显著性目标检测matlab代码_目标检测实战项目「代码实战篇」
深度学习的三驾马车:数据、模型、算力。本文将从这三方面,实现 YOLO 目标检测,让自己的数据跑起来
数据
一个深度学习项目最好的初始状态是拥有漂亮的数据,但是一般情况下很难达到这种条件,往往需要根据自己项目的需求寻找相应的数据。对于目标检测项目来说,漂亮的数据应该是按照规范的标注。那么有数据却没有标注怎么办,我们推荐一款开源的标注工具 LabelImg ,有着方便的 GUI 界面,可以方便打开一个文件夹,对相应的图片做标注,标注完成以后,支持 PascalVOC 或者 YOLO 格式导出,非常的方便。

Labelimg
该项目开源在: https://github.com/tzutalin/labelImg
想尝试一下本项目,苦于没数据怎么办?有数据不想标注,想看一下本项目的效果怎么办?这都不是问题,文末联系我,为你准备了两份数据!
模型
目标检测分为 Two-stage 和 One-stage 顾名思义就是两步完成还是一步完成(发展历程就是从 Two-stage 到 One-stage 的过程)
One-stage 和 Two-stage 各有千秋,One-stage 因为没有候选框生成步骤,所以速度会更快,速度更快意味着丧失了部分的精度,Two-stage 因为有候选框的选取过程,所以精度会更高,丧失部分精度,果然是鱼与熊掌不可兼得。
常见的 One-stage 算法有 OverFeat、YOLOv1、YOLOv2、YOLOv3、SSD 和 RetinaNet 等。
本文以 YOLOv3 为主要实践对象,一步一步通过开源的项目,使用 YOLOv3 训练自己的数据(完整的项目会在文末放出)
- 数据准备
巧妇难为无米之炊,没有数据,再优越的模型也无用武之地。
如果自己有原始的数据,但是没有标注,就可以使用 Labelimg 进行标注,输出的结果是一个 xml 文件。大致的文件结构如下:它包含的信息有图片的高宽通道数各个目标在原始图片的位置以及标签。

