微服务 ZooKeeper ,Dubbo ,Kafka 介绍应用
目录
微服务
微服务的优缺点
微服务技术栈 编辑
常见的微服务框架
ZooKeeper 工作原理
ZooKeeper 集中存放管理
ZooKeeper 功能 动物园管理员
ZooKeeper 服务流程编辑
命令行客户端访问 ZooKeeper
图形化客户端 ZooInspector
sudo apt install openjdk-11-jdk
客户端使用
ZooKeeper 集群运行介绍
集群角色
编辑
选举过程
ZooKeeper 集群部署
Kafka主流的消息队列(MQ)软件
MQ 使用场合
Kafka 特点和优势编辑
Kafka 写入消息的流程
Kafka 部署
各节点部署 Kafka
准备Kafka的service文件
创建 Topic
获取所有 Topic
验证 Topic 详情
图形工具 Offset Explorer (Kafka Tool)
官网:
Dubbo 介绍
实现 Dubbo 架构
准备 ZooKeeper 提供注册中心
微服务
简而言之,微服务架构风格是一种将单个应用程序开发为一套小型服务的方法,每个服务都在自己的进程中运行并与轻量级机制(通常是 HTTP 资源 API)进行通信。这些服务围绕业务功能构建,并可通过全自动部署机制独立部署。对这些服务进行最低限度的集中管理,这些服务可能用不同的编程语言编写并使用不同的数据存储技术。
- 属于SOA(Service Oriented Architecture)的子集
- 微服务化的核心就是将传统的一站式应用,根据业务拆分成一个一个的服务,彻底去掉耦合,每一个微服务提供单个业务功能,一个服务只做一件事。每个服务都围绕着具体业务进行构建,并且能够被独立地部署到生产环境、类生产环境等
- 从技术角度讲就是一种小而独立的处理过程,类似与进程的概念,能够自行单独启动或销毁
- 微服务架构(分布式系统),各个模块/服务,各自独立出来,"让专业的人干专业的事",独立部署。分布式系统中,不同的服务可以使用各自独立的数据库。服务之间采用轻量级的通信机制(通常是基于HTTP的RESTful API)。
- 微服务设计的思想改变了原有的企业研发团队组织架构。传统的研发组织架构是水平架构,前端、后端、DBA、测试分别有自己对应的团队,属于水平团队组织架构。而微服务的设计思想对团队的划分有着一定的影响,使得团队组织架构的划分更倾向于垂直架构,比如用户业务是一个团队来负责,支付业务是一个团队来负责。但实际上在企业中并不会把团队组织架构拆分得这么绝对,垂直架构只是一种理想的架构
- 微服务的实现框架有多种,不同的应用架构,部署方式也有不同
微服务的优缺点
微服务优点:
- 每个服务足够内聚,足够小,代码容易理解。这样能聚焦一个简单唯一的业务功能或业务需求。
- 开发简单、开发效率提高,一个服务可能就是专业的只干一件事,微服务能够被小团队单独开发,这个小团队可以是2到5人的开发人员组成
- 微服务是松耦合的,是有功能意义的服务,无论是在开发阶段或部署阶段都是独立的。
- 微服务能使用不同的语言开发
- 易于和第三方集成,微服务运行容易且灵活的方式集成自动部署,通过持续集成工具,如:Jenkins、Hudson、Bamboo
- 微服务易于被一个开发人员理解、修改和维护,这样小团队能够更关注自己的工作成果,无需通过合作才能体现价值
- 微服务允许你利用融合最新技术。微服务只是业务逻辑的代码,不会和HTML/CSS或其他界面组件混合,即前后端分离
- 每个微服务都有自己的存储能力,一般都有自己的独立的数据库,也可以有统一数据库
微服务缺点:
- 微服务把原有的一个项目拆分成多个独立工程,增加了开发、测试、运维、监控等的复杂度
- 微服务架构需要保证不同服务之间的数据一致性,引入了分布式事务和异步补偿机制,为设计和开发带来一定挑战
- 开发人员和运维需要处理分布式系统的复杂性,需要更强的技术能力
- 微服务适用于复杂的大系统,对于小型应用使用微服务,进行盲目的拆分只会增加其维护和开发成本
微服务技术栈 
常见的微服务框架
Dubbo
- 阿里开源贡献给了ASF,目前已经是Apache的顶级项目
- 一款高性能的Java RPC服务框架,微服务生态体系中的一个重要组件
- 将单体程序分解成多个功能服务模块,模块间使用Dubbo框架提供的高性能RPC通信
- 内部协调使用 Zookeeper,实现服务注册、服务发现和服务治理
Spring cloud
- 一个完整的微服务解决方案,相当于Dubbo的超集
- 微服务框架,将单体应用拆分为粒度更小的单一功能服务
- 基于HTTP协议的REST(Representational State Transfer 表述性状态转移)风格实现模块间
- 通信
ZooKeeper 工作原理
ZooKeeper 是一个分布式服务框架,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:命名服务、状态同步、配置中心、集群管理等 #基于Java管理
ZooKeeper 集中存放管理
ZooKeeper 是一个典型的分布式数据一致性解决方案,分布式应用程序可以基于 ZooKeeper 实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能。
Zookeeper 一个最常用的使用场景就是用于担任服务生产者和服务消费者的注册中心(提供发布订阅服务)。 服务生产者将自己提供的服务注册到Zookeeper中心,服务的消费者在进行服务调用的时候先到Zookeeper中查找服务,获取到服务生产者的详细信息之后,再去调用服务生产者的内容与数据。在Dubbo架构中 Zookeeper 就担任了注册中心这一角色
ZooKeeper 功能 动物园管理员
命名服务
命名服务是分布式系统中比较常见的一类场景。命名服务是分布式系统最基本的公共服务之一。在分布式系统中,被命名的实体通常可以是集群中的机器、提供的服务地址或远程对象等——这些我们都可以统称它们为名字(Name),其中较为常见的就是一些分布式服务框架(如RPC、RMI)中的服务地址列表,通过使用命名服务,客户端应用能够根据指定名字来获取资源的实体、服务地址和提供者的信息等。
Zookeeper 数据模型
在 Zookeeper 中,节点分为两类
第一类是指构成Zookeeper集群的主机,称之为主机节点
第二类则是指内存中zookeeper数据模型中的数据单元,用来存储各种数据内容,称之为数据节点 ZNode。Zookeeper内部维护了一个层次关系(树状结构)的数据模型,它的表现形式类似于Linux的文件系统,甚至操作的种类都一致。Zookeeper数据模型中有自己的根目录(/),根目录下有多个子目录,每个子目录后面有若干个文件,由斜杠(/)进行分割的路径,就是一个ZNode,每个 ZNode上都会保存自己的数据内容和一系列属性信息.简单来讲文件夹也是文件,他也能存放单独的数据,其文件夹还能存放别的文件夹
状态同步
