基于pytorch的MNIST数据集的四层CNN,测试准确率99.77%
基于pytorch的MNIST数据集的四层CNN,测试准确率99.77%
- MNIST数据集
- 环境配置
- 文件存储结构
- 代码
-
- 引入库
- 调用GPU
- 初始化变量
- 导入数据集并进行数据增强
- 导入测试集
- 加载测试集
- 查看部分图片
- model结构
- 权值初始化
- 实例化网络,设置优化器
- 定义存储数据的列表
- 定义训练函数
- 定义测试函数
- 查看模型的识别能力
- 训练模型
- 可视化训练结果
- 预测mnist数据集中的图片
- 预测手写数字
-
- 图片预处理
- 加载模型
- 预测手写数字(单张)
- 预测手写数字(多张)
- 调整参数,优化模型
- 五层结构
- 参考
MNIST数据集
MNIST 数据集已经是一个被”嚼烂”了的数据集, 很多教程都会对它”下手”, 几乎成为一个 “典范”. 不过有些人可能对它还不是很了解, 下面来介绍一下.
MNIST 数据集可在 http://yann.lecun.com/exdb/mnist/ 获取, 它包含了四个部分:
Training set images: train-images-idx3-ubyte.gz (9.9 MB, 解压后 47 MB, 包含 60,000 个样本)
Training set labels: train-labels-idx1-ubyte.gz (29 KB, 解压后 60 KB, 包含 60,000 个标签)
Test set images: t10k-images-idx3-ubyte.gz (1.6 MB, 解压后 7.8 MB, 包含 10,000 个样本)
Test set labels: t10k-labels-idx1-ubyte.gz (5KB, 解压后 10 KB, 包含 10,000 个标签)
MNIST 数据集来自美国国家标准与技术研究所, National Institute of Standards and Technology (NIST). 训练集 (training set) 由来自 250 个不同人手写的数字构成, 其中 50% 是高中学生, 50% 来自人口普查局 (the Census Bureau) 的工作人员. 测试集(test set) 也是同样比例的手写数字数据.
环境配置
python 3.7.6,GPU版PyTorch 1.7.1,torchvision 0.8.2,CUDA 10.1
cuDNN 7.6.5
文件存储结构
1---代码文件
1---mnist 文件夹
2---MNIST 文件夹
3---processed 文件夹
4---test.pt 文件
4---training.pt 文件
3---raw 文件夹
4---t10k-images-idx3-ubyte 文件
4---t10k-labels-idx1-ubyte 文件
4---train-images-idx3-ubyte 文件
4---train-labels-idx1-ubyte 文件
代码
引入库
import torch
import torchvision
from torch.utils.data import DataLoader
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.optim import lr_scheduler
import matplotlib.pyplot as plt
from PIL import Image
import matplotlib.image as image
import cv2
import os
调用GPU
#调用GPU
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
torch.backends.cudnn.benchmark = True
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
torch.cuda.empty_cache()
初始化变量
#初始化变量
n_epochs = 100 #训练次数
batch_size_train = 240 #训练的 batch_size
batch_size_test = 1000 #测试的 batch_size
learning_rate = 0.001 # 学习率
momentum = 0.5 # 在梯度下降过程中解决mini-batch SGD优化算法更新幅度摆动大的问题,使得收敛速度更快
log_interval = 10 # 操作间隔
random_seed = 2 # 随机种子,设置后可以得到稳定的随机数
torch.manual_seed(random_seed)
导入数据集并进行数据增强
数据增强是对数据集中的图片进行平移旋转等变换。数据增强只针对训练集,使训练集的图片更具有多样性,让训练出来的模型的适应性更广。使用数据增强会使训练准确率下降,但是可以有效提高测试准确率。
#导入训练集并增强数据
train_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST('./mnist/', train=True, download=False,
transform=torchvision.transforms.Compose([
torchvision.transforms.RandomAffine(degrees = 0,translate=(0.1, 0.1)),
torchvision.transforms.RandomRotation((-10,10)),#将图片随机旋转(-10,10)度
torchvision.transforms.ToTensor(),# 将PIL图片或者numpy.ndarray转成Tensor类型
torchvision.transforms.Normalize((0.1307,), (0.3081,))])
),
batch_size=batch_size_train, shuffle=True,num_workers=4, pin_memory=True) # shuffle如果为true,每个训练epoch后,会将数据顺序打乱
导入测试集
#导入测试集
test_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST('./mnist/', train=False, download=False,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize((0.1307,), (0.3081,))])
),
