学习笔记:Gan-DCGan-WGan-SuperResolutionGan发展生成对抗网络
https://www.cnblogs.com/frombeijingwithlove/
更过模型可以查看Gan Zoo(Ian Goodfellow)
loss升级:DCGAN–> WGan–>Wgan-DP
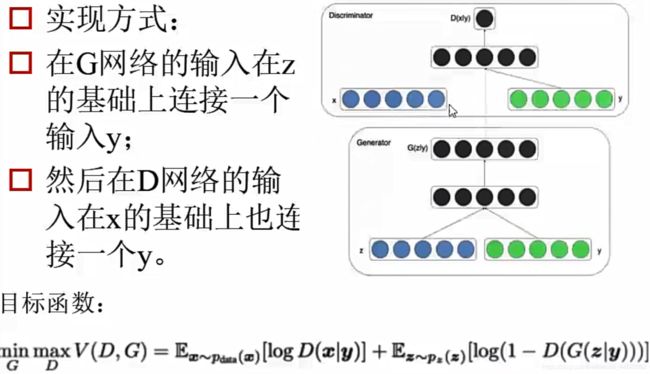
网络结构升级:有标签指定生成数据类型CGan条件Gan
生成离散数据:Seq-Gan
图像翻译:pix2pix cycleGan,starGan
可解释的生成模型:InfoGan
判别器多分类(不仅是二分类):AC_GAN Auxiliary Classifier Gan
不同于RL解决生成建模问题的一种方式(RL是特殊的GAN)
文章目录
-
- 不同于RL解决生成建模问题的一种方式(RL是特殊的GAN)
- 意义:造出新的类似但不是原样本的数据(风格变换、白天变黑夜)
- 关键点:分类能力提高,生成能力提高,博弈,直到纳什均衡(验钞机变强然后让生成器后来者居上)
-
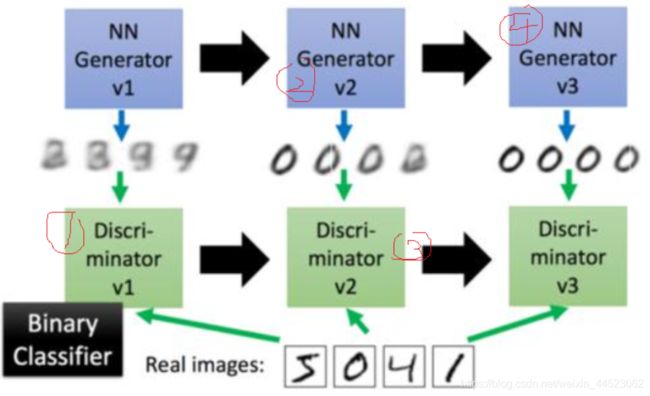
- 1 G1不变训练D1:结合图理解
-
-
-
- 第一代**v1-G**随机生成高斯噪声的图像,训练第一代**v1-D** 直到识别出真假(二分类器交叉熵,训练loss逼近标签真值01或10)
-
-
- 2 D1不变训练G2:
-
-
-
- 训练**v2-G**生成器训练使生成的更接近真的,从而使v1-D无法分别(即无法输出接近01真假标签,而是0.5左右无法判断的标签)
-
- 看G的更新让D(G)变大:G_loss=log(1-D(G))是减函数, 所以是min目标
- 看D的更新让D(G)变小:D_loss是增函数,D_loss-former=-log(Dx)增,later是减
-
- KL散度相对熵,但不是距离因为Dkl(p-q)不等于Dkl(q-p)
- JS散度,优化KL,使距离对称且值域(0,1)
- 1 训练图示过程(黑:真样本分布始终不变)
- 难点:收敛问题;模型奔溃D逼迫G直接生成原型;
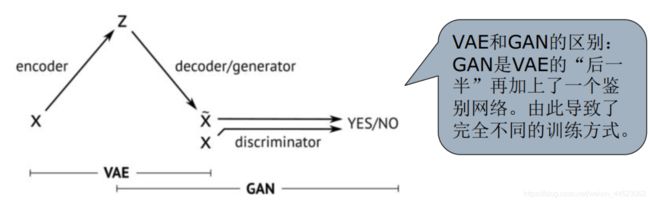
- 一、GAN模型:2015随机数据用全连接对抗生成新数据 VAE(variational Autoencoders)
- 二、DCGAN(2016年DeepConv卷积网路)
-
- 为gan训练提供了一个适合的网络结构;表明生成的特征具有向量的计算特性
- 数据集LSUN,仅支持低分辨率图片,无法捕捉物体结构特性
- 三、CGAN(条件Gan)给定的语义z +条件y向量(假设语义信息是‘1’)用卷积网络生成新数据condition
- 四、Wasserstein GAN (WGAN)针对gan分析过一篇论文,然后提出Wgan(可以是fn或cnn)
-
- 1 特点
- 2 解决的问题:无法平衡,逼死生成器拿真实样本冒充
- 标准 js 散度 kl散度对称性不好,式2解决逼死G问题
-
- 结论,无崩溃
- 五、Super-Resolution GAN(G(低分辨率)-->生成高分辨率图片)Lsr损失函数
-
- 生成网络结构
- 判别网络的结构
- 3 损失函数
- 六 CycleGan 输入图像无需配对
- 七 pix2pix Gan 输入图像最好配对(图像增强,去马赛克)
- 八 styleGan与风格迁移网络(风格损失和内容损失,直接训练的是随机图像的分布)
意义:造出新的类似但不是原样本的数据(风格变换、白天变黑夜)
关键点:分类能力提高,生成能力提高,博弈,直到纳什均衡(验钞机变强然后让生成器后来者居上)
1 G1不变训练D1:结合图理解
第一代v1-G随机生成高斯噪声的图像,训练第一代v1-D 直到识别出真假(二分类器交叉熵,训练loss逼近标签真值01或10)
2 D1不变训练G2:
训练v2-G生成器训练使生成的更接近真的,从而使v1-D无法分别(即无法输出接近01真假标签,而是0.5左右无法判断的标签)