每个节点除了存储数据内容和 node 节点状态信息之外,还存储了已经注册的APP 的状态信息,当有些节点或APP 不可用,就将当前状态同步给其他服务。
配置中心
简单来讲就是集体改文件
现在我们大多数应用都是采用的是分布式开发的应用,搭建到不同的服务器上,我们的配置文件,同一个应用程序的配置文件一样,还有就是多个程序存在相同的配置,当我们配置文件中有个配置属性需要改变,需要改变每个程序的配置属性,这样会很麻烦的去修改配置,那么可用使用ZooKeeper 来实现配置中心ZooKeeper 采用的是推拉相结合的方式:客户端向服务端注册自己需要关注的节点,一旦该节点的数据发生变更,那么服务端就会向相应的客户端发送Watcher事件通知,客户端接收到这个消息通知后,需要主动到服务端获取最新的数据。
Apollo(阿波罗)是携程框架部门研发的开源配置管理中心,此应用比较流行
集群管理
所谓集群管理,包括集群监控与集群控制两大块,前者侧重对集群运行时状态的收集,后者则是对集群进行操作与控制,在日常开发和运维过程中,我们经常会有类似于如下的需求:
- 希望知道当前集群中究竟有多少机器在工作。
- 对集群中每台机器的运行时状态进行数据收集。对集群中机器进行上下线操作。
ZooKeeper 具有以下两大特性:
- 客户端如果对ZooKeeper 的一个数据节点注册 Watcher监听,那么当该数据节点的内容或是其子节点列表发生变更时,ZooKeeper 服务器就会向已注册订阅的客户端发送变更通知。
- 对在ZooKeeper上创建的临时节点,一旦客户端与服务器之间的会话失效,那么该临时节点也就被自动清除。
Watcher(事件监听器)是 Zookeeper 中的一个很重要的特性。Zookeeper 允许用户在指定节点上注册一些 Watcher,并且在一些特定事件触发的时候, ZooKeeper 服务端会将事件通知到感兴趣的客户端上去,该机制是 Zookeeper 实现分布式协调服务的重要特性。
ZooKeeper 服务流程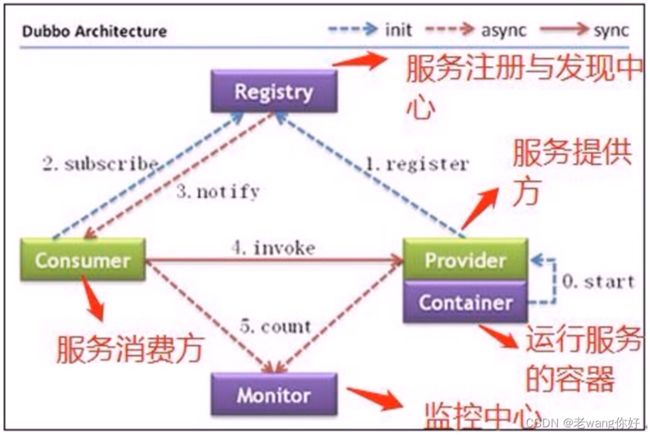
- 生产者启动
- 生产者注册至zookeeper
- 消费者启动并订阅频道
- zookeeper 通知消费者事件
- 监控中心负责统计和监控服务状态
二进制脚本安装 zookeeper
ZK_VERSION=3.8.0
#ZK_VERSION=3.6.3
#ZK_VERSION=3.7.1
ZK_URL=https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/zookeeper-${ZK_VERSION}/apache-zookeeper-${ZK_VERSION}-bin.tar.gz
#ZK_URL="https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/stable/apache-zookeeper-${ZK_VERSION}-bin.tar.gz"
#ZK_URL="https://downloads.apache.org/zookeeper/stable/apache-zookeeper-${ZK_VERSION}-bin.tar.gz"
INSTALL_DIR=/usr/local/zookeeper
HOST=`hostname -I|awk '{print $1}'`
. /etc/os-release
color () {
RES_COL=60
MOVE_TO_COL="echo -en \\033[${RES_COL}G"
SETCOLOR_SUCCESS="echo -en \\033[1;32m"
SETCOLOR_FAILURE="echo -en \\033[1;31m"
SETCOLOR_WARNING="echo -en \\033[1;33m"
SETCOLOR_NORMAL="echo -en \E[0m"
echo -n "$1" && $MOVE_TO_COL
echo -n "["
if [ $2 = "success" -o $2 = "0" ] ;then
${SETCOLOR_SUCCESS}
echo -n $" OK "
elif [ $2 = "failure" -o $2 = "1" ] ;then
${SETCOLOR_FAILURE}
echo -n $"FAILED"
else
${SETCOLOR_WARNING}
echo -n $"WARNING"
fi
${SETCOLOR_NORMAL}
echo -n "]"
echo
}
install_jdk() {
if [ $ID = 'centos' -o $ID = 'rocky' ];then
yum -y install java-1.8.0-openjdk-devel || { color "安装JDK失败!" 1; exit 1; }
else
apt update
apt install openjdk-11-jdk -y || { color "安装JDK失败!" 1; exit 1; }
#apt install openjdk-8-jdk -y || { color "安装JDK失败!" 1; exit 1; }
fi
java -version
}
install_zookeeper() {
wget -P /usr/local/src/ --no-check-certificate $ZK_URL || { color "下载失败!" 1 ;exit ; }
tar xf /usr/local/src/${ZK_URL##*/} -C /usr/local
ln -s /usr/local/apache-zookeeper-*-bin/ ${INSTALL_DIR}
echo "PATH=${INSTALL_DIR}/bin:$PATH" > /etc/profile.d/zookeeper.sh
. /etc/profile.d/zookeeper.sh
mkdir -p ${INSTALL_DIR}/data
cat > ${INSTALL_DIR}/conf/zoo.cfg < /lib/systemd/system/zookeeper.service < [root@ubuntu2004 ~]#exit #装好后需要重新登录才生效
[root@ubuntu2004 ~]#zkServer.sh version #查看版本
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Apache ZooKeeper, version 3.8.0 2022-02-25 08:49 UTC[root@ubuntu2004 ~]#zkServer.sh status #状态
命令行客户端访问 ZooKeeper
[zk: 10.0.0.100:2181(CONNECTED) 2] create /app1 创建
[zk: 10.0.0.100:2181(CONNECTED) 16] set /app1/m50 wee 在50文件夹里面写入
