LSTM实现语音识别
序言:语音识别作为人工智能领域重要研究方向,近几年发展迅猛,其中RNN的贡献尤为突出。RNN设计的目的就是让神经网络可以处理序列化的数据。本文笔者将陪同小伙伴们一块儿踏上语音识别之梦幻旅途,相信此处风景独好。
内容目录
欢迎下载小的demo,关注GitHub:GitHub 下载
环境准备
RNN与LSTM介绍RNNLSTM语音识别介绍声学特征提取声学特征转换成音素(声学模型)音素转文本(语言模型+解码)语音识别简单实现提取WAV文件中特征将WAV文件对应的文本文件转换成音素分类定义双向LSTM
模型训练和测试
环境准备
1、win10
2、python3.6.4
3、pip3
4、tensorflow1.12.0
(在运行代码的时候如果显示缺少python模块,直接用pip3安装即可)
RNN与LSTM介绍
循环神经网络(RNN)是神经网络模型中的一种,其中部分神经元的连接组成了有向环,有向环使得RNN中出现了内部状态或带记忆的结构,赋予了RNN对动态序列进行建模的能力。在接下来的两小节中笔者将详细的介绍一下RNN,以及RNN的变种长短期记忆(Long Short Term Memory,LSTM)网络。
RNN
图1中描绘了一个简单循环神经网络,叫做Elman网络,一共包含三层:输入层(input)、隐藏层(hidden)以及输出层(output)。context unit用来存储上一次的隐藏层的值,与下一次的输入一起输入到隐藏层(图中实线表示直接复制,虚线表示需要通过学习获得)。Elman网络和乔丹网络是循环神经网络中最简单的形态,本文只介绍Elman网络,感兴趣的读者可自行查阅乔丹网络。
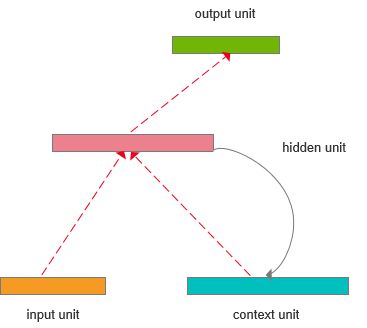
图1 Elman网络
Elman网络的数学表达式如下:
假设:
-
x(t):在t时间点的输入向量;
-
h(t):在t时间点的隐藏向量;
-
y(t):在t时间点的输出向量;
-
W、U和b:参数矩阵;
-
sigma(h)和sigma(y):激活函数。
隐藏层向量和输出层向量可以表示为:
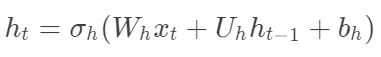
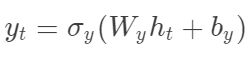
LSTM
长短期记忆(Long Short Term Memory,LSTM)是RNN的一种,最早由Hochreiter和Schmidhuber(1977)年提出,该模型克服了一下RNN的不足,通过刻意的设计来避免长期依赖的问题。现在很多大公司的翻译和语音识别技术核心都以LSTM为主。下边就详细的介绍一下LSTM的构成。图2描绘了LSTM单元的结构。
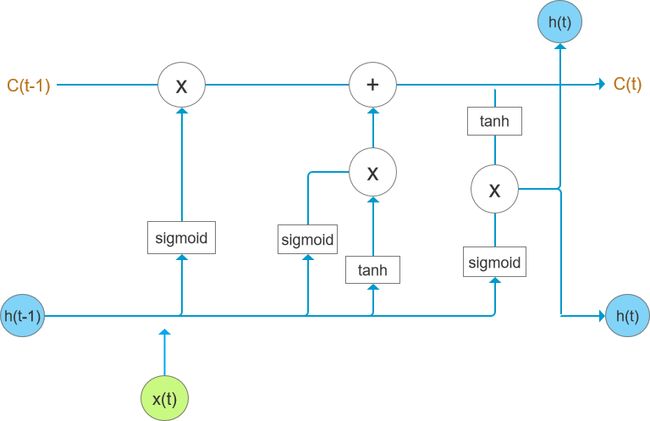
图2 LSTM单元结构
为了避免RNN中梯度消失和梯度爆炸的问题,LSTM相对于普通RNN单元有比较大的区别,主要的核心思想是:
①采用叫“细胞状态”(state)的通道贯穿整个时间序列,如图3中从C(t-1)到C(t),这条线上只有乘法操作和加法操作。
②通过设计“门”的结构来去除或者增加信息到细胞状态,LSML中有三个门,分别是“忘记门”、“输入门”和“输出门”。

