深度学习数据集制作_深度学习应用于Tabular数据的经验

导语: 在2019年4月份的时候,我们上线过一版利用MLP训练的风险模型,一年之后来看其AB-Test的表现,应该说达到了当初的目标,从当初的研究性质到线上使用遇到的问题,以及后来的持续迭代,与KDD2019年Airbnb发表的论文 Applying Deep Learning To Airbnb Search中讲述其心路历程有点类似,本文将结合原始论文,同时夹带点不那么干的私货,算是对很久之前的工作的一个点回忆吧,现在就让我们一起来看看训练一个表格数据的深度模型会遇到的问题,以及各种奇奇怪怪的网络结构设计是否真的有必要。
本文主要讲解Airbnb的论文,并在其中的一些点穿插着本人在其他项目中的实践经验,以及在其他地方看到过的相关内容一并作为补充,至于这些补充的内容能否在其他数据中有效,需要读者自行实践。本文的主要内容:
- 网络结构上的教训-Airbnb搜索模型从GBDT到深度神经网络到历程
- 套用其他领域的模型的教训-Airbnb中失败的模型尝试
- 直接利用GBDT的特征训练神经网络的教训-深度神经网络的特征工程-特征归一化,特征分布
- 深度神经网络中特征重要性的评估
网络结构上的教训
对于Airbnb文章中的内容,主要是关于其从GBDT转到深度神经网络中遇到的坑,学习到的宝贵经验,没有花大量的笔墨去写其如何设计网络结构,提出新的优化目标函数,面向的受众是对那些已经在使用机器学习模型,并且模型性能达到了一定的瓶颈,在思考应用深度学习的模型落地的团队。 论文中以搜索系统中的模型为例,具体一点就是根据用户的搜索词(query), 生成用户最有可能下单的房屋的列表(listing, 标的),用户根据推荐列表完成一系列的浏览行为,最后下单,或者流失。跟很多模型的迭代历程相似,在项目冷启动的时候,都是利用人工规则对标的进行打分(manually crafted scoring function)生成排序列表。当产品稳定,积累到一定的正负样本,就可以利用树模型GBDT以及大量的特征工程训练机器学习模型了,然后是各种线上AB-TEST,不断地迭代,最后达到模型性能的平台期,Airbnb也是这样的套路,在这个时候,就想到了深度学习的灵丹妙药,毕竟从2012年开始深度学习在CV上的巨大成功,让大家又了新的动力,从下图可以看到其深度模型的迭代时间点,
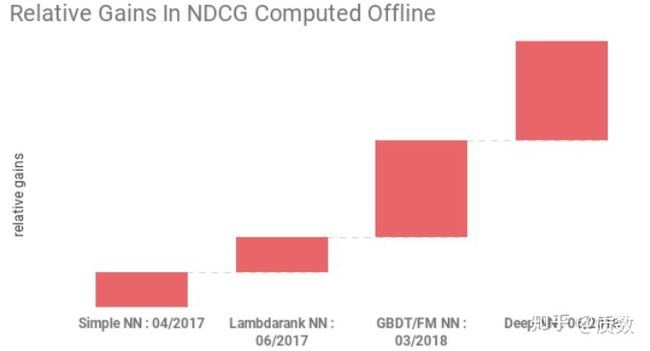
- 2017年4月,上线Simple NN模型,其网络结构很简单,利用与GBDT相同的特征,优化相同的目标函数,整个网络结构只有一个隐含层,其中为32个神经元+ReLU激活函数,其意义在于线上可以跑通整个流程,满足线上各种性能要求;
