<<视觉Transformer>>2021:Bottleneck Transformers for Visual Recognition

本专栏只研究vision Transformer的原理,对实验不做过多研究。
目录
摘要:
一、介绍
二、相关工作
三、方法
四、实验
五、结论
摘要:
我们提出了BoTNet,这是一个概念简单但功能强大的主干架构,它将自注意结合到多个计算机视觉任务中,包括图像分类、目标检测和实例分割。通过在ResNet的最后三个bottleneck blocks中使用全局自注意替换空间卷积,并且不做其他改变,我们的方法在实例分割和对象检测方面显著改善了基线,同时减少了参数。通过BoTNet的设计,我们还指出了如何将ResNet bottleneck block视为Transformer块。
一、介绍
大多数的标准深度卷积架构使用3x3卷积。
卷积运算可以有效地捕获局部信息,而目标检测、实例分割、关键点检测等视觉任务需要建模长距离依赖关系。例如,在实例分割中,能够从一个大的邻域收集和关联场景信息,对于学习对象之间的关系很有用。为了能捕获全局的信息,基于卷积的架构需要叠加多层,扩大感受野。尽管叠加更多的层确实提高了这些骨干的性能,但Transformer这种显式的机制来建模全局(非本地)依赖关系可能是一个更强大和可扩展的解决方案,而且不需要那么多层。
自注意机制是一种计算基元,已经成为NLP中的Transformer块形式的标准工具,例如GPT和BERT模型。
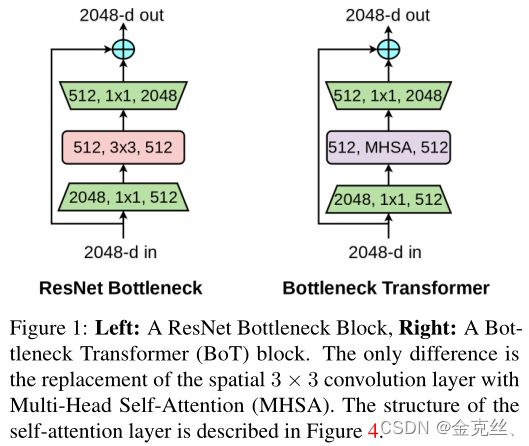
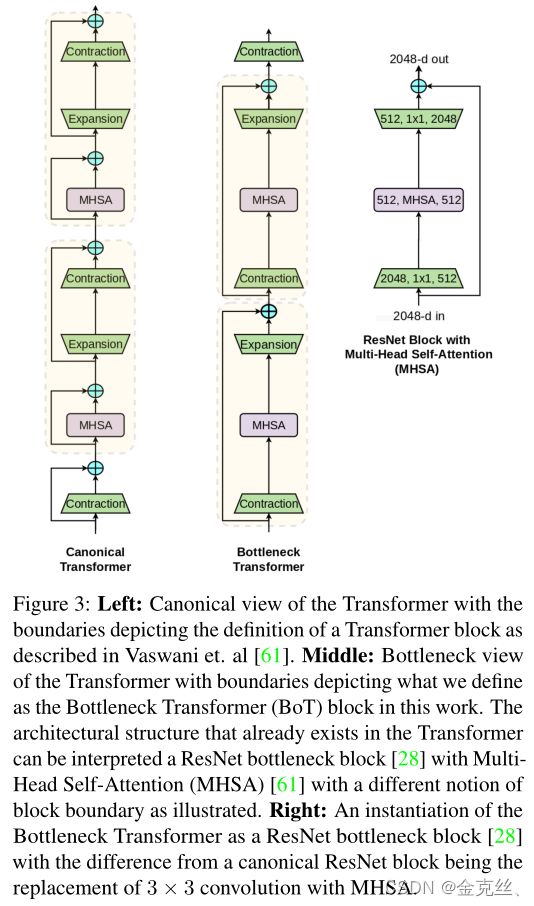
在视觉中使用自注意的一种简单方法是将空间卷积层替换为Transformer提出的多头自我注意(MHSA)层(图1)。一方面,我们有诸如SASA[49]、AACN[4]、SANet[68]、Axial-SASA[62]等模型,它们提出用不同形式的自注意(local、global、vector、axial等)来替换ResNet bottleneck block中的空间卷积。另一方面,我们有Vision Transformer (ViT)[15],它提出运行在非重叠patch的线性投影上的堆叠的Transformer block。带有MHSA层的ResNet bottleneck block可以被看作是具有bottleneck结构的Transformer block,对诸如残差连接、归一化层的选择等只做很小的处理(图3)。因此,我们将ResNet和MHSA层的bottleneck block称为bottleneck block transformer(BoT)块。
以下是在视觉中使用自注意时面临的一些挑战:(1)在对象检测和实例分割方面,与图像分类(224×224)相比,图像尺寸要大得多(1024×1024)。(2)自注意层的计算量随着分辨率的增大呈二次方增大。
