NO.61——100天机器学习实践第四天:python求解逻辑回归模型




其中,i是第几个样本,j是第几个特征

其中,alpha是步长(学习率),后边是方向
The Data
我们将建立一个逻辑回归模型来预测一个学生是否被大学录取。假设你是一个大学系的管理员,你想根据两次考试的结果来决定每个申请人的录取机会。你有以前的申请人的历史数据,你可以用它作为逻辑回归的训练集。对于每一个培训例子,你有两个考试的申请人的分数和录取决定。为了做到这一点,我们将建立一个分类模型,根据考试成绩估计入学概率。
#三大件
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
#同级目录下有个data文件夹,里边存放txt数据文件
import os
path = 'data' + os.sep + 'LogiReg_data.txt'
pdData = pd.read_csv(path, header=None, names=['Exam 1', 'Exam 2', 'Admitted'])
pdData.head()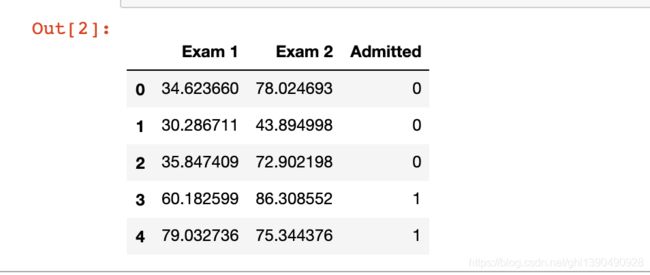

画散点图
positive = pdData[pdData['Admitted'] == 1] # returns the subset of rows such Admitted = 1, i.e. the set of *positive* examples
negative = pdData[pdData['Admitted'] == 0] # returns the subset of rows such Admitted = 0, i.e. the set of *negative* examples
fig, ax = plt.subplots(figsize=(10,5))
ax.scatter(positive['Exam 1'], positive['Exam 2'], s=30, c='b', marker='o', label='Admitted')
ax.scatter(negative['Exam 1'], negative['Exam 2'], s=30, c='r', marker='x', label='Not Admitted')
ax.legend()
ax.set_xlabel('Exam 1 Score')
ax.set_ylabel('Exam 2 Score')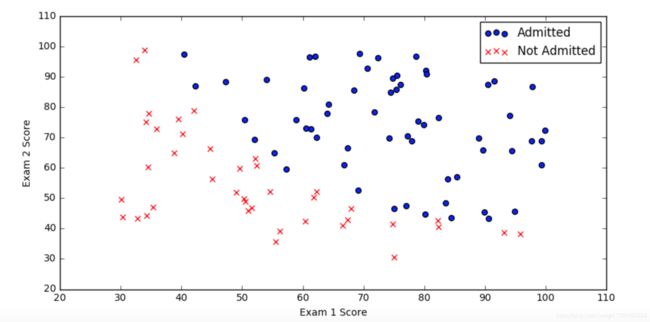
The Logistic Regression
目标:建立分类器(求解出三个参数 ![]() )
)
设定阈值,根据阈值判断录取结果
要完成的模块
-
sigmoid: 映射到概率的函数 -
model: 返回预测结果值 -
cost: 根据参数计算损失 -
gradient: 计算每个参数的梯度方向 -
descent: 进行参数更新 -
accuracy: 计算精度
sigmod函数

def sigmod(z):
ruturn 1 / (1+np.exp(-z))画图示例:
nums = np.arange(-10, 10, step=1) #creates a vector containing 20 equally spaced values from -10 to 10
fig, ax = plt.subplots(figsize=(12,4))
ax.plot(nums, sigmoid(nums), 'r')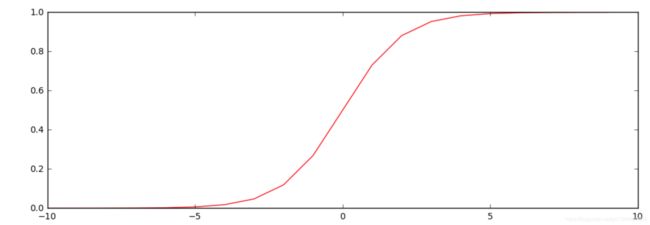
Model 预测模型

