Triton 模型推理使用案例、tritonclient https,grpc访问;导出onnx指定输入维度可变dynamic_axes
参考:https://www.cnblogs.com/infgrad/p/16283130.html
http://t.zoukankan.com/zzk0-p-15543824.html
https://www.bilibili.com/video/BV1ET411G7zV
1、下载安装Triton docker版
参考:https://github.com/triton-inference-server/server/blob/main/docs/quickstart.md
docker pull nvcr.io/nvidia/tritonserver:-py3
**我测试安装的是nvcr.io/nvidia/tritonserver:20.09-py3
2、运行案例
# Step 1: Create the example model repository
git clone https://github.com/triton-inference-server/server.git
cd server/docs/examples
./fetch_models.sh
# Step 2: Launch triton from the NGC Triton container
docker run --gpus=1 --rm --net=host -v /full/path/to/docs/examples/model_repository:/models nvcr.io/nvidia/tritonserver:20.09-py3 tritonserver --model-repository=/models
![]()
3、http post测试接口
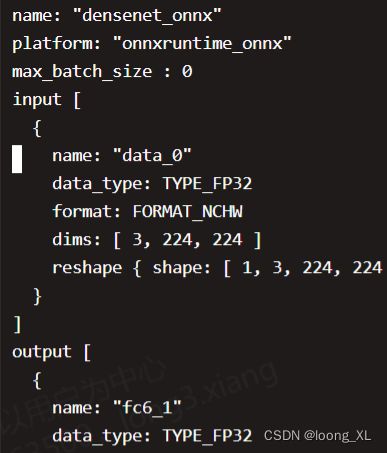
首先可以看到densenet_onnx的config.pbtxt 中输入输出接口
import requests
import numpy as np
if __name__ == "__main__":
request_data = {
"inputs": [{
"name": "data_0",
"shape": [3, 224, 224],
"datatype": "FP32",
"data": np.random.rand(3,224,224).tolist()
}],
"outputs": [{"name": "fc6_1"}]
}
res = requests.post(url="http://localhost:8000/v2/models/densenet_onnx/versions/1/infer",json=request_data).json()
print(res)
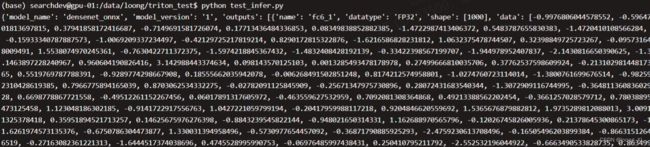
结果:
实际案例,Triton 模型推理使用案例、tritonclient https,grpc访问
1)、onnx导出,输入可变dynamic_axes
参考:https://blog.csdn.net/jacke121/article/details/104510401
import torch
from transformers import BertForSequenceClassification, BertConfig, BertTokenizer
import numpy as np
# 加载Taiyi 中文 text encoder
text_tokenizer = BertTokenizer.from_pretrained("IDEA-CCNL/Taiyi-CLIP-Roberta-102M-Chinese")
text_encoder = BertForSequenceClassification.from_pretrained("IDEA-CCNL/Taiyi-CLIP-Roberta-102M-Chinese").eval()
#转onnx,输入维度可变dynamic_axes
text1 = text_tokenizer(["三只小狗狗"], return_tensors='pt', padding=True)["input_ids"]
torch.onnx.export(text_encoder1, text1, "text_encoder3.onnx",opset_version=10,
input_names=['input'], # the model's input names
output_names=['output'], # the model's output names
