从零开始使用yoloair(4)
YOLOAir库使用(四)
YOLOAir:面向小白的目标检测库,更快更方便更完整的YOLO库

模型多样化:基于不同网络模块构建不同检测网络模型。
模块组件化:帮助用户自定义快速组合Backbone、Neck、Head,使得网络模型多样化,助力科研改进检测算法、模型改进,网络排列组合,构建强大的网络模型。
统一模型代码框架、统一应用方式、统一调参、统一改进、易于模块组合、构建更强大的网络模型:内置YOLOv5、YOLOv7、YOLOX、YOLOR、Transformer、Scaled_YOLOv4、YOLOv3、YOLOv4、YOLO-Facev2、TPH-YOLO、YOLOv5Lite、SPD-YOLO、SlimNeck-YOLO、PicoDet等模型网络结构
基于 YOLOv5 代码框架,并同步适配稳定的YOLOv5_v6.1更新, 同步v6.1部署生态。使用这个项目之前, 您可以先了解YOLOv5库。
YOLOv5仓库:https://github.com/ultralytics/yolov5
YOLOAir项目地址: https://github.com/iscyy/yoloair
YOLOAir部分改进说明教程: https://github.com/iscyy/yoloair/wiki/Improved-tutorial-presentation
YOLOAir CSDN地址:https://blog.csdn.net/qq_38668236
YOLOAir库使用说明
1. 下载源码
$ git clone https://github.com/iscyy/yoloair.git
或者打开github链接,下载项目源码,点击Code选择Download ZIP

2. 配置环境
首先电脑安装Anaconda,本文YOLOAir环境安装在conda虚拟环境里
2.1 创建一个python3.8的conda环境yoloair
conda create -n yoloair python=3.8
2.2 安装Pytorch和Torchvision环境
安装Pytorch有种方式,一种是官网链接[安装]https://pytorch.org/(),另外一中是下载whl包到本地再安装
Pytorch whl包下载地址:https://download.pytorch.org/whl/torch/
TorchVision包下载地址:https://download.pytorch.org/whl/torchvision/
本文Pytorch安装的版本为1.8.0,torchvision对应的版本为0.9.0
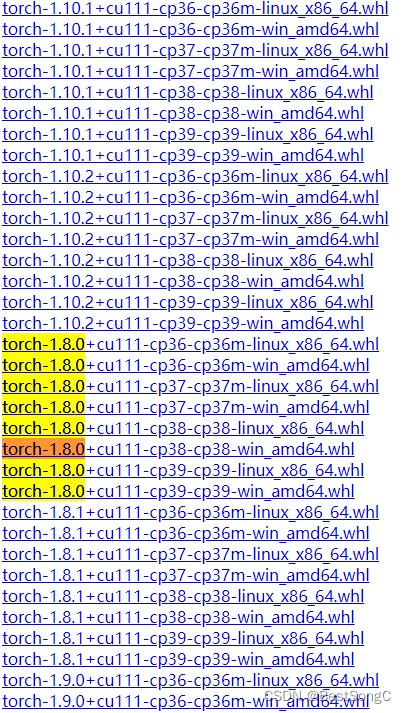

注意:cp对应Python包版本,linux对应lLinux版本,win对应Windows版本
当whl文件下载到本地后,进入包下载命令,使用pip install 包名来安装:
pip install torch-1.8.0+cu111-cp38-cp38-win_amd64.whl
pip install torchvision-0.9.0+cu111-cp38-cp38-win_amd64.whl
2.3 安装其他包依赖
YOLOAir项目依赖包具体包含如下:其中Base模块是基本项目依赖包,Logging和Plotting是模型训练时用到的日志和画图包,Export是用于模型转换时用到的(如pt转ONNX、TRT等),thop包是用来计算参数量的