batch_size=batch_size_test, shuffle=True,num_workers=4, pin_memory=True)
加载测试集
# 用 enumerate 加载测试集
examples = enumerate(test_loader)
# 获取一个 batch
batch_idx, (example_data, example_targets) = next(examples)
# 查看 batch 数据,有10000张图像的标签,tensor 大小为 [1000, 1, 28, 28]
# 即图像为 28 * 28, 1个颜色通道(灰度图), 1000张图像
#print(example_targets)
#print(example_data.shape)
查看部分图片
#查看部分图片
fig = plt.figure()
for i in range(6):
plt.subplot(2,3,i+1)# 创建 subplot
plt.tight_layout()
plt.imshow(example_data[i][0], cmap='gray', interpolation='none')
plt.title("Label: {}".format(example_targets[i]))
plt.xticks([])
plt.yticks([])
plt.show()
model结构
#model
class CNNModel(nn.Module):
def __init__(self):
super(CNNModel, self).__init__()
# Convolution layer 1 ((w - f + 2 * p)/ s ) + 1
self.conv1 = nn.Conv2d(in_channels = 1 , out_channels = 32, kernel_size = 5, stride = 1, padding = 0 )
self.relu1 = nn.ReLU()
self.batch1 = nn.BatchNorm2d(32)
self.conv2 = nn.Conv2d(in_channels =32 , out_channels = 32, kernel_size = 5, stride = 1, padding = 0 )
self.relu2 = nn.ReLU()
self.batch2 = nn.BatchNorm2d(32)
self.maxpool1 = nn.MaxPool2d(kernel_size = 2, stride = 2)
self.conv1_drop = nn.Dropout(0.25)
# Convolution layer 2
self.conv3 = nn.Conv2d(in_channels = 32, out_channels = 64, kernel_size = 3, stride = 1, padding = 0 )
self.relu3 = nn.ReLU()
self.batch3 = nn.BatchNorm2d(64)
self.conv4 = nn.Conv2d(in_channels = 64, out_channels = 64, kernel_size = 3, stride = 1, padding = 0 )
self.relu4 = nn.ReLU()
self.batch4 = nn.BatchNorm2d(64)
self.maxpool2 = nn.MaxPool2d(kernel_size = 2, stride = 2)
self.conv2_drop = nn.Dropout(0.25)
# Fully-Connected layer 1
self.fc1 = nn.Linear(576,256)
self.fc1_relu = nn.ReLU()
self.dp1 = nn.Dropout(0.5)
# Fully-Connected layer 2
self.fc2 = nn.Linear(256,10)
def forward(self, x):
# conv layer 1 的前向计算,3行代码
out = self.conv1(x)
out = self.relu1(out)
out = self.batch1(out)
out = self.conv2(out)
out = self.relu2(out)
out = self.batch2(out)
out = self.maxpool1(out)
out = self.conv1_drop(out)
# conv layer 2 的前向计算,4行代码
out = self.conv3(out)
out = self.relu3(out)
out = self.batch3(out)
out = self.conv4(out)
out = self.relu4(out)
out = self.batch4(out)
out = self.maxpool2(out)
out = self.conv2_drop(out)
#Flatten拉平操作
out = out.view(out.size(0),-1)
#FC layer的前向计算(2行代码)
out = self.fc1(out)
out = self.fc1_relu(out)
out = self.dp1(out)
out = self.fc2(out)
return F.log_softmax(out,dim = 1)
权值初始化
He初始化基本思想是,当使用ReLU做为激活函数时,Xavier的效果不好,原因在于,当RelU的输入小于0时,其输出为0,相当于该神经元被关闭了,影响了输出的分布模式。
因此He初始化,在Xavier的基础上,假设每层网络有一半的神经元被关闭,于是其分布的方差也会变小。经过验证发现当对初始化值缩小一半时效果最好,故He初始化可以认为是Xavier初始/2的结果。
#权值初始化
def weight_init(m):
# 1. 根据网络层的不同定义不同的初始化方式
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
# 也可以判断是否为conv2d,使用相应的初始化方式
'''
elif isinstance(m, nn.Linear):
nn.init.xavier_normal_(m.weight)
nn.init.constant_(m.bias, 0)
# 是否为批归一化层
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
'''
实例化网络,设置优化器
# 实例化一个网络
network = CNNModel()