xml 文件
如果你已经有了标注的数据,就可以根据 xml 文件生成一个 txt 文件来进行训练,txt 文件的格式如下:第一个值代表类别标签的索引,后面四个值是原始图片上目标折算后的数值,我们就是根据这些数据来训练模型。
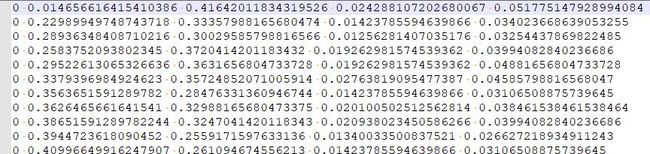
txt 数据文件
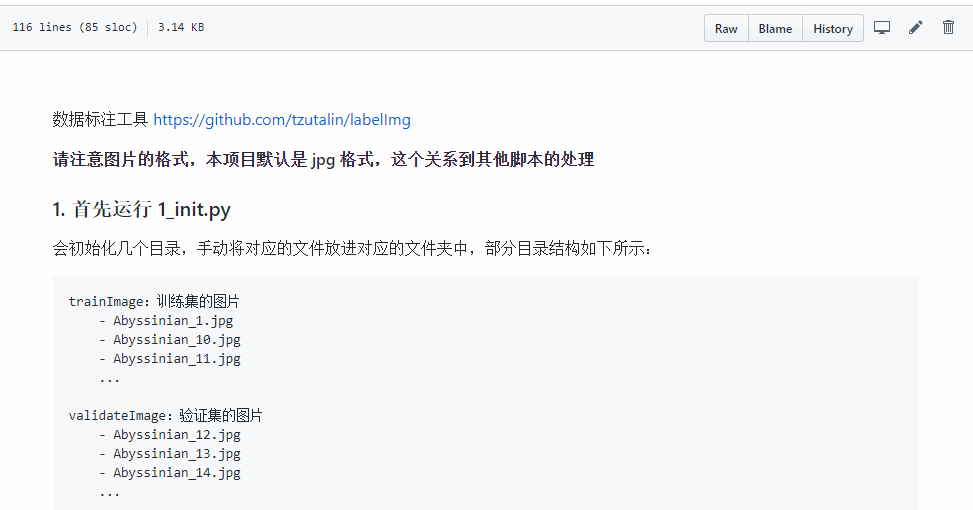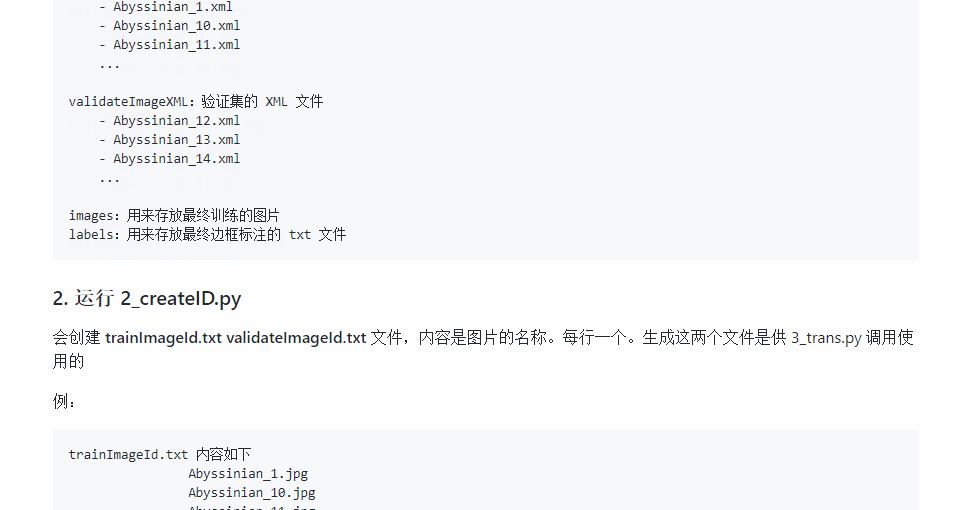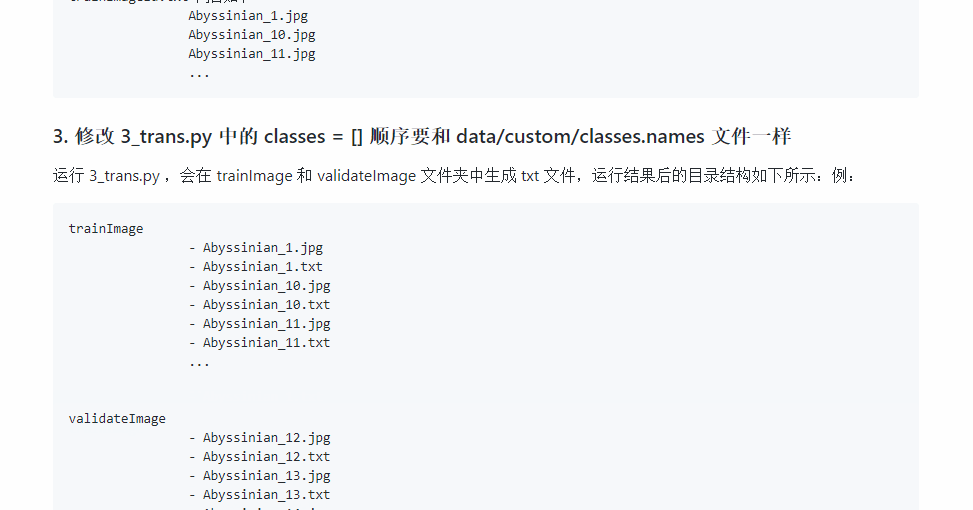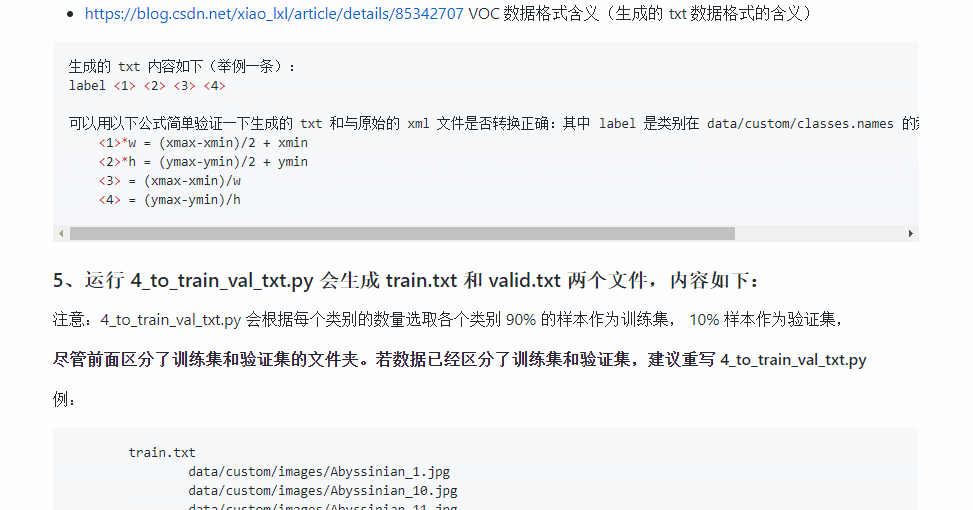
生成后可以用一下公式对转换前后的数据进行简单的验证,保证数据的准确性(具体的折算过程可以看文末的参考资料):
生成的 txt 内容如下(举例一条):label <1> <2> <3> <4>可以用以下公式简单验证一下生成的 txt 和与原始的 xml 文件是否转换正确:其中 label 是类别在 data/custom/classes.names 的索引, <> 代表缩放后的比例系数 <1>*w = (xmax-xmin)/2 + xmin <2>*h = (ymax-ymin)/2 + ymin <3> = (xmax-xmin)/w <4> = (ymax-ymin)/h对于如何根据 xml 标注文件生成 txt 数据文件,我们这边有份参考脚本可以帮助你:
阅读 readme.md 中的内容,按照 1、2、3、4 脚本运行,保证你啥问题都没有
│ 1_init.py│ 2_createID.py│ 3_trans.py│ 4_to_train_val_txt.py│ classes.names│ readme.md│ train.txt│ valid.txt│ ├─images│ train.jpg│ └─labels train.txt- YOLOv3 模型搭建
