使用Amazon SageMaker RL训练离线强化学习策略
使用Amazon SageMaker RL 训练离线强化学习策略
Training batch reinforcement learning policies with Amazon SageMaker RL
【更新日志】
2022年3月24日 更新训练代码部分
Amazon SageMaker 是一项完全托管的服务,它可以让开发人员和数据科学家能够快速轻松地构建、训练和部署任何规模的机器学习 (ML) 模型。 除了使用更常用的监督和非监督学习技术构建 ML 模型外,还可以使用 Amazon SageMaker RL 构建强化学习 (RL) 模型。
文章目录
-
- 使用Amazon SageMaker RL 训练离线强化学习策略
-
- 1. 离线强化学习(batch reinforcement Learning)
- 2. Batch RL on Amazon SageMaker RL
- 3. Simulating a random policy and collecting data
- 4. 通过离线数据训练强化学习策略
- 5. 评估强化学习性能
- 6. 结论
Amazon SageMaker RL 包含预构建的 RL 库和算法,可以很容易的学习强化学习相关的知识 Amazon SageMaker RL – Managed Reinforcement Learning with Amazon Sagemaker。 此外,Amazon SageMaker RL 可以轻松与各种模拟环境集成,例如 AWS RoboMaker、Open AI Gym、开源环境和用于训练 RL 模型的定制环境,也可以使用 Amazon RL 容器(MXNet 和 TensorFlow),其中包括 Open AI Gym、Intel Coach 和 Berkeley Ray RLLib等。
这篇博文主要是介绍如何使用 Amazon SageMaker RL 来训练离线强化学习 (batch RL),由于离线强化学习不需要与环境进行交互,就可以训练新的 RL 策略,本文通过 Amazon SageMaker RL 从初始随机策略中收集离线数据,使用离线数据训练 RL 策略,并从训练后的策略中获取行动预测来测试训练效果。
1. 离线强化学习(batch reinforcement Learning)
强化学习在解决多个领域的问题方面显示出了希望,例如投资组合管理、能源优化和机器人技术。 RL 是 ML 的一个类别,它不依赖于存在的任何训练数据。 相反,在 RL 中,学习代理与环境(真实的或模拟的)交互并学习提供最优动作序列的策略。 智能体学习的策略是基于它所采取的每一个动作所获得的奖励或惩罚。
然而,对于许多现实世界的问题,RL 代理需要从部署策略生成的历史数据中学习。 例如,您可能有专家玩游戏的历史数据、与网站交互的用户或来自控制系统的传感器数据。 您可以将此数据用作输入,通过将历史数据视为部署的现有策略的结果来训练新的和改进的 RL 策略。
这种 RL 方法称为离线 RL,其中学习代理从一批固定的离线数据集样本中得出改进的策略。 有关更多信息,请参阅“强化学习:最新技术”一书中的“离线强化学习”章节
这篇文章包含一个随附的笔记本,其中包含一个示例,说明如何使用批处理 RL 从离线数据集中训练新策略,该离线数据集由先前部署的策略的预测创建。 有关更多信息,请参阅 GitHub 存储库。
为了从之前部署的模型创建离线数据集,本文使用 Amazon SageMaker 离线转换,这是 Amazon SageMaker 中用于为大型数据集生成推理的高性能和高吞吐量功能。 我们可以收集来自 Batch Transform 的推论和来自环境的奖励,以使用批 RL 训练更好的策略。 有关详细信息,请参阅使用离线转换获取整个数据集的推断。
2. Batch RL on Amazon SageMaker RL
在这篇文章中,您将离线 RL 应用于 CartPole 平衡问题,其中一个未驱动的关节将一根杆连接到沿着无摩擦轨道移动的推车上。
- Objective – Prevent the pole from falling over
- Environment – The environment this post uses is part of OpenAI Gym
- State – Cart position, cart velocity, pole angle, and pole velocity at tip
- Action – Push the cart to the left and the right
- Reward – 1 for every step taken, including the termination step
在高层次上,离线 RL 实施包括以下步骤:
- 模拟初始策略并从该策略中收集数据
- 使用来自初始策略的离线数据训练 RL 策略,而无需与模拟器交互。
- 可视化和评估经过训练的 RL 策略的性能
- 使用 Amazon SageMaker 离线转换从经过训练的 RL 策略进行离线推理
这些步骤特定于 Amazon SageMaker 上的批处理 RL 实施。 导入库、设置权限和本文未讨论的其他功能还需要其他步骤。 有关更多信息,请参阅 GitHub 存储库。
3. Simulating a random policy and collecting data