以此类推(G2不变训练D2):训练D2分类G2,直到识别G2,提高分类能力
价值函数合并:交替固定(先固定G提升D)
训练G的时候关注后者损失,训练D的时候两者都要看
先提升D能力,maxD优化梯度上升优化D,后提升G,minG梯度下降优化G
![]()
在这里插入代码片
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
# torch.manual_seed(1) # reproducible
# np.random.seed(1)
# Hyper Parameters
BATCH_SIZE = 64
LR_G = 0.0001 # learning rate for generator
LR_D = 0.0001 # learning rate for discriminator
N_IDEAS = 5 # think of this as number of ideas for generating an art work (Generator)
ART_COMPONENTS = 15 # it could be total point G can draw in the canvas
PAINT_POINTS = np.vstack([np.linspace(-1, 1, ART_COMPONENTS) for _ in range(BATCH_SIZE)])
def artist_works(): # painting from the famous artist (real target)
a = np.random.uniform(1, 2, size=BATCH_SIZE)[:, np.newaxis]
paintings = a * np.power(PAINT_POINTS, 2) + (a-1)
paintings = torch.from_numpy(paintings).float()
return paintings
G = nn.Sequential( # Generator
nn.Linear(N_IDEAS, 128), # random ideas (could from normal distribution)
nn.ReLU(),
nn.Linear(128, ART_COMPONENTS), # making a painting from these random ideas
)
D = nn.Sequential( # Discriminator
nn.Linear(ART_COMPONENTS, 128), # receive art work either from the famous artist or a newbie like G
nn.ReLU(),
nn.Linear(128, 1),
nn.Sigmoid(), # tell the probability that the art work is made by artist
)
opt_D = torch.optim.Adam(D.parameters(), lr=LR_D)
opt_G = torch.optim.Adam(G.parameters(), lr=LR_G)
plt.ion() # something about continuous plotting
for step in range(10000):
artist_paintings = artist_works() # real painting from artist
G_ideas = torch.randn(BATCH_SIZE, N_IDEAS) # random ideas
G_paintings = G(G_ideas) # fake painting from G (random ideas)
##这里是全算法的唯一核心公式D要将作家判断成1,将D(G)=0; 但是G
