【读论文】VIT(Vision Transformer)
文章目录
- An Image is Worth 16*16 Words:Transformers for Image Recogniztion at Scale
-
- NLP领域的transformer应用到CV领域有哪些难点?
- Abstract
- Introduction
- Related Work
-
- (1)BERT
- (2)GPT
- (3)self-attention在CV领域的应用
- Method
-
- 整个前向传播过程
- 针对cls token的消融实验
- 对于位置编码的消融实验
- Hybrid Architecture(混合模型)
- Experiment
-
- 实验结果
- INSPECTING VISION TRANSFORMER(可视化vit的工作过程)
-
- (1)patch embedding
- (2)position embedding
- (3)自注意力是否像我们预期的那样工作:可以模拟长距离的关系
- (4)自注意力
- 自监督的学习方式
- Conclusion
- 未来展望
论文连接:
AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE

An Image is Worth 16*16 Words:Transformers for Image Recogniztion at Scale
NLP领域的transformer应用到CV领域有哪些难点?
算attention时是两两相互的,如果输入序列的长度是n,那么该过程的时间复杂度是O( n 2 n^2 n2)。在NLP中,目前硬件能支持的序列长度n一般是几百或上千。在BERT中,n=512。
- 2d的图片如何变成1d的序列或集合
最简单的直接将图像(假设尺寸为224x224)拉直,每个像素点当成序列中的元素,序列长度为224*224=50176,相当于是BERT中序列长度的100倍,会使计算attention的时候时间复杂度太高。此外,对于分类任务通常输入的是224x224,但对于检测和分割任务会达到600x600或800x800或者更大。
Abstract
- transformer是NLP领域的标准(BERT、GPT3、T5…),但很少应用于CV领域。
- CV领域中,attention要么是和卷积网络一起使用,要么是用attention替换卷积,并保持整体结构不变。(注:比如一个残差网络resnet50,有4个stage:res2,res3,res4,res5,只是用attention去取代每个block的操作)
- 我们的工作表明CV任务中,卷积网络并不是必要的,纯transformer可以直接应用于序列图片的图像分类任务。
- 当在大数据集上预训练再在迁移到中小数据集(ImageNet,CIFAR-100,VTAB,etc)上做识别VIT有很好的效果(和最好的卷积网络相媲美)。
Introduction
- transformer在NLP领域中扩展得很好,越大的数据,越大的模型最后得performance会一直上升,没有饱和的现象,那么transformer在视觉任务上,performance是不是也能获得大幅度的提升?
- 为了将transformer用于视觉任务,就要降低输入序列的长度,有论文将卷积后的特征图输入到transformer中,即将卷积和自注意力相结合
- 有的将卷积全部替换成自注意力机制:Stand-ALone Attention(孤立注意力,控制一个局部的小窗口的大小来控制输入序列的长度,有点像回到卷积的一个操作,因为卷积也是在局部的一个window里做的),Axial Attention(轴注意力,N=H*W,将一个在2d矩阵上的自注意力操作变成两个在1d的向量上的自注意力操作)
- 全部替换的这种自注意力操作理论上是高效的,但是Stand-ALone Attention和Axial Attention都是比较特殊的自注意力操作,没有在现在的硬件上加速,很难用它去训练一个大模型,所以基于Stand-ALone Attention都不会很大和Axial Attention的模型和百亿、千亿参数的transformer大模型相差甚远。在大规模的图像识别任务上,传统的残差网络还是效果最好的。
- 本论文的特点(本文想讲的故事) 是:直接用一个标准的transformer作用于图像,做尽可能少的修改(不做任何针对视觉任务的改变),这样的transformer能不能在视觉领域中扩展得很大。本文是如何解决输入序列过长的问题的呢?将一个图片分割成16*16个patch,如果输入图片是224 * 224,将每个patch作为输入序列的元素,那么输入的序列长度就是14 * 14=196。
- 本论文训练模型采用的是有监督的训练方式。强调这个是因为NLP领域中,transformer都是用无监督的方式训练(language modeling/mask language modeling),对于视觉任务大都是用有监督的baseline去训练。