我们先来看一下 YOLO 的设计流程,对整个项目的大局有一定的掌控
- 配置数据文件
classes= 1 # 目标检测的类别数量,有多少类 就设置多少类train=data/custom/train.txt # 训练集的图片名称,放在 train.txt 文件下,每一行是一张图片的名称valid=data/custom/valid.txt # 训练集的图片名称names=data/custom/classes.names # 每个类别的名字,一行一个- 模型初始化
YOLOv3 使用的是 Darknet53 的结构,是一个全卷积的模型,可以拥抱任何大小的输入,但是必须是 32 的整数倍。Darknet 结果图如下:
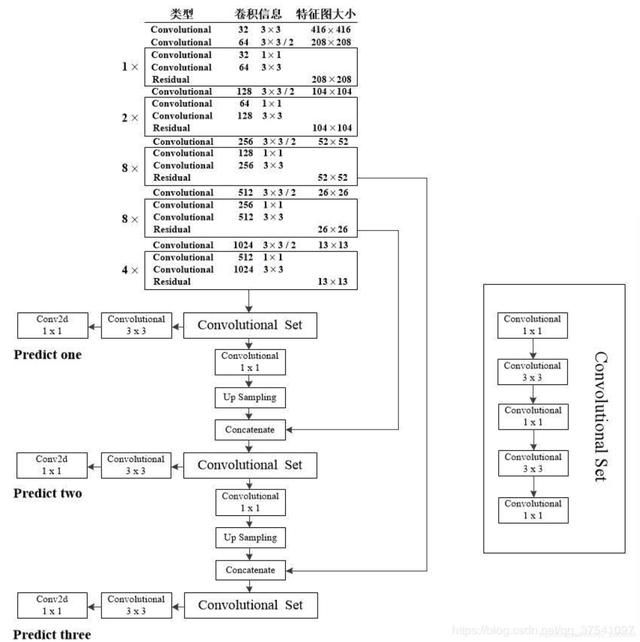
darknet53 结构图 图片来自互联网,侵删
本文使用的深度学习框架是 Pytorch 项目中读取 Darknet53 模型的方式是通过读取配置文件,格式如下,并把它加载带 Pytorch 定义的模型中
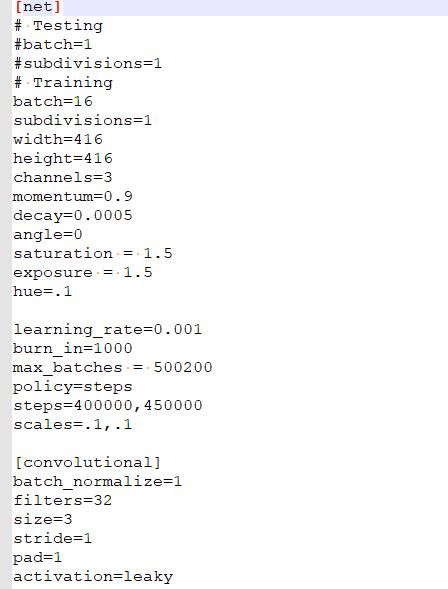
Darknet53 配置文件
- 加载预训练模型的参数 :从预训练模型开始训练
- 数据加载器配置
- 训练模型、保存模型等
- 预测
- 代码配置演练
接下来我们就开始真正配置我们的参数,实现检测自定义的数据,先展示一下整个项目的目录结构
│ detect.py│ detect_2.py # 检测代码│ models.py # 构建模型│ readme.md│ requirements.txt # 必须的依赖包│ test.py # 测试代码│ train.py # 训练代码│ ├─config # 配置文件│ coco.data│ create_custom_model.sh│ custom.data│ yolov3-tiny.cfg│ yolov3.cfg│ ├─data # 数据集│ │ coco.names│ │ get_coco_dataset.sh│ │ │ ├─custom│ │ │ 1_init.py│ │ │ 2_createID.py│ │ │ 3_trans.py│ │ │ 4_to_train_val_txt.py│ │ │ classes.names│ │ │ readme.md│ │ │ train.txt│ │ │ valid.txt│ │ │ │ │ ├─images│ │ │ train.jpg│ │ │ │ │ └─labels│ │ train.txt│ │ │ └─samples│ dog.jpg│ ├─utils # 依赖包│ │ augmentations.py│ │ datasets.py│ │ logger.py│ │ parse_config.py│ │ utils.py│ │ __init__.py│ ├─weights # 预训练权重│ download_weights.sh- 安装依赖
pip3 install -r requirements.txt # 整个项目需要的依赖包pip install terminaltables- 修改配置文件
$ cd config/ # Navigate to config dir# Will create custom model 'yolov3-custom.cfg'$ bash create_custom_model.sh # num-classes 类别数目参数- 修改数据配置文件
classes= 2 # 类别数train=data/custom/train.txtvalid=data/custom/valid.txtnames=data/custom/classes.names- 训练