对于离线 RL 训练,您需要模拟由先前部署的策略生成的离线数据。 在实际用例中,您可以通过使用现有策略与实时环境交互来收集非策略数据。 在这篇文章中,您使用 OpenAI Gym Cartpole-v0 作为环境来模拟实时环境,并使用具有统一动作分布的随机策略来模拟部署的代理。
完成以下步骤:
- 【Step-1】: 创建 100 个 Cartpole-v0 环境,并从每个环境中收集五集数据。
# initiate 100 environments to collect rollout data
NUM_ENVS = 100
NUM_EPISODES = 5
vectored_envs = VectoredGymEnvironment('CartPole-v0', NUM_ENVS)
这总共为您提供了 500 集进行训练。 您可以通过同时与多个环境交互来从环境中收集更多轨迹。
- 【Step-2】从对所有状态特征具有统一动作概率的随机策略开始。 请参阅以下代码:
# initiate a random policy by setting action probabilities as uniform distribution
action_probs = [[1/2, 1/2] for _ in range(NUM_ENVS)]
df = vectored_envs.collect_rollouts_with_given_action_probs(action_probs=action_probs, num_episodes=NUM_EPISODES)
#the rollout dataframes contain attributes: action, all_action_probabilities,episode_id, reward, cumulative_rewards, state_features.
df.head()
#average cumulative rewards for each episode
avg_rewards = df['cumulative_rewards’].sum() / (NUM_ENVS * NUM_EPISODES)
print(‘Average cumulative rewards over {} episodes rollouts was {}.”.format((NUM_ENVS * NUM_EPISODES), avg_rewards))
超过 500 集的平均累积奖励为 22.22
- 【Step-3】将数据框保存为 CSV 文件以供以后使用。 请参阅以下代码:
# dump dataframe as csv file
df.to_csv("src/cartpole_dataset.csv", index=False)
4. 通过离线数据训练强化学习策略
您现在拥有离线数据,可以使用它训练 RL 策略。
在这篇文章中,您将使用带有双 Q 学习 (DDQN) 算法的深度 RL 以非策略方式更新策略。有关更多信息,请参阅 ArXiv 上的使用双 Q 学习的深度强化学习。您将它与批处理约束的深度 Q 学习 BCQ 算法相结合,以解决由未见状态-动作对的不准确估计值引起的错误。培训完全离线。虽然 DDQN 解决了 RL 中典型 Q 学习的潜在高估问题,但 BCQ 旨在为给定数据集学习改进的策略,并限制减少外推误差的动作。数据集必须具有探索性交互,以便算法学习任何有用的东西。有关更多信息,请参阅研究论文 Off-Policy Deep Reinforcement Learning without Exploration。
RL 参数在 preset-cartpole-ddqnbcq.py 中捕获。您可以使用预设文件定义代理参数以选择特定的代理算法。您还可以定义计划参数、离线数据集参数和可视化参数。在此预设文件中,您使用 BatchRLGraphManager 而不为环境设置参数。请参阅以下代码:
agent_params = DDQNBCQAgentParameters()
agent_params.network_wrappers['main'].batch_size = 128
agent_params.algorithm.num_steps_between_copying_online_weights_to_target = TrainingSteps(50)
agent_params.algorithm.discount = 0.99
DATATSET_PATH = 'cartpole_dataset.csv'
agent_params.memory = EpisodicExperienceReplayParameters() agent_params.memory.load_memory_from_file_path = CsvDataset(DATATSET_PATH, is_episodic = True)
spaces = SpacesDefinition(state=StateSpace({'observation':VectorObservationSpace(shape=4)}),
goal=None,
action=DiscreteActionSpace(2),
reward=RewardSpace(1))
graph_manager = BatchRLGraphManager(agent_params=agent_params,
env_params=None,
spaces_definition=spaces,
schedule_params=schedule_params,
vis_params=vis_params,
