c#词频统计命令行程序
这里将用c#写一个关于词频统计的命令行程序。
预计时间分配:输入处理3h、词条排序打印2h、测试3h。
实际时间分配:输入处理1h、词条排序打印2h、测试3h、程序改进优化6h。
下面将讲解程序的完成过程:
-
首先是输入处理部分,我们需要递归地扫描文章中的单词,首先此程序中单词的定义如下:
-
A word: a string with at least 3 English alphabet letters, then followed by optional alphanumerical characters. Words are separated by delimiters. If a string contains non-alphanumerical characters, it’s not a word. Word is case insensitive, i.e. “file”, “FILE” and “File” are considered the same word.
“file123” is a word, and “123file” is NOT a word.
- Alphabetic letters: A-Z, a-z.
- Alphanumerical characters: A-Z, a-z, 0-9.
- Delimiter: space, non-alphanumerical letters.
- Each line has this format
所以我使用正则表达式来进行单词的匹配。
1 private static string matchpattern = @"\b[A-Za-z]{3,}[A-Za-z0-9]*|_\b[A-Za-z]{3,}[A-Za-z0-9]*";//单词正则表达式匹配模式
上式就满足了我的单次匹配模式,正则表达式的完整语法在这里就不再赘述,请读者自行百度。
*需要注意这里\b提供了匹配时单次前必须是非字母、非数字字符,以免123file中的file被匹配,但是这个词显然在当前定义下不符合。
之后使用Regex.Matches(source, matchpattern)方法,能够返回一个匹配类型match的数组以便后面操作。
-
在单词的处理上,我们选择了一个字典结构来进行存储相关的数据。
1 private static Dictionary<string, wordnode> vocabcount = new Dictionary<string, wordnode>(); 2 //private static Dictionary<string, string> vocabword = new Dictionary<string, string>();
其中vocabcout将存储我们程序中所扫描的单次基数,以及在字母相同的多个单词中选择后存储的ASCII最小的单词。
*这里注释掉的vocabword字典,是我第一版代码的数据结构,我在最开始因为要存储计数和ASCII最小的单词,所以开了两个索引都为词条的lowcase的数据表来进行分别存储计数和单词,但是这样非常消耗内存,同时在遍历表的同时增加了算法复杂度,在之后的代码优化后进行了改进。
wordnode是我自己定义的一个结构,代码如下:
1 class wordnode 2 { 3 public int count{get;set;} 4 public string word {get; set;} 5 public wordnode(int num,string word) 6 { 7 this.count=num; 8 this.word=word; 9 } 10 }
可以看到wordnode内具有count和word两种属性。这样就能存储我们所需要的数据。
-
接下来我们将对每一个文件内的单次进行处理,runsta()函数代码如下:
1 private void runsta() 2 { 3 4 Regex reg=new Regex(matchpattern); 5 if (option != 0) 6 { 7 Match m = reg.Match(source, 0); 8 while (m.Success) 9 { 10 match_process(m.ToString()); 11 m = reg.Match(source, m.Index + m.ToString().IndexOf(' ')); 12 } 13 } 14 else 15 { 16 foreach (Match m in reg.Matches(source)) 17 match_process(m.ToString()); 18 } 19 20 }
这里的第一个分支用于支持要进行连续的2-3个单词的识别,通过调整识别索引来进行识别不同的位置后的单词。
注意这里的match_process()函树是对一个词条进行处理的函数:
private void match_process(string tempword) { //foreach (Match m in Regex.Matches(source, matchpattern)) string lowerword = tempword.ToLower(); if (vocabcount.ContainsKey(lowerword)) { vocabcount[lowerword].count += 1; string temp = vocabcount[lowerword].word; if (temp.CompareTo(tempword) < 0) vocabcount[lowerword].word = tempword; } else { vocabcount.Add(lowerword, new wordnode(1, tempword)); } }
代码简单易读,这里就完成对统计数据的存储。
-
接下来要完成对文件夹结构的遍历
我们需要对用户输入的文件夹路径进行递归遍历,于是递归代码如下:
1 /* public bool recursiverun(string path) 2 { 3 if (File.Exists(path)) 4 { 5 process_eacchfile(path); 6 } 7 8 else if (Directory.Exists(path)) 9 { 10 string[] filelist = Directory.GetFiles(path); 11 string[] dirlist = Directory.GetDirectories(path); 12 if(filelist.Length!=0) 13 foreach(string onefile in filelist) 14 { 15 foreach (string ext in oneext) 16 { 17 if(onefile.EndsWith(ext)) 18 process_eacchfile(onefile); 19 } 20 } 21 if(dirlist.Length!=0) 22 foreach(string onedir in dirlist) 23 { 24 recursiverun(onedir); 25 } 26 } 27 else 28 return false; 29 return true; 30 }*/
*这里是我的第一版本的文件系统遍历的代码,代码对文件树进行深度遍历,在遍历同时进行文件处理,不仅因为递归算法内存和复杂度开销甚大,同是对各个临界值和条件的控制让算法非常脆弱,所以我在进行算法改进后换成了的以下的代码:
1 String[] files = (Directory.EnumerateFiles(path, "*.*", SearchOption.AllDirectories)).Where(s => s.EndsWith(".txt") || s.EndsWith(".cpp") || s.EndsWith(".h") || s.EndsWith(".cs")).ToArray();
这段代码易用准确,将遍历部分和处理部分分割开来,减少内存开销和算法复杂度。
以上,我们就将单词的匹配、单词数据的处理、文件系统的遍历功能完成了。此外,对于每个文件的可读有效性,路径有效性的函数在此就不再赘述。
2.再者是数据处理部分,即将统计数据排序打印
- 将字典项进行排序输出,代码如下:
1 var item = vocabcount.OrderByDescending(r => r.Value.count).ThenBy(r => r.Value.word); 2 //List<KeyValuePair<string, wordnode>> myList = new List<KeyValuePair<string, wordnode>>(vocabcount); 3 //myList.Sort(delegate(KeyValuePair<string, wordnode> s1, KeyValuePair<string, wordnode> s2) 4 //{ 5 6 // return s1.Value.word.CompareTo(s2.Value.word); 7 8 // });
这里列举了两种效果相同的算法,都会将字典项先按计数降序再按字典序升序排列。
*这里发现c#本身的compareto算法比较输出与ASCII比较相反,所以我在存储单词的时候取了反,在这里直接按着字典序排列,就有可能一些大写字母单词排在小写的后面,但这就是c#的字典序,所以我不选择去修改它了。核心代码就是以上,所以关于输出的函数在这里不做赘述。
3.测试用例
3.1测试单词识别:
file123 fie 123file
3.1测试结果:
<fie>:1
<file123>:1
3.2测试文本或文件树为空:
void
3.2测试结果:
void
3.3测试单词大小写识别和存储问题:
file File
3.3测试结果:
<File>:2
3.3测试单词排序:
FILE file ASD asd asD ASC asc ASc
3.3测试结果:
<ASC>:3
<ASD>:3
<FILE>:2
3.4测试连续两个单词的识别:
how are you are you
3.4测试结果:
<are you>:2
<how are>:1
<you are>:1
3.5测试连续三个单词的识别;
how are you doing ine these days
3.5测试结果:
<are you doing>:1
<doing ine these>:1
<how are you>:1
<ine these days>:1
<you doing ine>:1
3.6测试文件选择:
3.6测试结果:
只有txt、h、cpp、cs的文件可以被阅读
3.7测试路径无效的情况
3.7测试结果:
控制台显示不存在此文件或文件夹,请重新输入
3.8测试分隔符:
horweefa[]youw
3.8测试结果:
<horweefa>:1
<youw>:1
3.9测试连续两个单词的排序:
how are you are you
3.9测试结果:
<are you>:2
<how are>:1
<you are>:1
3.10测试大文件:
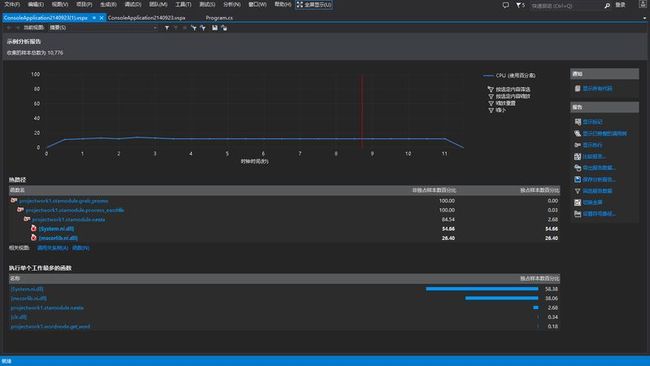
见最后一张性能截图,结果正确性能如下。
4.性能分析
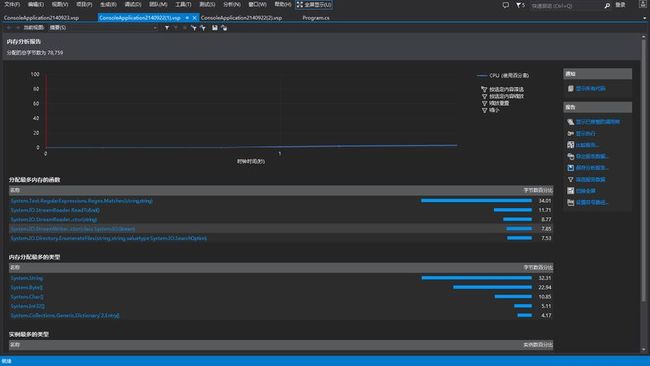
这里是内存分析的图。
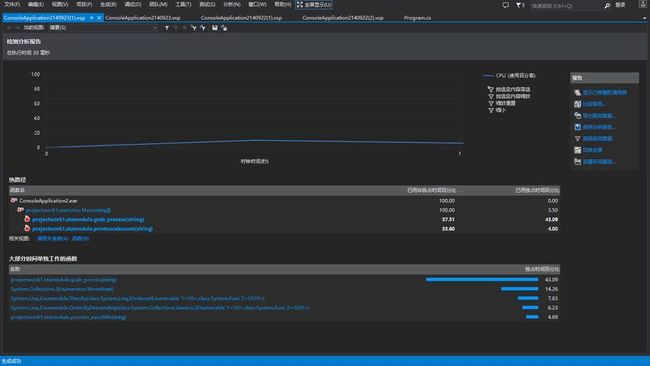
这里是时间分析的图,因为递归和处理算法的分离,使得递归过程更快速,程序的瓶颈在处理过程和存储数据结构上,之前使用sorteddictionary非常慢,我将数据结构改为dictionary,速度提升了一个数量级。如果需要继续提高数据结构的效率可能可以参考trie树,这里不做赘述,不过经过分析我觉得应该没有什么较大的区别。
5.收获
这次项目让我学会了熟练的使用正则表达式、LINQ、dictionary等语法,更会通过code analysis去分析代码的内存消耗和算法瓶颈,让我受益匪浅,而且写blog将自己的思路写下来,能够在社区里与他人交流,是一种全新的学习方式,希望在这里的印记能够为他人提供方便。