# 训练命令python train.py --model_def config/yolov3-custom.cfg --data_config config/custom.data --pretrained_weights weights/darknet53.conv.74# 添加其他参数请见 train.py 文件# 从中断的地方开始训练python train.py --model_def config/yolov3-custom.cfg --data_config config/custom.data --pretrained_weights checkpoints/yolov3_ckpt_299.pth --epoch - 测试
# 测试:python detect_2.py --image_folder data/samples/ --weights_path checkpoints/yolov3_ckpt_25.pth --model_def config/yolov3-custom.cfg --class_path data/custom/classes.names以上就是整个项目的架构思路,如果你还看不懂,没关系,贴心的我为你们准备了详细的文档说明,并在部分代码处加了详细的解释
本项目已经开源在: https://github.com/FLyingLSJ/Computer_Vision_Project/tree/master/Object_Detection/yolo_demo/PyTorch-YOLOv3-master
训练步骤文档:
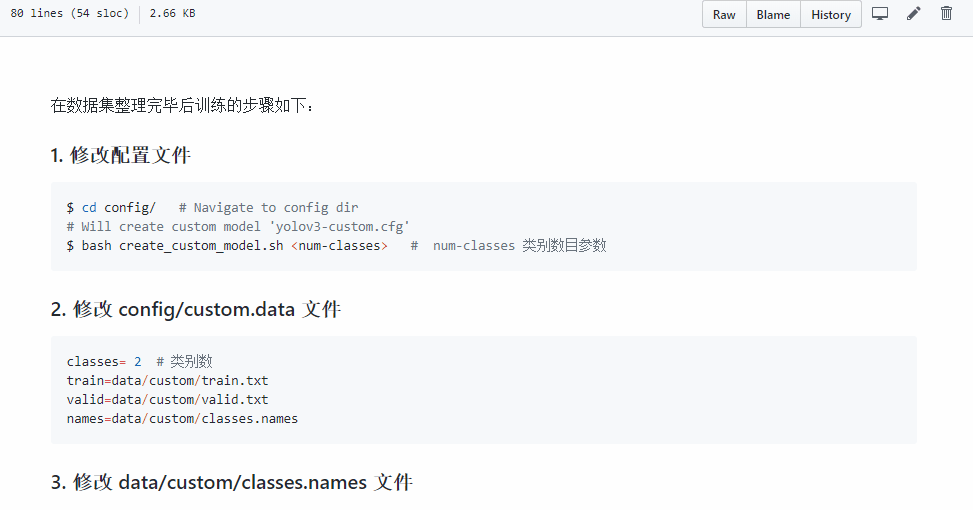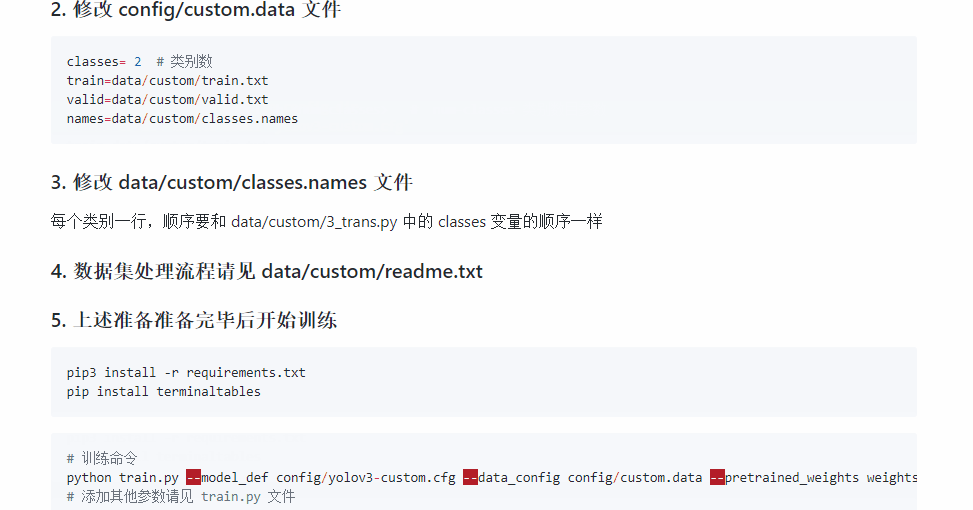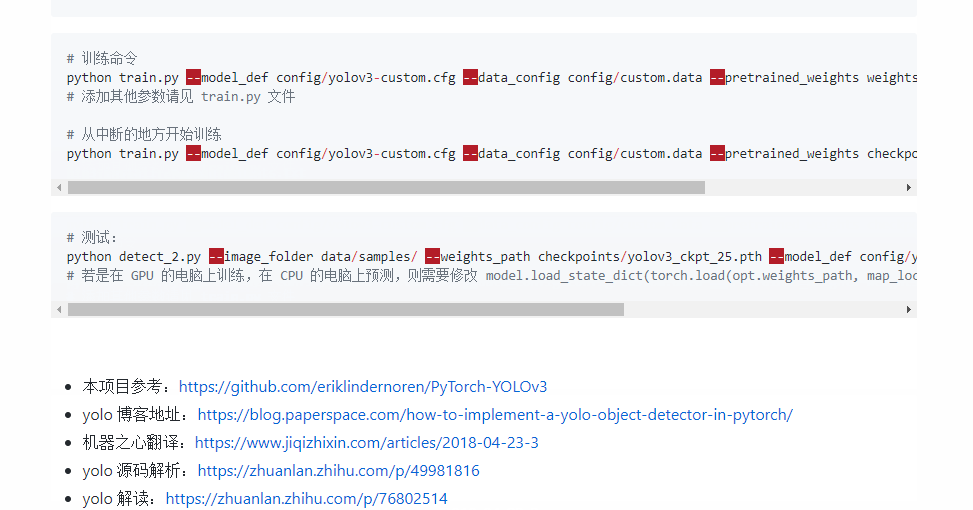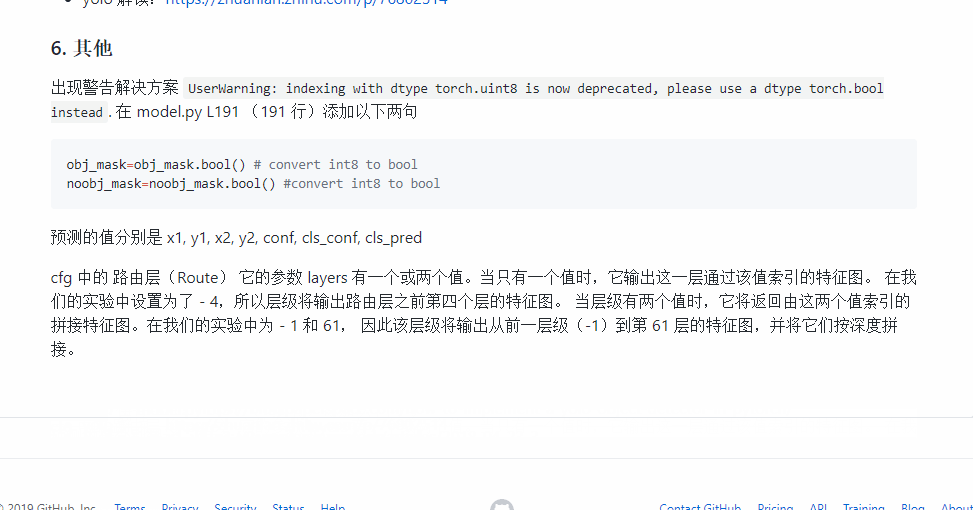