[zk: 10.0.0.100:2181(CONNECTED) 17] get /app1/m50 查文件夹的只能用get看 -s详细delete#删除不包含子节点的节点(相当于rmdir),如果想删除所有节点内的数据,使用deleteall /path(相当于rm -rf)
#可连接至zookeeper 集群中的任意一台zookeeper 节点进行以下操作,zkCli.sh 默认连接本机
[root@ubuntu2004 ~]#zkCli.sh -server 10.0.0.100:2181
[zk: 10.0.0.100:2181(CONNECTED) 0] #两个TAB 可以列出所有支持命令
addWatch addauth close config
connect create delete deleteall
delquota get getAcl getAllChildrenNumber
getEphemerals history listquota ls
printwatches quit reconfig redo
removewatches set setAcl setquota
stat sync version whoami
默认创建持久节点,即退出不丢失,create -e 可以创建临时节点(退出就丢失)
#持久节点才支持创建子节点,临时节点不支持,如: create /app1/subapp1 "subdata" ,不能递归创建
[zk: 10.0.0.100:2181(CONNECTED) 1] ls /app1
Node does not exist: /app1
[zk: 10.0.0.100:2181(CONNECTED) 2] create /app1 创建
Created /app1
[zk: 10.0.0.100:2181(CONNECTED) 3] ls /app1
[]
[zk: 10.0.0.100:2181(CONNECTED) 4] ls /
[app1, zookeeper]
[zk: 10.0.0.100:2181(CONNECTED) 9] ls /app1/m50
[]
[zk: 10.0.0.100:2181(CONNECTED) 5] create /app1/m50 创建
Created /app1/m50
[zk: 10.0.0.100:2181(CONNECTED) 16] set /app1/m50 wee 在50文件里面写入
[zk: 10.0.0.100:2181(CONNECTED) 17] get /app1/m50 查看
wee
[zk: 10.0.0.100:2181(CONNECTED) 19] ls /app1
[m50]
[zk: 10.0.0.100:2181(CONNECTED) 20] set /app1 app1-data
[zk: 10.0.0.100:2181(CONNECTED) 21] ls /app1
[m50]
[zk: 10.0.0.100:2181(CONNECTED) 22] get /app1
app1-data
修改已有节点的值
[zk: 10.0.0.103:2181(CONNECTED) 5] set /app1 "hello,linux"
[zk: 10.0.0.103:2181(CONNECTED) 6] get /app1
hello,linux
#删除不包含子节点的节点(相当于rmdir),如果想删除所有节点内的数据,使用deleteall /path(相当于
rm -rf)
[zk: 10.0.0.103:2181(CONNECTED) 7] delete /app1
[zk: 10.0.0.103:2181(CONNECTED) 8] ls /
[zookeeper]
#查看已知节点元数据
[zk: 10.0.0.103:2181(CONNECTED) 9] stat /zookeeper
zxid = Ox0 #节点创建时的zxid
ctime = Thu Jan 01 08:00:00 CST 1970 #节点创建时间
mzxid = Ox0 #节点最近一次更新时的zxid
mtime = Thu Jan 01 08:00:00 cST 1970 #节点最近一次更新的时间
pzxid = Ox0 #父节点创建时的zxid
cversion = -1 #子节点数据更新次数
dataversion = 0 #本节点数据更新次数
aclversion = o #节点ACL(授权信息)的更新次数
ephemera10wner = Ox0 #持久节点值为0,临时节点值为sessionid
dataLength = 0 #节点数据长度
numchi1dren = 1 #子节点个数
图形化客户端 ZooInspector
github链接
https://github.com/zzhang5/zooinspector
https://gitee.com/lbtooth/zooinspector.git
范例: 编译 zooinspector
注意:在Ubuntu18.04或Rocky8上编译,不支持Ubuntu20.04以上版本
#github
[root@zookeeper-node1 ~]#git clone https://github.com/zzhang5/zooinspector.git
#国内镜像
[root@zookeeper-node1 ~]#git clone https://gitee.com/lbtooth/zooinspector.git
[root@zookeeper-node1 ~]#cd zooinspector/
[root@zookeeper-node1 zooinspector]#apt install maven -y
#镜像加速
[root@zookeeper-node1 zooinspector]#vim /etc/maven/settings.xml
nexus-aliyun
*
Nexus aliyun
http://maven.aliyun.com/nexus/content/groups/public
#编译,此步骤需要较长时间下载,可能数分钟
[root@zookeeper-node1 zooinspector]#mvn clean package -Dmaven.test.skip=true编译完的
sudo apt install openjdk-11-jdk
ldd /usr/lib/jvm/java-11-openjdk-amd64/lib/libawt_xawt.so
/opt/zooinspector-1.0-SNAPSHOT/bin
./zooinspector.sh
客户端使用
[root@zookeeper-node1 zooinspector]#ls
pom.xml README.md src target
[root@zookeeper-node1 zooinspector]#du -sh .
7.3M .