- 如果在ImageNet数据集上不加较强的约束(regularization),VIT模型和同等大小的resnet相比要弱几个点,这是因为transformer跟卷积神经网络相比缺少归纳偏置(inductive bias)。Inductive bias是指我们的先验知识或提前做好的假设。对于卷积神经网络就有两个归纳偏置:locality:局部相关性(卷积神经网络是以滑窗的形式在图片上一点一点卷积的,所以它假设图片上相邻的区域会有很多相邻的特征)和translation equivariance:平移等变性( f ( g ( x ) ) = g ( f ( x ) ) f(g(x))=g(f(x)) f(g(x))=g(f(x)), f f f理解为卷积, g g g理解为平移。f和g的处理顺序对结果没有影响)。但是对于transformer来说,它没有这些先验信息,这些感知信息transformer全都要从数据里自己学。所以本论文上大数据集(14M-300M images),效果拔群。得出在transformer上大规模的预训练在下游任务上迁移学习比卷积的归纳偏置效果要好的结论。
Related Work
(1)BERT
a denoising self-supervised pre-training task:去噪的自监督方式(类似于一个完形填空,有一个句子,把其中某些词划掉,然后再把这些词predict出来)
(2)GPT
uses language modeling as its pre-training task :language modeling的自监督方式(我们已经有一个句子,我要预测下一个词是什么,next word prediction)
(3)self-attention在CV领域的应用
- 直接在像素层面上做自注意力,时间复杂度O( n 2 n^2 n2)过大,很难应用到真实尺寸的图片上
- 不用整张图,而用local neighborhoods做自注意力:local multi-head dot-product self attention blocks
- Sparse Transformers:只对稀疏的点做自注意力,相当于全局注意力的近似
- Axial Attention:现在横轴上做自注意力,再在纵轴上做自注意力
以上特制的自注意力结构在视觉任务上的表现都是可以的,但是需要很复杂的工程去加速算子,从而在CPU或GPU上跑得很快,让训练一个大模型称为可能。 - image GPT(iGPT),一个生成型模型,采用无监督的方式训练。拿训练好的模型去做微调,或者把它当成特征提取器,在imagenNet上最高的准确率只能达到72%。(注:在MAE之前生成式网络在视觉任务上是没办法跟判别式网络比的)
Method

整个前向传播过程
-
将图像(X:224 * 224 * 3)打成一个九宫格(假设每个patch是16 * 16),再将得到的九宫格排成一个序列(包含14 * 14个token,此时得到的数据维度:196 * 16 * 16 * 3=196 * 768)
-
Patch Embedding:通过一个linear projection of flattenned patches(线性投射层,就是一个全连接层E,维度为768 * 768,前面这个768是从图像patch算来的16 * 16 * 3=768;后面的768就是文章中提到的D,这个D是可变的,如果transformer更大,D也可以相应地变得更大)得到一个特征(X·E=(196 * 768) * (768 * 768),即X·E的维度是196 * 768)。此外,除了图像本身带来的token外,还要加一个额外的特殊token cls token(1 * 768),这个token是一个可以学习的特征,和图像的特征有相同的维度768。因此最后进入Transformer的整体序列长度是197 * 768。我们最终会将cls token当成整个图像的特征,其输出当成是整个transformer模型的输出。这是因为自注意力操作是两两token交互的,最终可以认为这个cls token会包含整个图像的特征。
-
Position Embedding:得到的9宫格本身是有顺序的,但是自注意力操作只是输入序列patch的两两交互,失去了这个顺序信息,因此要加入位置编码postion embedding,这样整体的token就既包含图片块原本有的图像信息,又包含了图像块所在的位置信息。关于位置编码,并不是直接用序列标号1,2,3…197(加上了额外的特殊字符cls token的位置编码)而是我们会有一个表(197 * 768),每一行是一个向量,向量的维度是D=768,这个向量也是可以学的。然后将位置信息加(不是concat) 到所有的token中,得到的序列Embedded Patches维度还是197 * 768。至此,完成所有的图片预处理。
-
Transformer Encoder
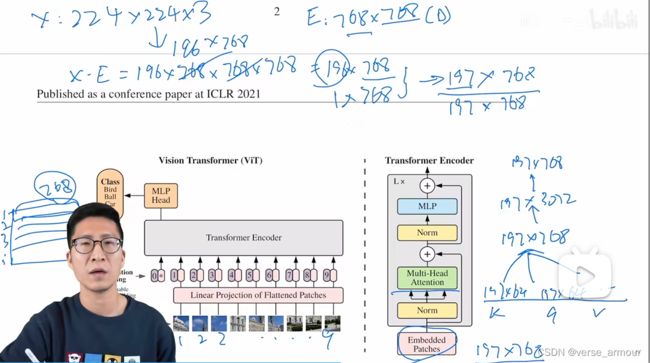
base版的多头注意力(12heads)要注意每个头的维度是197 * 64,将所有的头concat起来就有得到了197 * 768。总结一下transformer block的前向传播过程,进去的是197 * 768,出来的还是197 * 768,这个序列的长度和每个token对应的维度大小都是一样的,所以就可以在一个transformer block上不停地往上叠加transformer block,想加多少加多少。本图上是叠加了L层的transformer encoder。 -
Decoder:MLP Head,即一个分类头。 直接将transformer模型提取的特征通过MLP Head就可以完成图像的分类。
针对cls token的消融实验
注:针对特殊的cls token和位置编码,作者还做了详细的消融实验。因为中间的模型就是一个标准的transformer,因此对于VIT来说,如何对图片进行预处理,如何对图片最后的输出进行后处理是非常关键的。
- 对于cls token,其实我们也可以直接在transformer的输出196 * 768上做globally average-pooling(GAP)后的向量(196 * 1)来作为最后的输出,拿这个向量去做MLP得到最后的分类。
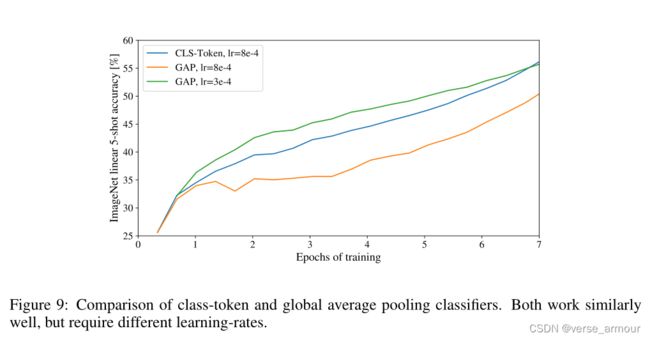
对于位置编码的消融实验
- 1d的位置编码
本文一直使用的位置编码。 - 2d的位置编码(这里不是很理解)