- 2017年6月,推出Lamdarank NN, 该网络结构结合了Lamdarank模型中思想,利用神经网络直接优化NDCG评估指标,相比于Simple NN, 在两个方面做出创新,从pointwise的训练集到pairwise方式,构建
, 对样本加权等等;
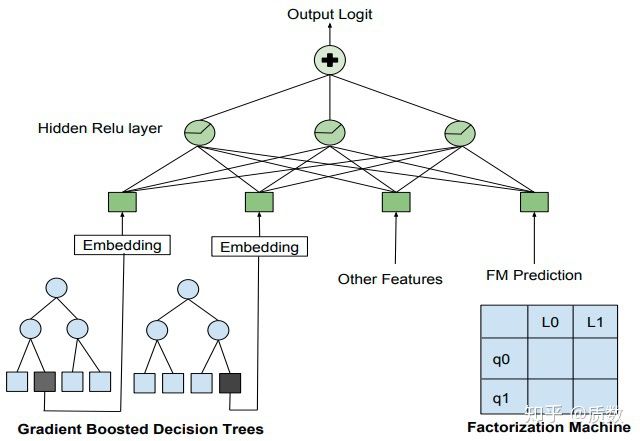
- 2018年3月,在研发的模型为GBDT + FM混合结构的神经网络模型,其网络结构如下图所示,网络的输入部分包含两个部分,第一部分是利用GBDT叶子节点作为类别型特征,学习其Embedding向量作为网络的输入,另外一部分是FM的输出结果,有这两部分构成了整个网络输入。因此,该网络结构结合了三种模型GBDT+FM+NN,树模型,广义线性模型,神经网络齐上阵,虽然该模型效果具有一定的优势,但是生成的排序列表跟其他模型很不一样;
- 2018年6月,鉴于GBDT + FM结构的神经网络结构过于复杂,最终为了减少模型的复杂性,化繁就简,仅仅将训练集扩大10倍,同时增加Simple NN的隐含层到2层,整个全连接网络结构为:
195-> 127 -> 83 -> 1,隐含层加入ReLU激活函数,模型的输入特征主要是价格,历史购买次数,以及其他子模型的模型分等,没有太多花哨的东西, 从增加训练样本的对比试验中,发现将样本增加到170W时,训练集和测试集的之间在NDCG评估指标上已经很接近了;
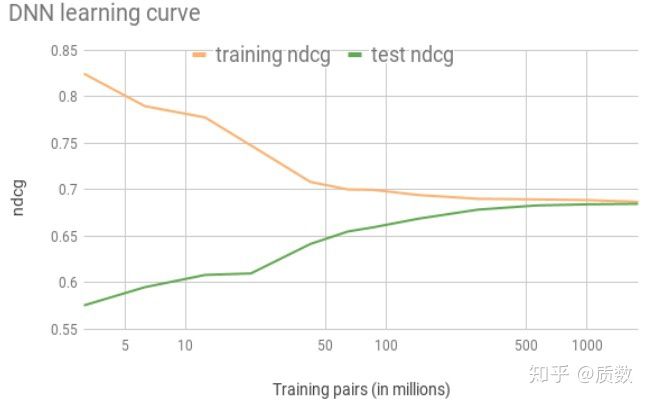
作者们开始的踏入深度神经网络大门的时候,没有听信AK(Andrej Karpathy)大佬总结的炼丹秘诀A Recipe for Training Neural Networks(http://karpathy.github.io/2019/04/25/recipe/ ), Don't be a hero, 一步步设计出越来越复杂的网络结构,而且是自定义的网络结构,最终被模型的复杂性所拖累,而仅仅将数据量增大,稍微增加网络的深度就能达到更好的结果。
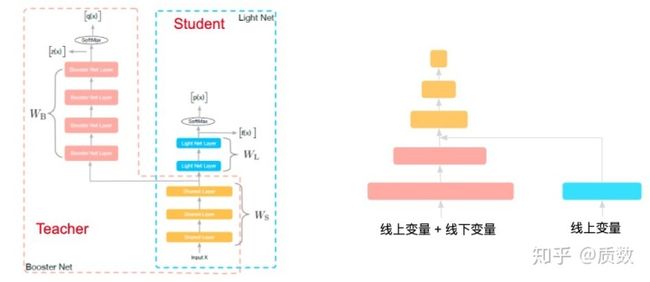
关于网络结构的设计,本人曾经也试图从其他优秀的结构中改过几个,部分是有点效果,如下图所示:
- 借鉴阿里的Rocket Launching(https://arxiv.org/abs/1708.04106),利用更多的线下特征训练更强的线上模型(上线线上变量周期长的顾虑),在线下可以开发很多变量,对于线上只需要利用部分即可
- 奇奇怪怪的迁移学习网络