图3 “细胞状态”通道示意图
下边详细阐述一下LSML中的三个门。
(1)忘记门
图4中红色加粗部分为LSML单元中“忘记门”的位置,“忘记门”决定之前状态中的信息有多少应该舍弃。它会输出一个0和1之间的数,代表C(t-1)中保留的部分。“忘记门”的计算公式如下:
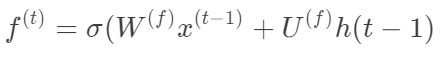
“忘记门”的输入是x(t),上一时刻的隐藏层输出h(t-1)、W(f)和U(f)是“忘记门的参数”,需要通过训练获取。
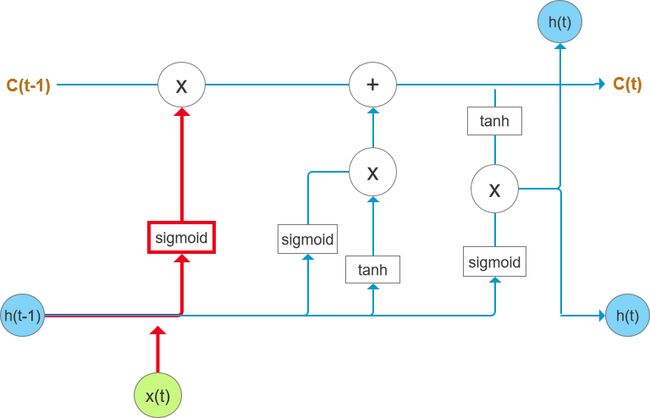
图4 “忘记门”
(2)输入门
图5中红色加粗部分为“输入门”,输入门决定什么样的输入信息应该保留在“细胞状态”C(t)中。它会读取h(t-1)和x(t)的内容,其计算公式为:

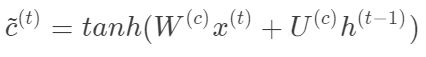
其中输入是h(t-1)和x(t),W(i)、U(i)、W(c)、U(c)是要训练的参数。
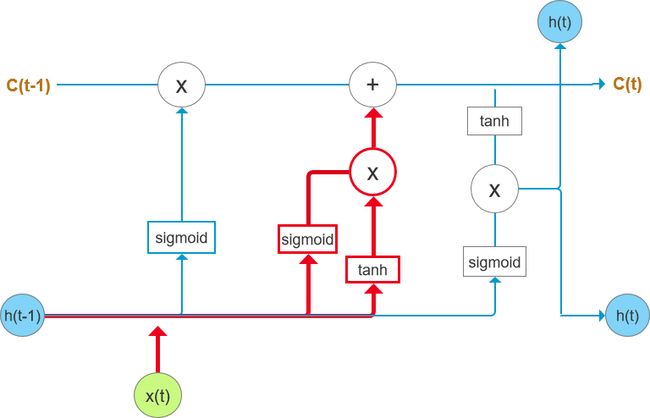
图5 “输入门”
接下来,研究一下“细胞状态”的值是如何更新的。首先经过忘记门,算出旧的细胞状态中有多少被遗弃,接着输入门将所得的结果加入到细胞状态,表示新的输入信息中有多少加入到细胞状态中。计算公式如下:

细胞状态的更新过程如图6所示:

图6 “细胞状态”更新
(3) 输出门
在细胞状态更新之后,将会基于细胞状态计算输出。首先输入数据h(t-1)和x(t),通过sigmoid激活函数得到“输出门”的值。然后,把细胞状态经过tanh处理,并与输出门的值相乘得到细胞的输出结果。输出门的公式如下:
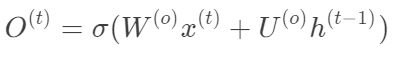
输出门的计算流程如图7红色加粗部分所示:
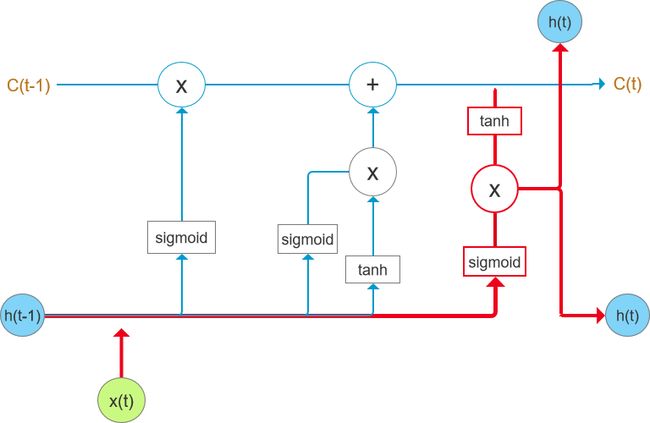
图7 “输出门”
语音识别介绍
语音识别的最主要过程是:(1)从声音波形中提取声学特征;(2)将声学特征转换成发音的因素;(3)使用语言模型等解码技术转变成我们能读懂的文本。语音识别系统的典型结构如图8所示:
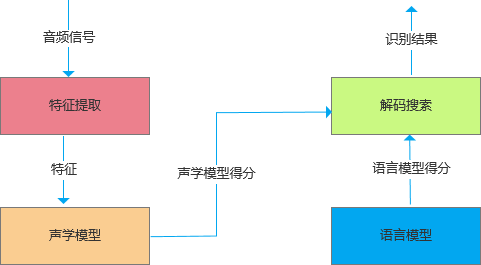
图8 语音识别结构
声学特征提取
声音实际上一种波,原始的音频文件叫WAV文件,WAV文件中存储的除了一个文件头以外,就是声音波形的一个个点。如图9所示:
图9 声音波形示意图
要对声音进行分析,首先对声音进行分帧,把声音切分成很多小的片段,帧与帧之间有一定的交叠,如图10,每一帧长度是25ms,帧移是10ms,两帧之间有25-10=15ms的交叠。
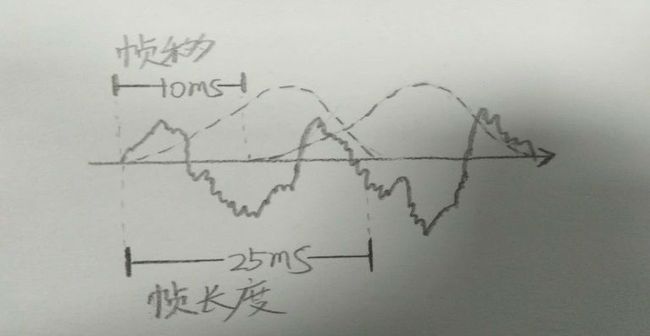
图10 帧切割图
分帧后,音频数据就变成了很多小的片段,然后针对小片段进行特征提取,常见的提取特征的方法有:线性预测编码(Linear Predictive Coding,LPC),梅尔频率倒谱系数(Mel-frequency Cepstrum),把一帧波形变成一个多维向量的过程就是声学特征提取。