prob_artist0 = D(artist_paintings) # D try to increase this prob
prob_artist1 = D(G_paintings) # G try to reduce this prob
# 看G的更新:一开始D是强壮的,计算出D(G)=假的=0,得到log1(1-D(G))=log1=0。但是G去七篇D使D(G)变大到0.5(假设),从而使D_loss=log(o.5)比原来小了。
# 看D的更新,一般情况是D(G)=0.5导致D_loss=-log0.5-log0.5.但是D目的是D(G)=0,进一步D_loss变大=0(分析D(art)=1,D(gan)=0,所以log(D(art)=1)=0, log(1-D(G))=log(1)=0,。。。)
D_loss = - torch.mean(torch.log(prob_artist0)) - torch.log(1. - prob_artist1) #max loss
G_loss = torch.mean(torch.log(1. - prob_artist1)) #min loss,
opt_D.zero_grad()
D_loss.backward(retain_graph=True) # reusing computational graph
opt_D.step()
opt_G.zero_grad()
G_loss.backward()
opt_G.step()
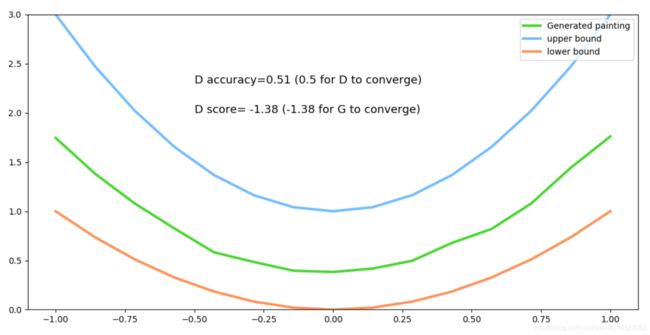
if step % 50 == 0: # plotting
plt.cla()
plt.plot(PAINT_POINTS[0], G_paintings.data.numpy()[0], c='#4AD631', lw=3, label='Generated painting',)
plt.plot(PAINT_POINTS[0], 2 * np.power(PAINT_POINTS[0], 2) + 1, c='#74BCFF', lw=3, label='upper bound')
plt.plot(PAINT_POINTS[0], 1 * np.power(PAINT_POINTS[0], 2) + 0, c='#FF9359', lw=3, label='lower bound')
plt.text(-.5, 2.3, 'D accuracy=%.2f (0.5 for D to converge)' % prob_artist0.data.numpy().mean(), fontdict={'size': 13})
plt.text(-.5, 2, 'D score= %.2f (-1.38 for G to converge)' % -D_loss.data.numpy(), fontdict={'size': 13})
plt.ylim((0, 3));plt.legend(loc='upper right', fontsize=10);plt.draw();plt.pause(0.01)
plt.ioff()
plt.show()
score是loss,accuracy是D判断画家的得分
看G的更新让D(G)变大:G_loss=log(1-D(G))是减函数, 所以是min目标
一开始D是强壮的,计算出D(G)=假的=0,得到log1(1-D(G))=log1=0。但是G为了欺骗D使D(G)变大到0.5(假设),从而使D_loss=log(o.5)比原来小了。
看D的更新让D(G)变小:D_loss是增函数,D_loss-former=-log(Dx)增,later是减
一般情况是D(G)=0.5导致D_loss=-log0.5-log0.5.但是D目的是D(G)=0,进一步D_loss变大=0(分析D(art)=1,D(gan)=0,所以log(D(art)=1)=0, log(1-D(G))=log(1)=0,。。。)
交叉熵loss(二元)

