PyTorch 表情识别
VX:13225601016 获取源码和数据集
实验环境:
硬件环境:CPU i7-6500U,GPU GTX950M
软件环境:python3.7,torch 1.7.0+cu101
实验步骤:
1.训练
数据集
将训练集文件夹train和验证集文件夹val加入到我的训练文件夹mytrain内。测试集文件夹test和我的训练集文件夹mytrain在同一工作目录下。如图1。
图1数据集
训练集和验证集数据加载
在训练数据集下,每种表情的图片均存储在其标签为目录的文件夹下。在这里可以使用torchvision.datasets.ImageFolder()方法来加载这种组织方式的数据集。如图2。验证集组织形式同训练集,数据加载方式相同。

图2训练集的组织形式
data_dir = './mytrain'
data_transforms = transforms.Compose([
transforms.ToTensor(),
transforms.Grayscale(num_output_channels=1)])#数据加载成tensor,加载灰度图像
train_dataset = torchvision.datasets.ImageFolder(root = os.path.join(data_dir, 'train'), transform = data_transforms)
val_dataset = torchvision.datasets.ImageFolder(root = os.path.join(data_dir, 'val'), transform = data_transforms)
train_dataloader = DataLoader(dataset=train_dataset, batch_size=128, shuffle=True)
val_dataloader = DataLoader(dataset=val_dataset, batch_size=128, shuffle=True)卷积神经网络的定义
使用卷积神经网络对数据集进行训练。卷积层分为三层,输入图像每一层均以3*3卷积核进行训练,每次经过卷积操作后进行归一化,通过激活函数后在进行下采样。线性层将卷积层得到的输出作为输入,输出向量的维度等于类别数目7。网络结构如图3。
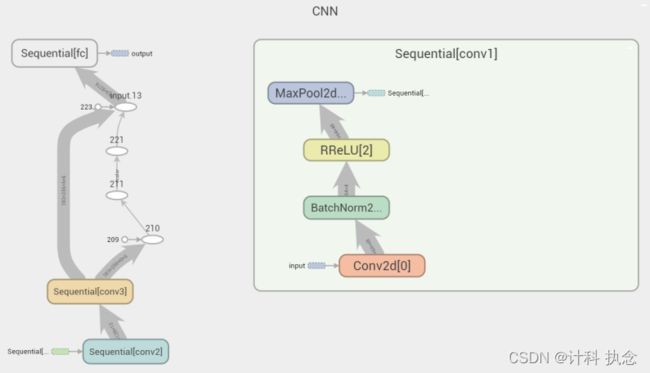
图3 网络结构图
# 参数初始化
def gaussian_weights_init(m):
classname = m.__class__.__name__
# 字符串查找find,找不到返回-1,不等-1即字符串中含有该字符
if classname.find('Conv') != -1:
m.weight.data.normal_(0.0, 0.04)
class CNN(nn.Module):
# 初始化网络结构
def __init__(self):
super(CNN, self).__init__()
# 第一次卷积、池化
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=64, kernel_size=3, stride=1, padding=1), # 卷积层
nn.BatchNorm2d(num_features=64), # 归一化
nn.RReLU(inplace=True), # 激活函数
nn.MaxPool2d(kernel_size=2, stride=2), # 最大值池化
)
# 第二次卷积、池化
self.conv2 = nn.Sequential(
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=128),
nn.RReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
)
# 第三次卷积、池化
self.conv3 = nn.Sequential(
nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=256),
nn.RReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
)
# 参数初始化
self.conv1.apply(gaussian_weights_init)
self.conv2.apply(gaussian_weights_init)
self.conv3.apply(gaussian_weights_init)
# 全连接层
self.fc = nn.Sequential(
nn.Dropout(p=0.2),
nn.Linear(in_features=256 * 6 * 6, out_features=4096),
nn.RReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(in_features=4096, out_features=1024),
nn.RReLU(inplace=True),
nn.Linear(in_features=1024, out_features=256),
nn.RReLU(inplace=True),
nn.Linear(in_features=256, out_features=7),)
# 前向传播
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
# 数据扁平化
x = x.view(x.shape[0], -1)
y = self.fc(x)
return y网络的训练
训练步骤一共有100个epoch。batch_size=512。损失函数使用交叉熵损失函数,使用Adam方法对学习率进行优化。每进行5个epoch,分别在训练集和验证集上进行验证,将验证集上正确率大于先前正确率的model进行存储。
def train(train_dataset, val_dataset, batch_size, epochs, learning_rate, wt_decay):
train_loader = DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(dataset=val_dataset, batch_size=batch_size, shuffle=True)
model = CNN().to(device)
loss_function = nn.CrossEntropyLoss().to(device)
optimizer = optim.Adam(model.parameters(), lr=learning_rate, weight_decay=wt_decay)
# scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.8)
max_acc = 0
for epoch in range(epochs):
loss_rate = 0
model.train() # 模型训练
for images, labels in train_loader:
images = images.to(device)
