【NLP】jieba分词
文章目录
- 1.jieba简介
- 2.主要方法
-
- 2.1 切分方法
- 2.2 向切分依据的字典中添加、删除词语
- 2.3 添加用户自定义词典
- 2.4 使用停用词
- 2.5 统计切分结果中的词频
- 3.文章关键词提取
-
- 3.1 extract_tags()
- 3.2 textrank()
1.jieba简介
jieba库是一款优秀的 Python 第三方中文分词库,jieba 支持三种分词模式:精确模式、全模式和搜索引擎模式,下面是三种模式的特点。
精确模式:
试图将语句最精确的切分,不存在冗余数据,适合做文本分析。
全模式:
将语句中所有可能是词的词语都切分出来,速度很快,但是存在冗余数据。
搜索引擎模式:
在精确模式的基础上,对长词再次进行切分,提高召回率,适合用于搜索引擎分词。
#精确模式
jieba.lcut(text, cut_all=False)
#全模式
jieba.lcut(text, cut_all=True)
#搜索引擎模式
jieba.lcut_for_search(text)
2.主要方法
2.1 切分方法
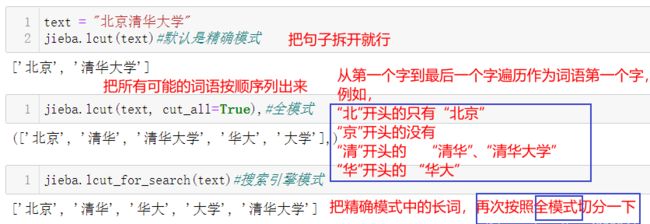
全模式和搜索引擎模式的区别
全模式是按照逐字遍历作为词语第一个字的方式;
搜索引擎模式只会对精确模式结果中长的词,再按照全模式切分一遍。
2.2 向切分依据的字典中添加、删除词语
| 方法 | 作用 |
|---|---|
| jieba.add_word(word) | 添加新的词语 |
| jieba.del_word(word) | 删除字典中已有的词语 |
之所以添加新的词语,是因为jieba并不能识别所有的词语,需要我们手动添加。

2.3 添加用户自定义词典
jieba.load_userdict()
这个作用和上面单个添加的作用一样,不过正这个是大批量添加,而且这个还可以增加描述性的赐予的词性。
我这里添加的一个实例

jieba.load_userdict("词典.txt") #加载词典,补充默认词典
jieba.lcut("我来自南京飞天大学",cut_all=True)
['我', '来自', '南京', '南京飞天大学', '飞天', '天大', '大学']
2.4 使用停用词
停用词就是那些语气词,口头禅之类的,对于研究并无实际贡献,需要删除。
作用原理就是在分词之后,手动遍历分词结果,看他是不是在停用词列表中,如果在,就把他删除。
可以选择手动删除,也可以使用jieba.analyse里的函数。
这里使用的是哈工大实验室构建的停用词表

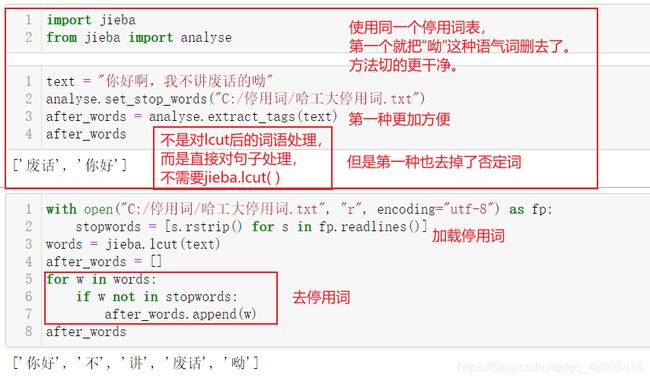
因此我们还是主要掌握函数的方法,因为他处理的更干净、且方便
analyse.set_stopwords(file) #加载停用词
analyse.extract_tags(text) #去掉停用词
2.5 统计切分结果中的词频
这个方法不是jieba中的功能,而是在collections包中的Counter方法,
作用是统计每个词的频数。

Counter()当然还可以用于别的东西,功能就是统计频次。
以上就是jieba的基本功能,还可以把分词结果用词云图的形式展现出来。
3.文章关键词提取
3.1 extract_tags()


from jieba import analyse
file = "济南的冬天.txt"
with open(file, "r", encoding="utf-8") as fp:
content = fp.read()
analyse.set_stop_words("C:/停用词/哈工大停用词.txt") #顺便去除停用词
keywords = analyse.extract_tags(content, topK=10, withWeight=False)#不显示权重
keywords
['济南', '冬天', '小山', '看吧', '花衣', '水藻', '好像', '阳光', '小雪', '一道']
3.2 textrank()


from jieba import analyse
file = "济南的冬天.txt"
with open(file, "r", encoding="utf-8") as fp:
content = fp.read()
analyse.set_stop_words("C:/停用词/哈工大停用词.txt")
keywords = analyse.textrank(content,
topK=10,
withWeight=False,
allowPOS=('ns', 'n', 'vn', 'n'))#别忘了设置需要的词性
keywords
['济南', '地方', '看吧', '小雪', '日本', '花衣', '水藻', '儿暗', '团花', '村庄']
对比 TF - IDF 的结果
['济南', '冬天', '小山', '看吧', '花衣', '水藻', '好像', '阳光', '小雪', '一道']