D/2的维度用来描述横坐标,第二个D/2的维度描述纵坐标,两个concat起来又是长度为D的向量,所以不是根号D。
这里的D是维度768,最后是要加到token embedding(197 * 768)上的,所以各用一半来表示横纵坐标。这里的位置编码还是一张表,只不过表中每个向量(1 * 768)的标号变成了(1,1),(1,2),(1,3)…等等具有位置信息的2d编码。无论向量的编码是1d还是2d的都要保证可以和之前patch embedding得到的tensor(197 * 768)可以相加,即保证size相同。如果是2d的位置编码,表中每一行的标号都是2位数来表达(一个横坐标,一个纵坐标),那么相当于这张表的行数翻倍,并且每个横坐标和每个纵坐标所对应的维度是原来的1/2,即D/2。以9个patch为例,示意图如下图所示:


这个D指编码长度,实际表达范围是2^D(假设每位编码都是0/1),那么开根号后,x/y轴分别只需要D/2的编码长度?
- 相对位置编码
可以用每个patch的绝对位置来描述位置信息进行位置编码;也可以用patch之间的相对位置来描述位置信息。消融实验的结果是无所谓。
结论: 位置编码对结果的影响不大
解释: 排列组合patch,比较容易知道相对位置的信息,因此用什么位置编码都无所谓。
公式描述:
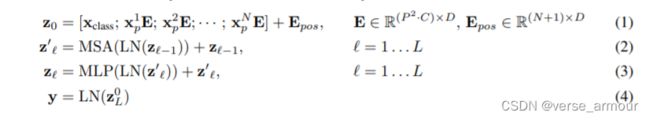
MSA::多头自注意力
MLP:多层感知机,一个分类头
Hybrid Architecture(混合模型)
考虑到卷积神经网络具有较好的归纳偏置,transformer具有较好的全局建模的能力,我们也可以做一个组合模型来综合两种模型的优势,提升最终的性能。
将原来method中将一整张图像分割成若干patch的操作替换成一个卷积网络,例如resnet50,同样也可以得到一个14*14的特征图,拉平之后也是一个长度196的向量。
这其实就是两种不同的图片与处理方式。前者是打成patch,后者是通过CNN。
Experiment
实验结果
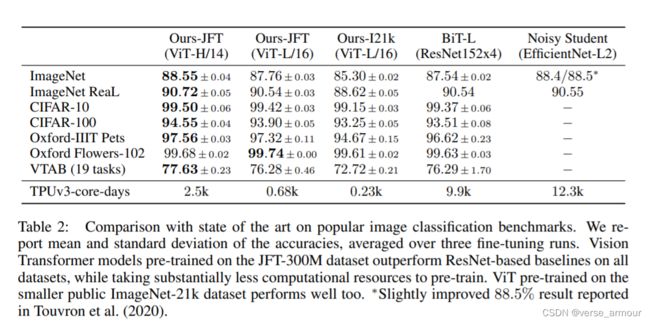
表格的横坐标:Ours-JFT…预训练数据集
表格的纵坐标:ImageNet…迁移学习的数据集
I21k表示ImageNet21k数据集,通常所说的ImageNet指的是ImageNet1k
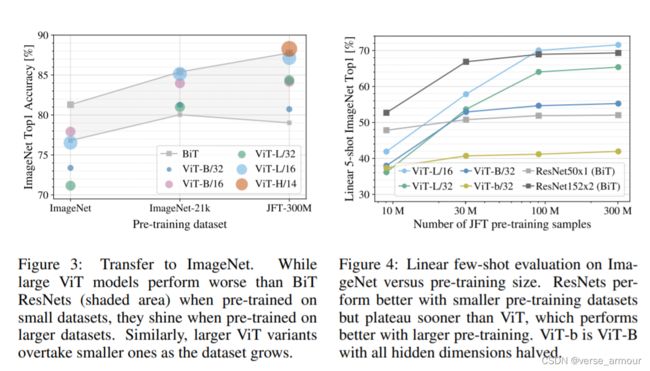
对于figure3,总结一下就是,如果你想用vit,你至少得准备像ImageNet21k这么大的数据集;如果只有很小的数据集,还是用卷积神经网络的性能更好。
对于figure4,Linear few-shot evaluation on ImageNet versus pretraining size。横坐标:pretraining size;纵坐标:Linear few-shot evaluation on ImageNet(在imageNet上的线性少样本评估)。将预训练的模型直接作为一个特征提取器。然后在其他数据集上选取5个样本做evaluation。