训练步骤文档
数据集准备步骤文档
数据集准备步骤文档
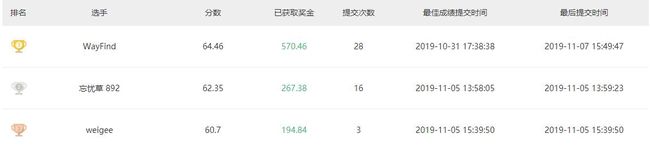
以下是该代码在某数据竞赛平台获得的成绩,该比赛是对是否有戴安全帽进行检测,其中有些数据是在教室进行采集的,以下的成绩说明,YOLO 对小目标和密集的目标检测效果并不好

本代码排名


其中前 3 名排名如下:
大佬排名
算力
以上说完两驾马车了,还有一驾算力马车,目标检测对于算力的要求相对高点,我用的是下面这台设备,用了快 9 个小时
GPU 算力
没有 GPU 算力跑不动怎么办,没关系,文末联系我,送上免费 GPU 算力
结论
没有数据怎么办?没有模型怎么办?没有算力怎么办?联系我吧~~~
参考
- https://github.com/scutan90/DeepLearning-500-questions/blob/master/
- https://blog.csdn.net/xiao_lxl/article/details/85342707 VOC 数据格式含义(生成的 txt 数据格式的含义)
- https://github.com/eriklindernoren/PyTorch-YOLOv3
- yolo 博客地址:https://blog.paperspace.com/how-to-implement-a-yolo-object-detector-in-pytorch/
- 机器之心翻译:https://www.jiqizhixin.com/articles/2018-04-23-3
- yolo 源码解析:https://zhuanlan.zhihu.com/p/49981816
- yolo 解读:https://zhuanlan.zhihu.com/p/76802514