为了克服这些挑战,我们考虑以下设计:(1)使用卷积有效地从大图像中学习抽象和低分辨率特征地图;(2)利用全局(all2all)自注意对卷积捕获的特征图中包含的信息进行处理和聚合。这样的混合设计:(1)使用现有的和良好优化的卷积模型和全局自注意;(2)可以有效地处理大图像,通过卷积进行空间下采样,让注意力在较小的分辨率上工作。下面是这种混合设计的一个简单实例:用BoT块替换ResNet的最后三个bottleneck blocks,不做任何其他更改。换句话说,取一个ResNet,只将最终的3个3×3卷积替换为MHSA层(图1,表1)。我们将这个简单的实例化称为BoTNet,因为它通过BoT块连接到Transformer。虽然我们注意到它的构造没有什么新奇之处,但我们相信它的简单性和性能使它成为一个值得研究的有用的参考主干体系结构。
二、相关工作
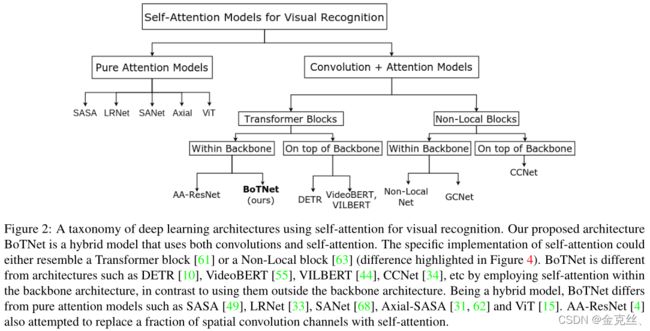
图2展示了一种利用自注意实现视觉的深度学习体系结构的分类。在本节中,我们将重点关注:(1)Transformer vs BoTNet;(2) DETR vs BoTNet;(3)非局部注意力 vs BoTNet。
Connection to the Transformer 正如文章标题所示,本文的一个关键信息是,具有多头自注意(MHSA)层的ResNet bottleneck blocks可以被视为具有bottleneck blocks结构的Transformer块。图3直观地解释了这一点,我们将此块命名为bottleneck Transformer(BoT)。我们注意到,BoT的设计不是我们的贡献,相反,我们指出了MHSA ResNet bottleneck blocks和Transformer之间的关系,希望它能提高我们对计算机视觉中自我关注的架构设计空间的理解。(1)归一化:transformer使用Layer Normalization,而BoT块使用Batch Normalization,这是ResNet bottleneck blocks的典型;(2)非线性:transformer在FFN块中使用一个非线性,而ResNet结构允许BoT块使用三个非线性;(3)输出投影:Transformer中的MHSA块包含输出投影,而BoT块中的MHSA层(图4)没有输出投影;(4)我们将SGD与通常用于计算机视觉的动量优化器一起使用,而transformer通常使用Adam优化器进行训练。
Connection to DETR DETR (Detection Transformer)是一个检测框架,它使用Transformer隐式的执行region proposals和对象定位,而不是使用R-CNN。DETR和BoTNet都使用自注意来提高对象检测和实例(或全景)分割的性能。不同之处在于,DETR在主干架构之外使用Transformer块,动机是为了简化而去除region proposals和非nms。另一方面,BoTNet的目标是提供一个主干架构,使用类似transformer的块进行检测和实例分割。