声学特征转换成音素(声学模型)
音素是人发音的基本单位。对于英文,常用的音素是一套39个音素组成的集合。对于汉语,基本就是汉语拼音的生母和韵母组成的音素集合。本文例子中LSTM+CTC神经网络就是声学特征转换成音素这个阶段,该阶段的模型被称为声学模型。
音素转文本(语言模型+解码)
得到声音的音素序列后,就可以使用语言模型等解码技术将音素序列转换成我们可以读懂的文本。解码过程对给定的音素序列和若干假设词序列计算声学模型和语言模型分数,将总体输出分数最高的序列作为识别的结果(这部分是比较复杂的,感兴趣的读者可以查阅相关资料)。
语音识别简单实现
本文通过一个简单的例子演示如何用tensorflow的LSTM+CTC完成一个端到端的语音识别,为了简化操作,本例子中的语音识别只训练一句话,这句话中的音素分类也简化成对应的字母(与真实因素的训练过程原理一致)。计算过程如下图所示:
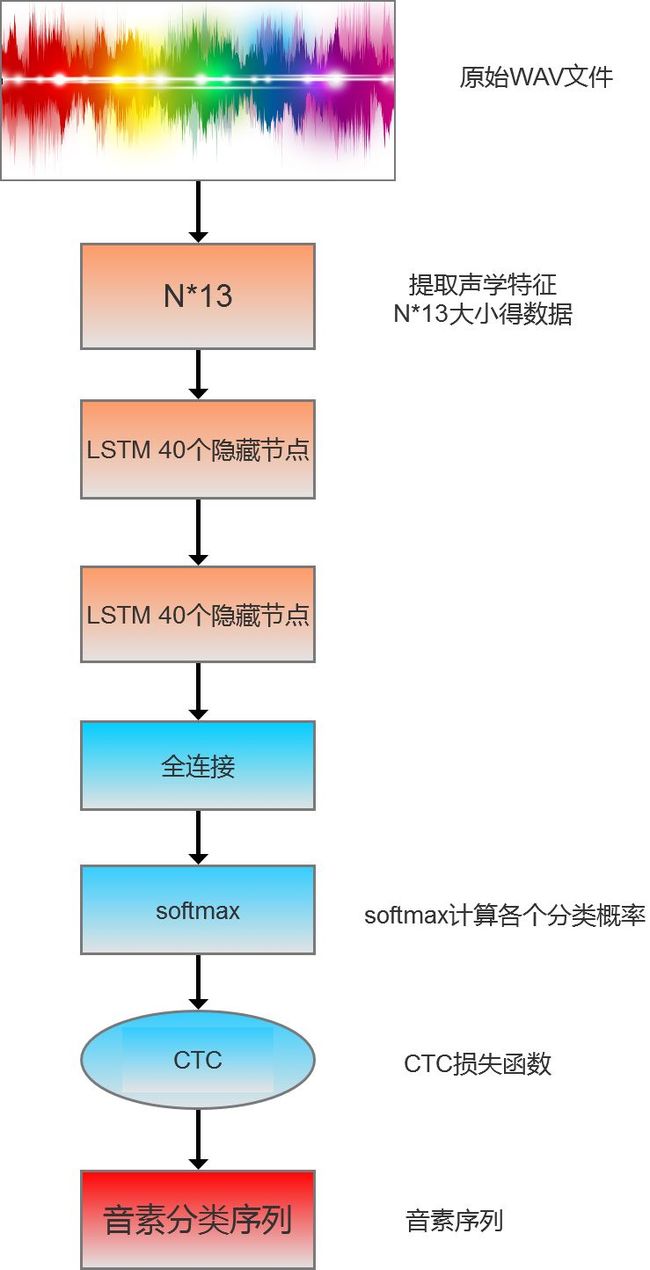
提取WAV文件中特征
首先读者肯定会有疑问?什么是WAV文件?笔者在此简单的介绍一下,WAV格式是微软公司开发的一种声音文件格式,也叫波形声音文件,是最早的数字音频格式,被Windows平台及其应用程序广泛支持,是一种无损的音频数据存放格式。
本文在读取WAV的特征数据后,采用python_speech_features包中的方法来读取文件的MFCC特征,详细代码如下:
def get_audio_feature():
'''
获取wav文件提取mfcc特征之后的数据
'''
audio_filename = "audio.wav"
#读取wav文件内容,fs为采样率, audio为数据
fs, audio = wav.read(audio_filename)
#提取mfcc特征
inputs = mfcc(audio, samplerate=fs)
# 对特征数据进行归一化,减去均值除以方差
feature_inputs = np.asarray(inputs[np.newaxis, :])
feature_inputs = (feature_inputs - np.mean(feature_inputs))/np.std(feature_inputs)
#特征数据的序列长度
feature_seq_len = [feature_inputs.shape[1]]
return feature_inputs, feature_seq_len
函数的返回值feature_seq_len表示这段语音被分割成了多少帧,一帧数据计算出一个13维长度的特征值。返回值feature_inputs是一个二维矩阵,矩阵行数是feature_seq_len长度,列数是13。
将WAV文件对应的文本文件转换成音素分类
