李宏毅机器学习-explainable machine learning(机器学习的可解释性)及代码
目录
为什么需要机器学习的可解释性?
Interpretable VS Powerful
什么叫做好的 Explanation
explainable ML的分类
Local Explanation(局部可解释性)
哪个元件最重要
遮挡实验
Saliency Map
改进Saliency Map——noisy gradient与SmoothGrad
Saliency Map局限性:gradient saturation(梯度饱和)
网络如何处理输入数据
visualization(可视化)
probing(探针)
global explanation(全局可解释性)
filter是怎么检测的
检测的基本思想
用数学语言描述机器创造图片的过程
以数字辨识Mnist为例
利用Generator加上限制
Explainable AI 技术的弊端
Local Interpretable Model-Agnostic Explanations (LIME)
为什么需要机器学习的可解释性?
1、我们需要知道机器做决策的背后理由,否则谁敢真正应用于实际,例如
- 银行判断要不要贷款给某一个客户,但是根据法律的规定,银行作用机器学习模型来做自动的判断,它必须要给出一个理由
- 机器学习未来也会被用在医疗诊断上,但医疗诊断人命关天的事情,需要给出诊断的理由
- 机器学习的模型帮助法官判案,帮助法官自动判案说,一个犯人能不能够被假释,
- 自驾车突然急剎的时候需要了解它急剎的理由
这些都直接作用于人类,搞清楚能决策成功的原因很重要。
2、我们可以通过这个解释性来修正我们的模型,提升模型的性能。
Interpretable VS Powerful
有一些模型在本质上是可以解释的,例如线性模型(从权重能知道特征的占比重要性),但是效果却并不厉害。深度神经网络很难解释其操作机制,因为它是黑箱,但是他却比线性模型的效果更好,我们应该努力去研究其机制的可解释性,而不是逃避黑箱模型。
那有没有一种模型同时具有可解释性和强劲力呢?决策树,一棵树能同时具备上述两个要素。决策树有很多的节点,每一个节点都会问一个问题,让你决定向左还是向右,最终当你走到 Leaf Node 的时候就可以做出最终的决定,因為在每一个节点都有一个问题,看那些问题以及答案就可以知道整个模型是如何做出最终的决断。但是在实际训练中,我们往往会用到很多棵树,这种情况也很难解释其机制。
什么叫做好的 Explanation
做机器学习的可解释性,做到什么程度?我们其实没有那麼在乎网络是怎么运行的,只要做出来的解释性是能够让人认同就行。其实对人而言,也许一个东西能不能让我们放心,能不能够让我们接受,理由是非常重要的。

好的 Explanation就是人能接受的 Explanation,人就是需要一个理由让我们觉得高兴,而到底是让谁高兴呢

explainable ML的分类
分为局部可解释性和全局可解释性,局部可解释性是针对一个特定的输入进行回答,为什么这张图片就是一只猫呢。全局可解释性是根据模型参数本身分析原因,不涉及某一具体的图片,对一个 Classifier 而言,什么样的图片叫做猫,一隻猫长什麼样子?
Local Explanation(局部可解释性)
哪个元件最重要
给机器一张图片,它知道它是一只,到底是这个图片裡面的什么东西让模型觉得它是一只猫
判删除或者修改某一component,如果网络的输出发生了巨大的改变,影响最后决策结果,那么这个元件就是很重要的。

遮挡实验
研究一个影像裡面每一个区域的重要性的时候,在这个图片裡面不同的位置放上灰色的方块,当这个方块放在不同的地方的时候,Network 会 Output 不同的结果。下图灰色方块放在“红色区域”时,对输出结果影响较小,输出原类别的概率高,放在“蓝色区域”时影响较大,输出原类别的概率低。
最右边的图,机器到底是真的看到了阿富汗猎犬,还是把人误认為狗呢,可以把这个灰色的方框在这个图片上移动,然后发现这个灰色的方框放在人的脸上的时候,机器仍然觉得它有看到阿富汗猎犬,但是当你把灰色的方框放到这个位置的时候,机器就觉得它没有看到阿富汗猎犬,所以它是真的知道这一只就是阿富汗猎犬,并不是把人误认為阿富汗猎犬。
