机器学习100天练习(4)-逻辑回归
机器学习100天练习(4)-逻辑回归
逻辑回归讲解
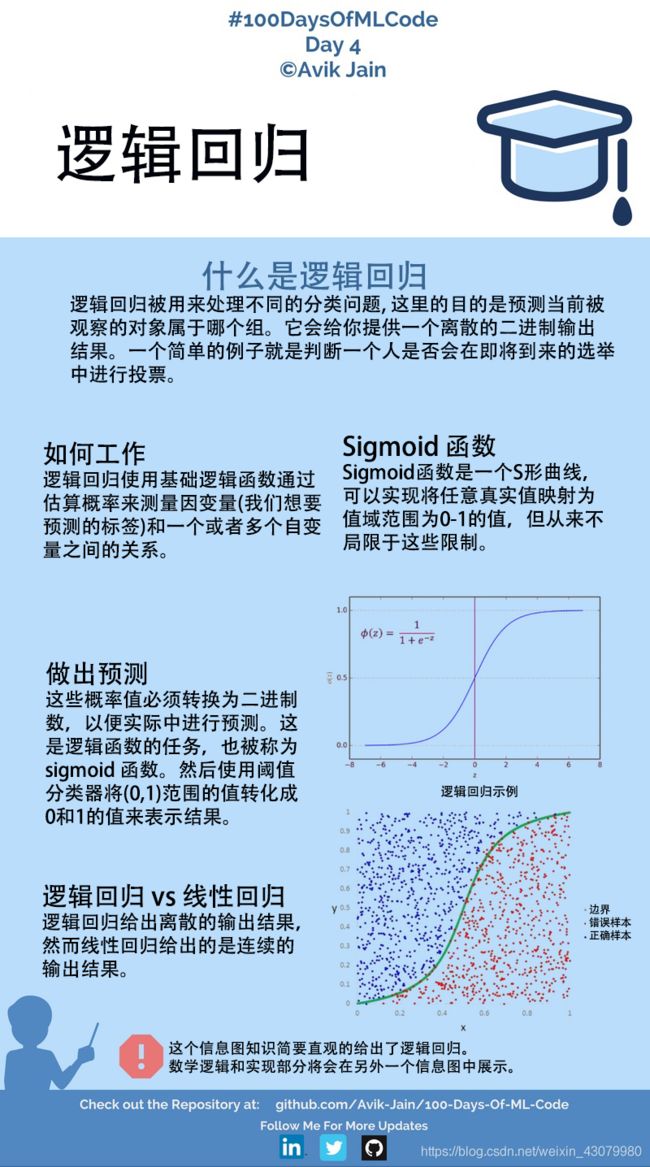

模型
输出为 0 或 1
假设 => y = Wx + b
hΘ(x) = sigmoid (Z)
Sigmoid 函数
本质是将数据拟合到线性回归模型中,然后用logistic函数预测目标分类因变量。
该数据集包含了社交网络中用户的信息。这些信息涉及用户ID,性别,年龄以及预估薪资。一家汽车公司刚刚推出了他们新型的豪华SUV,我们尝试预测哪些用户会购买这种全新SUV。并且在最后一列用来表示用户是否购买。我们将建立一种模型来预测用户是否购买这种SUV,该模型基于两个变量,分别是年龄和预计薪资。因此我们的特征矩阵将是这两列。我们尝试寻找用户年龄与预估薪资之间的某种相关性,以及他是否购买SUV的决定。
步骤1 | 数据预处理
导入库
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
导入数据集
数据
dataset = pd.read_csv('Social_Network_Ads.csv')
X = dataset.iloc[:, [2, 3]].values
Y = dataset.iloc[:,4].values
如果导入csv文件,报错如下或者类似其他错误
csv.Error: line contains NULL byte
- 解决办法:
1.如果文件是从xlxs格式重命名为csv格式,则重新再另存为csv格式
2.将空字符全部替换
将数据集分成训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size = 0.25, random_state = 0)
特征缩放
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
- 关于为什么训练数据用
fit_transform,而测试数据用transform
步骤2 | 逻辑回归模型
该项工作的库将会是一个线性模型库,之所以被称为线性是因为逻辑回归是一个线性分类器,这意味着我们在二维空间中,我们两类用户(购买和不购买)将被一条直线分割。然后导入逻辑回归类。下一步我们将创建该类的对象,它将作为我们训练集的分类器。
将逻辑回归应用于训练集
from sklearn.linear_model import LogisticRegression
classifier = LogisticRegression()
classifier.fit(X_train, y_train)
步骤3 | 预测
预测测试集结果
y_pred = classifier.predict(X_test)
步骤4 | 评估预测
我们预测了测试集。 现在我们将评估逻辑回归模型是否正确的学习和理解。因此这个混淆矩阵将包含我们模型的正确和错误的预测。
生成混淆矩阵
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
可视化
from matplotlib.colors import ListedColormap
X_set,y_set=X_train,y_train
#定义网格坐标,以meshgrid函数生成密集的网格点
X1,X2=np. meshgrid(np. arange(start=X_set[:,0].min()-1, stop=X_set[:, 0].max()+1, step=0.01),
np. arange(start=X_set[:,1].min()-1, stop=X_set[:,1].max()+1, step=0.01))
#绘制轮廓图
#ravel函数将数组维度拉成一维数组
plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(),X2.ravel()]).T).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap(('red', 'green')))
#定义x,y轴的取值范围
plt.xlim(X1.min(),X1.max())
plt.ylim(X2.min(),X2.max())