本文音素的数量是28,分别对应26个英文字母、空白符和没有分到类情况。WAV文件对应的文本文件的内容是she had your dark suit in greasy wash water all year。现在把这句话转换成整数表示的序列,空白用0表示,a-z分别用数字1-26表示,则转换的结果为:[19 8 5 0 8 1 4 0 25 15 21 18 0 4 1 18 110 19 21 9 20 0 9 14 0 7 18 5 1 19 25 0 231 19 8 0 23 1 20 5 18 0 1 12 12 0 25 5 118],最后将整个序列转换成稀疏三元组结构,这样就可以直接用在tensorflow的tf.sparse_placeholder上。转换代码如下:
with open(target_filename, 'r') as f:
#原始文本为“she had your dark suit in greasy wash water all year”
line = f.readlines()[0].strip()
targets = line.replace(' ', ' ')
targets = targets.split(' ')
targets = np.hstack([SPACE_TOKEN if x == '' else list(x) for x in targets])
targets = np.asarray([SPACE_INDEX if x == SPACE_TOKEN else ord(x) - FIRST_INDEX
for x in targets])
# 将列表转换成稀疏三元组
train_targets = sparse_tuple_from([targets])
print(train_targets)
return train_targets
定义双向LSTM
定义双向LSTM及LSTM之后的特征映射的代码如下:
def inference(inputs, seq_len):
#定义一个向前计算的LSTM单元,40个隐藏单元
cell_fw = tf.contrib.rnn.LSTMCell(num_hidden,
initializer=tf.random_normal_initializer(
mean=0.0, stddev=0.1),
state_is_tuple=True)
# 组成一个有2个cell的list
cells_fw = [cell_fw] * num_layers
# 定义一个向后计算的LSTM单元,40个隐藏单元
cell_bw = tf.contrib.rnn.LSTMCell(num_hidden,
initializer=tf.random_normal_initializer(
mean=0.0, stddev=0.1),
state_is_tuple=True)
# 组成一个有2个cell的list
cells_bw = [cell_bw] * num_layers
outputs, _, _ = tf.contrib.rnn.stack_bidirectional_dynamic_rnn(cells_fw,
cells_bw,
inputs,
dtype=tf.float32,
sequence_length=seq_len)
shape = tf.shape(inputs)
batch_s, max_timesteps = shape[0], shape[1]
outputs = tf.reshape(outputs, [-1, num_hidden])