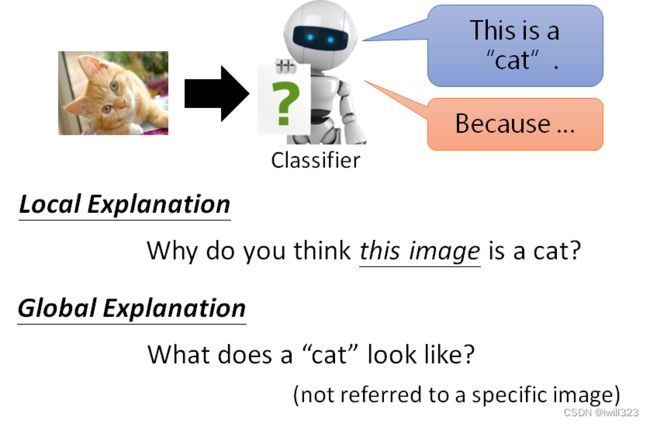
Saliency Map
Loss对图片的每个像素求导,根据导数的绝对值大小来判断像素的重要性。saliency map(显著图)中的白点越白,代表导数的值越大,该处的像素点对决策越重要。
举例来说,给机器看这个水牛的图片,并不是看到草地,也不是看到竹子,而是真的知道牛在这个位置,所以才会 Output 牛这个答案
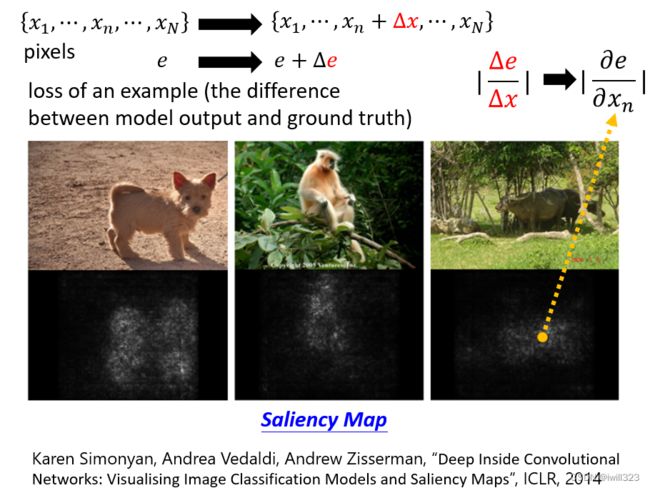
一个真实的例子,有一个 Benchmark Corpus,叫做 PASCAL VOC 2007,裡面有各式各样的物件,机器要学习做影像的分类,机器看到这张图片,它知道是马的图片,但如果你画 Saliency Map 的话,发现左下角对马是最重要,因為左下角有一串英文,这个图库裡面马的图片很多都是来自於某一个网站,左下角都有一样的英文,所以机器看到左下角这一行英文就知道是马,根本不需要学习马是长什么样子
def normalize(image):
return (image - image.min()) / (image.max() - image.min())
# return torch.log(image)/torch.log(image.max())
def compute_saliency_maps(x, y, model):
model.eval()
x,y = x.cuda(), y.cuda()
# we want the gradient of the input x
x.requires_grad_()
y_pred = model(x)
criterion = torch.nn.CrossEntropyLoss()
loss = criterion(y_pred, y)
loss.backward()
# saliencies = x.grad.abs().detach().cpu()
saliencies, _ = torch.max(x.grad.data.abs().detach().cpu(),dim=1)
# x shape:[10, 3, 128, 128] saliencies.shape:[10, 3, 128, 128]
# We need to normalize each image, because their gradients might vary in scale
saliencies = torch.stack([normalize(item) for item in saliencies])
return saliencies
# images, labels = train_set.getbatch(img_indices)
saliencies = compute_saliency_maps(images, labels, model)
# visualize
fig, axs = plt.subplots(2, len(img_indices), figsize=(15, 8))
for row, target in enumerate([images, saliencies]):
for column, img in enumerate(target):
if row==0:
axs[row][column].imshow(img.permute(1, 2, 0).numpy()) # 将pytorch的图片格式(channels, height, width)变为matplotlib图片格式(height, width, channels)
else:
axs[row][column].imshow(img.numpy(), cmap=plt.cm.hot) # img是单通道
plt.show()
plt.close() 
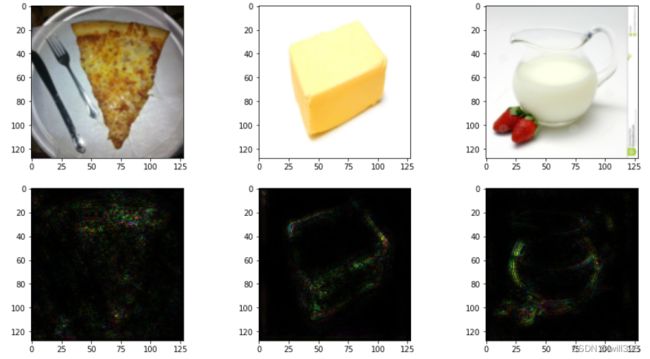