labels = labels.to(device)
optimizer.zero_grad()
output = model.forward(images)
loss_rate = loss_function(output, labels)
loss_rate.backward()
optimizer.step()
print('After {} epochs , the loss_rate is : '.format(epoch + 1), loss_rate.item())
with SummaryWriter(comment='mynet') as w:#tensorboard --logdir C:\Users\29290\Desktop\2020CV表情识别实验\runs
w.add_scalar('scalar/train',loss.item(),epoch+1)
w.add_graph(net,inputs)
if epoch % 5 == 0:
model.eval() # 模型评估
acc_train = validate(model, train_dataset, batch_size)
acc_val = validate(model, val_dataset, batch_size)
print('After {} epochs , the acc_train is : '.format(epoch + 1), acc_train)
print('After {} epochs , the acc_val is : '.format(epoch + 1), acc_val)
if acc_val > max_acc:
max_acc = acc_val
torch.save(model.state_dict(),'model.pth')main函数
def main():
data_dir = './mytrain'
data_transforms = transforms.Compose([
transforms.ToTensor(),
transforms.Grayscale(num_output_channels=1)])
train_dataset = torchvision.datasets.ImageFolder(root = os.path.join(data_dir, 'train'), transform = data_transforms)
val_dataset = torchvision.datasets.ImageFolder(root = os.path.join(data_dir, 'val'), transform = data_transforms)
train(train_dataset, val_dataset, batch_size = 512, epochs=150, learning_rate=0.001, wt_decay=0)2.测试
数据加载
测试集文件组织形式与训练集,验证集不同如图4。因此需要自定义数据加载。
图4 测试数据集
class Dataset(data.Dataset):
# 初始化
def __init__(self, root, transform):
super(Dataset, self).__init__()
self.root = root
self.files = os.listdir(self.root)
self.transform = transform
def __getitem__(self, index):
# 获取数据集样本个数
img = Image.open(os.path.join(self.root,self.files[index]))
img = self.transform(img)
return img
def __len__(self):
return len(self.files)定义测试函数
def test(model, dataset, batch_size):
test_loader = data.DataLoader(dataset, batch_size)
predict = []
for images in test_loader:
images = images.to(device)
pred = model.forward(images)
pred = np.argmax(pred.data.cpu().numpy(), axis=1)
predict.extend(list(pred))
return predictmain函数
将预测值对应的label写入prediction.csv。
def main():
data_dir = './test'
label_list = ['angry', 'disgust', 'fear', 'happy', 'neutral', 'sad', 'surprise']
data_transforms = transforms.Compose([
transforms.Grayscale(num_output_channels=1),
transforms.ToTensor()])
test_dataset = Dataset(data_dir ,data_transforms)
test_loader = torch.utils.data.DataLoader(test_dataset,batch_size=8)
model = torch.load('model_MyNet.pkl')
predict = test(model, test_dataset, 128)
predict_label = [label_list[i] for i in predict]
image = list(os.listdir(data_dir))
df = pd.DataFrame({'image':image,'lable':predict_label})
df.to_csv('prediction.csv', index=False)实验结果:
实验在训练集上准确率可以达到99%,而在验证集上只能达到57%。实验将loss,train_acc,val_acc进行可视化,如图5.
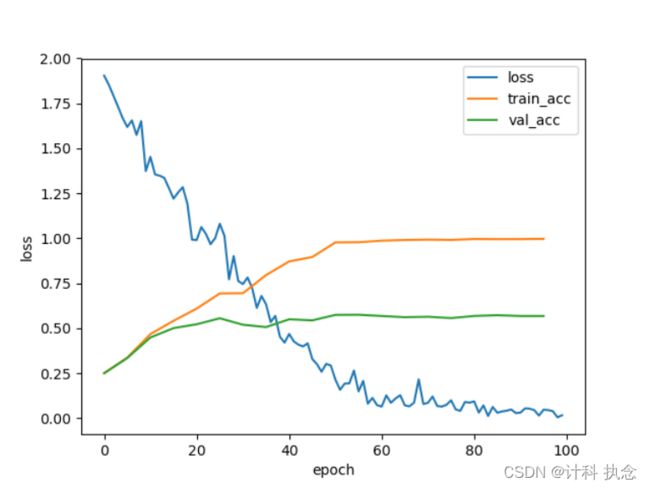
图5 网络损失和正确率曲线
import numpy as np
import matplotlib.pyplot as plt
loss = np.load('loss.npy')
epoch1 = np.arange(len(loss))
train_acc = np.load('train_acc.npy')
val_acc = np.load('val_acc.npy')
epoch2 = 5*np.arange(len(train_acc))
plt.plot(epoch1, loss, label='loss')
plt.plot(epoch2, train_acc, label='train_acc')
plt.plot(epoch2, val_acc, label='val_acc')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend()
plt.show()