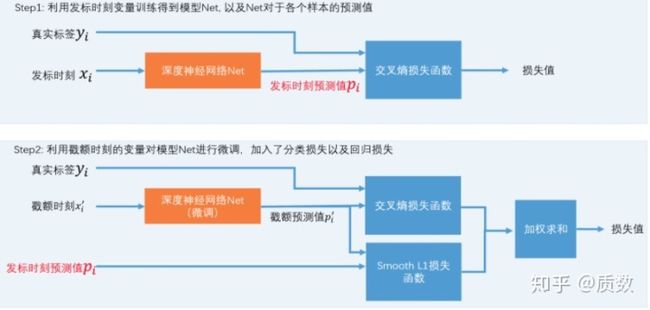
- 对缺失值设计专门的结构,对于缺失与否学习不同的参数,当特征X发生缺失,学习参数
,当特征不缺失,学习参数
, 参考美团公开文章
套用其他领域的模型的教训
Airbnb中论文中还提到了他们失败的模型,在论文中看到这样的经验真是难能可贵,现在展现在我们面前那么多的SOTA模型都是其光鲜的一面,其背后作者们尝试的失败方案,只有当事人才知道,而那些失败的方案可能很多人都要自己走一遍,才知道原来问题那么多。在文中,作者展示了两种他们失败模型,即借鉴其他领域的一些方法,应用到其业务场景中并不那么有效,第一个是 ListingID的Embedding,第二是多任务学习。
ListingID Embedding上的失败
在深度神经网络中,ID类型的变量通过Embedding向量的形式,极大的展现了其无须手动特征工程的能力,如NLP中的word2vec, 推荐系统的大量使用的物体的ID的Embedding向量等,这些成功的应用场景使得Airbnb的工程师按奈不住要亲自动手的冲动,也为其listingID学习Embedding向量,然而各种尝试下来,都是overfitting的结果,在训练集中NDCG评估指标特别好看,在测试集中一塌糊涂,对比不加入的baseline还差, 如下图所示;
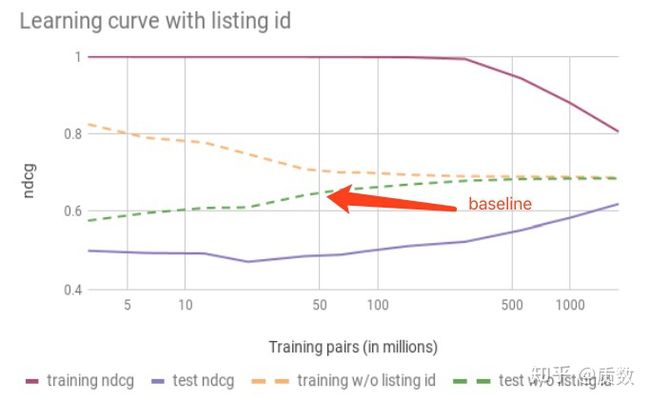
作者们给出了原因(有部分是我自己瞎编的):
- Embedding向量学习需要足够的数量,同时ID还需要满足一定的共现的特性,如果事物之间没有天然的共现关系,利用Embedding向量可能会出现问题,如自然语言中词汇与词汇之间是存在某种隐含的上下文关系的,而物品ID之间的关系可能会弱一些,有时只有很少一部分数据才有这样的模式;
- 在Airbnb中一个listingID一年最大的极限出现在订单序列列表的数目为365,即每天都被预定出去,然而在平台上大部分能够成交的lisingID是极少的,同时有些listingID还有因为季节性的影响因素,可能只出现在某个时间段,这些就使得共线性的问题减弱,数据的稀疏性使得训练的Embedding向量泛化能力不强;
- 在KDD2018中他们的提出的Embedding技术克服了部分问题,后面有空在去赏析那篇文章,这里先不跑题;在之前的文章中,简单介绍过其中的一个特征编码方式,感兴趣的可以后面再回来看一看;
多任务学习的失败
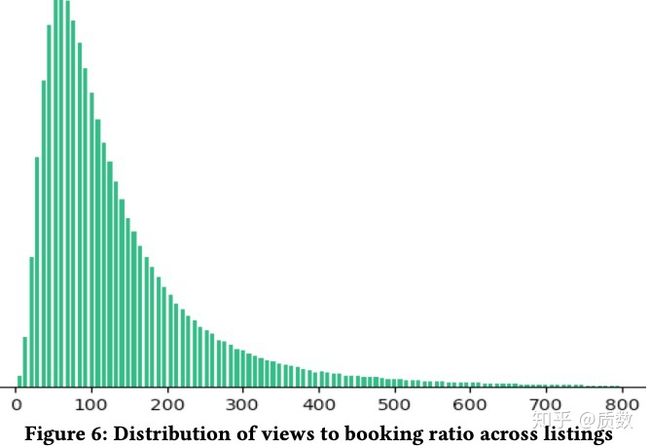
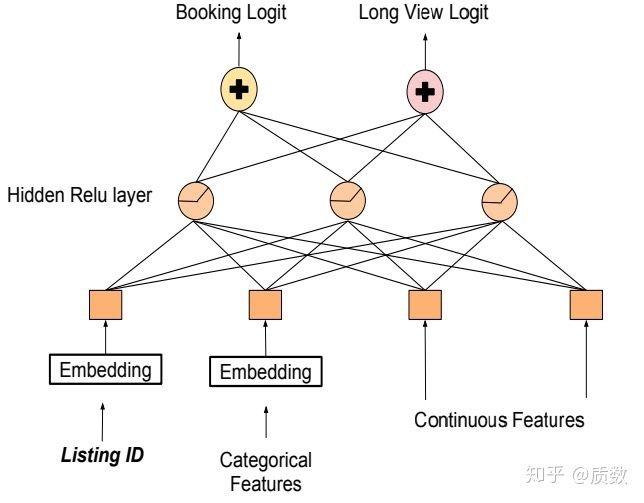