loss关于x在每个通道上都有梯度,上面的做法是在3个通道中取最大值,最终得到的是单通道图像。如果将3个通道上的梯度都保留,即saliencies = x.grad.abs().detach().cpu(),那么得到的是3通道图像,结果如下图
改进Saliency Map——noisy gradient与SmoothGrad
Saliency Map会存在杂讯梯度的问题,在未经处理的显著图(下图中间)中,白点分布杂乱无章看不出规律,通过smoothGrad方法后才减少了杂讯,这样的结果往往能够更加“集中”在被侦测的物体上。
smoothGrad:给输入的图片随机加入noise得到一系列的图片,对每个图片算saliency map后作平均,得到一個比較能抵抗 noisy gradient 的結果,这样就知道哪些像素点才是真正的决策因素了。

# Smooth grad
def normalize(image):
return (image - image.min()) / (image.max() - image.min())
def smooth_grad(x, y, model, epoch, param_sigma_multiplier):
model.eval()
#x = x.cuda().unsqueeze(0)
mean = 0
sigma = param_sigma_multiplier / (torch.max(x) - torch.min(x)).item()
smooth = np.zeros(x.cuda().unsqueeze(0).size())
for i in range(epoch):
noise = x.data.new(x.size()).normal_(mean, sigma**2)
x_mod = (x+noise).unsqueeze(0).cuda()
x_mod.requires_grad_()
y_pred = model(x_mod)
loss_func = torch.nn.CrossEntropyLoss()
loss = loss_func(y_pred, y.cuda().unsqueeze(0))
loss.backward()
# like the method in saliency map
smooth += x_mod.grad.abs().detach().cpu().data.numpy()
smooth = normalize(smooth / epoch) # don't forget to normalize
# smooth = smooth / epoch # try this line to answer the question
return smooth # (1, 3, 128, 128)
# images, labels = train_set.getbatch(img_indices)
smooth = []
for i, l in zip(images, labels):
smooth.append(smooth_grad(i, l, model, 500, 0.4))
smooth = np.stack(smooth)
#print(smooth.shape) (10, 1, 3, 128, 128)
fig, axs = plt.subplots(2, len(img_indices), figsize=(15, 8))
for row, target in enumerate([images, smooth]):
for column, img in enumerate(target):
axs[row][column].imshow(np.transpose(img.reshape(3,128,128), (1,2,0))) 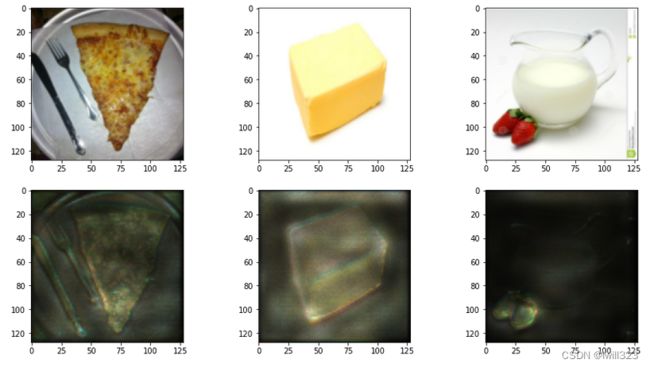
看起来结果更好了些
Saliency Map局限性:gradient saturation(梯度饱和)
