机器学习 最大熵模型
一.信息熵
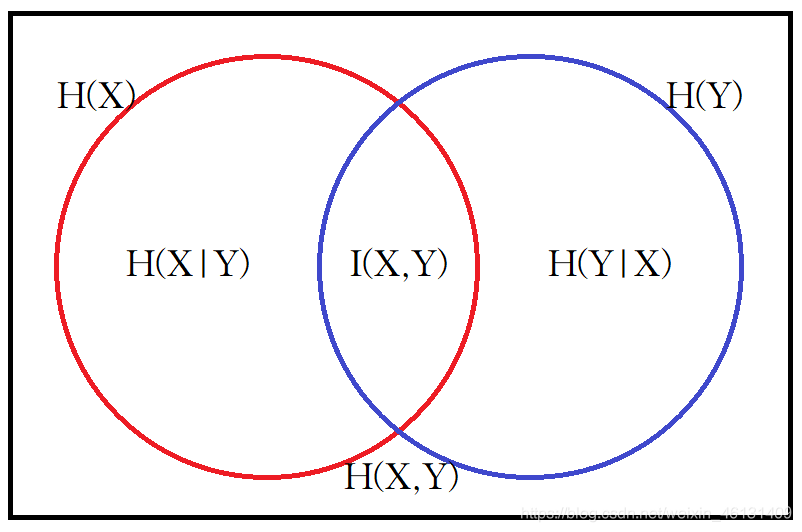
1.信息熵
(1)概述:
该概念由克劳德·艾尔伍德·香农在1948年首次提出,最初来自于热力学中熵的概念.为避免混淆,故称为信息熵(Entropy).这是1个用于度量信息的不确定性的抽象概念.由于1条信息的信息量的大小与其不确定性有直接关系,如为了弄清楚1件高度不确定的事,就需要大量信息,因此对不确定性的度量就相当于对信息量(或预期需求的信息量)的度量
(2)定义:
信息熵 H ( X ) H(X) H(X)被定义为 H ( X ) = − ∑ x P ( x ) log 2 P ( x ) H(X)=-\sum_x{P(x)\log_2P(x)} H(X)=−x∑P(x)log2P(x)
单位为比特(bit).信息熵也可以 e e e为底数,即 H ( X ) = − ∑ x P ( x ) ln P ( x ) H(X)=-\sum_x{P(x)\ln P(x)} H(X)=−x∑P(x)lnP(x)此时单位为奈特(nat).变量的不确定性越大,信息熵也就越大:当 X ∼ U ( a , b ) X\sim U(a,b) X∼U(a,b)时,信息熵最大;当 X X X为定值时,信息熵最小;在给定均值 μ μ μ和方差 σ 2 σ^2 σ2的前提下,当 X ∼ N ( μ , σ 2 ) X\sim N(μ,σ^2) X∼N(μ,σ2)时,信息熵最大
(3)最大熵定理:
最大熵定理表明 0 ≤ H ( X ) ≤ log ∣ X ∣ 0≤H(X)≤\log{|X|} 0≤H(X)≤log∣X∣
(4)信息熵的加总:
各部分的信息熵可以进行加总:设总信息熵为 H ( X ) H(X) H(X),第 i i i部分的信息熵为 H i ( X ) H_i(X) Hi(X),第 i i i部分占总体的比例为 p i p_i pi,则 H ( X ) = ∑ i = 1 m p i H i ( X ) H(X)=\displaystyle\sum_{i=1}^mp_iH_i(X) H(X)=i=1∑mpiHi(X)
2.联合熵
(1)概述:
联合熵(Joint Entropy)用于度量2个事件共同发生时的不确定性
(2)定义:
随机变量 X , Y X,Y X,Y的联合熵被定义为 H ( X , Y ) = − ∑ x , y P ( x , y ) log 2 P ( x , y ) H(X,Y)=-\sum_{x,y}P(x,y)\log_2P(x,y) H(X,Y)=−x,y∑P(x,y)log2P(x,y)
3.条件熵
(1)概述:
条件熵(Conditional Entropy)用于度量在1个事件发生的前提下,另1个事件的不确定性
注:当熵和条件熵中的概率由数据估计(特别是极大似然估计)得到时,称为经验熵(Empirical Entropy)和经验条件熵(Empirical Conditional Entropy)
(2)定义:
随机变量 X , Y X,Y X,Y的条件熵被定义为 H ( X ∣ Y ) = H ( X , Y ) − H ( Y ) = − ∑ x , y P ( x , y ) log 2 P ( x ∣ y ) H(X\,|\,Y)=H(X,Y)-H(Y)=-\sum_{x,y}P(x,y)\log_2P(x\,|\,y) H(X∣Y)=H(X,Y)−H(Y)=−x,y∑P(x,y)log2P(x∣y)可证明 H ( X ∣ Y ) ≤ H ( X ) H(X\,|\,Y)≤H(X) H(X∣Y)≤H(X)
4.相对熵
(1)概述:
相对熵(Relative Entropy)又称交叉熵/互熵(Cross Entropy),鉴别信息(Authentication Information),库尔贝克-莱布勒熵(Kullback-Leibler Entropy),库尔贝克-莱布勒散度(Kullback-Leibler Divergence;KL Divergence)或信息散度(Information Divergence),是2个概率分布间差异的非对称性度量
(2)定义:
