卷积神经网络实战——表情识别(Pytorch)超详细理解,含Pyqt5的可操作界面
卷积神经网络实战——表情识别(Pytorch)
这里作一下申明,之前对于神经网络的搭建解释的不够全面,这里进行补充,训练过程的代码可能太过繁琐不好理解,现在进行补充和修改,然后关于数据集用的是阿里天池公开课里面的表情识别数据集。
变化的部分会以红色字体标出
- 一、数据集
- 二、构建神经网络
- 三、网络训练(理解)
-
- 1、分类网络的初始化相关训练参数
- 2、数据输入网络前的准备(数据,真实标签)
- 3、模型准备
- 4、选用损失函数
- 5、选用的优化器,学习率
- 6、训练和验证
- 四、网络训练测试总代码
- 五、基于Pyqt5的Gui设计
日志:
2022.6.20:添加exp_lr_scheduler.step(),更新学习率,不加这一步学习率不会更新。
前面六篇文章详细介绍了神经网络的基础,下面就一个简单的识别案例对前六章进行一个总结(可能有人对前六章在具体的网络中是干什么的有疑惑,下面进行具体代码分析)。
一、数据集
二、构建神经网络
首先我们要构建一个搭建网络的类,在类中主要实现网络的两部分,一部分是网络层的定义,另一部分将网络层连接起来构成网络
在之前的篇章神经网络基础篇中我们知道网络的构建需要以下:
(1)卷积层
(2)激活
(3)池化
(4)全连接
(5)Batch Normalization
当然不同的网络构造采用的方式不一样,有的只包含其中的几层。
接下来对要构造的神经网络进行一个说明:
我们要构造的是一个3层卷积,3层全连接的网络,其中包含激活,以及Batch Normalization。
下图是网络结构的整体流程图,后面的部分没有画图,直接写了尺寸大小:

下面是构建网络层的代码(网络并不绝对,可以尝试不同的网络构建)
关于网络的python基础构建可以参考我的这篇文章(要想不借助别人的代码自己构建这一点很重要)
卷积神经网络构建的python基础-详细理解(Pytorch)
这里解释一下torch.nn,和 torch.nn.functional
前者可以自动提取可学习的参数,模型有可学习的参数可以采用(像卷积、全连接这些),后者进行简单的数学运算,适合像Relu这样的激活函数(激活函数无参数)直接运算。
import torch.nn as nn
import torch.nn.functional as F
class simpleconv(nn.Module):
def __init__(self, nclass):
super().__init__()
# conv1
self.conv1 = nn.Conv2d(3, 12, 3, 2) #卷积核大小:3,步长:2
self.bn1 = nn.BatchNorm2d(12)
# conv2
self.conv2 = nn.Conv2d(12, 24, 3, 2)#卷积核大小:3,步长:2
self.bn2 = nn.BatchNorm2d(24)
# conv3
self.conv3 = nn.Conv2d(24, 48, 3, 2)#卷积核大小:3,步长:2
self.bn3 = nn.BatchNorm2d(48)
# 三层全连接
self.fc1 = nn.Linear(48 * 5 * 5, 1200)
self.fc2 = nn.Linear(1200, 128)
self.fc3 = nn.Linear(128,nclass) # 最后一层全连接输出必须时类别数
def forward(self, x):
x = F.relu(self.bn1(self.conv1(x))) # torch.Size([128, 12, 23, 23])
x = F.relu(self.bn2(self.conv2(x))) # torch.Size([128, 24, 11, 11])
x = F.relu(self.bn3(self.conv3(x))) # torch.Size([128, 48, 5, 5])
x = x.view(-1 , 48*5*5) # 压缩维度 torch.Size([128, 1200])
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
if __name__ == '__main__':
import torch
x = torch.randn(128,3,48,48) # 生成随机数字的tensor
model = simpleconv(4)
y = model(x)
关于压缩维度的操作,可以参考我的这一篇博客神经网络中view(),torch.flatten(),torch.nn.Flatten()详解
#更改:
将super(simpleconv, self)._init_()更换为super()._init_(),目前大部分采用的python版本大都是python3,因此可以改用
【注】
Python3.x 和 Python2.x 的一个区别是: Python 3 可以使用直接使用 super().xxx 代替 super(Class, self).xxx
那么这里简单总结一下,网络构建所学的东西
(1)python的基础,要知道 类的创建,继承,_init_(), forward(), self 这些的具体原理,作用
(2)要知道神经网络结果,层与层之间是怎么操作的,激活,池化等都具有怎样的作用,以及他们尺寸通道的变化。
这些之前的文章都有讲解过。
三、网络训练(理解)
我们在训练卷积神经网络的时候,主要串联以下几点,就不会太过迷茫
(1)输入数据(处理过后),数据在网络中进行卷积等操作(网络的构建)
(2)卷积,全连接操作过后得到最终的预测值,并与真实标签值计算损失(损失函数)
(3)根据损失值计算梯度进而更新参数(优化器,即梯度下降的方式)
下面我将详细的描述各个训练部分
网络的训练主要包含以下部分:
1、定义分类网络初始化相关训练参数