network.to(device)
#调用权值初始化函数
network.apply(weight_init)
# 设置优化器,用stochastic gradient descent,设置学习率,设置momentum
#optimizer = optim.SGD(network.parameters(), lr=learning_rate, momentum=momentum)
#optimizer = optim.Adam(network.parameters(), lr=learning_rate)
optimizer = optim.RMSprop(network.parameters(),lr=learning_rate,alpha=0.99,momentum = momentum)
#设置学习率梯度下降,如果连续三个epoch测试准确率没有上升,则降低学习率
scheduler = lr_scheduler.ReduceLROnPlateau(optimizer, mode='max', factor=0.5, patience=3, verbose=True, threshold=0.00005, threshold_mode='rel', cooldown=0, min_lr=0, eps=1e-08)
定义存储数据的列表
#定义存储数据的列表
train_losses = []
train_counter = []
train_acces = []
test_losses = []
test_counter = [i*len(train_loader.dataset) for i in range(n_epochs + 1)]
test_acces = []
定义训练函数
# 定义训练函数
def train(epoch):
network.train() # 将网络设为 training 模式
train_correct = 0
# 对一组 batch
for batch_idx, (data, target) in enumerate(train_loader):
# 通过enumerate获取batch_id, data, and label
# 1-将梯度归零
optimizer.zero_grad()
# 2-传入一个batch的图像,并前向计算
# data.to(device)把图片放入GPU中计算
output = network(data.to(device))
# 3-计算损失
loss = F.nll_loss(output, target.to(device))
# 4-反向传播
loss.backward()
# 5-优化参数
optimizer.step()
#exp_lr_scheduler.step()
train_pred = output.data.max(dim=1, keepdim=True)[1] # 取 output 里最大的那个类别,
# dim = 1表示去每行的最大值,[1]表示取最大值的index,而不去最大值本身[0]
train_correct += train_pred.eq(target.data.view_as(train_pred).to(device)).sum() # 比较并求正确分类的个数
#打印以下信息:第几个epoch,第几张图像, 总训练图像数, 完成百分比,目前的loss
print('\r 第 {} 次 Train Epoch: [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, (batch_idx + 1) * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()),end = '')
# 每第10个batch (log_interval = 10)
if batch_idx % log_interval == 0:
#print(batch_idx)
# 把目前的 loss加入到 train_losses,后期画图用
train_losses.append(loss.item())
# 计数
train_counter.append(
(batch_idx*64) + ((epoch-1)*len(train_loader.dataset)))
train_acc = train_correct / len(train_loader.dataset)
train_acces.append(train_acc.cpu().numpy().tolist())
print('\tTrain Accuracy:{:.2f}%'.format(100. * train_acc))
定义测试函数
# 定义测试函数
def test(epoch):
network.eval() # 将网络设为 evaluating 模式
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
output = network(data.to(device)) # 传入这一组 batch,进行前向计算
#test_loss += F.nll_loss(output, target, size_average=False).item()
test_loss += F.nll_loss(output, target.to(device), reduction='sum').item()
pred = output.data.max(dim=1, keepdim=True)[1] # 取 output 里最大的那个类别,
# dim = 1表示去每行的最大值,[1]表示取最大值的index,而不去最大值本身[0]
correct += pred.eq(target.data.view_as(pred).to(device)).sum() # 比较并求正确分类的个数
acc = correct / len(test_loader.dataset)# 平均测试准确率
test_acces.append(acc.cpu().numpy().tolist())
test_loss /= len(test_loader.dataset) # 平均 loss, len 为 10000
test_losses.append(test_loss) # 记录该 epoch 下的 test_loss
#保存测试准确率最大的模型
if test_acces[-1] >= max(test_acces):
# 每个batch训练完后保存模型
torch.save(network.state_dict(), './model02.pth')