W = tf.Variable(tf.truncated_normal([num_hidden,
num_classes],
stddev=0.1))
b = tf.Variable(tf.constant(0., shape=[num_classes]))
# 进行全连接线性计算
logits = tf.matmul(outputs, W) + b
# 将全连接计算的结果,由宽度40变成宽度80,
# 即最后的输入给CTC的数据宽度必须是26+2的宽度
logits = tf.reshape(logits, [batch_s, -1, num_classes])
# 转置,将第一维和第二维交换。
# 变成序列的长度放第一维,batch_size放第二维。
# 也是为了适应Tensorflow的CTC的输入格式
logits = tf.transpose(logits, (1, 0, 2))
return logits
模型训练和测试
最后将读取数据、构建LSTM+CTC网络及训练过程结合起来,在完成500次迭代训练后,进行测试,并将结果输出,部分代码如下(完整代码,请读者关注本公众号“大数据技术宅”,输入“语音识别demo”获取):
def main():
# 输入特征数据,形状为:[batch_size, 序列长度,一帧特征数]
inputs = tf.placeholder(tf.float32, [None, None, num_features])
# 输入数据的label,定义成稀疏sparse_placeholder会生成稀疏的tensor:SparseTensor
# 这个结构可以直接输入给ctc求loss
targets = tf.sparse_placeholder(tf.int32)
# 序列的长度,大小是[batch_size]大小
# 表示的是batch中每个样本的有效序列长度是多少
seq_len = tf.placeholder(tf.int32, [None])
# 向前计算网络,定义网络结构,输入是特征数据,输出提供给ctc计算损失值。
logits = inference(inputs, seq_len)
# ctc计算损失
# 参数targets必须是一个值为int32的稀疏tensor的结构:tf.SparseTensor
# 参数logits是前面lstm网络的输出
# 参数seq_len是这个batch的样本中,每个样本的序列长度。
loss = tf.nn.ctc_loss(targets, logits, seq_len)
# 计算损失的平均值
cost = tf.reduce_mean(loss)
训练过程及结果如下图:
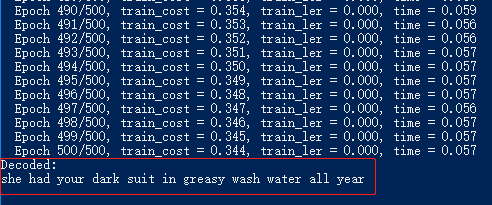
从上图训练结果可以清洗的看出经过500次的迭代训练,语音文件基本已经可以完全识别,本例只演示了一个简单的LSTM+CTC的端到端的训练,实际的语音识别系统还需要大量训练样本以及将音素转换成文本的解码过程。后续文章中,笔者会继续深入语音识别。
最后,在2020开年之际,笔者祝各位爱学习的小哥哥,小姐姐,发大财。