光看偏微分gradient不一定能看出component的重要性。例如在下图中,横轴代表的是某一个生物鼻子的长度,纵轴代表说这个生物是大象的可能性。大象的特徵就是长鼻子,一个生物在鼻子长度比较短的时候,随著鼻子长度越来越长,是大象的可能性越来越大,但是当鼻子的长度长到一个程度以后,就算是更长也不会变得更像大象。
蓝点处鼻子长度的变化对判断大象几乎没有影响了,也就是此时偏微分为零,光看 Saliency Map可能得到错误结论:鼻子的长度对是不是大象这件事情是不重要的。所以不仅要考虑偏微分,要考虑Integrated Gradient,具体参考下面论文。可解释性之积分梯度算法(Integrated Gradients) - 知乎

IG是在图片和空白图片之间做线性插值产生多个图片,然后通过图片的模型输出对图片求导(saliency map是loss函数求导,这两者的求导函数不一样),最后将导数的结果进行平均加权。
class IntegratedGradients():
def __init__(self, model):
self.model = model
self.gradients = None
# Put model in evaluation mode
self.model.eval()
def generate_images_on_linear_path(self, input_image, steps):
# Generate scaled xbar images
xbar_list = [input_image*step/steps for step in range(steps)]
return xbar_list
def generate_gradients(self, input_image, target_class):
# We want to get the gradients of the input image
input_image.requires_grad=True
model_output = self.model(input_image)
self.model.zero_grad()
# Target for backprop
one_hot_output = torch.FloatTensor(1, model_output.size()[-1]).zero_().cuda()
one_hot_output[0][target_class] = 1
# Backward
model_output.backward(gradient=one_hot_output) # model_output不是标量,求梯度需要传递参数进去
self.gradients = input_image.grad
# Convert Pytorch variable to numpy array, [0] to get rid of the first channel (1,3,128,128)
gradients_as_arr = self.gradients.data.cpu().numpy()[0]
return gradients_as_arr
def generate_integrated_gradients(self, input_image, target_class, steps):
# Generate xbar images 得到线性差值的图像
xbar_list = self.generate_images_on_linear_path(input_image, steps)
# Initialize an image composed of zeros
integrated_grads = np.zeros(input_image.size())
for xbar_image in xbar_list:
# Generate gradients from xbar images
single_integrated_grad = self.generate_gradients(xbar_image, target_class)
# Add rescaled grads from xbar images
integrated_grads += single_integrated_grad/steps