# 每个batch训练完后保存优化器
torch.save(optimizer.state_dict(), './optimizer02.pth')
# 打印相关信息 如:Test set: Avg. loss: 2.3129, Accuracy: 1205/10000 (12%)
print('\r Test set \033[1;31m{}\033[0m : Avg. loss: {:.4f}, Accuracy: {}/{} \033[1;31m({:.2f}%)\033[0m\n'\
.format(epoch,test_loss, correct,len(test_loader.dataset),100. * acc),end = '')
查看模型的识别能力
# 先看一下模型的识别能力,可以看到没有经过训练的模型在测试集上的表现是很差的,大概只有10%左右的正确识别率
test(1)
训练模型
### 训练!!! 并在每个epoch之后测试 ###
###################################################
# 根据epoch数正式训练并在每个epoch训练结束后测试
for epoch in range(1, n_epochs + 1):
scheduler.step(test_acces[-1])
train(epoch)
test(epoch)
#输入最后保存的模型的准确率,也就是最高测试准确率
print('\n\033[1;31mThe network Max Avg Accuracy : {:.2f}%\033[0m'.format(100. * max(test_acces)))

可视化训练结果
#可视化
fig = plt.figure(figsize=(15,5))#将画图窗口横向放大15倍,纵向放大5倍
ax1 = fig.add_subplot(121)
#训练损失
ax1.plot(train_counter, train_losses, color='blue')
#测试损失
plt.scatter(test_counter, test_losses, color='red')
#图例
plt.legend(['Train Loss', 'Test Loss'], loc='upper right')
plt.title('Train & Test Loss')
plt.xlabel('number of training examples seen')
plt.ylabel('negative log likelihood loss')
plt.subplot(122)
#最大测试准确率的索引
max_test_acces_epoch = test_acces.index(max(test_acces))
#最大值保留4位小数,四舍五入
max_test_acces = round(max(test_acces),4)
#训练准确率
plt.plot([epoch+1 for epoch in range(n_epochs) ], train_acces, color='blue')
#测试准确率
plt.plot([epoch+1 for epoch in range(n_epochs) ], test_acces[1:], color='red')
plt.plot(max_test_acces_epoch,max_test_acces,'ko') #最大值点
show_max=' ['+str(max_test_acces_epoch )+' , '+str(max_test_acces)+']'
#最大值点坐标显示
plt.annotate(show_max,xy=(max_test_acces_epoch,max_test_acces),
xytext=(max_test_acces_epoch,max_test_acces))
plt.legend(['Train acc', 'Test acc'], loc='lower right')
plt.title('Train & Test Accuracy')
#plt.ylim(0.8, 1)
plt.xlabel('number of training epoch')
plt.ylabel('negative log likelihood acc')
plt.show()

预测mnist数据集中的图片
#预测
examples = enumerate(test_loader)
batch_idx, (example_data, example_targets) = next(examples)
with torch.no_grad():
output = network(example_data.to(device))
fig = plt.figure()
for i in range(6):
plt.subplot(2,3,i+1)
plt.tight_layout()
plt.imshow(example_data[i][0], cmap='gray', interpolation='none')
plt.title("Prediction: {}".format(
output.data.max(1, keepdim=True)[1][i].item()))
plt.xticks([])
plt.yticks([])
plt.show()

预测手写数字
图片预处理
#图片处理
def imageProcess(img):
#处理图片
data_transform = torchvision.transforms.Compose(
[torchvision.transforms.Resize(32),
torchvision.transforms.CenterCrop(28),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize((0.1307,), (0.3081,))])
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)# 灰度处理
retval, dst = cv2.threshold(gray, 0, 255,cv2.THRESH_BINARY | cv2.THRESH_OTSU)# 二值化
fanse = cv2.bitwise_not(dst)#黑白反转
#将BGR图像转变成RGB图像:即将cv2.imread转换成Image.open
imgs = Image.fromarray(cv2.cvtColor(fanse, cv2.COLOR_BGR2RGB))
imgs = imgs.convert('L') #将三通道图像转换成单通道灰度图像
imgs = data_transform(imgs)#处理图像