对于成交的订单比较少,导致了listingID的Embedding向量化的尝试的失败,作者们自然考虑到了怎么利用其它数据来提升其效果,因此浏览行为数据自然成为其下一步要利用的数据,成交和浏览显然是两个不同的任务,拥有不同量级的数据,多任务学习上场。 在平台上浏览是不花钱的,每个人都可以去看看土豪们才住得起的豪宅,或者基于猎奇心理,去浏览各种神奇的房子,如城堡,树屋,房车等,这些都可以成为茶余饭后的谈资。从数据中看,一个房屋(listingID)被浏览的次数/被下单的次数的比例分布,如下图所示,浏览是下单次数的2个数据量级,拍脑袋想想都可以得出这样的结论,点点点与买买买之间存在正向相关性的, 被浏览的次数越多,时间越长,被下单的可能性也越大。
因此,作者们构建了一个多任务学习网络,一个用于预测listingID被下单的概率,一个用于预测listingID是否被长时间浏览(Long View),网络结构如下图所示,输出层共享相同的隐含层,对于输入层,由于浏览数据是成交数据的2个数据级,因此作者们希望可以将浏览的listingID的Embedding向量迁移到成交的listingID上,具体训练细节不深究。在训练好的模型中线上进行测试发现,模型提升了长时浏览的listingID,即推出的ListingID确实被浏览的时间更长了,但是成交数据没涨,通过检查浏览/下单比例高的样本发现,被浏览时间更久的listingID具有的特征如下:
- 高端大气,价格贵;
- 具有详细的描述,多图,导致系统渲染需要更多的时间;
- 独特,稀奇,导致很多人来猎奇;
(对于他们的结论没怎么看明白)作者们没有具体分析多任务学习失败的原因,除了对对上述case进行统计。但是我们可以发现,在利用多任务学习框架的时候,要考虑任务与任务之间的相关性,但是如果任务之间完全正交,也不适合利用多任务学习。
对于多任务学习,本人尝试过利用12个相关的逾期标签进行训练,当初的背景是对于不同的时刻的样本,其可看逾期表现的期数是不一样的,这就面临一个选择,该选哪期比较合适的问题,最终暴力的把12期标签全部丢进去,对于可看多少期的,就利用多少其的样本,但是这个网络本质上不上多任务,因为各个标签相关性太高,是一个任务,都是用于预测逾期。
从后面迭代效果来讲,LightGBM的迭代效率,预处理难度远远小于MLP,在Homecredit的比赛中,也看过几个深度网络网络的方案,什么DAE网络,但是看起来很复杂,一般人无法驾驭,同时在表现上确实会比LightGBM模型差一点,想要达到相同的结果,需要付出更多的时间。
直接利用GBDT的特征的教训