概率分布 P ( x ) , Q ( x ) P(x),Q(x) P(x),Q(x)的相对熵被定义为 K L ( P ∣ ∣ Q ) = ∑ x P ( x ) log 2 P ( x ) log 2 Q ( x ) = E x ∼ P ( x ) ( log 2 P ( x ) Q ( x ) ) ≥ 0 KL(P\,||\,Q)=\sum_xP(x)\frac{\log_2P(x)}{\log_2Q(x)}=E_{x\sim P(x)}(\log_2\frac{P(x)}{Q(x)})≥0 KL(P∣∣Q)=x∑P(x)log2Q(x)log2P(x)=Ex∼P(x)(log2Q(x)P(x))≥0当且仅当 P = Q , K L ( P ∣ ∣ Q ) = 0 P=Q,KL(P\,||\,Q)=0 P=Q,KL(P∣∣Q)=0.通常 K L ( P ∣ ∣ Q ) ≠ K L ( Q ∣ ∣ P ) KL(P\,||\,Q)≠KL(Q\,||\,P) KL(P∣∣Q)=KL(Q∣∣P)
(3)概率分布的近似:
假设存在某个未知的概率分布 P P P,希望使用概率分布 Q Q Q来近似 P P P,则有2种可能的目标:
①目标为 min Q K L ( Q ∣ P ) \underset{Q}{\min}\:{KL(Q\,|\,P)} QminKL(Q∣P)此时需要在 P P P接近0的位置, Q Q Q也尽可能接近0,会得到比较窄的分布
②目标为 min Q K L ( P ∣ Q ) \underset{Q}{\min}\:{KL(P\,|\,Q)} QminKL(P∣Q)此时需要在 P P P远离0的位置, Q Q Q也尽可能远离0,会得到比较宽的分布
5.互信息
(1)概述:
互信息(Mutual Information)用于度量1个事件中包含的关于另1个事件的信息量
(2)定义:
随机变量 X , Y X,Y X,Y的互信息被定义为 I ( X , Y ) = K L ( P ( x , y ) ∣ ∣ P ( x ) P ( y ) ) = ∑ x , y P ( x , y ) log 2 P ( x , y ) log 2 P ( x ) P ( y ) I(X,Y)=KL(P(x,y)\,||\,P(x)P(y))=\sum_{x,y}P(x,y)\frac{\log_2P(x,y)}{\log_2P(x)P(y)} I(X,Y)=KL(P(x,y)∣∣P(x)P(y))=x,y∑P(x,y)log2P(x)P(y)log2P(x,y)
(3)互信息与联合熵:
可证明 I ( X , Y ) = H ( X ) − H ( X ∣ Y ) = H ( X ) + H ( Y ) − H ( X , Y ) I(X,Y)=H(X)-H(X\,|\,Y)=H(X)+H(Y)-H(X,Y) I(X,Y)=H(X)−H(X∣Y)=H(X)+H(Y)−H(X,Y)有些文献使用上述2式之一定义互信息
二.最大熵模型
1.最大熵原理:
"最大熵原理"(Maximum Entropy Principle)认为:在所有可能的概率模型中,熵最大的模型是最好的模型.若模型需要满足一些约束条件,则
最大熵原理要求在所有满足已知约束条件的模型中,找到熵最大的那个.也就是说在满足所有约束条件的前提下,不对未知情况做任何主观假设(称为
"无偏(好)原则",要求概率分布尽可能均匀).这时模型的熵最大,预测风险最小
2.最大熵模型
参见:https://zhuanlan.zhihu.com/p/29978153,https://blog.csdn.net/v_july_v/article/details/40508465
(1)概念:
"最大熵模型"(Maximum Entropy Model)是将最大熵原理应用到分类问题而得到的模型,即所有满足已知约束条件的模型中熵(通常使用条件
熵)最大(等价于概率分布最均匀)的那个,比如:
已知"学习"可能是动词或名词;可能是主语,谓语,宾语或定语.令 x 1 x_1 x1表示"学习"为名词, x 2 x_2 x2表示"学习"为动词, y 1 y_1 y1表示"学习"为主语, y 2 y_2 y2表示"学习"为谓语, y 3 y_3 y3表示"学习"为宾语, y 4 y_4 y4表示"学习"为定语.易知模型应满足 P ( x 1 ) + P ( x 2 ) = 1 P ( y 1 ) + P ( y 2 ) + P ( y 3 ) + P ( y 4 ) = 1 P(x_1)+P(x_2)=1\\P(y_1)+P(y_2)+P(y_3)+P(y_4)=1 P(x1)+P(x2)=1P(y1)+P(y2)+P(y3)+P(y4)=1根据无偏好原则,模型应满足 P ( x 1 ) = P ( x 2 ) P ( y 1 ) = P ( y 2 ) = P ( y 3 ) = P ( y 4 ) P(x_1)=P(x_2)\\P(y_1)=P(y_2)=P(y_3)=P(y_4) P(x1)=P(x2)P(y1)=P(y2)=P(y3)=P(y4)故最优模型为 