动手学OCR笔记-介绍与实践
参考:https://gitee.com/paddlepaddle/PaddleOCR/tree/release/2.5/notebook/notebook_ch
OCR技术挑战
算法层(应用场景决定):
- 透视变换
- 尺度太小
- 文字弯曲
- 背景干扰
- 字体多变
- 多种语言
- 拍摄模糊
- 光照不足
应用层
- 海量数据要求OCR能够实时处理
- 端侧应用要求OCR模型足够轻量,识别速度足够快
OCR前沿算法
文本检测、文本识别、端到端文本识别、文档分析等等。
文本检测
文本检测的任务是定位出输入图像中的文字区域。
一类方法将文本检测视为目标检测中的一个特定场景,基于通用目标检测算法进行改进适配,
另一类是专用于文本检测的算法
目前较为流行的文本检测算法可以大致分为基于回归和基于分割的两大类文本检测算法,也有一些算法将二者相结合。
- 基于回归的算法借鉴通用物体检测算法,通过设定anchor回归检测框,或者直接做像素回归,这类方法对规则形状文本检测效果较好,但是对不规则形状的文本检测效果会相对差一些,比如CTPN[3]对水平文本的检测效果较好,但对倾斜、弯曲文本的检测效果较差,SegLink[8]对长文本比较好,但对分布稀疏的文本效果较差;
- 基于分割的算法引入了Mask-RCNN[9],这类算法在各种场景、对各种形状文本的检测效果都可以达到一个更高的水平,但缺点就是后处理一般会比较复杂,因此常常存在速度问题,并且无法解决重叠文本的检测问题

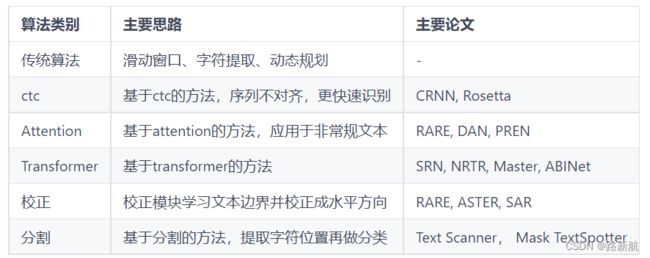
文本识别
文本识别的任务是识别出图像中的文字内容,一般输入来自于文本检测得到的文本框截取出的图像文字区域。
文本识别一般可以根据待识别文本形状分为规则文本识别和不规则文本识别两大类。
规则文本识别的算法根据解码方式的不同可以大致分为基于CTC和Sequence2Sequence两种,将网络学习到的序列特征 转化为 最终的识别结果 的处理方式不同。

文档结构化识别
OCR结果+后处理是一种常用的结构化方案,但流程往往比较复杂,并且后处理需要精细设计,泛化性也比较差。在OCR技术逐渐成熟、结构化信息抽取需求日益旺盛的背景下,版面分析、表格识别、关键信息提取等关于智能文档分析的各种技术受到了越来越多的关注和研究。
版面分析
版面分析(Layout Analysis)主要是对文档图像进行内容分类,类别一般可分为纯文本、标题、表格、图片等。现有方法一般将文档中不同的板式当做不同的目标进行检测或分割。
表格识别
表格识别(Table Recognition)的任务就是将文档里的表格信息进行识别和转换到excel文件中。文本图像中表格种类和样式复杂多样,例如不同的行列合并,不同的内容文本类型等,除此之外文档的样式和拍摄时的光照环境等都为表格识别带来了极大的挑战。这些挑战使得表格识别一直是文档理解领域的研究难点
表格识别的方法种类较为丰富,早期的基于启发式规则的传统算法,;近年来随着深度学习的发展,开始涌现一些基于CNN的表格结构识别算法;此外,随着图神经网络(Graph Neural Network)的兴起,也有一些研究者尝试将图神经网络应用到表格结构识别问题上,基于图神经网络,将表格识别看作图重建问题;基于端到端的方法直接使用网络完成表格结构的HTML表示输出,端到端的方法大多采用Seq2Seq方法来完成表格结构的预测,如一些基于Attention或Transformer的方法,如TableMaster
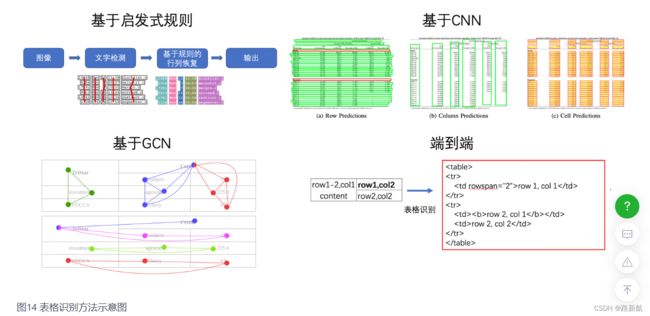
关键信息提取
关键信息提取(Key Information Extraction,KIE)是Document VQA中的一个重要任务,主要从图像中提取所需要的关键信息
KIE通常分为两个子任务进行研究:语义实体识别、关系抽取
一般的KIE方法基于命名实体识别(Named Entity Recognition,NER)来研究,但是这类方法只利用了图像中的文本信息,缺少对视觉和结构信息的使用,因此精度不高。在此基础上,近几年的方法都开始将视觉和结构信息与文本信息融合到一起,按照对多模态信息进行融合时所采用的原理可以将这些方法分为下面四种:
基于Grid的方法
基于Token的方法
基于GCN的方法
基于End to End 的方法
PaddleOCR介绍
PP-OCR与PP-Structrue
用的典型的两阶段OCR算法,即检测模型+识别模型的组成方式,具体的算法框架如下:

可以看到,除输入输出外,PP-OCR核心框架包含了3个模块,分别是:文本检测模块、检测框矫正模块、文本识别模块。
- 文本检测模块:核心是一个基于DB检测算法训练的文本检测模型,检测出图像中的文字区域;