对于特征工程,尤其是这种与时间序列相关的特征构建,套路已经比较固定化了,感兴趣的同学可以参考之前的文章。在Airbnb,GBDT相关模型的特征基本也是那样构造出来的,然后通过逐步挖掘,补充新的特征到模型中,毕竟特征工程的好坏(数据)决定了模型的上限,因此他们自己也不清楚当前的特征是否是最好的,或者随着市场环境的变化,这些特征是否有效。考虑到深度学习在特征工程自动化的方面的优势,很自然的认为只要把原始数据送到网络中,让神经网络的隐含层完成各自特征的交叉组合即可,然而这种简单粗暴的行为,可能并不能发挥神经网络的优势,在使用神经网络上,输入的数据需要处理得更细致,因此作者在这部分引入了特征归一化的经验公式,用于告诉读者们,以后用神经网络可得用点心,好好预处理一下特征,在特征分布上面,需要尽可能的利用平滑的数据,特征要尽可能的平滑,作者们用了两个例子来告诉读者怎么去得到这样的数据。
特征归一化-Feature normalizaiton
在作者们第一次使用深度神经网络的时候,直接将GBDT模型中用到的特征作为网络的输入,结果可想而知,差的一塌糊涂,训练损失在降到一定程度后,即使增加训练次数也不会发生变化(可能发生了梯度消失),直接原因当然是未对特征进行归一化,有读者可能会说,不是有BatchNorm层嘛,直接利用这个归一化不就可以么,其实这样做还是有点问题的,训练的结果不一定会好,最好的办法是根据各个特征的分布来决定对特征进行归一化. 作者们提出了两种归一化的方法:
- 对于正太分布的特征:直接利用如下公式进行归一化,
为特征在训练集中的均值,
为标准差:
- 对于服从幂律分布的变量,直接进行如下变换, median表示特征的中位数:
在我自己的实践中,在做上述处理的时候,需要考虑一种的情况是特征的缺失值,由于很多特征的缺失值占据着很多的比例,在进行上述变换的过程,统计特征的均值,方差,中位数时,一般是需要将这些缺失样本刨除,在变换完成之后,利用变换后的均值填充缺失值即可,下面是一个特征变换的示例:
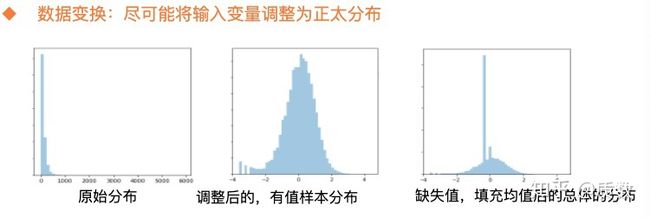
样本分布服从幂律分布,进过变换后,基本上服从正太分布。其实很多时候,大家可能会将特征一化理解成将各个特征缩放到
特征分布- Feature distribution
这里的特征分布,指的是特征分布是平滑的,直观上特征分布不存在多个波峰或者波谷(跟上述Feature normalizaiton感觉是一样),作者认为平滑的特征分布,具有有如下优点:
- 发现特征中的bug, 虽然特征的范围检查可以在一定程度上发生特征在数据上的问题,他们发现对比特征的分布图,可以很直观的发现正常分布与异常分布的,因此异常数据在分布上有很大的差异(有点什么都没说的感觉)