[root@zookeeper-node1 zooinspector]#chmod +x target/zooinspector-
pkg/bin/zooinspector.sh
[root@zookeeper-node1 zooinspector]#target/zooinspector-pkg/bin/zooinspector.sh
#自动打开下面图形界面

ZooKeeper 集群运行介绍
ZooKeeper集群用于解决单点和单机性能及数据高可用等问题。
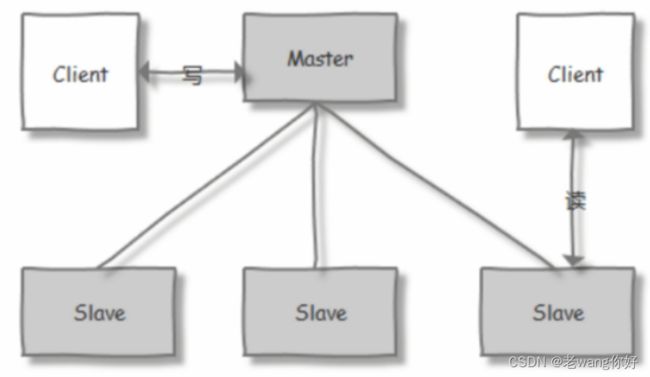
zookeeper集群基于Master/Slave的模型,处于主要地位(处理写操作)的主机称为Master(Leader)节点,处于次要地位(处理读操作)的主机称为 slave节点,生产中读取的方式一般是以异步复制方式来实现的。
对于n台server,每个server都知道彼此的存在。只要有>n/2台server节点可用,整个zookeeper系统保持可用。
因此zookeeper集群通常由奇数台Server节点组成
当进行写操作时,由Master(leader)完成,并且同步到其它Slave(follower)节点,当在保证写操作在所有节点的总数过半后,才会认为写操作成功
集群角色



选举过程
节点角色状态:
- LOOKING:寻找 Leader 状态,处于该状态需要进入选举流程
- LEADING:领导者状态,处于该状态的节点说明是角色已经是Leader
- FOLLOWING:跟随者状态,表示 Leader已经选举出来,当前节点角色是follower
- OBSERVER:观察者状态,表明当前节点角色是 observer
选举 ID:
- ZXID(zookeeper transaction id):每个改变 Zookeeper状态的操作都会形成一个对应的zxid。ZXID最大的节点优先选为Leader
- myid:服务器的唯一标识(SID),通过配置 myid 文件指定,集群中唯一,当ZXID一样时,myid大的节点优先选为Leader
ZooKeeper 集群部署
环境准备
#三台ubuntu18.04
zookeeper-node1.wang.org 10.0.0.101
zookeeper-node2.wang.org 10.0.0.102
zookeeper-node3.wang.org 10.0.0.103#在三个节点都安装JDK
[root@zookeeper-node1 ~]#apt -y install openjdk-8-jdk
在所有节点下载并解压缩 ZooKeeper 包文件
[root@zookeeper-node1 ~]#wget -P /usr/local/src
https://downloads.apache.org/zookeeper/zookeeper-3.8.0/apache-zookeeper-3.8.0-bin.tar.gz
[root@zookeeper-node1 ~]#tar xf /usr/local/src/apache-zookeeper-3.8.0-bin.tar.gz
-C /usr/local/
[root@zookeeper-node1 ~]#ln -s /usr/local/apache-zookeeper-3.6.3-bin
/usr/local/zookeeper
[root@zookeeper-node1 ~]#echo 'PATH=/usr/local/zookeeper/bin:$PATH' >
/etc/profile.d/zookeeper.sh
[root@zookeeper-node1 ~]#. /etc/profile.d/zookeeper.sh
准备配置文件
#三个节点都要创建数据目录
[root@zookeeper-node1 ~]#mkdir /usr/local/zookeeper/data
#基于模板配置文件生成配置文件
[root@zookeeper-node1 ~]#cp /usr/local/zookeeper/conf/zoo_sample.cfg
/usr/local/zookeeper/conf/zoo.cfg
#修改配置文件
[root@zookeeper-node1 ~]#vim /usr/local/zookeeper/conf/zoo.cfg
#配置文件内容
[root@zookeeper-node1 ~]#grep -v "\^\#" /usr/local/zookeeper/conf/zoo.cfg
tickTime=2000 #服务器与服务器之间的单次心跳检测时间间隔,单位为毫秒
initLimit=10 #集群中leader 服务器与follower服务器初始连接心跳次数,即多少个 2000 毫秒
syncLimit=5 #leader 与follower之间连接完成之后,后期检测发送和应答的心跳次数,如果该follower在设置的时间内(5*2000)不能与 leader 进行通信,那么此 follower将被视为不可用。
dataDir=/usr/local/zookeeper/data #自定义的zookeeper保存数据的目录
clientPort=2181 #客户端连接 Zookeeper 服务器的端口,Zookeeper会监听这个端口,接受客户端的访问请求
maxClientCnxns=128 #单个客户端IP 可以和zookeeper保持的连接数
autopurge.snapRetainCount=3 #3.4.0中的新增功能:启用后,ZooKeeper 自动清除功能,会将只保留此最新3个快照和相应的事务日志,并分别保留在dataDir 和dataLogDir中,删除其余部分,默认值为3,最小值为3
autopurge.purgeInterval=24 #3.4.0及之后版本,ZK提供了自动清理日志和快照文件的功能,这个参数指定了清理频率,单位是小时,需要配置一个1或更大的整数,默认是 0,表示不开启自动清理功能
#格式: server.MyID服务器唯一编号=服务器IP:Leader和Follower的数据同步端口(只有leader才会打
开):Leader和Follower选举端口(L和F都有)
server.1=10.0.0.101:2888:3888
server.2=10.0.0.102:2888:3888
server.3=10.0.0.103:2888:3888
#如果添加节点,只需要在所有节点上添加新节点的上面形式的配置行,在新节点创建myid文件,并重启所有节
点服务即可
[root@zookeeper-node1 ~]#scp /usr/local/zookeeper/conf/zoo.cfg
10.0.0.102:/usr/local/zookeeper/conf/