# [0] to get rid of the first channel (1,3,128,128)
return integrated_grads[0]
def normalize(image):
return (image - image.min()) / (image.max() - image.min())
# put the image to cuda
images = images.cuda()
IG = IntegratedGradients(model)
integrated_grads = []
for i, img in enumerate(images):
img = img.unsqueeze(0)
integrated_grads.append(IG.generate_integrated_gradients(img, labels[i], 10)) # 10是插值得到的图片数量
fig, axs = plt.subplots(2, len(img_indices), figsize=(15, 8))
for i, img in enumerate(images):
axs[0][i].imshow(img.cpu().permute(1, 2, 0))
for i, img in enumerate(integrated_grads):
axs[1][i].imshow(np.moveaxis(normalize(img),0,-1))
plt.show()
plt.close()效果图对比图如下,看起来效果一般,优点是形状勾勒的还可以。

网络如何处理输入数据
既然是找寻网络的可解释性,那么就要知道网络的隐藏层到底发生了什么,要知道每经过一层网络之后的结果是什么。
visualization(可视化)
对于语音识别问题,将隐藏层的输出抽出来,并将其维度降低,例如将100维的输出向量转成2维的向量,然后用2维向量生成图片或者图表。

资料中有很多句子是重复的,比如A、B 、C三人分别说了 How are you。第一张图是直接用输入内容降到二维,画在二维的平面上,每一个点代表一小段声音讯号,每一个顏色代表某一个讲话的人,杂乱无章;第二张图是用中间隐藏层的输出做出的图表,每一条纹代表同样内容的某一个句子,不同颜色代表不同的语者,可以发现不同语者说类似的话会被聚拢到空间中的接近位置,所以最后就可以得到精确的分类结果

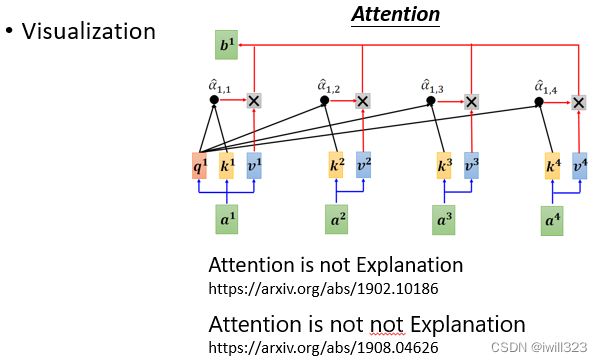
probing(探针)
- 对BERT进行探测:
分类器作为探针,将隐藏层的输出放到分类器中(例如词性分类POS、地理人名分类NER),从而就知道每一层是在分离什么资讯。假如第一层输出在词性分类的准确率高,那么证明第一层主要用于处理词性了。
但是这个方法的结论不一定适用,因为可能我们的分类器性能本身就低,正确率很低不是因為这些 Feature 裡面没有我们需要的资讯,单纯就是Learning Rate 没有调好,训练不起来。所以用 Probing Model 的时候不要太快下结论,可能 Classifier 没有 Train好,导致Classifier 的正确率没有办法当做评断的依据

- 对于语音转文字模型进行探测:
输入一段语音,从隐藏层中抽取输出,输入到TTS 的模型裡面,用这个TTS 的模型復现原来的声音讯号。假如这段输出合成的语音不包含语者资讯(机器人声音),那么就证明在训练过程中抹去了语者资讯,只保留语音内容。
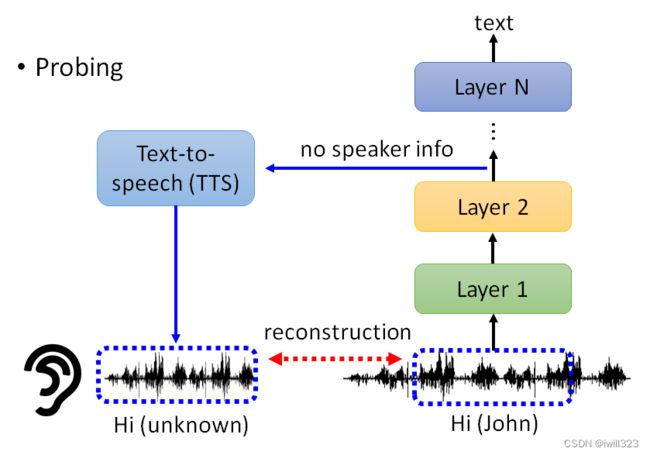
global explanation(全局可解释性)
filter是怎么检测的
想要知道某一個 filter 到底認出了什麼。我們會做以下兩件事情:
- Filter activation: 观察图片的哪些位置会activate该filter
- Filter visualization: 什么样的图片能最大程度的activate该filter
检测的基本思想