2、数据输入网络前的准备(数据,真实标签)
3、模型准备
4、选用损失函数
5、选用的优化器,学习率
6、训练
1、分类网络的初始化相关训练参数
关于训练参数,我们想到的有如下几条:
(1)训练轮数:就是我们想要将整个数据集训练几遍。
(2)batchsize:就是我们想要一次性输入多少数据(根据电脑性能进行选择)。
(3)类别:要识别的类别数量。
(5)数据路径:这个路径是存放训练集和测试集的根目录。
# 1、设置一些网络训练的参数
batch_size = 128 # 输入网络的batch(即一次性输入多少张图片)
nclass = 4 # 网络识别的类别
data_dir = './data' # 数据 路径
num_epochs = 100 # 训练轮数100轮
2、数据输入网络前的准备(数据,真实标签)
这一部分我们主要考虑什么样的数据才能输入到pytorch网络中进行训练呢?
(1)数据加载器:torchvision库中的datasets.ImageFolder,该库可以完成数据的读取和处理,有如下几个属性:
self.classes:一般来说是文件的名字
self.class_to_idx:类别对应的索引,从0开始
self.imgs:保存(img-path, class) tuple的列表
需要注意的是下面的transforms操作,transforms.Normalize只能对PIL、tensor格式进行操作,因此需要放在ToTensor之后,详情见我的另一篇博客
神经网络数据增强transforms的相关操作(持续更新)
# (1)数据增强处理:
data_transforms = transforms.Compose([transforms.Resize((64, 64)),
transforms.RandomSizedCrop(48),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])])
# (2)进行数据读取和数据预处理:
image_datasets = datasets.ImageFolder(os.path.join(data_dir, 'train'), data_transforms)
#有以下几个属性:
print(image_datasets.classes) # 数据标签
print(image_datasets.class_to_idx) # 数据标签代号
print(image_datasets.imgs) # 路径,标签
>> ['expression_none', 'mouth_open', 'pouting', 'smile']
>>{'expression_none': 0, 'mouth_open': 1, 'pouting': 2, 'smile': 3}
>>[('./data\\train\\expression_none\\1000none.jpg', 0)...]
(2)上一步可以得到图片数据和标签,但是我们输入网络需要的是批量的图片数据以及对应标签的,因此还需将图片及标签进行batchsize分批。
dataloaders = torch.utils.data.DataLoader(image_datasets,
batch_size,
shuffle=True,
num_workers=0)
此时我们的数据就已经准备好了,可能有的小伙伴还不太理解,下面画一幅图进行理解。
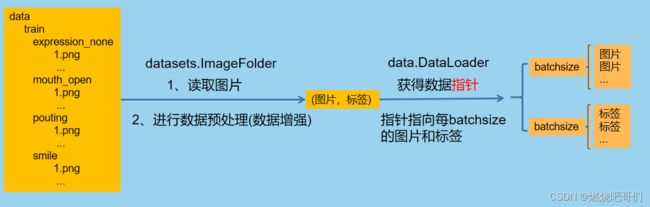
总的来说如上图,这只是我个人的理解,有不对的地方望指教。
3、模型准备
模型这里主要是是否使用GPU
# 初始化网络模型,判断是否能用GPU进行训练
if torch.cuda.is_available():
device = "cuda"
else:
device = "cpu"
model = simpleconv(nclass).to(device)
4、选用损失函数
一般来说分类损失采用交叉熵损失函数,关于交叉熵损失见我的这篇博客。
卷积神经网络的深入理解-优化目标(损失函数)篇
criterion = nn.CrossEntropyLoss() # 交叉熵损失
5、选用的优化器,学习率
优化器即梯度更新的方式,详细见我的这篇博客
卷积神经网络的深入理解-最优化方法(梯度下降篇)(持续更新)
这里采用的是一个基本方法SGD,优化器和学习率主要是用于更新网络模型的参数,这里设置学习率每200轮变为原来的1/10。
optimizer_ft = optim.SGD(model.parameters(), lr=0.1, momentum=0.8) # 梯度下降方式,用于更新梯度
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=200, gamma=0.1) # 根据训练的轮数调整学习率
6、训练和验证
将模型,数据,损失,优化器(主要是这四大部分)…传入训练函数
这里,去掉了Variable以及.data,理由是版本大于等于0.4.0的Pytorch将Variable与Tensor合并了,具体见我的这篇文章
Variable与Tensor合并后,关于训练、验证的相关变化
def train(train_loader,model,criterion,optimizer,device,len_train,batch_size):
num_loss = 0.0
num_corrects = 0.0
model.train()
for i ,(data,target) in enumerate(train_loader): # enumerate:列举
data = data.to(device)
target = target.to(device)
optimizer.zero_grad()
outputs = model(data)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs,target)