dynamic_axes={'input': {1: 'int_height'}}) ## 第一维可变,第0维默认维batch
onnx是从pt转换得来的,参考https://blog.csdn.net/weixin_42357472/article/details/125749246
2)、构造triton model_repository
model_repository文件夹下(必须全部放在这个目录下)
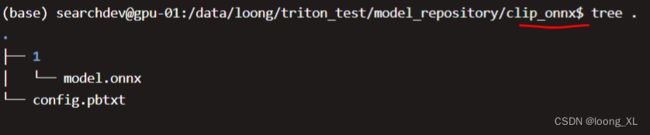
***注意模型1文件夹下 model.onnx,前缀必须是model
config.pbtxt
name: "clip_onnx" # 模型名,也是目录名
platform: "onnxruntime_onnx" # 模型对应的平台,本次使用的是torch,不同格式的对应的平台可以在官方文档找到
max_batch_size : 0 # 一次送入模型的最大bsz,防止oom
input [
{
name: "input" # 输入名字,对于torch来说名字于代码的名字不需要对应,但必须是__的形式,注意是2个下划线,写错就报错
data_type: TYPE_INT64 # 类型,torch.long对应的就是int64,不同语言的tensor类型与triton类型的对应关系可以在官方文档找到
dims: [ 1,-1] # -1 代表是可变维度,虽然输入是二维的,但是默认第一个是bsz,所以只需要写后面的维度就行(无法理解的操作,如果是[-1,-1]调用模型就报错)
}
]
output [
{
name: "output" # 命名规范同输入
data_type: TYPE_FP32
dims: [1,512]
}
]
***1、这里name需要与model_repository下的clip_onnx文件对其
2、platform为模型平台,是tf还是torch、还是onnx需要对应上;torch ==》pytorch_libtorch
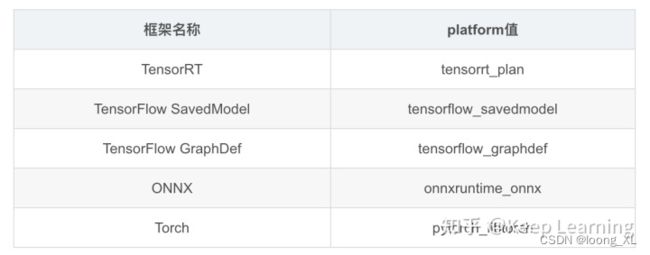
3、input与output的name需要与保存模型的对其,另外数字类型和维度都要对其
3)访问http与tritonclient
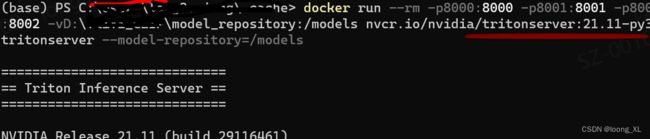
首先启动triton(linux环境和windows都可以下载docker版运行)
docker run --gpus=all --rm -p8000:8000 -p8001:8001 -p8002:8002 -v/data/loong/triton_test/model_repository:/models nvcr.io/nvidia/tritonserver:20.09-py3 tritonserver --model-repository=/models
截图是windows运行效果
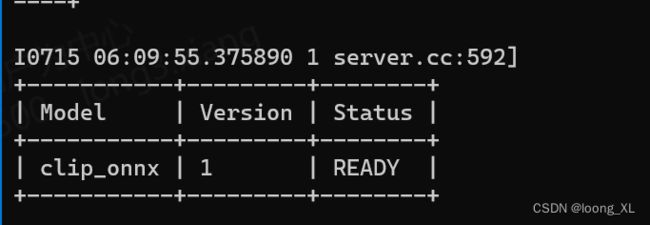

***查看部署状态检查
curl -v localhost:8000/v2/health/ready
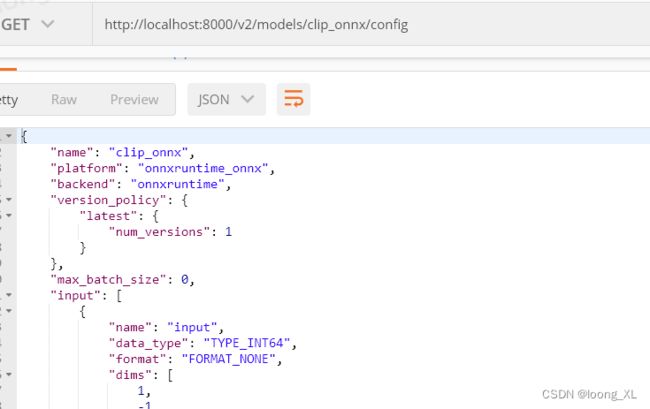
http://localhost:8000/v2/models/clip_onnx/config
a、http post
再访问http py文件:
onnx_infer.py
import requests
import numpy as np
if __name__ == "__main__":
request_data = {
"inputs": [{
"name": "input",
"shape": [1,8],
"datatype": "INT64",
"data": [[101,23, 235,562, 671, 1372, 4344, 102]]
}],
"outputs": [{"name": "output"}]
}
res = requests.post(url="http://localhost:8000/v2/models/clip_onnx/versions/1/infer",json=request_data).json()
print(res)
~
*** 1、这里必须要shape
2、数字类型datatype与前面config.pbtxt不一样,去掉了前缀TYPE_
3、/v2/models/{clip_onnx}/versions/{1}/infer;clip_onnx模型名,1是版本号

b、tritonclient
首先安装:
pip install tritonclient[all]
代码:onnx_infer_tritonclient.py
import requests
import numpy as np
import tritonclient.http as httpclient
if __name__ == "__main__":
triton_client = httpclient.InferenceServerClient(url='127.0.0.1:8000')
inputs = []
inputs.append(httpclient.InferInput('input', [1,8], "INT64"))
inputs[0].set_data_from_numpy(np.array([[101,23, 235,562, 671, 1372, 4344, 102]]).astype(np.int64), binary_data=False)
outputs = []
outputs.append(httpclient.InferRequestedOutput('output', binary_data=False))
results = triton_client.infer('clip_onnx', inputs=inputs, outputs=outputs)
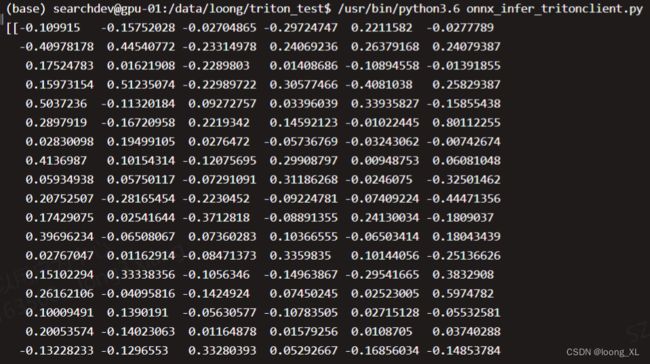
result = results.as_numpy("output")
print(result)
***1)result结果为numpy格式,如果需要tensor需要转换torch.from_numpy(result)
2)greenlet.error: cannot switch to a different thread报错,通过flask接口验证报错,最上面可以添加下面两行解决,参考:https://blog.csdn.net/qq_35152505/article/details/107230827
from gevent import monkey
monkey.patch_all()
grpc访问参考:
https://github.com/QunBB/DeepLearning/blob/main/Triton/client/_grpc.py
注意tritonclient http默认端口是8000,grpc默认端口是8001
import numpy as np
import tritonclient.grpc as grpcclient
if __name__ == "__main__":
triton_client = grpcclient.InferenceServerClient(
url='127.0.0.1:8001',
verbose=False,
ssl=False,
root_certificates=None,
private_key=None,
certificate_chain=None)
inputs = []
inputs.append(grpcclient.InferInput('input', [1,8], "INT64"))
inputs[0].set_data_from_numpy(np.array([[101,23, 235,562, 671, 1372, 4344, 102]]).astype(np.int64))
outputs = []
outputs.append(grpcclient.InferRequestedOutput('output'))
results = triton_client.infer(model_name='clip_onnx', inputs=inputs, outputs=outputs,compression_algorithm=None)
result = results.as_numpy("output")
print(result)
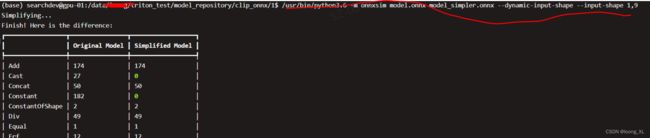
3、onnx-simplifier简化onnx 指定输入维度可变dynamic-input-shape
参考:https://github.com/daquexian/onnx-simplifier
安装:pip install onnx-simplifier
转化命令:
python -m onnxsim model.onnx model_simpler.onnx --dynamic-input-shape --input-shape 1,9
注意:在用dynamic-input-shape 可变维度输入也需要带个input-shape ,这个数可以随意填,这个只是用来做检查