P ( x 1 ) = P ( x 2 ) = 1 2 P ( y 1 ) = P ( y 2 ) = P ( y 3 ) = P ( y 4 ) = 1 4 P(x_1)=P(x_2)=\frac{1}{2}\\P(y_1)=P(y_2)=P(y_3)=P(y_4)=\frac{1}{4} P(x1)=P(x2)=21P(y1)=P(y2)=P(y3)=P(y4)=41若从其他渠道得知 P ( y 4 ) = 1 20 P(y_4)=\frac{1}{20} P(y4)=201,则最优模型变为 P ( x 1 ) = P ( x 2 ) = 1 2 P ( y 1 ) = P ( y 2 ) = P ( y 3 ) = 19 60 P ( y 4 ) = 1 20 P(x_1)=P(x_2)=\frac{1}{2}\\P(y_1)=P(y_2)=P(y_3)=\frac{19}{60}\\P(y_4)=\frac{1}{20} P(x1)=P(x2)=21P(y1)=P(y2)=P(y3)=6019P(y4)=201若从其他渠道又得知 P ( y 2 ∣ x 1 ) = 19 20 P(y_2\,|\,x_1)=\frac{19}{20} P(y2∣x1)=2019,则最优模型变为 max H ( Y ∣ X ) = − ∑ x ∈ { x 1 , x 2 } y ∈ { y 1 , y 2 , y 3 , y 4 } P ( x , y ) log 2 P ( y ∣ x ) s . t . { P ( x 1 ) + P ( x 2 ) = 1 P ( y 1 ) + P ( y 2 ) + P ( y 3 ) + P ( y 4 ) = 1 P ( y 4 ) = 1 20 P ( y 2 ∣ x 1 ) = 19 20 \max\:H(Y\,|\,X)=\underset{\quad x∈\{x_1,x_2\}\atop\quad y∈\{y_1,y_2,y_3,y_4\}}{-\displaystyle\sum}P(x,y)\log_2P(y\,|\,x)\\s.t.\begin{cases}P(x_1)+P(x_2)=1\\P(y_1)+P(y_2)+P(y_3)+P(y_4)=1\\P(y_4)=\frac{1}{20}\\P(y_2\,|\,x_1)=\frac{19}{20}\end{cases} maxH(Y∣X)=y∈{y1,y2,y3,y4}x∈{x1,x2}−∑P(x,y)log2P(y∣x)s.t.⎩⎪⎪⎪⎨⎪⎪⎪⎧P(x1)+P(x2)=1P(y1)+P(y2)+P(y3)+P(y4)=1P(y4)=201P(y2∣x1)=2019
(2)一般形式:
对特征(注意:最大熵模型中"特征"的概念与其他模型中不同) ( x i , y i ) (x_i,y_i) (xi,yi),定义特征函数(注意:具体问题中也可能使用其他特征函数): f i ( x , y ) = { 1 i f x = x i ∧ y = y i 0 o t h e r w i s e f_i(x,y)=\begin{cases}1\,if\:x=x_i∧y=y_i\\0\:otherwise\end{cases} fi(x,y)={1ifx=xi∧y=yi0otherwise f i ( x , y ) f_i(x,y) fi(x,y)在样本中的期望值为 E ˉ ( f i ) = ∑ x , y P ˉ ( x , y ) f i ( x , y ) \bar{E}(f_i)=\displaystyle\sum_{x,y}\bar{P}(x,y)f_i(x,y) Eˉ(fi)=x,y∑Pˉ(x,y)fi(x,y)其中 P ˉ ( x , y ) \bar{P}(x,y) Pˉ(x,y)是 ( x , y ) (x,y) (x,y)在样本中出现的频率.同时 f i ( x , y ) f_i(x,y) fi(x,y)在模型中的期望值为 E ( f ) = ∑ x , y P ( x , y ) f i ( x , y ) = ∑ x , y P ( x ) P ( y ∣ x ) f i ( x , y ) = ∑ x , y P ˉ ( x ) P ( y ∣ x ) f i ( x , y ) E(f)=\displaystyle\sum_{x,y}P(x,y)f_i(x,y)\\\qquad\qquad\:\:\,=\displaystyle\sum_{x,y}P(x)P(y\,|\,x)f_i(x,y)\\\qquad\qquad\:=\displaystyle\sum_{x,y}\bar{P}(x)P(y\,|\,x)f_i(x,y) E(f)=x,y∑P(x,y)fi(x,y)=x,y∑P(x)P(y∣x)fi(x,y)=x,y∑Pˉ(x)P(y∣x)fi(x,y)其中 P ( x ) P(x) P(x)是 x x x在模型中出现的概率; P ˉ ( x ) \bar{P}(x) Pˉ(x)是 x x x在样本中出现的频率; P ( y ∣ x ) P(y\,|\,x) P(y∣x)是 y y y在模型中在 x x x下的条件概率.