思路:机器创造图片,让其包含filter 1要检测的pattern,藉由看这张图片裡面的内容,就可以知道 filter 1负责检测什麼样的东西。
对于一张未知的图片,输入卷积神经网络后,隐藏层每个filter对应一个feature map。filter 1的 feature map值越大,说明输入的图片 X中满足filter 1所侦测的pattern的部分越多,由此可以将filter侦测的pattern可视化。
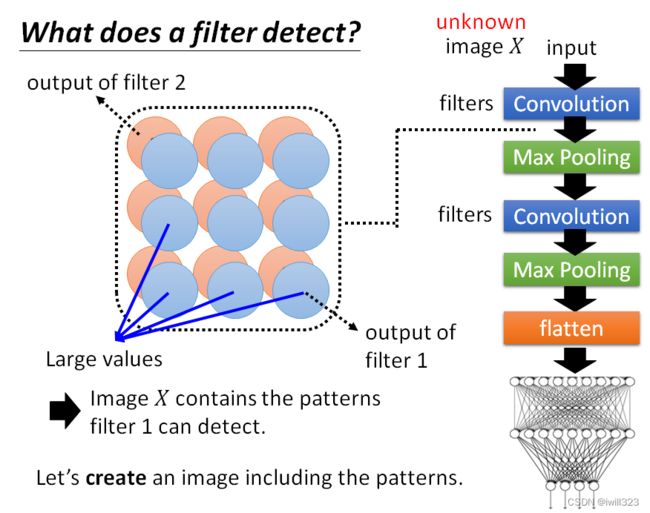
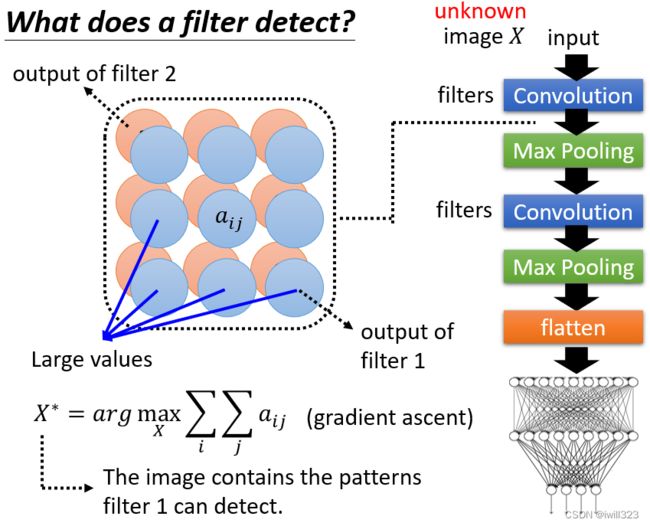
用数学语言描述机器创造图片的过程
特征图中每一个元素的值表示为aij,将输入图片X作为一个要训练的未知参数,找一个X让aij的总和越大越好, 用X*来表示,这个 X* 就会包含filter能侦测的pattern。用梯度上升Gradient ascent的方法。
以数字辨识Mnist为例
下图是第二层每一个 Filter 对应的X*,找出来的特征是一些基本的笔画。
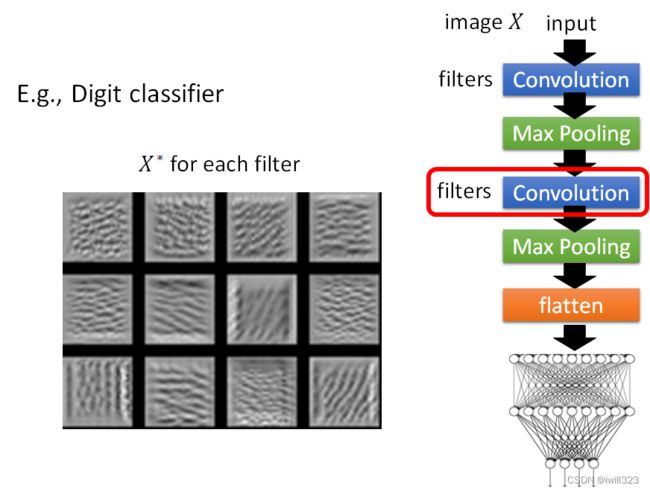
看最终这个 Image Classifier 的输出,找一张图片 X使某一个类别的分数越高越好。当输出为0~8时,找到的 X 看起来都是杂讯,根本没有办法看到数字,和Adversarial Attack对抗攻击的杂讯一样。

为了改善上图,让找到的 X 能够看起来像数字,给函数 X*加上一项R(X),这一项是用来衡量 X 有多像数字,一个数字的笔画就是几画,可以把这件事情当做一个限制,希望白色的点越少越好,最后找到的结果还是有点数字的影子。

用Global Explanation的方法去反推一个 Image classifier心中的某种动物长什麼样子。要得到这样子的图片必须要根据你对影像的了解下非常多的限制,再加上一大堆的 Hyperparameter Tuning
在训练模型的时候,大多数情况下会一train到底,所以想要获取模型中间某层所观察到的内容比较困难,但是Pytorch提供了hook方法,能够轻松的获取模型中间的层数,并且观察到CNN网络中间所观察到的输出内容。hook函数会自动保存模型中的某一层,使用完再将其移出即可。
def normalize(image):
return (image - image.min()) / (image.max() - image.min())
layer_activations = None
def filter_explanation(x, model, cnnid, filterid, iteration=100, lr=1):
# x: input image cnnid: cnn layer id filterid: which filter
model.eval()
x = x.cuda()
def hook(model, input, output):
global layer_activations
layer_activations = output
hook_handle = model.cnn[cnnid].register_forward_hook(hook)
# When the model forwards through the layer[cnnid], it needs to call the hook function first
# The hook function save the output of the layer[cnnid]
# After forwarding, we'll have the loss and the layer activation
# Filter activation: x passing the filter will generate the activation map
model(x) # forward # 通过这一步获得layer_activations
filter_activations = layer_activations[:, filterid, :, :].detach().cpu()