def model(X, theta):
return sigmoid(np.dot(X, theta.T))#在下标0的位置插入名称为‘ones’的列,值为1
pdData.insert(0, 'Ones', 1) # in a try / except structure so as not to return an error if the block si executed several times
# set X (training data) and y (target variable)
orig_data = pdData.as_matrix() # convert the Pandas representation of the data to an array useful for further computations
cols = orig_data.shape[1]
X = orig_data[:,0:cols-1]
y = orig_data[:,cols-1:cols]
# convert to numpy arrays and initalize the parameter array theta
#X = np.matrix(X.values)
#y = np.matrix(data.iloc[:,3:4].values) #np.array(y.values)
theta = np.zeros([1, 3])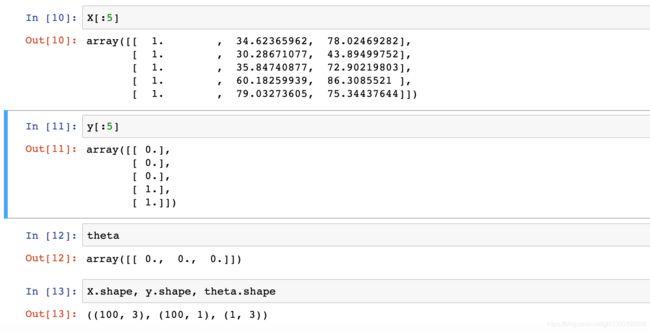
损失函数