reward_model_num_epochs=30,
train_to_eval_ratio=0.4,
preset_validation_params=preset_validation_params)
使用 Amazon SageMaker RLEstimator 对象指向提供训练代码的脚本 train-coach.py。 有关更多信息,请参阅 GitHub 存储库。 本文使用 Amazon SageMaker 脚本模式。 这允许您自定义可能在本地环境(例如笔记本电脑或 Amazon SageMaker 笔记本)中开发的训练脚本。 有关更多信息,请参阅通过 Amazon SageMaker 脚本模式使用 TensorFlow Eager Execution。
实例类型根据 local_mode 设置更改。 在 Amazon SageMaker 笔记本实例上,您可以使用本地模式训练 RL 模型,在这种模式下,您可以在笔记本实例本身上启动的容器上训练策略,从而加快迭代测试和调试。 有关更多信息,请参阅使用 Amazon SageMaker 本地模式在您的笔记本实例上进行训练。 Amazon SageMaker 让您只需更改一行代码即可在本地训练和分布式托管训练之间无缝切换。 请参阅以下代码:
%%time
if local_mode:
instance_type = 'local'
else:
instance_type = "ml.m4.xlarge"
estimator = RLEstimator(entry_point="train-coach.py",
source_dir='src',
dependencies=["common/sagemaker_rl"],
image_name=image,
role=role,
train_instance_type=instance_type,
train_instance_count=1,
output_path=s3_output_path,
base_job_name=job_name_prefix,
hyperparameters = {
"RLCOACH_PRESET": "preset-cartpole-ddqnbcq",
"save_model": 1
}
)
estimator.fit()
使用以下代码存储中间训练输出和模型检查点:
job_name=estimator._current_job_name
print("Job name: {}".format(job_name))
s3_url = "s3://{}/{}".format(s3_bucket,job_name)
if local_mode:
output_tar_key = "{}/output.tar.gz".format(job_name)
else:
output_tar_key = "{}/output/output.tar.gz".format(job_name)
intermediate_folder_key = "{}/output/intermediate/".format(job_name)
output_url = "s3://{}/{}".format(s3_bucket, output_tar_key)
intermediate_url = "s3://{}/{}".format(s3_bucket, intermediate_folder_key)
print("S3 job path: {}".format(s3_url))
print("Output.tar.gz location: {}".format(output_url))
print("Intermediate folder path: {}".format(intermediate_url))
tmp_dir = "/tmp/{}".format(job_name)
os.system("mkdir {}".format(tmp_dir))
print("Create local folder {}".format(tmp_dir))
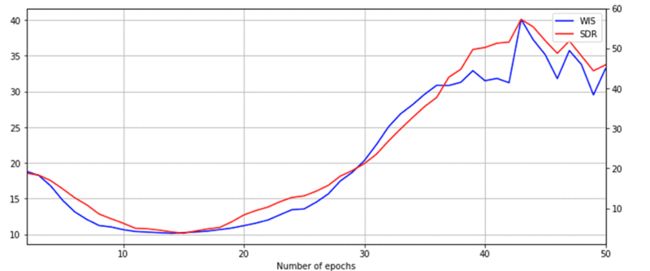
您现在可以可视化训练作业的指标。 使用中间结果提取训练的离策略评估 (OPE) 指标,并绘制它以查看模型随时间的性能。
您可以使用一组方法来调查当前训练策略的性能,而无需与模拟器或实时环境进行交互。 您可以使用它们根据从其他策略收集的数据集来估计策略的有效性。 以下代码使用两个 OPE 指标:加权重要性抽样 (WIS) 和顺序双重稳健 (SDR):
%matplotlib inline
import pandas as pd
import matplotlib.pyplot as plt
csv_file_name = "worker_0.batch_rl_graph.main_level.main_level.agent_0.csv"
key = os.path.join(intermediate_folder_key, csv_file_name)
wait_for_s3_object(s3_bucket, key, tmp_dir, training_job_name=job_name)
csv_file = "{}/{}".format(tmp_dir, csv_file_name)
df = pd.read_csv(csv_file)
df = df.dropna(subset=['Sequential Doubly Robust'])