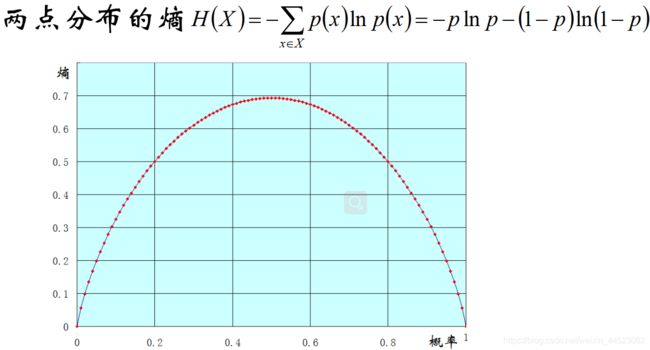
熵是表示信息的混乱程度

KL散度相对熵,但不是距离因为Dkl(p-q)不等于Dkl(q-p)
JS散度,优化KL,使距离对称且值域(0,1)
损失函数分开分析:设伪造的是0,后者是提升G欺骗D的损失,minG梯度下降
信息量 − l o g 2 P ( x ) -log_2P(x) −log2P(x)的期望就是熵: E l o g ( P ( x ) ) = − 1 N ∑ i = 0 N l o g ( P x ) Elog(P(x)) =- \frac{1}{N}\sum_{i=0}^Nlog(P_x) Elog(P(x))=−N1∑i=0Nlog(Px)

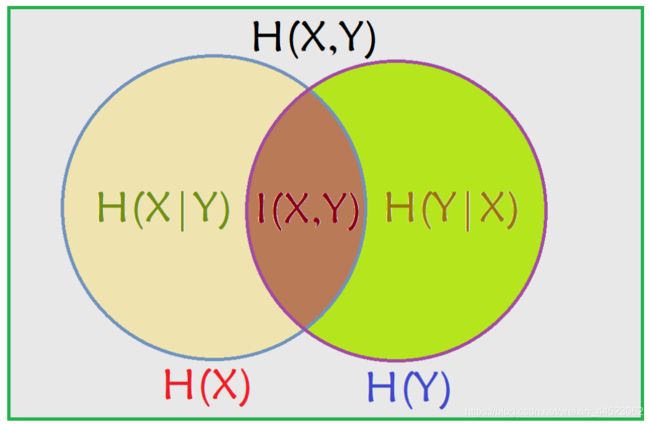
联合熵 H ( x , y ) H(x,y) H(x,y)
条件熵 H ( x , y ) − H ( x ) = H ( y ∣ x ) ) H(x,y)-H(x)=H(y|x) ) H(x,y)−H(x)=H(y∣x))
互信息: I ( x , y ) = H ( y ) − H ( y ∣ x ) I(x,y)=H(y)-H(y|x) I(x,y)=H(y)−H(y∣x),带入替换条件熵得到
I ( x , y ) = H ( x ) + H ( x ) − H ( x , y ) I(x,y)=H(x)+H(x)-H(x,y) I(x,y)=H(x)+H(x)−H(x,y)
Veen图
交叉熵就是相对熵:两个分布的距离Kullback-Leible(KL散度)
概率=频率(从分布中得出概率)
GAN中D的loss就是交叉熵

Wgan 公式进化

1 训练图示过程(黑:真样本分布始终不变)
- 1、如a图,先训练D能分别真假(黑绿),使D从a变到b,提高了分类能力
- 2、如c图,生成器绿色提高创作能力接近黑色,蓝色分别器判断误差较大(无法正确判断)
- 3、直到均衡,G相真的,D分别不出真假
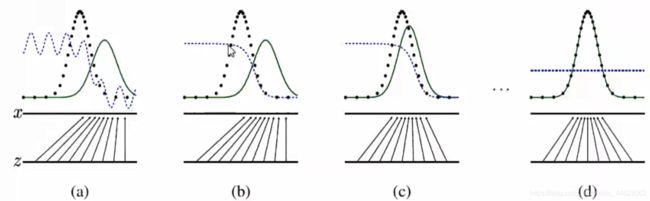
难点:收敛问题;模型奔溃D逼迫G直接生成原型;
- 训练困难:收敛问题,很难达到纳什均衡点
- 模型崩溃:G造出了和真实样本一摸一样,失去了创造能力
一、GAN模型:2015随机数据用全连接对抗生成新数据 VAE(variational Autoencoders)
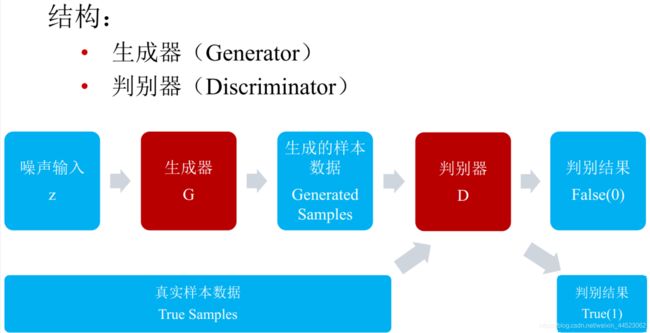
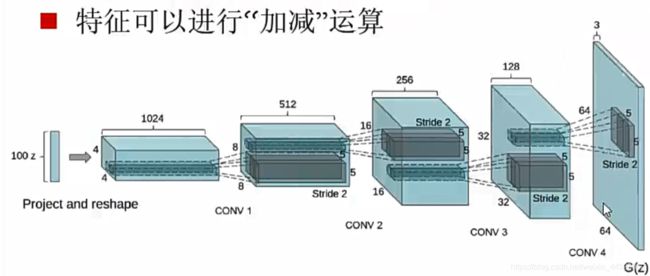
二、DCGAN(2016年DeepConv卷积网路)
为gan训练提供了一个适合的网络结构;表明生成的特征具有向量的计算特性
unsurpervised represententation learning with Deep Convolutional Generative anversarial Networks Alec Radford