def cost(X, y, theta):
left = np.multiply(-y, np.log(model(X, theta)))
right = np.multiply(1 - y, np.log(1 - model(X, theta)))
return np.sum(left - right) / (len(X))
计算梯度
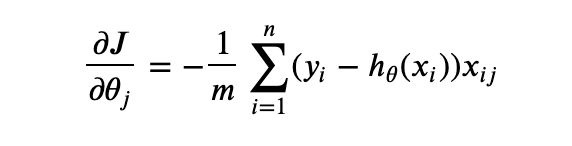
def gradient(X, y, theta):
grad = np.zeros(theta.shape)
error = (model(X, theta)- y).ravel() #转化为一维数组
for j in range(len(theta.ravel())): #for each parmeter
term = np.multiply(error, X[:,j])
grad[0, j] = np.sum(term) / len(X)
return gradGradient descent 梯度更新
比较3中不同梯度下降方法
STOP_ITER = 0
STOP_COST = 1
STOP_GRAD = 2
def stopCriterion(type, value, threshold):
#设定三种不同的停止策略
if type == STOP_ITER: return value > threshold
elif type == STOP_COST: return abs(value[-1]-value[-2]) < threshold
elif type == STOP_GRAD: return np.linalg.norm(value) < thresholdimport numpy.random
#洗牌
def shuffleData(data):
np.random.shuffle(data)
cols = data.shape[1]
X = data[:, 0:cols-1]
y = data[:, cols-1:]
return X, yimport time
def descent(data, theta, batchSize, stopType, thresh, alpha):
#梯度下降求解
init_time = time.time()
i = 0 # 迭代次数
k = 0 # batch
X, y = shuffleData(data)
grad = np.zeros(theta.shape) # 计算的梯度
costs = [cost(X, y, theta)] # 损失值
while True:
grad = gradient(X[k:k+batchSize], y[k:k+batchSize], theta)
k += batchSize #取batch数量个数据,即一次训练选取的样本数
if k >= n:
k = 0
X, y = shuffleData(data) #重新洗牌
theta = theta - alpha*grad # 参数更新
costs.append(cost(X, y, theta)) # 计算新的损失
i += 1
if stopType == STOP_ITER: value = i
elif stopType == STOP_COST: value = costs
elif stopType == STOP_GRAD: value = grad
if stopCriterion(stopType, value, thresh): break
return theta, i-1, costs, grad, time.time() - init_timedef runExpe(data, theta, batchSize, stopType, thresh, alpha):
#import pdb; pdb.set_trace();
theta, iter, costs, grad, dur = descent(data, theta, batchSize, stopType, thresh, alpha)
name = "Original" if (data[:,1]>2).sum() > 1 else "Scaled"
name += " data - learning rate: {} - ".format(alpha)
if batchSize==n: strDescType = "Gradient"
elif batchSize==1: strDescType = "Stochastic"
else: strDescType = "Mini-batch ({})".format(batchSize)
name += strDescType + " descent - Stop: "
if stopType == STOP_ITER: strStop = "{} iterations".format(thresh)
elif stopType == STOP_COST: strStop = "costs change < {}".format(thresh)
else: strStop = "gradient norm < {}".format(thresh)
name += strStop
print ("***{}\nTheta: {} - Iter: {} - Last cost: {:03.2f} - Duration: {:03.2f}s".format(
name, theta, iter, costs[-1], dur))
fig, ax = plt.subplots(figsize=(12,4))
ax.plot(np.arange(len(costs)), costs, 'r')
ax.set_xlabel('Iterations')
ax.set_ylabel('Cost')
ax.set_title(name.upper() + ' - Error vs. Iteration')
return theta不同的停止策略
设置不同的迭代次数
#选择的梯度下降方法是基于所有样本的
n=100
runExpe(orig_data, theta, n, STOP_ITER, thresh=5000, alpha=0.000001)
梯度损失值停止
设定阈值 1E-6, 差不多需要110 000次迭代
runExpe(orig_data, theta, n, STOP_COST, thresh=0.000001, alpha=0.001)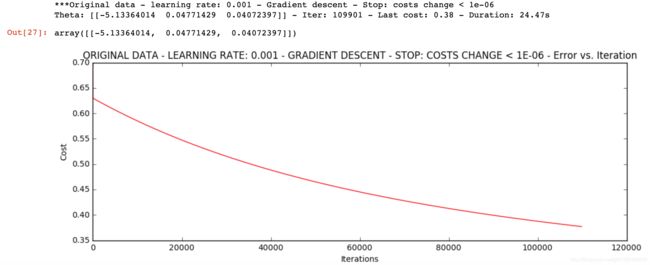
根据梯度变化停止
设定阈值 0.05,差不多需要40 000次迭代
runExpe(orig_data, theta, n, STOP_GRAD, thresh=0.05, alpha=0.001)
对比不同的梯度下降方法
stochastic descent 随机下降
runExpe(orig_data, theta, 1, STOP_ITER, thresh=5000, alpha=0.001)
有点爆炸。。。很不稳定,再来试试把学习率调小一些
runExpe(orig_data, theta, 1, STOP_ITER, thresh=15000, alpha=0.000002)
速度快,但稳定性差,需要很小的学习率
Mini-batch descent
runExpe(orig_data, theta, 16, STOP_ITER, thresh=15000, alpha=0.001)
浮动仍然比较大,我们来尝试下对数据进行标准化 将数据按其属性(按列进行)减去其均值,然后除以其方差。最后得到的结果是,对每个属性/每列来说所有数据都聚集在0附近,方差值为1
from sklearn import preprocessing as pp
scaled_data = orig_data.copy()
scaled_data[:, 1:3] = pp.scale(orig_data[:, 1:3]) #左闭右开
runExpe(scaled_data, theta, n, STOP_ITER, thresh=5000, alpha=0.001)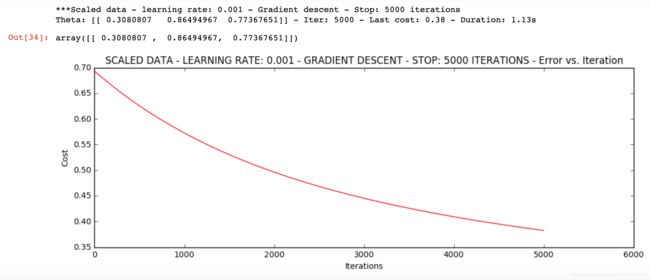
它好多了!原始数据,只能达到达到0.61,而我们得到了0.38个在这里! 所以对数据做预处理是非常重要的

更多的迭代次数会使得损失下降的更多!

随机梯度下降更快,但是我们需要迭代的次数也需要更多,所以还是用batch的比较合适!!!

精度
#设定阈值
def predict(X, theta):
return [1 if x >= 0.5 else 0 for x in model(X, theta)]scaled_X = scaled_data[:, :3]
y = scaled_data[:, 3]
predictions = predict(scaled_X, theta)
correct = [1 if ((a == 1 and b == 1) or (a == 0 and b == 0)) else 0 for (a, b) in zip(predictions, y)] #并行遍历
#map() 会根据提供的函数对指定序列做映射。第一个参数 function 以参数序列中的每一个元素调用 function 函数,返回包含每次 function 函数返回值的新列表。
accuracy = (sum(map(int, correct)) % len(correct))
print ('accuracy = {0}%'.format(accuracy))accuracy = 89%