return imgs
加载模型
network = CNNModel()
model_path = "./model02.pth"
network.load_state_dict(torch.load(model_path))
network.eval()
预测手写数字(单张)
#预测手写数字
path = 'E:/jupyter_notebook/test/' #图片保存路径
with torch.no_grad():
img = cv2.imread(path + '9.jpg')#预测图片
#调用图片预处理函数
imgs = imageProcess(img)
if imgs.shape == torch.Size([1,28,28]):
imgs = torch.unsqueeze(imgs, dim=0) #在最前面增加一个维度
output = network(imgs.to(device))
plt.tight_layout()
plt.subplot(121)
img = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
plt.imshow(img)
plt.title("Original Image")
plt.xticks([])
plt.yticks([])
plt.subplot(122)
plt.imshow(imgs[0][0], cmap='gray', interpolation='none')
plt.title("Prediction: {}".format(output.data.max(dim = 1, keepdim=True)[1].item()))
plt.xlabel("Processed Image")
plt.xticks([])
plt.yticks([])
plt.show()

预测手写数字(多张)
#预测多张手写数字图片
with torch.no_grad():
fig = plt.figure(figsize=(15,5))
for i in range(9):
img = cv2.imread(path + str(i+1) + ".jpg")#预测图片
imgs = imageProcess(img)
if imgs.shape == torch.Size([1,28,28]):
imgs = torch.unsqueeze(imgs, dim=0)
output = network(imgs)
ax1 = fig.add_subplot(3,6,2*i+1)
img = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
plt.imshow(img)
plt.title("Original")
plt.xticks([])
plt.yticks([])
plt.subplot(3,6,2*i+2)
plt.tight_layout()
plt.imshow(imgs[0][0], cmap='gray', interpolation='none')
plt.title("Prediction: {}".format(
output.data.max(dim = 1, keepdim=True)[1].item()))
plt.xticks([])
plt.yticks([])
plt.show()
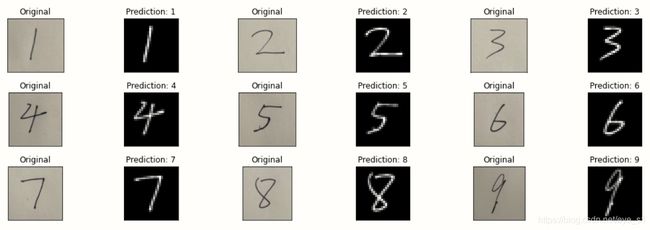
调整参数,优化模型
将训练准确率作为参考,连续1个epoch没有上升则降低学习率
# 实例化一个网络
network = CNNModel()
#加载模型
model_path = "./model02.pth"
network.load_state_dict(torch.load(model_path))
network.to(device)
#network.apply(weights_init)
optimizer = optim.RMSprop(network.parameters(),lr=learning_rate,alpha=0.99,momentum = momentum)
scheduler = lr_scheduler.ReduceLROnPlateau(optimizer, mode='max', factor=0.5, patience=1, verbose=True, threshold=1e-06, threshold_mode='rel', cooldown=0, min_lr=0, eps=1e-09)
for epoch in range(101, 201):
scheduler.step(train_acces[-1])
train(epoch)
test(epoch)
print('\n\033[1;31mThe network Max Avg Accuracy : {:.2f}%\033[0m'.format(100. * max(test_acces)))
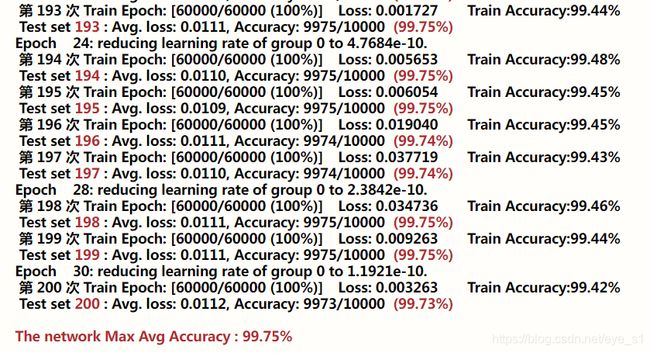
最终准确率达到99.75%
#完整预测代码
#引入库
import torch
import torchvision
from torch.utils.data import DataLoader
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import matplotlib.pyplot as plt
from PIL import Image
import matplotlib.image as image
import cv2
import time
import os
#model
class CNNModel(nn.Module):
def __init__(self):
super(CNNModel, self).__init__()
# Convolution layer 1
self.conv1 = nn.Conv2d(in_channels = 1 , out_channels = 32, kernel_size = 5, stride = 1, padding = 0 )
self.relu1 = nn.ReLU()
self.batch1 = nn.BatchNorm2d(32)
self.conv2 = nn.Conv2d(in_channels =32 , out_channels = 32, kernel_size = 5, stride = 1, padding = 0 )
self.relu2 = nn.ReLU()
self.batch2 = nn.BatchNorm2d(32)