进入到下载的YOLOAir项目目录,使用以下命令安装项目包依赖
pip install -r requirements.txt # 安装依赖包
如果嫌安装速度太慢,可以在此网站(https://pypi.org/)找包下载到本地再安装
2.4 开箱训练
train.py里面可以设置各种参数,具体参数解释详见后续实战更新
python train.py --data coco128.yaml --cfg configs/yolov5/yolov5s.yaml
2.5 模型推理
detect.py在各种数据源上运行推理, 并将检测结果保存到runs/detect目录
python detect.py --source 0 # 网络摄像头
img.jpg # 图像
vid.mp4 # 视频
path/ # 文件夹
path/*.jpg # glob
2.6 集成融合
如果使用不同模型来推理数据集,则可以使用 wbf.py文件通过加权框融合来集成结果,只需要在wbf.py文件中设置img路径和txt路径
$ python wbf.py
开箱使用YOLOAir
1. 模块选择
本文选取空间偏移注意力模型S2Attention,整体结构如下图所示:

- 首先对输入特征图进行一个全连接,其实也就是1×1卷积,只不过这里将维度变为了原来的三倍,然后经过一个 GELU 激活函数
- 然后特征图被均分为 三等份,分别用于后续三个 Spatial-shift 分支的输入;第一个分支Spatial-shift 操作,即右-左-下-上移动,第二个分支进行与第一个分支反对称的 Spatial-shift 操作,即下-上-右-左移动,第三个分支保持不变
- 最后将三个分支的结果通过 Split Attention 结合起来。这样不同位置的信息就被加到同一个通道上对齐了,再经过一个 MLP 进行不同位置的信息整合,然后经过 LN 激活函数
import numpy as np
import torch
from torch import nn
from torch.nn import init
def spatial_shift1(x):
b,w,h,c = x.size()
x[:,1:,:,:c//4] = x[:,:w-1,:,:c//4]
x[:,:w-1,:,c//4:c//2] = x[:,1:,:,c//4:c//2]
x[:,:,1:,c//2:c*3//4] = x[:,:,:h-1,c//2:c*3//4]
x[:,:,:h-1,3*c//4:] = x[:,:,1:,3*c//4:]
return x
def spatial_shift2(x):
b,w,h,c = x.size()
x[:,:,1:,:c//4] = x[:,:,:h-1,:c//4]
x[:,:,:h-1,c//4:c//2] = x[:,:,1:,c//4:c//2]
x[:,1:,:,c//2:c*3//4] = x[:,:w-1,:,c//2:c*3//4]
x[:,:w-1,:,3*c//4:] = x[:,1:,:,3*c//4:]
return x
class SplitAttention(nn.Module):
def __init__(self, channel=512, k=3):
super().__init__()
self.channel=channel
self.k=k
self.mlp1=nn.Linear(channel,channel,bias=False)
self.gelu=nn.GELU()
self.mlp2=nn.Linear(channel,channel*k,bias=False)
self.softmax=nn.Softmax(1)
def forward(self,x_all):
b, k, h, w, c = x_all.shape
x_all = x_all.reshape(b, k, -1, c) # bs,k,n,c
a = torch.sum(torch.sum(x_all, 1), 1) # bs,c
hat_a = self.mlp2(self.gelu(self.mlp1(a))) # bs,kc
hat_a = hat_a.reshape(b, self.k, c) # bs,k,c
bar_a = self.softmax(hat_a) # bs,k,c
attention = bar_a.unsqueeze(-2) # bs,k,1,c
out = attention*x_all # bs,k,n,c
out = torch.sum(out, 1).reshape(b, h, w, c)
return out
class S2Attention(nn.Module):
def __init__(self, channels=512, out_channel=1024):
super().__init__()
self.mlp1 = nn.Linear(channels, channels*3)
self.mlp2 = nn.Linear(channels, channels)
self.split_attention = SplitAttention()
def forward(self, x):
b, c, w, h = x.size()
x=x.permute(0, 2, 3, 1)
x = self.mlp1(x)
x1 = spatial_shift1(x[:,:,:,:c])
x2 = spatial_shift2(x[:,:,:,c:c*2])
x3 = x[:,:,:,c*2:]
x_all = torch.stack([x1,x2,x3],1)
a = self.split_attention(x_all)
x = self.mlp2(a)
x=x.permute(0,3,1,2)
return x
参考论文:https://arxiv.org/pdf/2108.01072.pdf
2.模型配置
# parameters
nc: 3 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
# anchors
anchors:
#- [5,6, 7,9, 12,10] # P2/4
# - [10,13, 16,30, 33,23] # P3/8
# - [30,61, 62,45, 59,119] # P4/16
# - [116,90, 156,198, 373,326] # P5/32
- [11,10, 17,16, 25,24] # P3/8
- [38,37, 46,72, 88,67] # P4/16
- [75,129, 180,145, 283,348] # P5/32
# YOLOv5 backbone
backbone:
# [from, number, module, args]
[ [-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]],
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 20 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 23 (P4/16-medium) [256, 256, 1, False]
# [-1, 3, CBAM, [512]], #26
[-1, 1, Conv, [512, 3, 2]], # 24 [256, 256, 3, 2]
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 26 (P5/32-large) [512, 512, 1, False]
[-1, 1, S2Attention, [1024]],
[[17, 20, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
- nc:检测的类别数
- depth_multiple:控制每层代码块的个数
- width_multiple:控制每层特征图的深度
- 参数量:YOLOv5s_S2Attention summary: 278 layers, 9126920 parameters, 9126920 gradients, 17.6 GFLOPs
3.模块配置
在yolo.py中加载模块,配置相关参数(先在Common.py中导入该模块)
elif m in [S2Attention]:
c1, c2 = ch[f], args[0]
if c2 != no: # if not output
c2 = make_divisible(c2 * gw, 8)
args = [c1, *args[1:]]
4.开箱训练
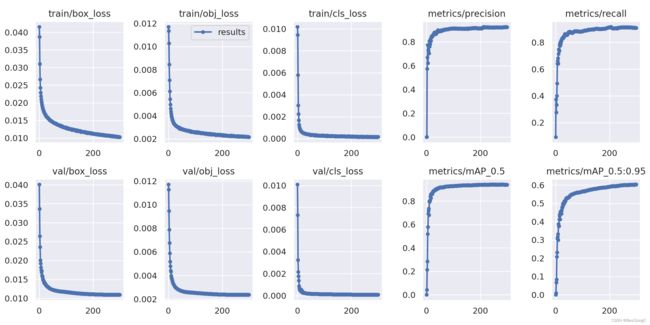
笔者对一个三类别目标检测任务进行训练,得到最终的结果图如下:


训练超参数:hyp.yaml
lr0: 0.00334
lrf: 0.15135
momentum: 0.74832
weight_decay: 0.00025
warmup_epochs: 3.3835
warmup_momentum: 0.59462
warmup_bias_lr: 0.18657
box: 0.02
cls: 0.21638
cls_pw: 0.5
obj: 0.51728
obj_pw: 0.67198
iou_t: 0.2
anchor_t: 3.3744
fl_gamma: 0.0
fl_eiou_gamma: 0.0
hsv_h: 0.01041
hsv_s: 0.54703
hsv_v: 0.27739
degrees: 0.0
translate: 0.04591
scale: 0.75544
shear: 0.0
perspective: 0.0
flipud: 0.0
fliplr: 0.5
mosaic: 0.85834
mixup: 0.04266
copy_paste: 0.0
paste_in: 0.0
- 所有实验默认初始化参数为yolov5s,模型为yolov5s权重加载
- base_size=64,hyp=hyp.VOC.yaml,epoch=300,IOU=CIOU,Imgsz=640
- 相比于普通的YOLOv5模型,添加了S2Attention模块的模型在训练稳定性上更胜一筹,训练和验证loss下降比较快且平稳,但S2Attention模块的添加同样也带来更多的参数量
总结
开箱即用YOLOAir库,使用或自定义模块遵循以下几个部分:
- 模块选择
- 模型配置
- 模块配置
- 开箱训练
彩蛋
本文对构建YOLOAir库环境进行详细阐述,笔者以后会定期分享关于项目的其他模块和相关技术,笔者也建立了一个关于目标检测的交流群:781334731,欢迎大家踊跃加入,一起学习鸭!
笔者也持续更新一个微信公众号:Nuist计算机视觉与模式识别,大家帮忙点个关注,后台回复YOLOAir(四)获取本文PDF。