对于figure5,vit的预训练比卷积神经网络便宜
同等的计算复杂度下,VIT的效果较好。
INSPECTING VISION TRANSFORMER(可视化vit的工作过程)
(1)patch embedding

Filters of the initial linear embedding of RGB values of ViT-L/32
(2)position embedding

Similarity of position embeddings of ViT-L/32. Tiles show the cosine similarity between the position embedding of the patch with the indicated row and column and the position embeddings of all other patches.
cosine similarity:余弦相似度。用来衡量两个序列之间相似度。 c o s θ = A B ⋅ C D ∣ A B ∣ ∣ C D ∣ cos\theta=\frac{ AB·CD }{|AB||CD|} cosθ=∣AB∣∣CD∣AB⋅CD
关于余弦相似度更多参考:
深度学习-Word Embedding的详细理解(包含one-hot编码和cos余弦相似度)
(3)自注意力是否像我们预期的那样工作:可以模拟长距离的关系

对于ViT-L来说有24层,横坐标网络深度为24;head1,head2…是每一层的transformer block中多头自注意力的头,对于ViT-L来说,一共有16个head,因此上图的每一列有16个点。
对于纵坐标Mean attention distance(pixels),平均注意力的距离。
d a b = l a b ∗ a t t e n t i o n w e i g h t a b d_{ab}=l_{ab}*attentionweight_{ab} dab=lab∗attentionweightab
该指标可以反应该模型是否可以注意到两个距离很远的pixel。
就本图表明,自注意力真的可以在网络的前几层,即网络刚开始的时候注意到两个较远的pixel。而不是像卷积神经网络一样,刚开始第一层的receptive field(感受野)非常小,只能看到附近的pixel,随着网络越来越深网络学到的特征也会越来越high level,即越来越具有语义信息。
(4)自注意力

用输出token的自注意力折射回原来的输入图片。
Globally, we find that the model attends to image regions that are semantically relevant for classification.
模型可以关注到和图像分类有关的那些区域。
自监督的学习方式
。。。
Conclusion
- 实现了纯transformer直接应用到图像上。和Stand-ALone Attention和Axial Attention不一样的是,除了刚开始抽图像块和位置编码的时候,用了图像特有的归纳偏置,没有引入任何图像特有的归纳偏置。
- 未来展望:挖了一个新模型的坑(一般还会有挖一个新问题的坑、新数据集的坑),VIT还可以处理目标检测(VIT-RCNN)和图像分割的任务(SETR)。3个月之后,swin transformer横空出世,将多尺度的设计融合到transformer里,更加适合做视觉的问题了。
未来展望
可以从很多角度来提高、推广ViT
- 任务角度
vit只做了分类,自然地,也可以拿他做检测和分割甚至别的领域的任务。 - 结构角度
可以改一开始的tokenization,也可以改中间的trandformer block。
后来已经有人把self-attention换成MLP,发现还是可以工作得很好。还有人觉得transformer真正work的原因是transformer这个架构而不是某些特殊的算子,把self-attention直接换成了一个池化操作,提出了metaformer,发现用一个不能学习的池化操作也能在视觉领域取得很好的效果 - 目标函数
可以继续沿用有监督,也可以尝试很多不同的自监督 - 多模态
做视频、音频、基于touch的信号