独家 | 图片主题建模?为什么不呢?!

作者:Maarten Grootendorst
翻译:陈超
校对:赵茹萱
本文约3200字,建议阅读5分钟
本文介绍了使用图片主题进行建模。主题建模是一种允许用户在无监督情况下,在海量数据当中寻找主题的一系列技术合集、在这些文件内容当中尝试建模并跑EDA模型的时候是非常冒险的一种行为。
之前我发明了一个主题建模技术叫做BERTopic,这种技术可以利用BERT和基于类的TF-IDF来创建密集的类用于易解释主题。
一段时间之后,我开始思考它在其他领域的可解释性,比如计算机视觉。如果我们可以将其应用于图片主题建模那将是一件多么酷的事情呀!
图片主题建模,你需要做的一切。图片来自作者
这件事确实花了一些时间,但是若干实验之后,我想到了解决方法:Concept!
Concept是一个同时介绍图片和文本主题建模概念的包。然而,由于主题通常指的是文本或者口语,它通常不能很好地涵盖图片组的含义。我们这里将图片组和文字都定义为概念。

概念的logo。图片来自作者
因此,Concept包可以做Concept建模,这种建模是一种统计模型,用于在图片集合以及相应文件当中发现抽象的概念。
概念模型是图片和文本主题建模的泛化
为了让你更好地了解,以下是从概念建模当中抽取的概念:

由概念建模生成的多模态概念。图片来自作者
如同你注意到的,我们可以通过他们的文本表征和视觉表征来解释这些概念。真正的概念建模可以通过结合这些表征来提取。
概念建模允许一种概念的多模态表征
一图胜千言。但是如果我们给图片增加文字呢?两类交流方法的协同作用(synergy)可以丰富概念的解释和理解。
概念建模指南
Concept是一种利用CLIP和基于BERTopic技术来对图片和文本进行概念建模的工具。
(https://colab.research.google.com/drive/1XHwQPT2itZXu1HayvGoj60-xAXxg9mqe?usp=sharing)
在本文当中,我将带大家了解如何用Concept包构建你自己的概念模型。你可以跟随上方的Google Colab notebook链接一起学习。
第一步:安装Concept包
我们可以通过PyPI轻松安装Concept:
pip install concept第二步:准备好图片
为了进行概念建模,我们需要一些图片来聚类。我们将在UNsplash上下载25,000张图片,这些图片已经被Sentence-Transformers包整理好了。
import os |
|
import glob |
|
import zipfile |
|
from tqdm import tqdm |
|
from sentence_transformers import util |
|
# Download 25k images from Unsplash |
|
img_folder = 'photos/' |
|
if not os.path.exists(img_folder) or len(os.listdir(img_folder)) == 0: |
|
os.makedirs(img_folder, exist_ok=True) |
|
photo_filename = 'unsplash-25k-photos.zip' |
|
if not os.path.exists(photo_filename): #Download dataset if does not exist |
|
util.http_get('http://sbert.net/datasets/'+photo_filename, photo_filename) |
|
#Extract all images |
|
with zipfile.ZipFile(photo_filename, 'r') as zf: |
|
for member in tqdm(zf.infolist(), desc='Extracting'): |
|
zf.extract(member, img_folder) |
|
# Load image paths |
|
img_names = list(glob.glob('photos/*.jpg')) |
view rawload_images.py hosted with ❤ by GitHub
准备好图片之后,我们就可以在没有任何文本的情况下在Concept包中使用它。然而,这并不会构建任何文本化的表征。所以下一步是准备我们的文本。
第三步:准备好文本
Concept有趣的地方在于,任何文本都可以喂给这个模型。理想状况下,我们想把跟手边图片最相关的文本喂给模型。我们通常会对我们图片中的细节产生一些理解。
然而,事实却并不总是如此顺利。所以为了阐明目的,我们需要给模型喂英文词典当中的一堆词:
import random |
import nltk |
nltk.download("wordnet") |
from nltk.corpus import wordnet as wn |
all_nouns = [word for synset in wn.all_synsets('n') for word in synset.lemma_names() |
if "_" not in word] |
selected_nouns = random.sample(all_nouns, 50_000) |
view rawprepare_text.py hosted with ❤ by GitHub
在上述文本当中,我们以两个原因纳入了50,000个随机名词。第一,不需要将英文词典上出现的所有名词都纳入进来,因为我们可以假定50,000词应该表征了充分的实体。第二,这可以加速计算过程,因为我们需要从更少的单词当中提取嵌入。
从实践角度来看,如果你有已知与图片相关的文本数据,用他们替代名词即可。
第四步:训练模型
下一步就是训练模型啦!像通常一样,我们相对直接一点儿。只需将每个图片的路径和我们选择的名词提供给模型:
from concept import ConceptModel |
concept_model = ConceptModel() |
concepts = concept_model.fit_transform(img_names, docs=selected_nouns) |
view rawtrain_concept.py hosted with ❤ by GitHub
Concept变量包括了每幅图的预测概念。
划线的概念模型是Openai的CLIP,这是一个训练大量图片和文本对的神经网络。这意味着模型在生成嵌入时受益于使用GPU。
最后,运行concept_model.frequency来看一下包括概念频率的数据框。
注意:使用Concept(embedding_model="clip-ViT-B-32-multilingual-v1")来选择一个支持50+种语言的模型!
预训练图片嵌入
对那些想要尝试这个demo但是没有GPU使用权限的人来说,我们可以从sentence-Transformers站点来加载预训练的图像嵌入:
import pickle |
|
from sentence_transformers import util |
|
# Load pre-trained image embeddings |
|
emb_filename = 'unsplash-25k-photos-embeddings.pkl' |
|
if not os.path.exists(emb_filename): #Download dataset if does not exist |
|
util.http_get('http://sbert.net/datasets/'+emb_filename, emb_filename) |
|
with open(emb_filename, 'rb') as fIn: |
|
img_names, image_embeddings = pickle.load(fIn) |
|
img_names = [f"photos/{path}" for path in img_names] |
view rawpretrained_embeddings.py hosted with ❤ by GitHub
之后,我们将预训练的嵌入添加到模型中并训练它:
from concept import ConceptModel |
|
# Train Concept using the pre-trained image embeddings |
|
concept_model = ConceptModel() |
|
concepts = concept_model.fit_transform(img_names, |
|
image_embeddings=image_embeddings, |
|
docs=selected_nouns) |
view rawpretrained_modeling.py hosted with ❤ by GitHub
第五步:概念可视化
现在是有趣的部分,对概念进行可视化!
就像之前提到的,最终的概念是多模态的,也就是说包括了视觉和文本化双重本质。我们需要找到一种方式来从单一视角来表征两者。
为了做到这一点,我们选取了一些最能表征每个概念的一组图片,并找到最能表征这些图片的名词。
通常,我们会以如下直观方式创建可视化:
fig = concept_model.visualize_concepts() |
view rawvisualize.py hosted with ❤ by GitHub
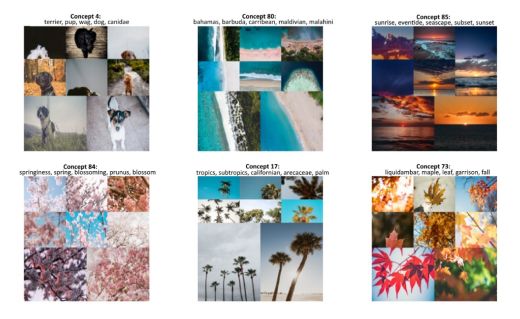
九个最常用的概念可视化。图片来自作者
我们数据集当中的大部分图片斗鱼大自然有关。然而,如果我们再深入看一看更多有趣的概念:

更常见的概念,标记概念多样性。图片来自作者
以上结果为如何在概念建模中直观地思考概念提供了一个漂亮的例子。我们不仅可以通过图片集来看可视化表征,也可以通过文本表征来帮助我们更深入地理解我们可以在这些概念当中发现的内容。
第六步:检索概念
我们可以通过嵌入一个检索术语以及发现表征类的最佳特征来快速检索特定概念。举例来看,我们检索沙滩(beach)这个术语来看看我们能找到什么。为了做到这一点,我们可以简单地运行以下代码:
>>> search_results =concept_model.find_concepts("beach") |
|
>>> search_results |
|
[(100, 0.277577825349102), |
|
(53, 0.27431058773894657), |
|
(95, 0.25973751319723837), |
|
(77, 0.2560122597417548), |
|
(97, 0.25361988261846297)] |
view rawsearch.py hosted with ❤ by GitHub
每一个元组包含两个值,第一个是概念类,另一个是检索术语相似性。返回前五个最相似的主题。
现在,让我们对概念进行可视化来看看这个检索函数是如何工作的:
|
view rawvisualize_search.py hosted with ❤ by GitHub

检索术语“beach”。图片来自作者
我们可以看到,结果概念与我们的检索术语非常相似!多模态的模型本质使得我们可以轻易地检索到概念和图片。
第七步:算法概览
对于那些对概念机制感兴趣的朋友,以下为创造结果概念的方法抽象概览:

概念算法概览。图片来自作者
1. 嵌入图片和文件
我们通过使用OpenAI的CLIP模型将图片和文件嵌入相同的向量空间开始。这允许我们在图片和文本面前比较。文件包括文字,短语,句子等。一切你觉得可以表征概念类的最佳方式。
2. 概念聚类
使用UMAP+HDBSCAN,我们可以聚类图片特征并创建视觉和语义相似的类。我们指的是那些表征多模态本质的概念类。
3. 概念表征
为了表征这些概念类,我们选取与每个概念最相关的图片,叫做范例(exemplar)。依赖于概念类的大小,每个类里范例的数量可能会超过几百,因此需要一个过滤器。
我们使用MMR来选择那些与概念特征最相关但是彼此之间仍然充分不相似的图片。这样,我们可以尽可能多地来展示这个概念。选中的图片将合称为单图来创建单个可视化表征。
4. 多模态
最后,我们提取文本特征并与创建的概念类特征进行比较。使用余弦相似性,我们选出那些最相关的特征。将多模态引入概念表征之中。
注意:使用 c-TF-IDF的 concept_model = ConceptModel(ctfidf=True) 提取文本表征也是一种选择。
感谢您的阅读!
如果你想我一样对AI,数据科学或者心理学感兴趣,请在LinkedIn
(https://www.linkedin.com/in/mgrootendorst/)
上添加我或者关注我的Twitter(https://twitter.com/MaartenGr)。
你可以在下方找到Concept包,以及它的文件:
概念建模:文本和图片主题建模(https://github.com/MaartenGr/Concept)
概念文档(https://maartengr.github.io/Concept/)
原文标题:
Topic Modeling on Images? Why Not?!
原文链接:
https://towardsdatascience.com/topic-modeling-on-images-why-not-aad331d03246
编辑:王菁
校对:杨学俊
译者简介

陈超,北京大学应用心理硕士在读。本科曾混迹于计算机专业,后又在心理学的道路上不懈求索。越来越发现数据分析和编程已然成为了两门必修的生存技能,因此在日常生活中尽一切努力更好地去接触和了解相关知识,但前路漫漫,我仍在路上。
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。

点击“阅读原文”拥抱组织