# Filter visualization: find the image that can activate the filter the most
x.requires_grad_()
optimizer = torch.optim.Adam([x], lr=lr)
for iter in range(iteration):
model(x)
objective = -layer_activations[:, filterid, :, :].sum() # 负号代表梯度上升
optimizer.zero_grad()
objective.backward() # 计算filter activation 对输入图片的偏微分
optimizer.step() # Modify input image to maximize filter activation
filter_visualizations = x.detach().cpu().squeeze()
# Don't forget to remove the hook
hook_handle.remove()
# The hook will exist after the model register it, so you have to remove it after used
# Just register a new hook if you want to use it
return filter_activations, filter_visualizations
filter_activations, filter_visualizations = filter_explanation(images, model, cnnid=6, filterid=0, iteration=900, lr=0.1)
fig, axs = plt.subplots(3, len(img_indices), figsize=(15, 8))
for i, img in enumerate(images):
axs[0][i].imshow(img.permute(1, 2, 0))
# Plot filter activations
for i, img in enumerate(filter_activations):
axs[1][i].imshow(normalize(img))
# Plot filter visualization
for i, img in enumerate(filter_visualizations):
axs[2][i].imshow(normalize(img.permute(1, 2, 0)))
plt.show()
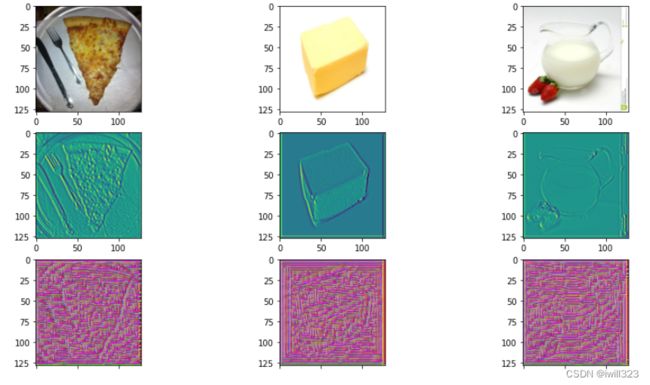
plt.close()下面两图是模型第6层(一个卷积层)第0个filter的activation图和visualization图,visualization图的初始是从原图开始的,所以效果看起来还不错,在其他书本里面,初始化可能是从空白图开始的,最终看到的图类似于有规律的杂讯,注意这个区别。
利用Generator加上限制
上面通过神经网络的结果来找 X很难找出像样的 X ,所以我们改变策略,将找像样的 X改为找像样的低维向量。
先用 GAN或 VAE等训练出一个Image Generator,输入是一个从高斯分布裡面Sample 出来的低维度的向量 z,输出是一张图片 X。将 X 放入classifier,输出分类的结果。目标是找一个 z*,让某一个类别yi的分数越大越好。把z*丢到Generator 裡面,查看生成的图片X*。
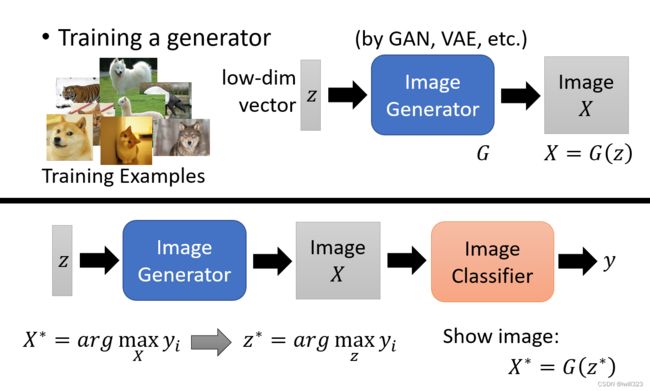
结果如下,可以发现结果非常好。感觉这种做法有点牵强,训练集里的蚂蚁或火山图片能让网络的对应分类得分最高,那么我们用generator产生的让对应分类得分最高的图像,当然就是蚂蚁或火山图片,这样做真的能解释神经网络在干什么,而不是类似于将一句话换一种说法又说了一遍?