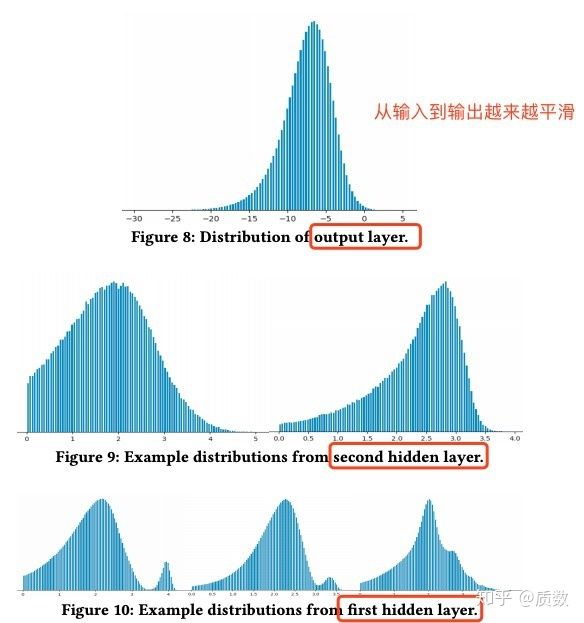
- 特征平滑能够提升模型泛化能力, 探索深度神经网络泛化性问题是一个专门的研究领域,因此作者们的经验是基于模型和数据观察到,从输入层到输出层,中间数据经过网络后,变得越来越平滑(smooth), 如图所示,将样本经过中间层的输出(去除取值为0的),对数据进行变换
。关于为什么特征平滑能够提升模型泛化能力,作者的解释为,让神经网络中在特征所有的取值范围内进行特征交叉的计算是不可能完成(需要各种各样的训练样本),然而现实中的训练集也仅仅代表其中的部分数据,因此如果更low-level的特征的服从某种分布,越平滑的话,那么对于更高层的来说,其能够输如取值的范围可以确定下来,这样对于测试集中low-level的特征取值在训练集中未出现的值,也不至于跑出下一层的范围,这样就是模型的泛化能力更强(还不如利用BatchNorm的一种解释来说明),总之一句话,训练深度神经网络,最后要把特征转化到更平滑的分布上,而特征归一化在一定程度上就是要将输入特征变得更平滑。
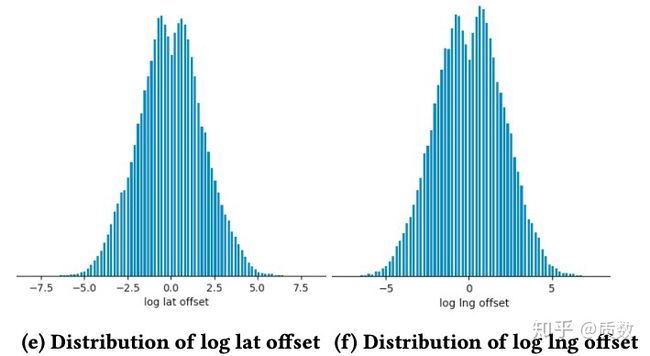
关于特征平滑,直接通过上述特征归一化方式并不能得到想要的结果,需要额外的操作。作者举了一个例子,即经纬度坐标信息,正常情况下,其分布如图(a)(b)所示,非常的不平滑,存在多个波峰或者波谷,作者们尝试了利用位置偏移做为新的特征,即利用显示给用户的地图中心点作为原点,得到其他各个点与原点的位置偏移(offset), 重新将经纬度做的偏移作为新的特征,其分布如图(c)所示,由于将原始特征转成偏移特征时,可能存在多对一的情况,因此其分布主要是集中在原点周围,对图(c)取

特征完整性
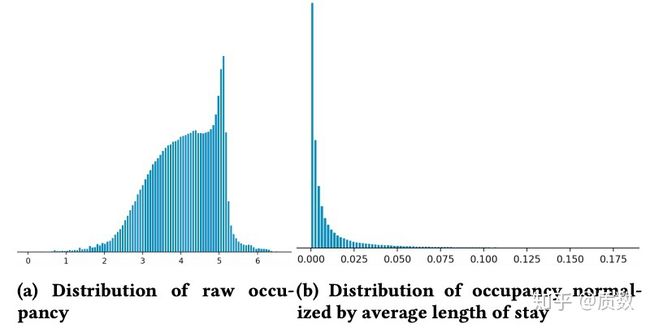
其实这点主要是讲如果发现某些特征的分布跟预期不符,需要去探索背后是否存在某种业务含义。这里面讲了一个例子,说他们做了一个关于listingid质量的特征,一个listingid越优质,那么其在未来一段时间内被预定出去的天数的占比应该越大,通过数据发现这个特征的分布存在诡异的地方,如下图所示,在横轴坐标为5处后发现了数据断层,不平滑;面对这样的分布,自然要提高警惕,结果是因为越高端的listingid相邻两次预定需要满足一定的时间间隔才能被下一个订单预定(minimum stay requirements),这样其实越高端的listingid这个特征取值并是其最大值,因此特征存在一定的问题,需要结合最小时间间隔来加权,变换后特征平滑了。