对每个特征 ( x i , y i ) (x_i,y_i) (xi,yi),要求模型所建立的条件概率分布和训练样本表现出的分布相同,即 E ( f i ) = E ˉ ( f i ) E(f_i)=\bar{E}(f_i) E(fi)=Eˉ(fi)则最大熵模型的一般形式为 max P ( y ∣ x ) H ( Y ∣ X ) = − ∑ x , y P ( x , y ) ln P ( y ∣ x ) = − ∑ x , y P ( y ∣ x ) P ˉ ( x ) ln P ( y ∣ x ) s . t . { E ( f i ) = E ˉ ( f i ) E ( f i ) = ∑ x , y P ˉ ( x ) P ( y ∣ x ) f i ( x , y ) E ˉ ( f i ) = ∑ x , y P ˉ ( x , y ) f i ( x , y ) ∑ y P ( y ∣ x ) = 1 \underset{P(y\,|\,x)}{\max}\:H(Y\,|\,X)=-\displaystyle\sum_{x,y}P(x,y)\ln{P(y\,|\,x)}\\\qquad\qquad\qquad\qquad\:\:\:\,=-\displaystyle\sum_{x,y}P(y\,|\,x)\bar{P}(x)\ln{P(y\,|\,x)}\\\quad s.t.\:\begin{cases}E(f_i)=\bar{E}(f_i)\\E(f_i)=\displaystyle\sum_{x,y}\bar{P}(x)P(y\,|\,x)f_i(x,y)\\\bar{E}(f_i)=\displaystyle\sum_{x,y}\bar{P}(x,y)f_i(x,y)\\\displaystyle\sum_yP(y\,|\,x)=1\end{cases} P(y∣x)maxH(Y∣X)=−x,y∑P(x,y)lnP(y∣x)=−x,y∑P(y∣x)Pˉ(x)lnP(y∣x)s.t.⎩⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎧E(fi)=Eˉ(fi)E(fi)=x,y∑Pˉ(x)P(y∣x)fi(x,y)Eˉ(fi)=x,y∑Pˉ(x,y)fi(x,y)y∑P(y∣x)=1
3.求解
(1)解析解:
最大熵模型的一般形式的拉格朗日函数为 L ( P , λ ) = ∑ x , y P ( y ∣ x ) P ˉ ( x ) ln 1 P ( y ∣ x ) + ∑ i [ λ i ∑ x , y f i ( x , y ) ( P ˉ ( x ) P ( y ∣ x ) − P ˉ ( x , y ) ) ] + λ 0 ∑ y ( P ( y ∣ x ) − 1 ) L(P,λ)=\displaystyle\sum_{x,y}P(y\,|\,x)\bar{P}(x)\ln{\frac{1}{P(y\,|\,x)}}+\sum_i[λ_i\sum_{x,y}f_i(x,y)(\bar{P}(x)P(y\,|\,x)-\bar{P}(x,y))]+λ_0\displaystyle\sum_y(P(y\,|\,x)-1) L(P,λ)=x,y∑P(y∣x)Pˉ(x)lnP(y∣x)1+i∑[λix,y∑fi(x,y)(Pˉ(x)P(y∣x)−Pˉ(x,y))]+λ0y∑(P(y∣x)−1)利用利用拉格朗日对偶性可知,原问题等价于 max P min λ L ( P , λ ) \underset{P}{\max}\:\underset{λ}{\min}\:L(P,λ) PmaxλminL(P,λ)通过交换极大和极小的位置,可以得到与其等价的对偶问题 min λ max P L ( P , λ ) \underset{λ}{\min}\:\underset{P}{\max}\:L(P,λ) λminPmaxL(P,λ)最优解的1阶必要条件为 ∂ L ∂ P ( y ∣ x ) = P ˉ ( x ) ( ln 1 P ( y ∣ x ) − 1 ) + ∑ i λ i f i ( x , y ) P ˉ ( x ) + λ 0 = 0 ( 1 ) P ∗ ( y ∣ x ) = e ∑ i λ i f i ( x , y ) + λ 0 P ˉ ( x ) − 1 \frac{\partial{L}}{\partial{P(y\,|\,x)}}=\bar{P}(x)(\ln{\frac{1}{P(y\,|\,x)}}-1)+\sum_iλ_if_i(x,y)\bar{P}(x)+λ_0=0\qquad(1)\\\qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad P^*(y\,|\,x)=e^{\sum_iλ_if_i(x,y)+\frac{λ_0}{\bar{P}(x)}-1} ∂P(y∣x)∂L=Pˉ(x)(lnP(y∣x)1−1)+i∑λifi(x,y)Pˉ(x)+λ0=0(1)P∗(y∣x)=e∑iλifi(x,y)+Pˉ(x)λ0−1简写为 P ∗ ( y ∣ x ) = e ∑ i λ i f i ( x , y ) Z λ ( x ) P^*(y\,|\,x)=\frac{e^{\sum_iλ_if_i(x,y)}}{Z_λ(x)} P∗(y∣x)=Zλ(x)e∑iλifi(x,y)其中 Z λ ( x ) Z_λ(x) Zλ(x)称为规范化因子.由最后1项约束条件有 ∑ y e ∑ i λ i f i ( x , y ) Z λ ( x ) = 1 Z λ ( x ) = ∑ y e ∑ i λ i f i ( x , y ) \sum_y\frac{e^{\sum_iλ_if_i(x,y)}}{Z_λ(x)}=1\\\qquad\qquad\qquad\qquad\quad\:\:\, Z_λ(x)=\sum_ye^{\sum_iλ_if_i(x,y)} y∑Zλ(x)e∑iλifi(x,y)=1Zλ(x)=y∑e∑iλifi(x,y)从而得到 P ∗ ( y ∣ x ) = e ∑ i λ i f i ( x , y ) Z λ ( x ) = e ∑ i λ i f i ( x , y ) ∑ y e ∑ i λ i f i ( x , y ) ( 2 ) P^*(y\,|\,x)=\frac{e^{\sum_iλ_if_i(x,y)}}{Z_λ(x)}\\\qquad\qquad\qquad\qquad\:\:=\frac{e^{\sum_iλ_if_i(x,y)}}{\sum_ye^{\sum_iλ_if_i(x,y)}}\qquad(2) P∗(y∣x)=Zλ(x)e∑iλifi(x,y)=∑ye∑iλifi(x,y)e∑iλifi(x,y)(2)将 ( 2 ) (2) (2)式带入 L L L得到 min λ L ( λ ) = ∑ x , y P ( y ∣ x ) P ˉ ( x ) ln Z λ ( x ) − ∑ i ( P ˉ ( x , y ) ∑ x , y λ i f i ( x , y ) ) ( 3 ) \underset{λ}{\min}\:L(λ)=\displaystyle\sum_{x,y}P(y\,|\,x)\bar{P}(x)\ln{Z_λ(x)}-\sum_i(\bar{P}(x,y)\sum_{x,y}λ_if_i(x,y))\qquad(3) λminL(λ)=x,y∑P(y∣x)Pˉ(x)lnZλ(x)−i∑(Pˉ(x,y)x,y∑λifi(x,y))(3)此时 λ i λ_i λi未知.理论上来说,将 ( 2 ) (2) (2)式带入 ( 1 ) (1) (1)式即可解出 ∑ i λ i f i ( x , y ) \sum_iλ_if_i(x,y) ∑iλifi(x,y),从而得到 P ∗ ( y ∣ x ) P^*(y\,|\,x) P∗(y∣x).但实际上不存在显式的解析解,故需要求数值解
(2)数值解:
可以使用通用的最优化方法如梯度下降,牛顿法,拟牛顿法;也可以使用为最大熵模型量身定制的2个最优化方法,即通用迭代尺度法(General Iterative Scaling;GIS)和改进的迭代尺度法(Improved Iterative Scaling;IIS;目前求解最大熵模型的最优算法)
4.优缺点
(1)优点:
①准确率较高
②可以灵活地设置约束条件,可通过约束条件数调节模型对未知数据的适应度和对已知数据的拟合程度
(2)缺点:
①由于约束条件数常与样本数有关,因此当样本数增多时,约束条件数也会增加,导致计算量大幅增加
5.与极大似然估计的关系:
最大熵模型和极大似然估计的目标函数的形式相同,也就是说熵最大的解也是最符合样本数据分布的解,这证明了最大熵模型的合理性.这是因为最
大熵模型是对不确定性的无偏分配,极大似然估计是对知识的无偏理解,而知识是不确定性的补集.故从本质上讲,最大熵模型就是极大似然估计,但
前者更容易建立目标函数
极大似然估计则要求 max P L = ln ∏ x P ( x ) P ˉ ( x ) = ∑ x P ˉ ( x ) ln P ( x ) \underset{P}{\max}\:L=\ln{\prod_xP(x)^{\bar{P}(x)}}\\\qquad\quad\:\:\:\,=\sum_x\bar{P}(x)\ln{P(x)} PmaxL=lnx∏P(x)Pˉ(x)=x∑Pˉ(x)lnP(x)其中 P ( x ) P(x) P(x)是根据模型得到的概率分布, P ˉ ( x ) \bar{P}(x) Pˉ(x)是样本的分布,从而最大熵模型的目标为 max P L ( P ) = ∑ x , y P ˉ ( x , y ) ln P ( x , y ) = ∑ x , y P ˉ ( x , y ) ln ( P ˉ ( x ) P ( y ∣ x ) ) = ∑ x , y P ˉ ( x , y ) ln P ( y ∣ x ) + ∑ x , y P ˉ ( x , y ) ln P ˉ ( x ) \underset{P}{\max}\:L(P)=\sum_{x,y}\bar{P}(x,y)\ln{P(x,y)}\\\qquad\qquad\qquad\quad\:\:\:\:=\sum_{x,y}\bar{P}(x,y)\ln{(\bar{P}(x)P(y\,|\,x))}\\\qquad\qquad\qquad\qquad\qquad\qquad\qquad=\sum_{x,y}\bar{P}(x,y)\ln{P(y\,|\,x)}+\sum_{x,y}\bar{P}(x,y)\ln{\bar{P}(x)} PmaxL(P)=x,y∑Pˉ(x,y)lnP(x,y)=x,y∑Pˉ(x,y)ln(Pˉ(x)P(y∣x))=x,y∑Pˉ(x,y)lnP(y∣x)+x,y∑Pˉ(x,y)lnPˉ(x)这相当于(因为第2项是常数) max P M L E = ∑ x , y P ˉ ( x , y ) ln P ( y ∣ x ) ( 4 ) \underset{P}{\max}\:{MLE=\sum_{x,y}\bar{P}(x,y)\ln{P(y\,|\,x)}}\qquad(4) PmaxMLE=x,y∑Pˉ(x,y)lnP(y∣x)(4)将最大熵模型的最优解带入 ( 4 ) (4) (4)式,得到 max λ M L E = ∑ x , y P ˉ ( x , y ) ( ∑ i λ i f i ( x , y ) − ln Z λ ( x ) ) = ∑ x , y ( P ˉ ( x , y ) ∑ i λ i f i ( x , y ) ) − ∑ x , y P ˉ ( x , y ) ln Z λ ( x ) = ∑ x , y ( P ˉ ( x , y ) ∑ i λ i f i ( x , y ) ) − ∑ x P ˉ ( x ) ln Z λ ( x ) \underset{λ}{\max}\:MLE=\sum_{x,y}\bar{P}(x,y)(\sum_iλ_if_i(x,y)-\ln{Z_λ(x)})\\\qquad\qquad\qquad\qquad\quad\:\:\:\,=\sum_{x,y}(\bar{P}(x,y)\sum_iλ_if_i(x,y))-\sum_{x,y}\bar{P}(x,y)\ln{Z_λ(x)}\\\qquad\qquad\qquad\qquad\:\:\,=\sum_{x,y}(\bar{P}(x,y)\sum_iλ_if_i(x,y))-\sum_{x}\bar{P}(x)\ln{Z_λ(x)} λmaxMLE=x,y∑Pˉ(x,y)(i∑λifi(x,y)−lnZλ(x))=x,y∑(Pˉ(x,y)i∑λifi(x,y))−x,y∑Pˉ(x,y)lnZλ(x)=x,y∑(Pˉ(x,y)i∑λifi(x,y))−x∑Pˉ(x)lnZλ(x)这与 ( 3 ) (3) (3)式等价.其中 M L E MLE MLE称为最大熵模型的对数似然函数(Log-Likelihood Function)
三.迭代尺度法