loss.backward()
optimizer.step()
num_corrects += torch.sum(preds==target).item()
num_loss = num_loss + loss.item()
train_loss = num_loss / (len_train//batch_size+1) # 每一个epoch的训练损失
train_acc = num_corrects / len_train # 每一个epoch的训练正确率
return train_loss,train_acc
def val(val_loader,model,criterion,device,len_val,batch_size):
num_loss = 0.0
num_corrects = 0.0
model.eval() # 将模型转化到验证模式
with torch.no_grad(): # # 模型的参数都不会进行更新(把模型的参数固定下来)
for i ,(data,target) in enumerate(val_loader):
data = data.to(device)
target = target.to(device)
outputs = model(data)
_, preds = torch.max(outputs.data, 1)
loss = criterion(outputs, target)
num_corrects += torch.sum(preds == target).item()
num_loss = num_loss + loss.item()
val_loss = num_loss / (len_val//batch_size+1) # 每一个epoch的训练损失
val_acc = num_corrects / len_val # 每一个epoch的训练正确率
return val_loss,val_acc
四、网络训练测试总代码
原先代码进行了重写,同时也发现了原先的一些错误,
(1)打印的loss不太对,之前是直接计算总的loss然后除以数据量,但是这和batch有关,因为不管是多少个batch得到的loss都只是一个,所以做了如下操作:
num_loss / (len_train//batch_size+1)
(2)将训练与验证分开,更加方便理解
网络见二、构建神经网络
import torch
from net import simpleconv
from torchvision import transforms, datasets
import os
def train(train_loader,model,criterion,optimizer,device,len_train,batch_size):
num_loss = 0.0
num_corrects = 0.0
model.train()
for i ,(data,target) in enumerate(train_loader): # enumerate:列举
data = data.to(device)
target = target.to(device)
optimizer.zero_grad()
outputs = model(data)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs,target)
loss.backward()
optimizer.step()
num_corrects += torch.sum(preds==target).item()
num_loss = num_loss + loss.item()
train_loss = num_loss / (len_train//batch_size+1) # 每一个epoch的训练损失
train_acc = num_corrects / len_train # 每一个epoch的训练正确率
return train_loss,train_acc
def val(val_loader,model,criterion,device,len_val,batch_size):
num_loss = 0.0
num_corrects = 0.0
model.eval() # 将模型转化到验证模式
with torch.no_grad(): # # 模型的参数都不会进行更新(把模型的参数固定下来)
for i ,(data,target) in enumerate(val_loader):
data = data.to(device)
target = target.to(device)
outputs = model(data)
_, preds = torch.max(outputs.data, 1)
loss = criterion(outputs, target)
num_corrects += torch.sum(preds == target).item()
num_loss = num_loss + loss.item()
val_loss = num_loss / (len_val//batch_size+1) # 每一个epoch的训练损失
val_acc = num_corrects / len_val # 每一个epoch的训练正确率
return val_loss,val_acc
# 设置网络参数
batch_size = 128
nclass = 4
num_epochs = 300
data_dir = './data'
# 初始化网络模型
if torch.cuda.is_available():
device = "cuda"
else:
device = "cpu"
model = simpleconv(nclass).to(device)
