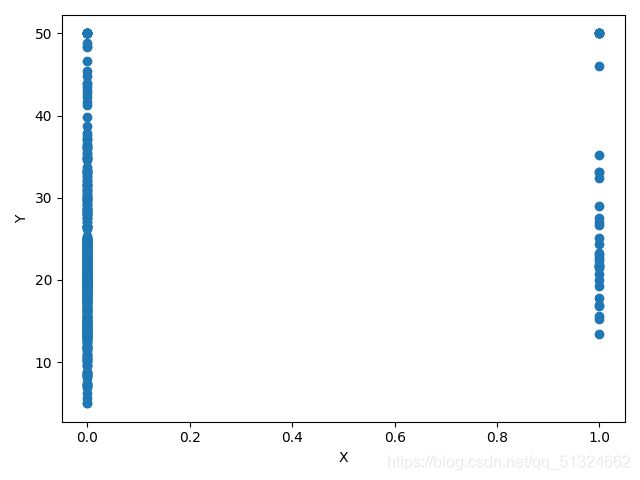
NOX
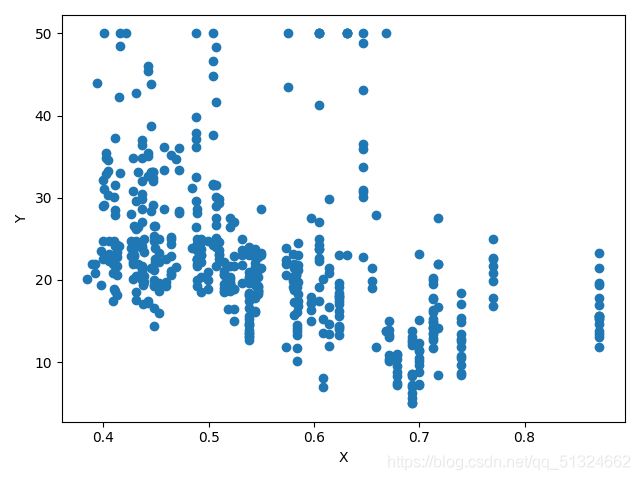
RM
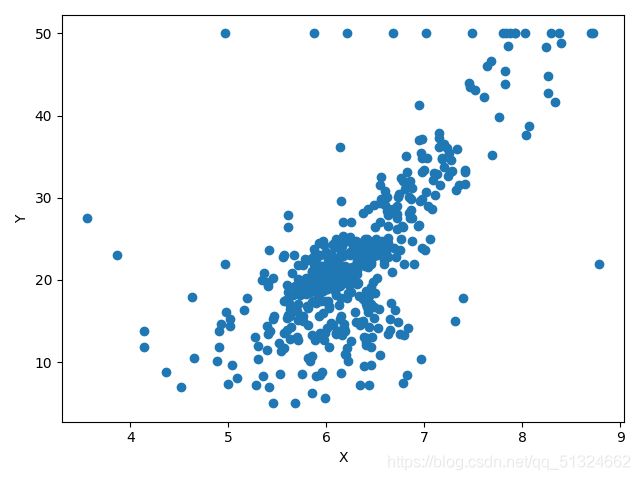
AGE
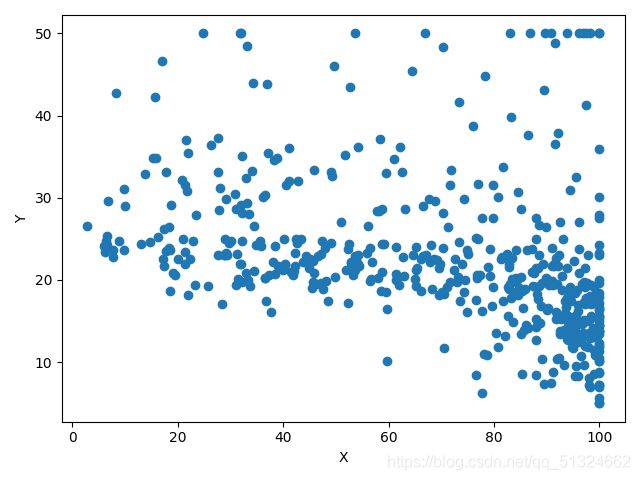
DIS
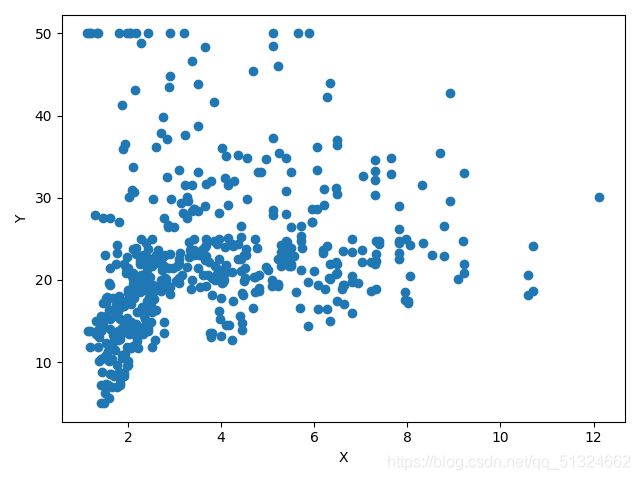
RAD
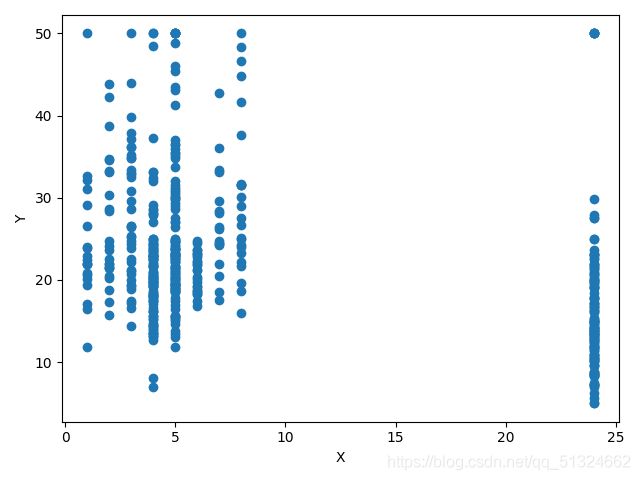
TAX
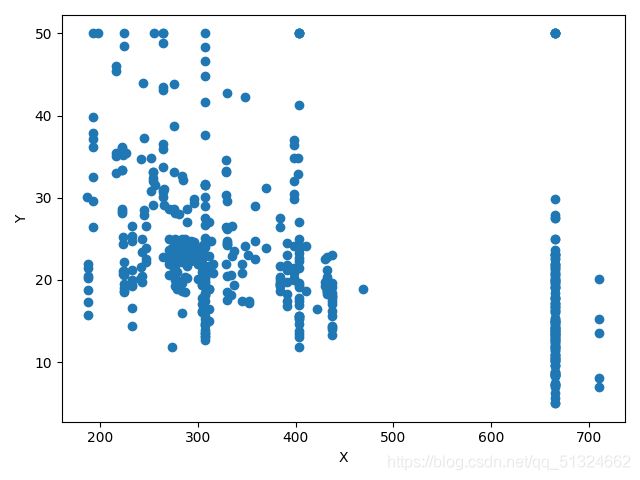
PTRATIO
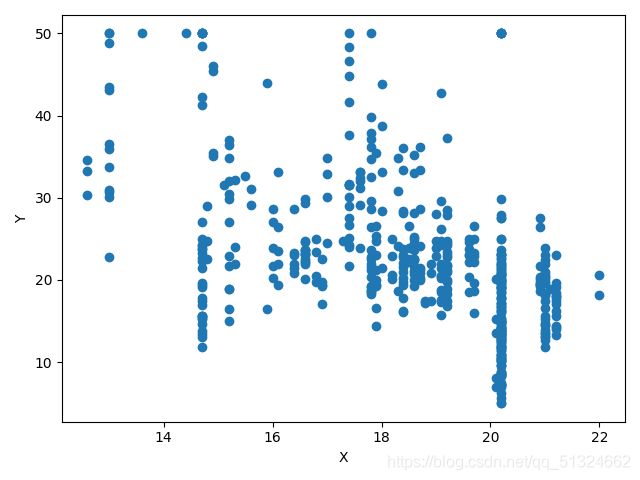
LSTAT
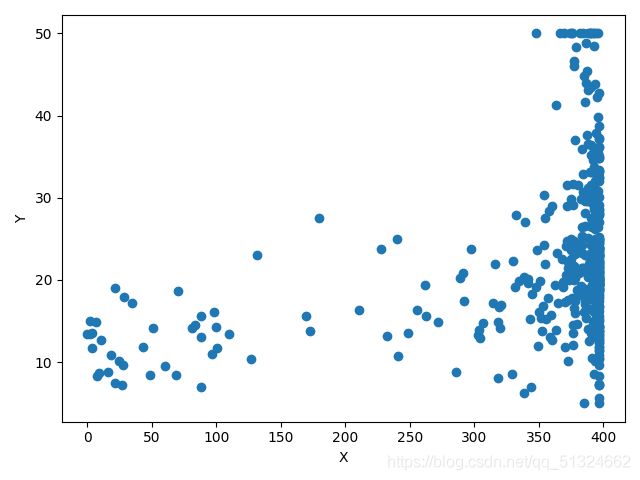
MEDV
归一化处理
这里有一个很好的博客