数据集LSUN,仅支持低分辨率图片,无法捕捉物体结构特性
白噪声z向量 可加减计算,z是VAE编码解码中间提取的语义向量(RME区别于受限玻尔兹曼机,一开始是hinton为了预训练卷积神经网络的)



三、CGAN(条件Gan)给定的语义z +条件y向量(假设语义信息是‘1’)用卷积网络生成新数据condition
一开始Gan都是随机数据
四、Wasserstein GAN (WGAN)针对gan分析过一篇论文,然后提出Wgan(可以是fn或cnn)
1 特点
- 1 判别器最后一层去掉sigmoid
- 2、loss中去掉llog
- 3、每次更新判别器的参数之后,把他们的绝对值截断到不超过一个固定常数C
- 4、不要基于动量的优化算法(momentum、Adam),推荐使用RMSProp,SGD
2 解决的问题:无法平衡,逼死生成器拿真实样本冒充
- 1、彻底解决了训练不稳定,不需要再小心平衡GD的训练程度
- 2、基本解决了collapse崩溃问题,使之干脆直接输出真实样本的问题
- 3、判别标准推土机距离:训练过程中终于有了一个像交叉熵、准确率这样的数值来指示训练的进程,这个数值越小代表GAN训练的越好。代表生成器产生的质量越高(以前看不到平衡过程)
- 4、以上好处–》导致不需要精心设计网络架构,最简单的多层全连接网络就可以做到
标准 js 散度 kl散度对称性不好,式2解决逼死G问题

推土机距离:Earth-Mover====》 wasserstein距离


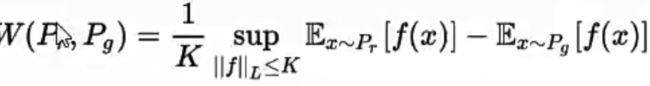
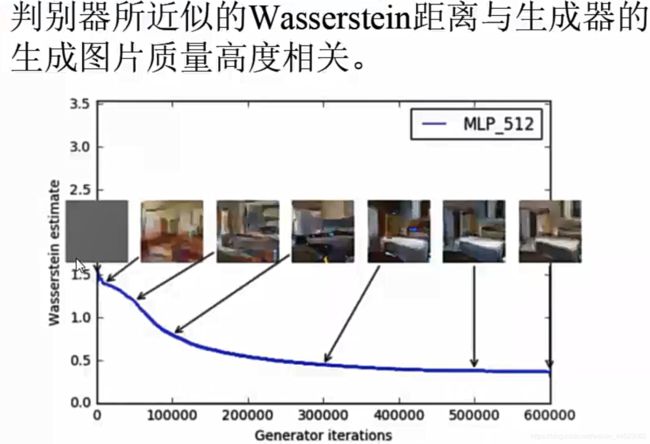
结论,无崩溃
五、Super-Resolution GAN(G(低分辨率)–>生成高分辨率图片)Lsr损失函数
生成网络结构
判别网络的结构
3 损失函数

六 CycleGan 输入图像无需配对
七 pix2pix Gan 输入图像最好配对(图像增强,去马赛克)
八 styleGan与风格迁移网络(风格损失和内容损失,直接训练的是随机图像的分布)