# 准备数据
# 1、数据增强处理
train_transforms = transforms.Compose([
transforms.Resize((64, 64)),
transforms.RandomSizedCrop(48),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])])
val_transforms = transforms.Compose([
transforms.Resize((64, 64)),
transforms.CenterCrop(48),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])])
# 2、数据读取与处理
train_datasets = datasets.ImageFolder(os.path.join(data_dir, 'train'), train_transforms)
val_datasets = datasets.ImageFolder(os.path.join(data_dir, 'val'), val_transforms)
len_train = len(train_datasets)
len_val = len(val_datasets)
# 3、数据封装(batch)
train_loaders = torch.utils.data.DataLoader(
dataset=train_datasets,
batch_size=batch_size,
shuffle=True,
num_workers=0
)
val_loaders = torch.utils.data.DataLoader(
dataset=val_datasets,
batch_size=batch_size,
shuffle=True,
num_workers=0
)
# 损失函数(用于更新参数)、优化器(梯度下降以一个什么样的方式下降)、学习率
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer_ft = optim.SGD(model.parameters(), lr=0.1, momentum=0.8) # 优化器
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=200, gamma=0.1) # 根据训练的轮数调整学习率
from tensorboardX import SummaryWriter
import time
writer = SummaryWriter() # 用于生成可视化的图
best_acc = 0.0
for epoch in range(num_epochs):
start = time.time()
train_loss,train_acc = train(train_loaders,model,criterion,optimizer_ft,device,len_train,batch_size)
exp_lr_scheduler .step() # 更新学习率
val_loss,val_acc = val(val_loaders,model,criterion,device,len_val,batch_size)
# 保存最好的模型
if val_acc > best_acc:
best_acc = val_acc
torch.save(model.state_dict(), './best.pth')
writer.add_scalar('trainloss', train_loss, epoch)
writer.add_scalar('trainacc', train_acc, epoch)
writer.add_scalar('valloss', val_loss, epoch)
writer.add_scalar('valacc', val_acc, epoch)
end = time.time()
print('[{}/{}]: train_loss:{:.3f}, train_acc:{:.3f},eval_loss:{:.3f}, eval_acc:{:.3f}, time:{:.3f}'.format(epoch+1,num_epochs,train_loss,train_acc,val_loss,val_acc,end-start))
writer.close()
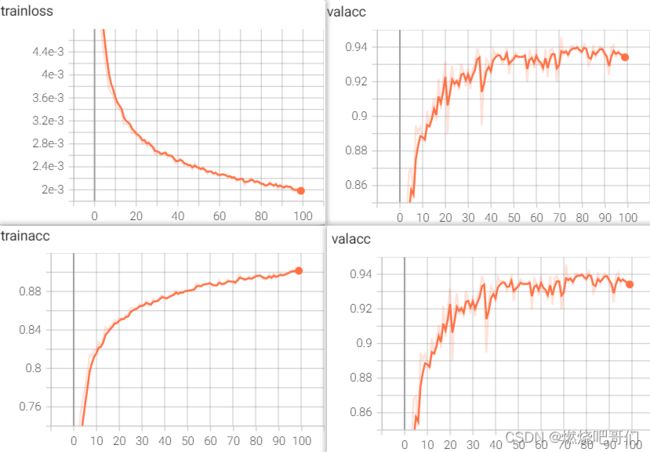
下面是有关结果
五、基于Pyqt5的Gui设计
这是界面的设计代码参考的
这篇博客
from PyQt5.QtWidgets import (QGridLayout, QPushButton, QLabel)
from PyQt5.QtGui import *
from PyQt5.QtWidgets import *
import sys
from PyQt5.QtCore import Qt
# 预测脚本
import torch
import torchvision.transforms as transforms
from PIL import Image
from net import simpleconv
import numpy as np
def predict(img):
device = torch.device('cpu')
data_tranform = transforms.Compose([transforms.Resize((48, 48)),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])])
img = data_tranform(img) # 数据预处理
img = torch.unsqueeze(img, dim=0) # 数据维数扩充,前面一维为batch