- 检测框矫正模块:将检测到的文本框输入检测框矫正模块,在这一阶段,将四点表示的文本框矫正为矩形框,方便后续进行文本识别,另一方面会进行文本方向判断和校正,例如如果判断文本行是倒立的情况,则会进行转正,该功能通过训练一个文本方向分类器实现;
- 文本识别模块:最后文本识别模块对矫正后的检测框进行文本识别,得到每个文本框内的文字内容,PP-OCR中使用的经典文本识别算法CRNN。
PP-OCR模型分为mobile版(轻量版)和server版(通用版)。PP-OCRv2保持了PP-OCR的整体框架,主要做了效果上的进一步策略优化。
PP-Structure文档分析模型
PP-Structure支持版面分析(layout analysis)、表格识别(table recognition)、文档视觉问答(DocVQA)三种子任务。
PP-Structure核心功能点如下:
- 支持对图片形式的文档进行版面分析,可以划分文字、标题、表格、图片以及列表5类区域(与Layout-Parser联合使用)
- 支持文字、标题、图片以及列表区域提取为文字字段(与PP-OCR联合使用)
- 支持表格区域进行结构化分析,最终结果输出Excel文件
- 支持Python whl包和命令行两种方式,简单易用
- 支持版面分析和表格结构化两类任务自定义训练
- 支持VQA任务-SER和RE
部署
飞桨支持全流程、全场景推理部署,模型来源主要分为三种,第一种使用PaddlePaddle API构建网络结构进行训练所得,第二种是基于飞桨套件系列,飞桨套件提供了丰富的模型库、简洁易用的API,具备开箱即用,包括视觉模型库PaddleCV、智能语音库PaddleSpeech以及自然语言处理库PaddleNLP等,第三种采用X2Paddle工具从第三方框架(PyTorh、ONNX、TensorFlow等)产出的模型。
飞桨模型可以选用PaddleSlim工具进行压缩、量化以及蒸馏,支持五种部署方案,分别为服务化Paddle Serving、服务端/云端Paddle Inference、移动端/边缘端Paddle Lite、网页前端Paddle.js, 对于Paddle不支持的硬件,比如MCU、地平线、鲲云等国产芯片,可以借助Paddle2ONNX转化为支持ONNX的第三方框架。
文本检测
文本检测任务是找出图像或视频中的文字位置。不同于目标检测任务,目标检测不仅要解决定位问题,还要解决目标分类问题。
文本在图像中的表现形式可以视为一种‘目标’,通用的目标检测的方法也适用于文本检测。
近些年来基于深度学习的文本检测算法层出不穷,这些方法大致可以分为两类:
基于回归的文本检测方法
基于分割的文本检测方法

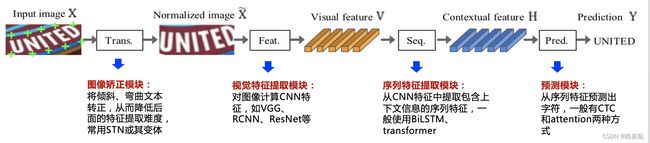
文本识别
本识别方法中,任务分为3个步骤,即图像预处理、字符分割和字符识别。
参考:
PP-Structure Quick Start
识别图片中的表格数据(opencv 和pyteressact)
paddle ocr 实践
安装
参考:https://blog.csdn.net/Jia_Feng_/article/details/116670461
pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
gitlab下载源码
如果执行ocr = PaddleOCR(use_angle_cls=True, lang="ch")报错
Initializing libiomp5md.dll
识别文字
from paddleocr import PaddleOCR, draw_ocr
ocr = PaddleOCR(use_angle_cls=True, lang="ch")
# 输入待识别图片路径
img_path = r"image.png"
# 输出结果保存路径
result = ocr.ocr(img_path, cls=True)
for line in result:
print(line[1][0])
识别结构化文本
命令行
paddleocr
--image_dir ./input
--lang ch
--use_gpu false
--type structure
--layout=='true'
--output ./output
python编码
import os
import cv2
from paddleocr import PPStructure,draw_structure_result,save_structure_res
save_folder = './output'
img_path = 'input/image.png'
img_path = 'input/fapiao.jpg'
def ocr_recoginze():
table_engine = PPStructure(layout=False, show_log=True)
img = cv2.imread(img_path)