Explainable AI 技术的弊端
今天找出来的图片如果跟你想像的东西不一样,你就说这个 Explanation 的方法不好,然后硬是要弄一些方法去找出来那个图片,跟人想像的是一样的,才会说这个 Explanation 的方法是好的。也许对机器来说,它看到的图片就是像是一些杂讯一样,也许它心裡想像的某一个数字就是像是那
些杂讯一样,那我们却不愿意认同这个事实,而是硬要想一些方法让机器產生出看起来比较像样的图片。今天 Explainable AI 的技术往往就是有这个特性,我们其实没有那麼在乎机器真正想的是什麼,其实我们不知道机器真正想的是什麼,而是希望有些方法解读出来的东西是人看起来觉得很开心的,然后你就说机器想的应该就是这个样子,然后你的老闆、你的客户听了就会觉得很开心,今天 Explainable AI 往往会有这样的倾向。
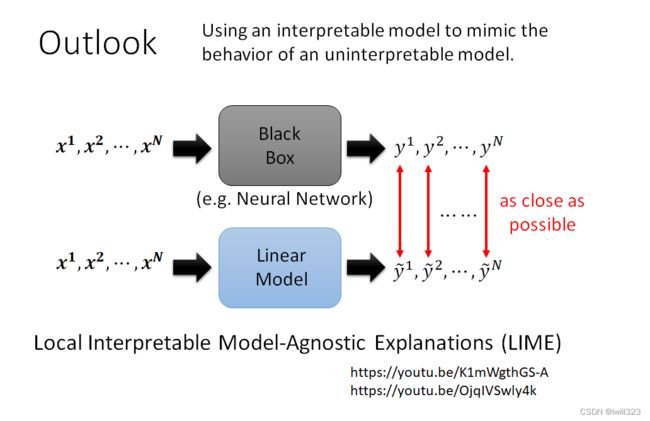
Local Interpretable Model-Agnostic Explanations (LIME)
用简单模型来模仿复杂model的行为,再分析简单模型,这样就知道复杂model的行为在干嘛了。并不是让简单模型去模仿黑箱的全部行为,而是让简单模型模仿黑箱中一小块区域的行为,解读那一小个区域裡面发生的事情。https://arxiv.org/pdf/1711.06178.pdf
先训练一个分类器,模型的输入为切块的图片,将其训练为输出与CNN模型类似,然后通过线性模型的权重来判断图片的哪一个位置比较重要。
针对图像数据的分类解释,主要包括以下几个主要的函数:explain_instance(image,classifier_fn,segmentation_fn),get_image_and_mask(label,num_features)
第一个函数是核心函数,输入是要解释的图像,分类器以及语义分割的函数,其中语义分割函数需要自定义,然后通过第二个函数把需要解释的图像进行一个可视化的表示
def predict(input):
# input: numpy array, (batches, height, width, channels)
model.eval()
input = torch.FloatTensor(input).permute(0, 3, 1, 2)
# pytorch tensor, (batches, channels, height, width)
output = model(input.to(devices[0]))
return output.detach().cpu().numpy()
def segmentation(input):
# split the image into 200 pieces with the help of segmentaion from skimage
return slic(input, n_segments=200, compactness=1, sigma=1, start_label=1)
img_indices = [i for i in range(10)]
fig, axs = plt.subplots(1, len(img_indices), figsize=(15, 8))
# fix the random seed to make it reproducible
np.random.seed(16)
for idx, (image, label) in enumerate(zip(images.permute(0, 2, 3, 1).numpy(), labels)):
x = image.astype(np.double)
# numpy array for lime
explainer = lime_image.LimeImageExplainer()
explaination = explainer.explain_instance(image=x, classifier_fn=predict, segmentation_fn=segmentation)
# doc: https://lime-ml.readthedocs.io/en/latest/lime.html?highlight=explain_instance#lime.lime_image.LimeImageExplainer.explain_instance
lime_img, mask = explaination.get_image_and_mask(
label=label.item(),
positive_only=False,
hide_rest=False,
num_features=11,
min_weight=0.05
)
# turn the result from explainer to the image
# doc: https://lime-ml.readthedocs.io/en/latest/lime.html?highlight=get_image_and_mask#lime.lime_image.ImageExplanation.get_image_and_mask
axs[idx].imshow(lime_img)
plt.show()
plt.close()LIME训练后效果图如下,食物的位置确实是被标记了,不过标记的并不全。

针对文本的分类任务的解释,主要使用的只有一个函数:lime_text.LimeTextExplainer(class_names).explain_instance(text_instance,num_features)。
两者可视化的方式不同,文本不能够像图像一样可以直接进行可视化的操作,所以需要借助柱状图来进行一个可视化的解释,如下所示:

参考:李宏毅机器学习笔记07 恶意攻击和可解释性 - 知乎
李宏毅2022机器学习HW9解析_机器学习手艺人的博客-CSDN博客
Explainable AI(可解释性AI) - 知乎