self.maxpool1 = nn.MaxPool2d(kernel_size = 2, stride = 2)
self.conv1_drop = nn.Dropout(0.25)
# Convolution layer 2
self.conv3 = nn.Conv2d(in_channels = 32, out_channels = 64, kernel_size = 3, stride = 1, padding = 0 )
self.relu3 = nn.ReLU()
self.batch3 = nn.BatchNorm2d(64)
self.conv4 = nn.Conv2d(in_channels = 64, out_channels = 64, kernel_size = 3, stride = 1, padding = 0 )
self.relu4 = nn.ReLU()
self.batch4 = nn.BatchNorm2d(64)
self.maxpool2 = nn.MaxPool2d(kernel_size = 2, stride = 2)
self.conv2_drop = nn.Dropout(0.25)
# Fully-Connected layer 1
self.fc1 = nn.Linear(576,256)
self.fc1_relu = nn.ReLU()
self.dp1 = nn.Dropout(0.5)
# Fully-Connected layer 2
self.fc2 = nn.Linear(256,10)
def forward(self, x):
# conv layer 1 的前向计算,3行代码
out = self.conv1(x)
out = self.relu1(out)
out = self.batch1(out)
out = self.conv2(out)
out = self.relu2(out)
out = self.batch2(out)
out = self.maxpool1(out)
out = self.conv1_drop(out)
# conv layer 2 的前向计算,4行代码
out = self.conv3(out)
out = self.relu3(out)
out = self.batch3(out)
out = self.conv4(out)
out = self.relu4(out)
out = self.batch4(out)
out = self.maxpool2(out)
out = self.conv2_drop(out)
#Flatten拉平操作
out = out.view(out.size(0),-1)
#FC layer的前向计算(2行代码)
out = self.fc1(out)
out = self.fc1_relu(out)
out = self.dp1(out)
out = self.fc2(out)
return F.log_softmax(out,dim = 1)
#实例化模型
network = CNNModel()
#加载模型
model_path = "./model02.pth"
network.load_state_dict(torch.load(model_path))
network.eval()
#图片处理
def imageProcess(img):
#处理图片
data_transform = torchvision.transforms.Compose(
[torchvision.transforms.Resize(32),
torchvision.transforms.CenterCrop(28),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize((0.1307,), (0.3081,))])
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)# 灰度处理
retval, dst = cv2.threshold(gray, 0, 255,cv2.THRESH_BINARY | cv2.THRESH_OTSU)# 二值化
fanse = cv2.bitwise_not(dst)#黑白反转
#将BGR图像转变成RGB图像:即将cv2.imread转换成Image.open
imgs = Image.fromarray(cv2.cvtColor(fanse, cv2.COLOR_BGR2RGB))
imgs = imgs.convert('L') #将三通道图像转换成单通道灰度图像
imgs = data_transform(imgs)#处理图像
return imgs
#预测单张手写数字图片
path = 'E:/jupyter_notebook/test/'
with torch.no_grad():
img = cv2.imread(path + '9.jpg')#预测图片
imgs = imageProcess(img)
if imgs.shape == torch.Size([1,28,28]):
imgs = torch.unsqueeze(imgs, dim=0) #在最前面增加一个维度
output = network(imgs)
plt.tight_layout()
plt.subplot(121)
img = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
plt.imshow(img)
plt.title("Original")
plt.xticks([])
plt.yticks([])
plt.subplot(122)
plt.imshow(imgs[0][0], cmap='gray', interpolation='none')
plt.title("Prediction: {}".format(output.data.max(dim = 1, keepdim=True)[1].item()))
plt.xticks([])
plt.yticks([])
plt.show()
"""
#预测多张手写数字图片
with torch.no_grad():
fig = plt.figure(figsize=(15,5))
for i in range(9):
img = cv2.imread(path + str(i+1) + ".jpg")#预测图片
imgs = imageProcess(img)
if imgs.shape == torch.Size([1,28,28]):
imgs = torch.unsqueeze(imgs, dim=0)