[root@zookeeper-node1 ~]#scp /usr/local/zookeeper/conf/zoo.cfg
10.0.0.103:/usr/local/zookeeper/conf/在各个节点生成ID文件
注意: 各个myid文件的内容要和zoo.cfg文件相匹配
[root@zookeeper-node1 ~]#echo 1 > /usr/local/zookeeper/data/myid
[root@zookeeper-node2 ~]#echo 2 > /usr/local/zookeeper/data/myid
[root@zookeeper-node3 ~]#echo 3 > /usr/local/zookeeper/data/myid
各服务器启动 zookeeper
#注意:在所有三个节点快速启动服务,否则会造成集群失败
[root@zookeeper-node1 ~]#zkServer.sh start
[root@zookeeper-node2 ~]#zkServer.sh start
[root@zookeeper-node3 ~]#zkServer.sh start
#注意:如果无法启动查看日志
[root@zookeeper-node1 ~]#cat /usr/local/zookeeper/logs/zookeeper-root-server-
zookeeper-node1.wang.org.out
查看集群状态
#follower会监听3888/tcp端口
[root@zookeeper-node1 ~]#zkServer.sh status
Mode: follower
[root@zookeeper-node1 ~]#ss -ntl |grep 888
LISTEN 0 50 [::ffff:10.0.0.101]:3888 *:*#只有leader监听2888/tcp端口
[root@zookeeper-node2 ~]#zkServer.sh statusMode: leader
Kafka主流的消息队列(MQ)软件
Kafka 被称为下一代分布式消息系统,由 Scala 和 Java编写,是非营利性组织ASF(Apache SoftwareFoundation)基金会中的一个开源项目,比如:HTTP Server、Tomcat、Hadoop、ActiveMQ等开源软件都属于 Apache基金会的开源软件,类似的消息系统还有RabbitMQ、ActiveMQ、ZeroMQ。
Kafka用于构建实时数据管道和流应用程序。 它具有水平可伸缩性,容错性,快速性,可在数千家组织中同时投入生产协同工作。
MQ 定义
在分布式场景中,相对于大量的用户请求来说,内部的功能主机之间、功能模块之间等,数据传递的数据量是无法想象的,因为一个用户请求,会涉及到各种内部的业务逻辑跳转等操作。那么,在大量用户的业务场景中,如何保证所有的内部业务逻辑请求都处于稳定而且快捷的数据传递呢? 消息队列(Message Queue)技术可以满足此需求
消息队列(Message Queue,简称 MQ)是构建分布式互联网应用的基础设施,通过 MQ 实现的松耦合架构设计可以提高系统可用性以及可扩展性,是适用于现代应用的最佳设计方案。
消息队列是一种异步的服务间通信方式,适用于无服务器和微服务架构。消息在被处理和删除之前一直存储在队列上。每条消息仅可被一位用户处理一次。消息队列可被用于分离重量级处理、缓冲或批处理工作以及缓解高峰期工作负载。
MQ 使用场合
 消息队列作为高并发系统的核心组件之一,能够帮助业务系统结构提升开发效率和系统稳定性
消息队列作为高并发系统的核心组件之一,能够帮助业务系统结构提升开发效率和系统稳定性
消息队列主要有以下应用场景
削峰填谷
诸如电商业务中的秒杀、抢红包、企业开门红等大型活动时皆会带来较高的流量脉冲,或因没做相应的保护而导致系统超负荷甚至崩溃,或因限制太过导致请求大量失败而影响用户体验,消息队列可提供削峰填谷的服务来解决该问题。
异步解耦
交易系统作为淘宝等电商的最核心的系统,每笔交易订单数据的产生会引起几百个下游业务系统的关注,包括物流、购物车、积分、流计算分析等等,整体业务系统庞大而且复杂,消息队列可实现异步通信和应用解耦,确保主站业务的连续性。
顺序收发细数日常中需要保证顺序的应用场景非常多,例如证券交易过程时间优先原则,交易系统中的订单创建、支付、退款等流程,航班中的旅客登机消息处理等等。与先进先出FIFO(First In FirstOut)原理类似,消息队列提供的顺序消息即保证消息FIFO。
分布式事务一致性
交易系统、支付红包等场景需要确保数据的最终一致性,大量引入消息队列的分布式事务,既可以实现系统之间的解耦,又可以保证最终的数据一致性。
大数据分析
数据在“流动”中产生价值,传统数据分析大多是基于批量计算模型,而无法做到实时的数据分析,利用消息队列与流式计算引擎相结合,可以很方便的实现业务数据的实时分析。
分布式缓存同步
电商的大促,各个分会场琳琅满目的商品需要实时感知价格变化,大量并发访问数据库导致会场页面响应时间长,集中式缓存因带宽瓶颈,限制了商品变更的访问流量,通过消息队列构建分布式缓存,实时通知商品数据的变化
蓄流压测
线上有些链路不方便做压力测试,可以通过堆积一定量消息再放开来压测
Kafka 介绍
Kafka 被称为下一代分布式消息系统,由 Scala 和 Java编写,是非营利性组织ASF(Apache SoftwareFoundation)基金会中的一个开源项目,比如:HTTP Server、Tomcat、Hadoop、ActiveMQ等开源软件都属于 Apache基金会的开源软件,类似的消息系统还有RabbitMQ、ActiveMQ、ZeroMQ。
Kafka用于构建实时数据管道和流应用程序。 它具有水平可伸缩性,容错性,快速性,可在数千家组织中同时投入生产协同工作 。 官 网: http://kafka.apache.org/
常用消息队列对比
kafka 最主要的优势是其具备分布式功能、并可以结合 zookeeper 可以实现动态扩容,Kafka 是一种高吞吐量的分布式发布订阅消息系统。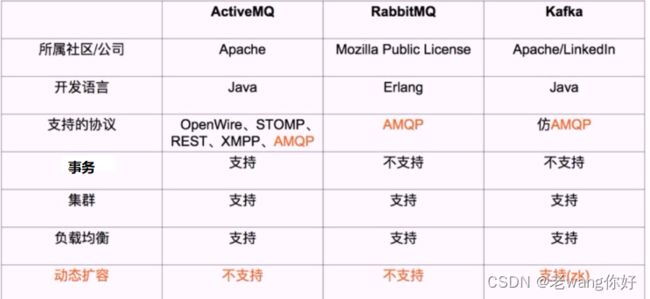
Kafka 特点和优势
特点
- 分布式: 多机实现,不允许单机
- 分区: 一个消息.可以拆分出多个,分别存储在多个位置
- 多副本: 防止信息丢失,可以多来几个备份
- 多订阅者: 可以有很多应用连接kafka
- Zookeeper: 早期版本的Kafka依赖于zookeeper, 2021年4月19日Kafka 2.8.0正式发布
- 包括了很多重要改动,最主要的是kafka通过自我管理的仲裁来替代ZooKeeper,即Kafka将不再需要ZooKeeper!