result = table_engine(img)
save_structure_res(result, save_folder,
os.path.basename(img_path).split('.')[0])
for line in result:
line.pop('img')
print(line)
# from PIL import Image
#
# font_path = 'PaddleOCR-release-2.5/doc/fonts/simfang.ttf' # PaddleOCR下提供字体包
# image = Image.open(img_path).convert('RGB')
# im_show = draw_structure_result(image, result,font_path=font_path)
# im_show = Image.fromarray(im_show)
# im_show.save('result.jpg')
ocr_recoginze()
paddle
paddle波士顿放假预测
参考 https://www.paddlepaddle.org.cn/tutorials/projectdetail/4309126
import paddle
from paddleocr import PaddleOCR,draw_ocr
#加载飞桨、NumPy和相关类库
import paddle
from paddle.nn import Linear
import paddle.nn.functional as F
import numpy as np
import os
import random
def load_data():
# 从文件导入数据
datafile = './work/housing.data'
datafile = 'G:/数据挖掘/算法书/datamining/2020A/datasets/Boston/housing.data'
data = np.fromfile(datafile, sep=' ', dtype=np.float32)
# 每条数据包括14项,其中前面13项是影响因素,第14项是相应的房屋价格中位数
feature_names = ['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', \
'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV']
feature_num = len(feature_names)
# 将原始数据进行Reshape,变成[N, 14]这样的形状
data = data.reshape([data.shape[0] // feature_num, feature_num])
# 将原数据集拆分成训练集和测试集
# 这里使用80%的数据做训练,20%的数据做测试
# 测试集和训练集必须是没有交集的
ratio = 0.8
offset = int(data.shape[0] * ratio)
training_data = data[:offset]
# 计算train数据集的最大值,最小值
maximums, minimums = training_data.max(axis=0), training_data.min(axis=0)
# 记录数据的归一化参数,在预测时对数据做归一化
global max_values
global min_values
max_values = maximums
min_values = minimums
# 对数据进行归一化处理
for i in range(feature_num):
data[:, i] = (data[:, i] - min_values[i]) / (maximums[i] - minimums[i])
# 训练集和测试集的划分比例
training_data = data[:offset]
test_data = data[offset:]
return training_data, test_data
class Regressor(paddle.nn.Layer):
# self代表类的实例自身
def __init__(self):
# 初始化父类中的一些参数
super(Regressor, self).__init__()
# 定义一层全连接层,输入维度是13,输出维度是1
self.fc = Linear(in_features=13, out_features=1)
# 网络的前向计算
def forward(self, inputs):
x = self.fc(inputs)
return x
def load_one_example():