简而言之,1、在分类、聚类算法中,需要使用距离来度量相似性的时候、或者使用PCA技术进行降维的时候,第二种方法(Z-score standardization)表现更好。
2、在不涉及距离度量、协方差计算、数据不符合正太分布的时候,可以使用第一种方法或其他归一化方法。比如图像处理中,将RGB图像转换为灰度图像后将其值限定在[0 255]的范围。
很明显这个预测采用,第一种方法优化比较好
有一点让人注意:如果归一化的过程中,两个参数之间可能有关系,或者是每个关系会对target的权值造成的影响不同,那么这个归一化的过程就不让人满意。但是,要知道在神经网络计算中y=W*wx这个会归一化的权重会被分配到神经网络计算中所以,这点不让人满意完全是可以忽略的
选择优化器
一些最常用的优化器
在深度学习中,几乎所有流行的优化器都基于梯度下降。这意味着他们反复估计给定的损失函数L的斜率,并将参数向相反的方向移动(因此向下爬升到一个假设的全局最小值)。这种优化器最简单的例子可能是随机梯度下降(或SGD),自20世纪50年代以来一直使用。在2010年代,自适应梯度的使用,如AdaGrad或Adam已经变得越来越流行了。然而,最近的趋势表明,部分研究界重新使用SGD而不是自适应梯度方法。此外,当前深度学习的挑战带来了新的SGD变体,如LARS或LAMB。例如,谷歌研究在其最新论文中使用LARS训练了一个强大的自监督模型。
下面的部分将介绍最流行的优化器。如果你已经熟悉了这些概念,请转到“如何选择正确的优化器”部分。
我们将使用以下符号:用w表示参数,用g表示模型的梯度,α为每个优化器的全局学习率,t为时间步长。
Stochastic Gradient Descent (SGD)

Stochastic Gradient Descent (SGD)的更新规则
在SGD中,优化器基于一个小batch估计最陡下降的方向,并在这个方向前进一步。由于步长是固定的,SGD会很快陷入平坦区或陷入局部极小值。
SGD with Momentum

带动量的SGD的更新规则
其中β < 1,使用了动量,SGD可以在持续的方向上进行加速(这就是为什么也被叫做“重球方法”)。这个加速可以帮助模型摆脱平坦区,使它更不容易陷入局部最小值。
AdaGrad

AdaGrad的更新规则
AdaGrad是首个成功的利用自适应学习率的方法之一(因此得名)。AdaGrad根据梯度的平方和的倒数的平方根来衡量每个参数的学习速率。这个过程将稀疏梯度方向上的梯度放大,从而允许在这些方向上执行更大的步骤。其结果是:AdaGrad在具有稀疏特征的场景中收敛速度更快。
RMSprop

RMSprop的更新规则
RMSprop是一个未发布的优化器,在过去几年中被过度使用。这个想法与AdaGrad相似,但是梯度的重新缩放不那么激进:梯度的平方的总和被梯度平方的移动平均值所取代。RMSprop通常与动量一起使用,可以理解为Rprop对mini-batch设置的适应。
Adam

Adam的更新规则
Adam将AdaGrad,RMSprop和动量法结合在一起。步长方向由梯度的移动平均值决定,步长约为全局步长的上界。此外,梯度的每个维度都被重新缩放,类似于RMSprop。Adam和RMSprop(或AdaGrad)之间的一个关键区别是,矩估计m和v被纠正为偏向于零。Adam以通过少量的超参数调优就能获得良好性能而闻名。
LARS

LARS的更新规则
LARS是使用动量的SGD的一种扩展,具有适应每层学习率的能力。它最近引起了研究界的注意。原因是由于可用数据量的稳步增长,机器学习模型的分布式训练已经流行起来。其结果是批大小开始增长。然而,这导致了训练中的不稳定。Yang等人认为,这些不稳定性源于某些层的梯度范数和权重范数之间的不平衡。因此,他们提出了一个优化器,该优化器基于一个“trust”参数η < 1和该层的梯度的范数的倒数,对每一层的学习率进行缩放。
这是deeplearning书中关于优化器的长处和短处

这些东西的选择最重要的是积累需要多看论文,多积累知识才能实现最好的优化方法
在本这个预测中我们当然选择admn梯度下降方法啦
划分数据集
这个很简单一般就分为:训练集和测试集
模型搭建
我们根据一篇论文:

搭建模型如下:
训练效果

github上的仓库:https://github.com/hideonpython/-tensorflow2.0-