优势 顺序写入
- Kafka 通过 O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以 TB 级别以上的消息存储也能够保持长时间的稳定性能。 也就是硬盘的顺序写入
- 高吞吐量:即使是非常普通的硬件Kafka也可以支持每秒数百万的消息。支持通过Kafka 服务器分区消息。
- 分布式: Kafka 基于分布式集群实现高可用的容错机制,可以实现自动的故障转移
- 顺序保证:在大多数使用场景下,数据处理的顺序都很重要。大部分消息队列本来就是排序的,并且能保证数据会按照特定的顺序来处理。 Kafka保证一个Partiton内的消息的有序性(分区间数据是无序的,如果对数据的顺序有要求,应将在创建主题时将分区数partitions设置为1)
- 支持 Hadoop 并行数据加载
- 通常用于大数据场合,传递单条消息比较大,而Rabbitmq 消息主要是传输业务的指令数据,单条数据较小
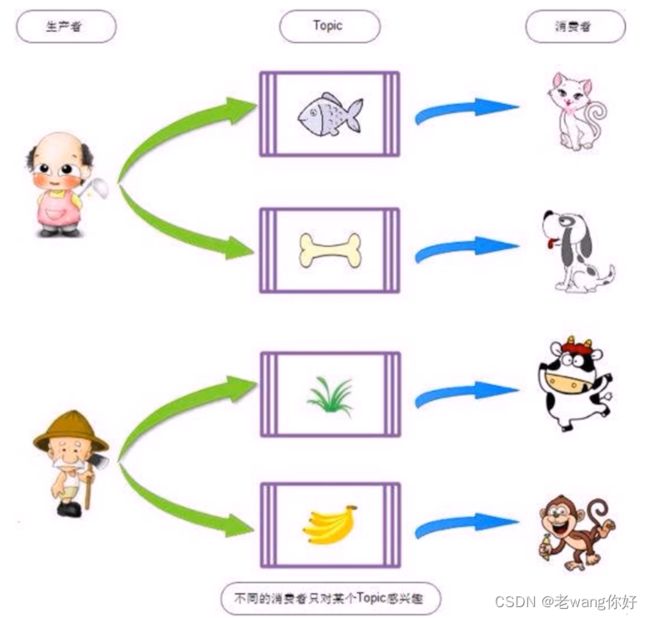 Replication: 同样数据的副本,包括leader和follower的副本数,基本于数据安全,建议至少2个,是Kafka的高可靠性的保障,和ES不同的,ES中的副本数不包括主分片数
Replication: 同样数据的副本,包括leader和follower的副本数,基本于数据安全,建议至少2个,是Kafka的高可靠性的保障,和ES不同的,ES中的副本数不包括主分片数

Kafka 写入消息的流程

Kafka 部署
官方文档:
http://kafka.apache.org/quickstart
环境准备 ZooKeeper
当前版本 Kafka 依赖 Zookeeper 服务,但以后将不再依赖
环境说明
#在三个Ubuntu18.04节点提前部署zookeeper和kafka三个节点复用
node1:10.0.0.101
node2:10.0.0.102
node3:10.0.0.103
#注意:生产中zookeeper和kafka一般是分开独立部署的,kafka安装前需要安装java环境确保三个节点的zookeeper启动
[root@node1 ~]#zkServer.sh status
各节点部署 Kafka
kafka 基于scala语言实现,所以使用kafka需要指定scala的相应的版本.kafka 为多个版本的Scala构建。这仅在使用 Scala 时才重要,并且希望为使用的相同 Scala 版本构建一个版本。否则,任何版本都可以
Kafka 节点配置
#配置文件 ./conf/server.properties内容说明
############################# Server Basics###############################
# broker的id,值为整数,且必须唯一,在一个集群中不能重复
broker.id=1
############################# Socket ServerSettings ######################
# kafka监听端口,默认9092
listeners=PLAINTEXT://10.0.0.101:9092
# 处理网络请求的线程数量,默认为3个
num.network.threads=3
# 执行磁盘IO操作的线程数量,默认为8个
num.io.threads=8
# socket服务发送数据的缓冲区大小,默认100KB
socket.send.buffer.bytes=102400
# socket服务接受数据的缓冲区大小,默认100KB
socket.receive.buffer.bytes=102400
# socket服务所能接受的一个请求的最大大小,默认为100M
socket.request.max.bytes=104857600
############################# Log Basics###################################
# kafka存储消息数据的目录
log.dirs=../data
# 每个topic默认的partition
num.partitions=1
# 设置副本数量为3,当Leader的Replication故障,会进行故障自动转移。
default.replication.factor=3
# 在启动时恢复数据和关闭时刷新数据时每个数据目录的线程数量
num.recovery.threads.per.data.dir=1
############################# Log FlushPolicy #############################
# 消息刷新到磁盘中的消息条数阈值
log.flush.interval.messages=10000
# 消息刷新到磁盘中的最大时间间隔,1s
log.flush.interval.ms=1000
############################# Log RetentionPolicy #########################
# 日志保留小时数,超时会自动删除,默认为7天
log.retention.hours=168
# 日志保留大小,超出大小会自动删除,默认为1G
#log.retention.bytes=1073741824
# 日志分片策略,单个日志文件的大小最大为1G,超出后则创建一个新的日志文件
log.segment.bytes=1073741824
# 每隔多长时间检测数据是否达到删除条件,300s
log.retention.check.interval.ms=300000
############################# Zookeeper ####################################
# Zookeeper连接信息,如果是zookeeper集群,则以逗号隔开
zookeeper.connect=10.0.0.101:2181,10.0.0.102:2181,10.0.0.103:2181
# 连接zookeeper的超时时间,6s
zookeeper.connection.timeout.ms=6000范例:
#在所有节点上执行安装java
[root@node1 ~]#apt install openjdk-8-jdk -y
#在所有节点上执行下载,官方下载
[root@node1 ~]#wget https://archive.apache.org/dist/kafka/2.7.0/kafka_2.13-
2.7.0.tgz
[root@node1 ~]#wget https://downloads.apache.org/kafka/3.3.1/kafka_2.13-
3.3.1.tgz
#国内镜像下载
[root@node1 ~]#wget
https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/3.3.1/kafka_2.13-3.3.1.tgz
[root@node1 ~]#wget
https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/3.0.0/kafka_2.13-3.0.0.tgz
[root@node1 ~]#wget https://mirror.bit.edu.cn/apache/kafka/2.7.0/kafka_2.13-
2.7.0.tgz
#解压缩