# 从上边已加载的测试集中,随机选择一条作为测试数据
idx = np.random.randint(0, test_data.shape[0])
idx = -10
one_data, label = test_data[idx, :-1], test_data[idx, -1]
# 修改该条数据shape为[1,13]
one_data = one_data.reshape([1,-1])
return one_data, label
if __name__ == '__main__':
# paddle.utils.run_check()
# 验证数据集读取程序的正确性
training_data, test_data = load_data()
print(training_data.shape)
print(training_data[1, :])
# 声明定义好的线性回归模型
model = Regressor()
# 开启模型训练模式
model.train()
# 加载数据
training_data, test_data = load_data()
# 定义优化算法,使用随机梯度下降SGD
# 学习率设置为0.01
opt = paddle.optimizer.SGD(learning_rate=0.01, parameters=model.parameters())
EPOCH_NUM = 10 # 设置外层循环次数
BATCH_SIZE = 10 # 设置batch大小
# 定义外层循环
for epoch_id in range(EPOCH_NUM):
# 在每轮迭代开始之前,将训练数据的顺序随机的打乱
np.random.shuffle(training_data)
# 将训练数据进行拆分,每个batch包含10条数据
mini_batches = [training_data[k:k + BATCH_SIZE] for k in range(0, len(training_data), BATCH_SIZE)]
# 定义内层循环
for iter_id, mini_batch in enumerate(mini_batches):
x = np.array(mini_batch[:, :-1]) # 获得当前批次训练数据
y = np.array(mini_batch[:, -1:]) # 获得当前批次训练标签(真实房价)
# 将numpy数据转为飞桨动态图tensor的格式
house_features = paddle.to_tensor(x)
prices = paddle.to_tensor(y)
# 前向计算
predicts = model(house_features)
# 计算损失
loss = F.square_error_cost(predicts, label=prices)
avg_loss = paddle.mean(loss)
if iter_id % 20 == 0:
print("epoch: {}, iter: {}, loss is: {}".format(epoch_id, iter_id, avg_loss.numpy()))
# 反向传播,计算每层参数的梯度值
avg_loss.backward()
# 更新参数,根据设置好的学习率迭代一步
opt.step()
# 清空梯度变量,以备下一轮计算
opt.clear_grad()
# 保存模型参数,文件名为LR_model.pdparams
paddle.save(model.state_dict(), 'LR_model.pdparams')
print("模型保存成功,模型参数保存在LR_model.pdparams中")
# 参数为保存模型参数的文件地址
model_dict = paddle.load('LR_model.pdparams')
model.load_dict(model_dict)
model.eval()
# 参数为数据集的文件地址
one_data, label = load_one_example()
# 将数据转为动态图的variable格式
one_data = paddle.to_tensor(one_data)
predict = model(one_data)
# 对结果做反归一化处理
predict = predict * (max_values[-1] - min_values[-1]) + min_values[-1]
# 对label数据做反归一化处理
label = label * (max_values[-1] - min_values[-1]) + min_values[-1]
print("Inference result is {}, the corresponding label is {}".format(predict.numpy(), label))