output = network(imgs)
ax1 = fig.add_subplot(3,6,2*i+1)
img = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
plt.imshow(img)
plt.title("Original")
plt.xticks([])
plt.yticks([])
plt.subplot(3,6,2*i+2)
plt.tight_layout()
plt.imshow(imgs[0][0], cmap='gray', interpolation='none')
plt.title("Prediction: {}".format(
output.data.max(dim = 1, keepdim=True)[1].item()))
plt.xticks([])
plt.yticks([])
plt.show()
"""
五层结构
五层卷积的模型,不知道算不算优化,准确率达到99.77%,但是由于网络层数加深,训练速度变慢了很多。
#model
class CNNModel(nn.Module):
def __init__(self):
super(CNNModel, self).__init__()
# Convolution layer 1
self.conv1 = nn.Conv2d(in_channels = 1 , out_channels = 64, kernel_size = 5, stride = 1, padding = 2 )
self.relu1 = nn.ReLU()
self.batch1 = nn.BatchNorm2d(64)
self.conv2 = nn.Conv2d(in_channels =64 , out_channels = 64, kernel_size = 5, stride = 1, padding = 2 )
self.relu2 = nn.ReLU()
self.batch2 = nn.BatchNorm2d(64)
self.maxpool1 = nn.MaxPool2d(kernel_size = 2, stride = 2)
self.drop1 = nn.Dropout(0.25)
# Convolution layer 2
self.conv3 = nn.Conv2d(in_channels = 64, out_channels = 64, kernel_size = 3, stride = 1, padding = 1 )
self.relu3 = nn.ReLU()
self.batch3 = nn.BatchNorm2d(64)
self.conv4 = nn.Conv2d(in_channels = 64, out_channels = 64, kernel_size = 3, stride = 1, padding = 1 )
self.relu4 = nn.ReLU()
self.batch4 = nn.BatchNorm2d(64)
self.maxpool2 = nn.MaxPool2d(kernel_size = 2, stride = 2)
self.drop2 = nn.Dropout(0.25)
self.conv5 = nn.Conv2d(in_channels = 64, out_channels = 64, kernel_size = 3, stride = 1, padding = 1 )
self.relu5 = nn.ReLU()
self.batch5 = nn.BatchNorm2d(64)
self.drop3 = nn.Dropout(0.25)
# Fully-Connected layer 1
self.fc1 = nn.Linear(3136,256)
self.fc1_relu = nn.ReLU()
self.batch5 = nn.BatchNorm2d(64)
self.dp1 = nn.Dropout(0.25)
# Fully-Connected layer 2
self.fc2 = nn.Linear(256,10)
def forward(self, x):
# conv layer 1 的前向计算,3行代码
out = self.conv1(x)
out = self.relu1(out)
out = self.batch1(out)
out = self.conv2(out)
out = self.relu2(out)
out = self.batch2(out)
out = self.maxpool1(out)
out = self.drop1(out)
# conv layer 2 的前向计算,4行代码
out = self.conv3(out)
out = self.relu3(out)
out = self.batch3(out)
out = self.conv4(out)
out = self.relu4(out)
out = self.batch4(out)
out = self.maxpool2(out)
out = self.drop2(out)
out = self.conv5(out)
out = self.relu5(out)
out = self.batch5(out)
out = self.drop3(out)
#Flatten拉平操作
out = out.view(out.size(0),-1)
#FC layer的前向计算(2行代码)
out = self.fc1(out)
out = self.fc1_relu(out)
out = self.dp1(out)
out = self.fc2(out)
return F.log_softmax(out,dim = 1)

代码,模型以及数据集
链接:https://pan.baidu.com/s/1X80lLbKHi-JwiR2L879KeQ
提取码:8igs
参考
[1]: 详解 MNIST 数据集
[2]: TensorFlow、PyTorch各版本对应的CUDA、cuDNN关系
[3]: PyTorch学习之数据增强(image transformations)
[4]:pytorch中BatchNorm2d的用法
[5]:神经网络之BN层
[6]:pytorch系列 – 9 pytorch nn.init 中实现的初始化函数 uniform, normal, const, Xavier, He initialization
[7]:pytorch中的参数初始化方法总结
[8]:PyTorch 学习笔记(七):PyTorch的十个优化器
[9]:PyTorch学习之六个学习率调整策略
[10]:Python print()输出颜色设置