[root@node1 ~]#tar xf kafka_2.13-2.7.0.tgz -C /usr/local/
[root@node1 ~]#ln -s /usr/local/kafka_2.13-2.7.0/ /usr/local/kafka
#配置PATH变量
[root@node1 ~]#echo 'PATH=/usr/local/kafka/bin:$PATH' > /etc/profile.d/kafka.sh
[root@node1 ~]#. /etc/profile.d/kafka.sh
#修改配置文件
[root@node1 ~]#vim /usr/local/kafka/config/server.properties
broker.id=1 #每个broker在集群中每个节点的正整数唯一标识,此值保存在log.dirs下的meta.properties文件
listeners=PLAINTEXT://10.0.0.101:9092 #指定当前主机的IP做为监听地址,注意:不支持0.0.0.0
log.dirs=/usr/local/kafka/data #kakfa用于保存数据的目录,所有的消息都会存储在该目录当中
num.partitions=1 #设置创建新的topic时默认分区数量,建议和kafka的节点数量一致
default.replication.factor=3 #指定默认的副本数为3,可以实现故障的自动转移
log.retention.hours=168 #设置kafka中消息保留时间,默认为168小时即7天
zookeeper.connect=10.0.0.101:2181,10.0.0.102:2181,10.0.0.103:2181 #指定连接的zk的地址,zk中存储了broker的元数据信息
zookeeper.connection.timeout.ms=6000 #设置连接zookeeper的超时时间,单位为ms,默认6秒钟
#准备数据目录
[root@node1 ~]#mkdir /usr/local/kafka/data
[root@node1 ~]#scp /usr/local/kafka/config/server.properties
10.0.0.102:/usr/local/kafka/config
[root@node1 ~]#scp /usr/local/kafka/config/server.properties
10.0.0.103:/usr/local/kafka/config
#修改第2个节点配置
[root@node2 ~]#vim /usr/local/kafka/config/server.properties
broker.id=2 #每个broker 在集群中的唯一标识,正整数。
listeners=PLAINTEXT://10.0.0.102:9092 #指定当前主机的IP做为监听地址,注意:不支持0.0.0.0
#修改第3个节点配置
[root@node3 ~]#vim /usr/local/kafka/config/server.properties
broker.id=31 #每个broker 在集群中的唯一标识,正整数。
listeners=PLAINTEXT://10.0.0.103:9092 #指定当前主机的IP做为监听地址,注意:不支持0.0.0.0启动服务
在所有kafka节点执行下面操作
[root@node1 ~]#vim vim /usr/local/kafka/bin/kafka-server-start.sh
if[ " x$KAFKA_HEAP_OPTS"="x"] ; then
export KAFKA_HEAP_OPTS=" -Xmx1G-Xms1G" #可以调整内存
fi
[root@node1 ~]#kafka-server-start.sh -daemon
/usr/local/kafka/config/server.properties确保服务启动状态
[root@node1 ~]#ss -ntl|grep 9092
LISTEN 0 50 [::ffff:10.0.0.101]:9092 *:*
[root@node1 ~]#tail /usr/local/kafka/logs/server.log
````````````````````````````
new controller, from now on will use broker 1
(kafka.server.BrokerToControllerRequestThread)
#如果使用id,还需要修改/usr/local/kafka/data/meta.properties
#打开zooinspector可以看到三个id- Broker 依赖于 Zookeeper,每个Broker 的id 和 Topic、Partition这些元数据信息都会写入Zookeeper 的 ZNode 节点中
- consumer 依赖于Zookeeper,Consumer 在消费消息时,每消费完一条消息,会将产生的offset保存到 Zookeeper 中,下次消费在当前offset往后继续消费.kafka0.9 之前Consumer 的offset 存储在 Zookeeper 中,kafka0.9 以后offset存储在本地。
- Partition 依赖于 Zookeeper,Partition 完成Replication 备份后,选举出一个Leader,这个是依托于 Zookeeper 的选举机制实现的
准备Kafka的service文件
[root@node1 ~]#cat /lib/systemd/system/kafka.service
[unit]
Description=Apache kafka
After=network.target
[service]
Type=simple
#Environment=JAVA_HOME=/data/server/java
PIDFile=/usr/local/kafka/kafka.pid
Execstart=/usr/local/kafka/bin/kafka-server-start.sh
/usr/local/kafka/config/server. properties
Execstop=/bin/kill -TERM ${MAINPID}
Restart=always
RestartSec=20
[Install]
wantedBy=multi-user.target
[root@node1 ~]#systemctl daemon-load
[root@node1 ~]#systemctl restart kafka.service创建 Topic
创建名为 wang,partitions(分区)为3,replication(每个分区的副本数/每个分区的分区因子)为 2 的
topic(主题)
#新版命令 需要重连刷新一下/usr/local/kafka/bin/
[root@node1 ~]#/usr/local/kafka/bin/kafka-topics.sh --create --topic wang --bootstrap-server 10.0.0.101:9092 --partitions 3 --replication-factor 2
#在各节点上观察生成的相关数据
[root@node1 ~]#ls /usr/local/kafka/data/
[root@node2 ~]#ls /usr/local/kafka/data/
[root@node3 ~]#ls /usr/local/kafka/data/
#旧版命令