1.通用迭代尺度法:
略
2.改进的迭代尺度法
(1)基本思想:
假设当前参数为λ,试图找到新的参数λ+δ,使最大熵模型的对数似然函数尽可能增大.重复上述过程,直到收敛
(2)步骤:
可以得到 M L E ( λ + δ ) − M L E ( λ ) = ∑ x , y ( P ˉ ( x , y ) ∑ i δ i f i ( x , y ) ) − ∑ x P ˉ ( x ) ln Z λ + δ ( x ) Z λ ( x ) ≥ ∑ x , y ( P ˉ ( x , y ) ∑ i δ i f i ( x , y ) ) + 1 − ∑ x P ˉ ( x ) Z λ + δ ( x ) Z λ ( x ) = ∑ x , y ( P ˉ ( x , y ) ∑ i δ i f i ( x , y ) ) + 1 − ∑ x P ˉ ( x ) e ∑ i δ i f i ( x , y ) = ∑ x , y ( P ˉ ( x , y ) ∑ i δ i f i ( x , y ) ) + 1 − ∑ x ( P ˉ ( x ) e ∑ i δ i f i ( x , y ) ∑ y P ( y ∣ x ) ) MLE(λ+δ)-MLE(λ)=\sum_{x,y}(\bar{P}(x,y)\sum_iδ_if_i(x,y))-\sum_{x}\bar{P}(x)\ln{\frac{Z_{λ+δ}(x)}{Z_λ(x)}}\\\qquad\qquad\qquad\qquad\qquad\quad\:\:\geq\sum_{x,y}(\bar{P}(x,y)\sum_iδ_if_i(x,y))+1-\sum_{x}\bar{P}(x)\frac{Z_{λ+δ}(x)}{Z_λ(x)}\\\qquad\qquad\qquad\qquad\qquad\qquad\:=\sum_{x,y}(\bar{P}(x,y)\sum_iδ_if_i(x,y))+1-\sum_{x}\bar{P}(x)e^{\sum_iδ_if_i(x,y)}\\\qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad\quad\:\:\:=\sum_{x,y}(\bar{P}(x,y)\sum_iδ_if_i(x,y))+1-\sum_{x}(\bar{P}(x)e^{\sum_iδ_if_i(x,y)}\sum_yP(y\,|\,x)) MLE(λ+δ)−MLE(λ)=x,y∑(Pˉ(x,y)i∑δifi(x,y))−x∑Pˉ(x)lnZλ(x)Zλ+δ(x)≥x,y∑(Pˉ(x,y)i∑δifi(x,y))+1−x∑Pˉ(x)Zλ(x)Zλ+δ(x)=x,y∑(Pˉ(x,y)i∑δifi(x,y))+1−x∑Pˉ(x)e∑iδifi(x,y)=x,y∑(Pˉ(x,y)i∑δifi(x,y))+1−x∑(Pˉ(x)e∑iδifi(x,y)y∑P(y∣x))定义 f # ( x , y ) = ∑ i f i ( x , y ) f^\#(x,y)=\sum_if_i(x,y) f#(x,y)=∑ifi(x,y),再利用琴生不等式有 A ( δ ∣ λ ) : = [ ∑ x , y P ˉ ( x , y ) ( ∑ i δ i f i ( x , y ) ) ] + 1 − [ ∑ x P ˉ ( x ) e ∑ i δ i f i ( x , y ) ( ∑ y P ( y ∣ x ) ) ] = [ ∑ x , y P ˉ ( x , y ) ( ∑ i δ i f i ( x , y ) ) ] + 1 − [ ∑ x P ˉ ( x ) e f # ( x , y ) ∑ i δ i f i ( x , y ) f # ( x , y ) ( ∑ y P ( y ∣ x ) ) ] ≥ [ ∑ x , y P ˉ ( x , y ) ( ∑ i δ i f i ( x , y ) ) ] + 1 − [ ∑ x P ˉ ( x ) e δ i f # ( x , y ) ( ∑ y P ( y ∣ x ) ) ( ∑ i f i ( x , y ) f # ( x , y ) ) ] : = B ( δ ∣ λ ) A(δ\,|\,λ):=[\sum_{x,y}\bar{P}(x,y)(\sum_iδ_if_i(x,y))]+1-[\sum_{x}\bar{P}(x)e^{\sum_iδ_if_i(x,y)}(\sum_yP(y\,|\,x))]\\\qquad\qquad\qquad\:\:\,=[\sum_{x,y}\bar{P}(x,y)(\sum_iδ_if_i(x,y))]+1-[\sum_{x}\bar{P}(x)e^{f^\#(x,y)\sum_i\frac{δ_if_i(x,y)}{f^\#(x,y)}}(\sum_yP(y\,|\,x))]\\\qquad\qquad\qquad\qquad\qquad\quad\:\:\geq[\sum_{x,y}\bar{P}(x,y)(\sum_iδ_if_i(x,y))]+1-[\sum_{x}\bar{P}(x)e^{δ_if^\#(x,y)}(\sum_yP(y\,|\,x))(\sum_i\frac{f_i(x,y)}{f^\#(x,y)})]:=B(δ\,|\,λ) A(δ∣λ):=[x,y∑Pˉ(x,y)(i∑δifi(x,y))]+1−[x∑Pˉ(x)e∑iδifi(x,y)(y∑P(y∣x))]=[x,y∑Pˉ(x,y)(i∑δifi(x,y))]+1−[x∑Pˉ(x)ef#(x,y)∑if#(x,y)δifi(x,y)(y∑P(y∣x))]≥[x,y∑Pˉ(x,y)(i∑δifi(x,y))]+1−[x∑Pˉ(x)eδif#(x,y)(y∑P(y∣x))(i∑f#(x,y)fi(x,y))]:=B(δ∣λ)求 B B B对 δ i δ_i δi的偏导,得到 ∂ B ∂ δ i = ∑ x , y P ˉ ( x , y ) f i ( x , y ) − [ ∑ x P ˉ ( x ) f i ( x , y ) e δ i f # ( x , y ) ( ∑ y P ( y ∣ x ) ) ] = ∑ x , y P ˉ ( x , y ) f i ( x , y ) − ( ∑ x , y P ˉ ( x ) P ( y ∣ x ) f i ( x , y ) e δ i f # ( x , y ) ) = E ˉ ( f i ) − ( ∑ x , y P ˉ ( x ) P ( y ∣ x ) f i ( x , y ) e δ i f # ( x , y ) ) : = g ( δ i ) \frac{\partial{B}}{\partial{δ_i}}=\sum_{x,y}\bar{P}(x,y)f_i(x,y)-[\sum_{x}\bar{P}(x)f_i(x,y)e^{δ_if^\#(x,y)}(\sum_yP(y\,|\,x))]\\=\sum_{x,y}\bar{P}(x,y)f_i(x,y)-(\sum_{x,y}\bar{P}(x)P(y\,|\,x)f_i(x,y)e^{δ_if^\#(x,y)})\:\,\\=\bar{E}(f_i)-(\sum_{x,y}\bar{P}(x)P(y\,|\,x)f_i(x,y)e^{δ_if^\#(x,y)}):=g(δ_i)\qquad\:\:\, ∂δi∂B=x,y∑Pˉ(x,y)fi(x,y)−[x∑Pˉ(x)fi(x,y)eδif#(x,y)(y∑P(y∣x))]=x,y∑Pˉ(x,y)fi(x,y)−(x,y∑Pˉ(x)P(y∣x)fi(x,y)eδif#(x,y))=Eˉ(fi)−(x,y∑Pˉ(x)P(y∣x)fi(x,y)eδif#(x,y)):=g(δi)在最大点处应有 g ( δ i ) = 0 g(δ_i)=0 g(δi)=0,从而问题被转换为 g ( δ i ) g(δ_i) g(δi)求根.若 f # ( x , y ) f^\#(x,y) f#(x,y)为常数 M M M,则 δ i = ln E ˉ ( f i ) E ( f i ) M δ_i=\frac{\ln{\frac{\bar{E}(f_i)}{E(f_i)}}}{M} δi=MlnE(fi)Eˉ(fi)否则,可使用牛顿法求解:更新规则为 δ i k + 1 = δ i k − g ( δ i k ) g ′ ( δ i k ) δ_i^{k+1}=δ_i^k-\frac{g(δ_i^k)}{g'(δ_i^k)} δik+1=δik−g′(δik)g(δik)注意,因为要求的是根而非极值,故除以 g ′ ( δ i k ) g'(δ_i^k) g′(δik)而非 g ′ ′ ( δ i k ) g''(δ_i^k) g′′(δik),这与通常使用的牛顿法不同.另外,实践中可以采用拟牛顿法求解.利用求出的 δ δ δ对 λ λ λ进行更新: λ k + 1 = λ k + δ λ^{k+1}=λ^k+δ λk+1=λk+δ然后重复上述步骤,直到 λ λ λ收敛.将最终的 λ λ λ带回 ( 2 ) (2) (2)式,就得到了最大熵模型的最优解