df.dropna(subset=['Weighted Importance Sampling'])
plt.figure(figsize=(12,5))
plt.xlabel('Number of epochs')
ax1 = df['Weighted Importance Sampling'].plot(color='blue', grid=True, label='WIS')
ax2 = df['Sequential Doubly Robust'].plot(color='red', grid=True, secondary_y=True, label='SDR')
h1, l1 = ax1.get_legend_handles_labels()
h2, l2 = ax2.get_legend_handles_labels()
plt.legend(h1+h2, l1+l2, loc=1)
plt.show()
下图显示,随着学习代理在给定数据集上迭代多个时期,这些指标得到了改善。
5. 评估强化学习性能
要评估使用离线数据训练的模型,您需要通过与环境交互来查看代理的累积奖励。 使用最后一个检查点模型为 RL 代理运行评估。 来自先前训练的模型的检查点数据在检查点通道中传递以进行评估和推理。 请参阅以下代码:
estimator_eval = RLEstimator(entry_point="evaluate-coach.py",
source_dir='src',
dependencies=["common/sagemaker_rl"],
image_name=image,
role=role,
train_instance_type=instance_type,
train_instance_count=1,
output_path=s3_output_path,
base_job_name=job_name_prefix,
hyperparameters = {
"RLCOACH_PRESET": " preset-cartpole-ddqnbcq-env",
"evaluate_steps": 1000
}
)
estimator_eval.fit({'checkpoint': checkpoint_path})
以下屏幕截图显示代理的总奖励为 195.33。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zwUahx6v-1648290429729)(https://gitee.com/Jin0932/typora_imgs/raw/master/imgs/batch-rl-2.gif)]
当您将此与使用随机策略获得的累积奖励 22.22 进行比较时,您可以看到您使用离线数据训练的 RL 策略的改进。 由于收集的数据集中的随机性,当您执行笔记本时,确切的奖励值可能会有所不同。
使用 Amazon SageMaker 离线转换进行离线推理
训练 RL 策略后,您可以使用离线转换,其中您提供一组输入状态特征并获得高吞吐量的推理。 您可以使用推理和由此产生的环境奖励为下一批 RL 策略训练准备离线数据。
以下代码使用环境的状态作为离线转换的输入:
transformer = model.transformer(instance_count=1, instance_type=instance_type, output_path=batch_output, assemble_with = 'Line', accept = 'application/jsonlines', strategy='SingleRecord')
transformer.transform(data=batch_input, data_type='S3Prefix', content_type='application/jsonlines', split_type='Line', join_source='Input')
transformer.wait()
您可以看到如何在生产中使用离线转换推理来训练下一个 RL 策略。 在这篇文章中,您将使用模拟环境来收集随机策略的推出数据。 假设更新后的策略现在可以部署,您可以使用离线转换从该策略收集推出数据。 该过程包括以下步骤:
- 您使用离线转换来获取动作预测,在时间步长 t 提供来自实时环境的观察特征。
- 部署的代理在时间步 t 对环境(模拟器或真实)采取建议的操作。
- 环境返回时间步长 t+1 的新观察特征和奖励。
- 您返回到使用离线转换来获得时间步长 t+1 的动作预测。
这个迭代过程使您能够收集一组可以涵盖整个剧集的数据。 当数据足够时,您可以使用这些数据再次开始离线 RL 训练。
6. 结论
这篇博文向您展示了使用 Amazon SageMaker RL 实施批处理 RL 的详细过程。虽然这篇文章使用了一个简单的 CartPole 游戏来详细说明所涉及的各个步骤,但您可以进行适当的更改以将这些步骤应用于其他问题。此外,GitHub repo 上的最终解决方案展示了如何训练批处理 RL 策略。这篇文章还演示了如何使用离线转换功能来收集非策略数据并使用它来训练未来的 RL 策略。您可以使用离线转换从数百万用户上下文中高效地同时收集推出数据,并使用收集到的推出数据来训练更好的策略。
本文翻译自AWS blog: https://aws.amazon.com/cn/blogs/machine-learning/training-batch-reinforcement-learning-policies-with-amazon-sagemaker-rl/