[root@node1 ~]#/usr/local/kafka/bin/kafka-topics.sh --create --zookeeper 10.0.0.101:2181,10.0.0.102:2181,10.0.0.103:2181 --partitions 3 --replication-
factor 2 --topic wang
Created topic wang获取所有 Topic
#新版命令
[root@node1 ~]#/usr/local/kafka/bin/kafka-topics.sh --list --bootstrap-server 10.0.0.101:9092
#旧版命令
[root@node1 ~]#/usr/local/kafka/bin/kafka-topics.sh --list --zookeeper 10.0.0.101:2181,10.0.0.102:2181,10.0.0.103:2181
wang验证 Topic 详情
状态说明:wang 有三个分区分别为0、1、2,分区0的leader是3 (broker.id),分区 0 有2 个副本,并且状态都为 lsr(ln-sync,表示可以参加选举成为 leader)。
[root@node1 ~]#/usr/local/kafka/bin/kafka-topics.sh --describe --bootstrap-
server 10.0.0.101:9092 --topic wang
Topic: wang TopicId: beg6bPXwToW1yp7cuv7F8w PartitionCount: 3
ReplicationFactor: 2 Configs:
Topic: wang Partition: 0 Leader: 3 Replicas: 3,1 Isr: 3,1
Topic: wang Partition: 1 Leader: 1 Replicas: 1,2 Isr: 1,2
Topic: wang Partition: 2 Leader: 2 Replicas: 2,3 Isr: 2,3图形工具 Offset Explorer (Kafka Tool)

Offset Explorer ,旧称Kafka Tool,工具是一个 GUI 应用程序,用于管理和使用 Apache Kafka 群集。它提供了一个直观的 UI,允许人们快速查看 Kafka 群集中的对象以及存储在群集主题中的消息。它包含面向开发人员和管理员的功能。一些关键功能包括
- 快速查看您的所有 Kafka 集群,包括其经纪人、主题和消费者
- 查看分区中邮件的内容并添加新邮件
- 查看消费者的偏移量,包括阿帕奇风暴卡夫卡喷口消费者
- 以漂亮的打印格式显示 JSON和 XML 消息
- 添加和删除主题以及其他管理功能
- 将单个邮件从分区保存到本地硬盘驱动器
- 编写自己的插件,允许您查看自定义数据格式
- Kafka 工具在Windows、Linux 和 Mac 操作系统上运行
官网:
https://www.kafkatool.com/
Dubbo 介绍

Apache Dubbo 是一款高性能、轻量级的开源RPC服务框架
Apache Dubbo 提供了六大核心能力:面向接口代理的高性能RPC调用,智能容错和负载均衡,服务自动注册和发现,高度可扩展能力,运行期流量调度,可视化的服务治理与运维。
SpringCloud 提供了微服务的全家桶的整套解决方案,Dubbo只是实现了微服务中RPC部分的功能,基本相当于SpringCloud中的Feign,还需要组合其它服务才能实现全部功能
阿里云微服务
https://promotion.aliyun.com/ntms/act/edasdubbo.html
Dubbo 官网
Apache Dubbo
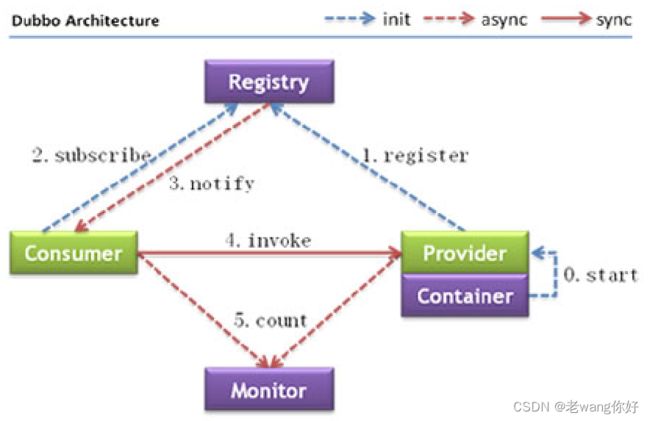 节点角色说明
节点角色说明
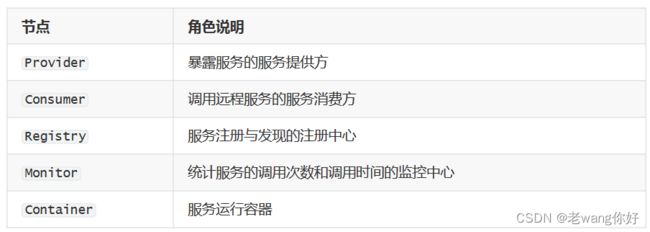
调用关系说明
1. 服务容器负责启动,加载,运行服务提供者。
2. 服务提供者在启动时,向注册中心注册自己提供的服务。
3. 服务消费者在启动时,向注册中心订阅自己所需的服务。
4. 注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者。
5. 服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失
败,再选另一台调用。
6. 服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心。
Dubbo服务框架的工作流程如下:
1. 提供者在启动时,在注册中心注册服务。
2. 消费者在启动时,在注册中心订阅所需的服务。
3. 注册中心返回提供者地址列表给消费者。如果提供者发生变更,注册中心将推送变更数据给消费
者。
4. 消费者基于软负载均衡算法,从提供者地址列表中选一个提供者进行调用。
Nacos 介绍
Nacos 致力于帮助您发现、配置和管理微服务。Nacos 提供了一组简单易用的特性集,帮助您快速实现动态服务发现、服务配置、服务元数据及流量管理。
Nacos 帮助您更敏捷和容易地构建、交付和管理微服务平台。 Nacos 是构建以“服务”为中心的现代应用架构 (例如微服务范式、云原生范式) 的服务基础设施。
实现 Dubbo 架构
首先Dubbo是依赖于网络的注册中心,服务发现等组件

环境说明
#准备三台zookeeper集群
#10.0.0.101 node1
#10.0.0.102 node2
#10.0.0.103 node3#准备两台主机充当provider
#10.0.0.104 provider1
#10.0.0.105 provider2#准备两台主机充当consumer
#10.0.0.106 consumer1
#10.0.0.107 consumer2
官方 Demo
https://github.com/apache/dubbo/tree/master/dubbo-demo
准备 ZooKeeper 提供注册中心
只支持Ubuntu18.04和Jdk8或11,但不支持Ubuntu20.04
基于 ZooKeeper 发现并管理 provider 和consumer准备环境
官方说明: https://dubbo.apache.org/zh/docs/references/registry/zookeeper/
Zookeeper 是 Apache Hadoop 的子项目,是一个树型的目录服务,支持变更推送,适合作为 Dubbo服务的注册中心,工业强度较高,可用于生产环境,并推荐使用

流程说明:
- 服务提供者启动时: 向 /dubbo/com.foo.BarService/providers 目录下写入自己的 URL 地址
- 服务消费者启动时: 订阅 /dubbo/com.foo.BarService/providers 目录下的提供者 URL 地址。
- 并向 /dubbo/com.foo.BarService/consumers 目录下写入自己的 URL 地址
- 监控中心启动时: 订阅 /dubbo/com.foo.BarService 目录下的所有提供者和消费者 URL 地址。
支持以下功能:
- 当提供者出现断电等异常停机时,注册中心能自动删除提供者信息
- 当注册中心重启时,能自动恢复注册数据,以及订阅请求
- 当会话过期时,能自动恢复注册数据,以及订阅请求
- 当设置
- 可通过
- 可通过
- 支持 * 号通配符