Connection to Non-Local Neural Nets Non-Local (NL) Nets在Transformer和Non-Local- means算法之间建立连接。他们将NL块插入ResNet中的最后一个(或)两个block(c4,c5),并提高了视频识别和实例分割的性能。和NL-Nets一样,BoTNet是一种混合设计,使用卷积和全局自注意。(1) NL层和MHSA层之间的三个区别(如图4所示):在MHSA中使用多个头、value投影和位置编码;(2) NL块使用通道系数减少为2的bottleneck(而不是采用ResNet结构的4);(3)在ResNet主干中插入NL块作为额外的块,而不是像BoTNet那样替换现有的卷积块。
三、方法
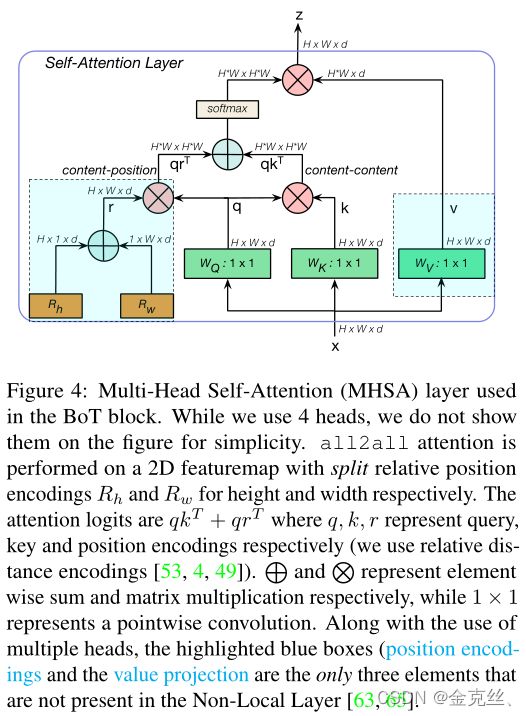
BoTNet的设计很简单:将ResNet中的最后三个空间(3×3)卷积替换为multi head Self-Attention (MHSA)层,该层在2D特征图(Fig4)上实现全局(all2all)自注意。ResNet通常有4个stage(或block groups),通常被称为[c2,c3,c4,c5],对应于输入图像的步长[4,8,16,32]。Stacks[c2,c3,c4,c5]由多个具有残差连接的bottleneck blocks组成(例如,R50有[3,4,6,3]bottleneck blocks)。
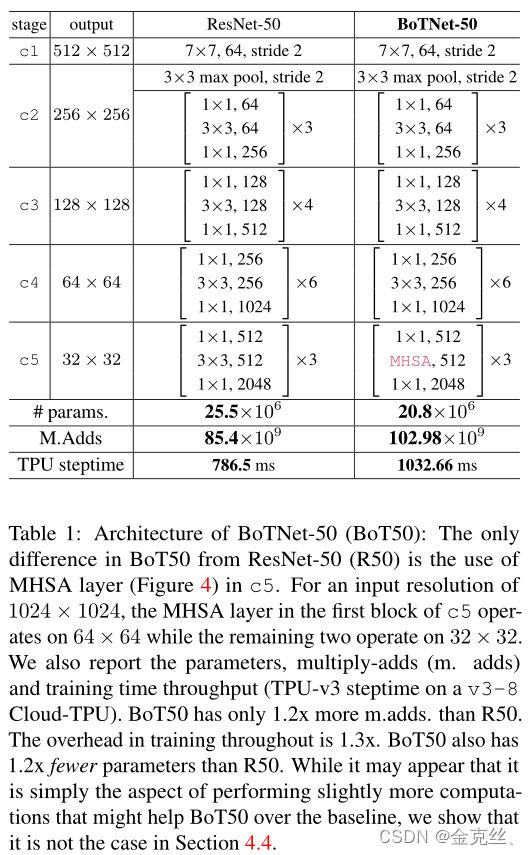
在整个主干中使用自注意的方法对于输入分辨率(224×224(用于分类)和640×640(用于SASA中的检测)是可行的。我们的目标是在更真实的高性能实例分割模型中使用注意力,通常使用更大分辨率的图像(1024×1024)。考虑到在整个网络中执行全局的自注意需要非常大内存和计算量,我们认为,最简单的设置,就是合并自注意在低分辨率的特征图上,即c5 stack中的残差块。ResNet主干中的c5 stack通常使用3个block,每个block中有一个3×3卷积。用MHSA层替换它们构成了BoTNet架构的基础。第一个block 使用了步长2的3×3卷积,而另外两个块使用了1的步长。由于all2all 注意力不是一个跨步操作,我们使用2×2平均池化与步长2作为第一个BoT块。BoTNet架构如表1所示,MHSA层如图4所示。
Relative Position Encodings 为了使注意力操作能够感知位置,基于Transformer的体系结构通常使用位置编码。在BotNet中,我们采用了来自[49,4]的2D相对位置自注意实现。
四、实验
请看原论文。
五、结论
没什么。