# 载入网络模型
model = simpleconv(4)
model_weight_pth = './best.pth'
model.load_state_dict(torch.load(model_weight_pth))
model.to(device)
model.eval()
# 标签设置
class_indict = {'0': '无表情',
'1': '张口',
'2': '撅嘴',
'3': '笑'}
# 输入网络输出结果
output = torch.squeeze(model(img)) # 去除batch
output = torch.softmax(output, dim=0) # 经过激活函数变为各个标签的概率
pro, preds = torch.max(output, 0) # 得到最大概率的标签索引
pro = pro.data.item()
pred = preds.item() # 变为数组类型
return class_indict[str(pred)],str(pro) # 返回预测结果,和预测概率
class Ui_example(QWidget):
def __init__(self):
super().__init__()
self.window_pale = QPalette() #窗口背景
self.layout = QGridLayout(self)
self.label_image = QLabel(self) #图像显示
self.label_predict_result = QLabel('识别结果', self)
self.label_predict_result_display = QLabel(self)
self.label_predict_acc = QLabel('识别准确率', self)
self.label_predict_acc_display = QLabel(self)
self.button_search_image = QPushButton('选择图片',self)
self.button_run = QPushButton('识别表情',self)
self.setLayout(self.layout)
self.initUi()
def initUi(self):
self.layout.addWidget(self.label_image,1,1,3,2) #,1.5,1,3,2 #图像位置
self.layout.addWidget(self.button_search_image,1,3,1,2) #,1,3,1,2 #"选择图片"按钮位置
self.layout.addWidget(self.button_run,3,3,1,2) #,3,3,1,2 #"识别表情"位置
self.layout.addWidget(self.label_predict_result, 4, 3, 1, 1) # "识别结果"位置
self.layout.addWidget(self.label_predict_result_display, 4, 4, 1, 1) # 识别结果
self.layout.addWidget(self.label_predict_acc, 5, 3, 1, 1) # "识别准确率"位置
self.layout.addWidget(self.label_predict_acc_display, 5, 4, 1, 1) # 识别准确率
self.button_search_image.clicked.connect(self.openimage)
self.button_run.clicked.connect(self.run)
self.setGeometry(500,500,500,500)
self.setWindowTitle('表情识别')
self.window_pale.setBrush(QPalette.Background, QBrush(QPixmap("./win.jpg"))) # 背景图片
self.setPalette(self.window_pale)
self.show()
def openimage(self):
global fname
imgName, imgType = QFileDialog.getOpenFileName(self, "选择图片", "", "*.jpg;;*.png;;All Files(*)")
jpg = QPixmap(imgName).scaled(self.label_image.width(), self.label_image.height(), Qt.KeepAspectRatio,Qt.SmoothTransformation)
self.label_image.setPixmap(jpg)
fname = imgName
def run(self):
global fname
file_name = str(fname)
img = Image.open(file_name)
pred, pro = predict(img)
self.label_predict_result_display.setText(pred)
self.label_predict_acc_display.setText(pro)
if __name__ == '__main__':
'''
app.exec_()其实就是QApplication的方法,
这个exec_()方法的作用是“进入程序的主循环直到exit()被调用”
'''
app = QApplication(sys.argv)
ex = Ui_example()
sys.exit(app.exec_())
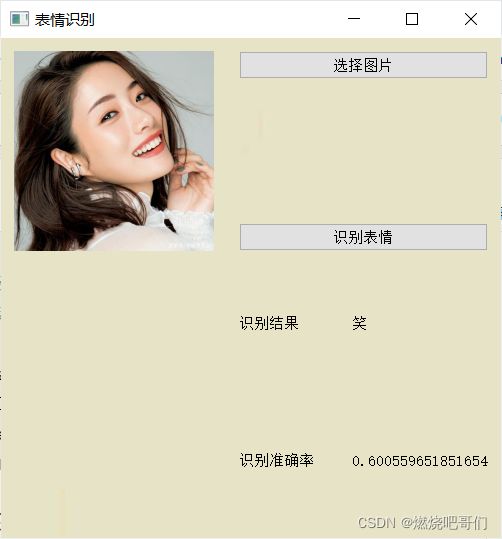
下面是可视话界面的结果图:
虽然文章只是简单的实现了一个网络,但是涉及的基础内容比较多,如有错误还望指教,最后希望获得一个免费的赞,谢谢。