#np. unique该函数是去除数组中的重复数字,并进行排序之后输出,在此例中y_set只有0和1两个值,故输出[0,1]
for i,j in enumerate(np. unique(y_set)):
#X_set[y_set==0,0]找到X的所有行,它们的y_set值为0(y == 0),并且位于X_set的第一列(第二个0代表第一列),这里以Age(第一列)作为横轴,Estimated Salary(第二列)作为纵轴
plt.scatter(X_set[y_set==j,0],X_set[y_set==j,1],
c = ListedColormap(('red', 'green'))(i), label=j)
plt. title(' LOGISTIC(Training set)')
plt. xlabel(' Age')
plt. ylabel(' Estimated Salary')
plt. legend()
plt. show()
X_set,y_set=X_test,y_test
X1,X2=np. meshgrid(np. arange(start=X_set[:,0].min()-1, stop=X_set[:, 0].max()+1, step=0.01),
np. arange(start=X_set[:,1].min()-1, stop=X_set[:,1].max()+1, step=0.01))
plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(),X2.ravel()]).T).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap(('red', 'green')))
plt.xlim(X1.min(),X1.max())
plt.ylim(X2.min(),X2.max())
for i,j in enumerate(np. unique(y_set)):
plt.scatter(X_set[y_set==j,0],X_set[y_set==j,1],
c = ListedColormap(('red', 'green'))(i), label=j)
plt. title(' LOGISTIC(Test set)')
plt. xlabel(' Age')
plt. ylabel(' Estimated Salary')
plt. legend()
plt. show()


numpy.meshgrid
- 应用实例
x = np.array([0, 1, 2])
y = np.array([0, 1])
X, Y = np.meshgrid(x, y)
print(X)
print(Y)
#输出
[[0 1 2]
[0 1 2]]
[[0 0 0]
[1 1 1]]
plt.contour
contour([X, Y,] Z, [levels], **kwargs)
| 参数 | 描述 |
|---|---|
| X, Y | Z值的坐标。X和Y必须是与Z形状相同的二维(例如,通过numpy.meshgrid),或者它们必须都是一维的,这样len(X)==M是Z中的列数,len(Y)==N是Z中的行数。 |
| Z | 绘制轮廓的高度值 |
| levels | 确定轮廓线/区域的数量和位置。如果为int n,则使用MaxNLocator,它会尝试在vmin和vmax之间自动选择不超过n+1个的轮廓级别。如果是阵列状,则在指定的水平上绘制轮廓线,值必须按升序排列。 |
enumerate(sequence, [start=0])
- 应用实例
>>>seasons = ['Spring', 'Summer', 'Fall', 'Winter']
>>> list(enumerate(seasons))
[(0, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter')]
>>> list(enumerate(seasons, start=1)) # 下标从 1 开始
[(1, 'Spring'), (2, 'Summer'), (3, 'Fall'), (4, 'Winter')]