关于特征完整性,其实在现实场景中容易忽略的一点是,一个特征对于不同时间段上的样本,含义是否真的一致。举例,如果我们要生成一个商品类目在12个月内被用户点击的次数,因此我们至少需要保证每个样本都能拿到其历史12个月内的样本,但是很多线上应用考虑到时效性,往往会对数据进行截断,比如只保存最近6个月的记录,那么在线上打分时,特征含义发生了变化,造成线上与线下发生不一致。另外一点是,如果在生成训练集时,数据的样本不能够保证离现在最远的样本可以获得其12个月的历史数据,那么不同时间段上的样本,特征也发生了变化,所以,在我们做特征的时候,要考虑时间上的样本含义是否发生了这种隐藏的风险点。
关于超参
经验证明,不要花过多的时间在调参上,当我们不余遗力地,尽可能不遗漏地去尝试各种试验,其实很大程度上都是无用功,但是作者列出了几个他们得到的经验点。
dropout: 没啥好说的,dropout不一定有效,其实很多MLP网络都会用BatchNorm层了,一般不要和dropout混用,并且现在有很多种正则化的方式,同时现在的训练样本比当年提出dropout年代要大几个数量级,过拟合的风险应该小了很多。另外可以通过随机地使得部分特征缺失也可以达到dropout的效果
网络参数初始化: 不要把参数和Embedding向量初始化为0,他们的经验是先尝试Xavier初始化,对于Embedding向量利用
学习率&BatchSize: LazyAdamOptimiezer!!!没用过,我就用过Adam,SGD,其他改进的不一定那么好用。BatchSize设置在200左右
神经网络特征重要性评估
在这部分作者提出了一种基于样本排序的特征重要性评估,方法如下:
- 利用神经网络对样本进行打分,根据得分将样本按照顺序排序
- 设置一定的切分点,将样本分成TOP的样本和Bottom的样本,即排名高的样本,和排名低的样本;
- 对于选取的一个特征,观察其在TOP和Bottom样本中的统计分布,如图所示:
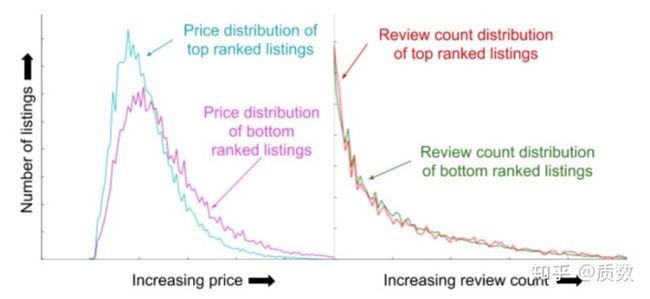
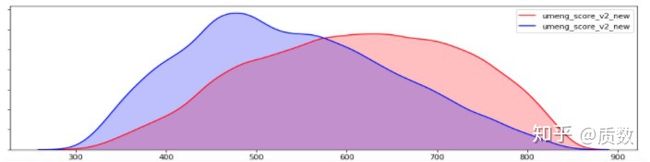
从图中可以发现,对于价格越高的listingID,其被预定的概率越低,而对于评论次数的,在TOP和Bottom样本中分布是一致的,区分性不是特别大。在真实的业务场景中,这个自顶向下的评估方式,似乎是有效的,简单好理解,缺点是需要大量的人工操作,挑选,如图所示,列举了一个外部数据源的分,取值越大说明用户越优质。
写在最后
不想总结了,后面再写了,干不动了。
http://weixin.qq.com/r/ny-u9i-ECXJ2rWuV93qN (二维码自动识别)