知识图谱初识-什么是知识图谱
目录
-
- 1 概念
-
- 1.1 信息(Information)&知识(Knowledge)
- 1.2 知识图谱(Knowledge Graph)
- 2 知识图谱的技术流程
-
- 2.1 知识获取
- 2.2 知识表示
- 2.3 知识抽取
- 2.4 知识融合
- 3 知识图谱的价值与应用
-
- 3.1 辅助搜索
- 3.2 辅助问答
- 3.3 辅助大数据分析
- 3.4 辅助语言理解
- 3.5 辅助设备互联
- 参考
笔者现阶段也是初识知识图谱,该篇文章仅作为学习分享,不能与大牛们的相提并论,也希望读者能够对不足之处指正。
1 概念
关于知识图谱的历史,这里就略去了,谷歌百度有很多可以查阅的资料。
1.1 信息(Information)&知识(Knowledge)
了解知识图谱的概念之前,我们先区分两个概念:信息(Information) 和 知识(Knowledge)。
之前在知乎看到过一句对这两个概念理解:给人刺激的是信息,理解刺激的是知识。举个例子,“气温是36摄氏度” 这是一条信息,因为我们具备相关的知识,我们会想到:“36摄氏度十分炎热”,“要注意防晒”,“这么热的天呆在空调房里再舒服不过了”。再比如,“气温是96.8华氏度”这是条类似的信息,我们知道了气温是多少,可我们缺少对华氏度相关知识,我们并不能理解“气温96.8华氏度”到底是个怎么样情况。
这里有一张图,也能形象的解释信息和知识的区别和联系。(图片来自知乎 @顾鹏)
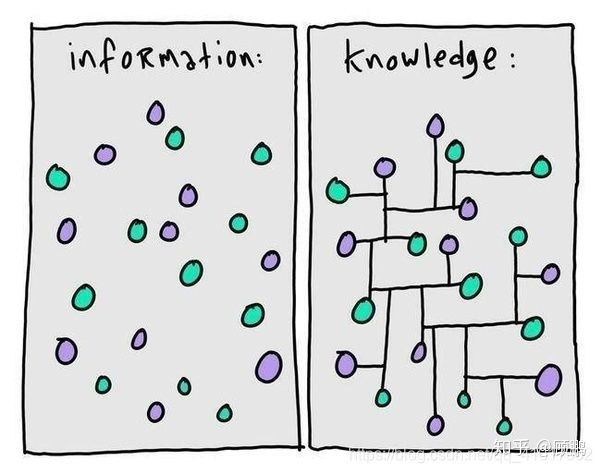
可以看出在信息的基础上,建立实体(如人、机构、地点等)之间的联系,就能形成“知识”。
1.2 知识图谱(Knowledge Graph)
知道什么是知识后,那什么是知识图谱呢?
知识图谱是一种用图模型来描述知识和建模世界万物之间的关联关系的技术方法。知识图谱由节点和边组成。节点可以是实体,如一个人、一本书等,或是抽象的概念,如人工智能、知识图谱等。边可以是实体的属性,如姓名、书名,或是实体之间的关系,如朋友、配偶。可以说,知识图谱,就是成千上万的知识有组织的结合在一起。
如下图所示,知识图谱旨在从数据中识别、发现和推断事物与概念之间的复杂关系,是事物关系的可计算模型。知识图谱的构建涉及知识建模、关系抽取、图存储、关系推理、实体融合等多方面的技术,而知识图谱的应用则涉及语义搜索、智能问答、语言理解、决策分析等多个领域。构建并利用好知识图谱需要系统性地利用包括知识表示(Knowledge Representation)、图数据库、自然语言处理、机器学习等多方面的技术。

2 知识图谱的技术流程
2.1 知识获取
我们可以从多种来源获取知识图谱数据,包括文本、结构化数据库、多媒体数据、传感器数据和人工众包等。
另外,每一种数据源的知识化都需要综合各种不同的技术手段。例如,对于文本数据源,需要综合实体识别、实体链接、关系抽取、事件抽取等各种自然语言处理技术,实现从文本中抽取知识。
2.2 知识表示
知识表示是指用计算机符号描述和表示人脑中的知识,以支持机器模拟人的心智进行推理的方法与技术。
基本描述框架定义知识图谱的基本数据模型(Data Model)和逻辑结构( Structure ) , 如国际万维网联盟( World Wide WebConsortium,W3C)的RDF。W3C 的 RDF 把三元组(Triple)作为基本的数据模型,其基本的逻辑结构包含主语( Subject ) 、谓词( Predicate ) 、宾语(Object)三个部分。
按知识类型的不同, 知识图谱包括词( Vocabulary ) 、实体( Entity ) 、关系( Relation ) 、事件( Event ) 、术语体系(Taxonomy)、规则(Rule)等。词一级的知识以词为中心,并定义词与词之间的关系,如 WordNet、ConceptNet 等。实体一级的知识以实体为中心,并定义实体之间的关系、描述实体的术语体系等。事件则是一种复合的实体。
2.3 知识抽取
知识抽取,即从不同来源、不同结构的数据中进行知识提取,形成知识(结构化数据)存入到知识图谱。大体的任务分类与对应技术如下图所示:
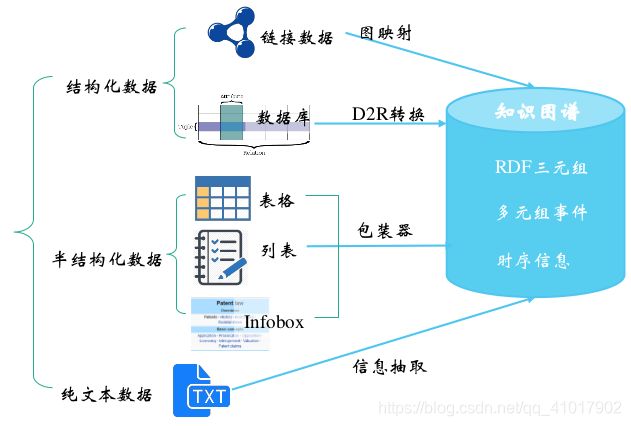
知识抽取有如下几个子任务:
- 命名实体识别
检测:北京是忙碌的城市。[北京]:实体
分类:北京是忙碌的城市。[北京]:地名 - 术语抽取
从语料中发现多个单词组成的相关术语。 - 关系抽取
王思聪是万达集团董事长王健林的独子。→ [王健林] <父子关系> [王思聪] - 事件抽取
例如从一篇新闻报道中抽取出事件发生是触发词、时间、地点等信息,如图二所示。 - 共指消解
弄清楚在一句话中的代词的指代对象。例子如图三所示。
2.4 知识融合
由于知识图谱中的知识来源广泛,存在知识质量良莠不齐、来自不同数据源的知识重复、知识间的关联不够明确等问题,所以必须要进行知识的融合。知识融合是高层次的知识组织,使来自不同知识源的知识在同一框架规范下进行异构数据整合、消歧、加工、推理验证、更新等步骤,达到数据、信息、方法、经验以及人的思想的融合,形成高质量的知识库。
其中,知识更新是一个重要的部分。人类的认知能力、知识储备以及业务需求都会随时间而不断递增。因此,知识图谱的内容也需要与时俱进,不论是通用知识图谱,还是行业知识图谱,它们都需要不断地迭代更新,扩展现有的知识,增加新的知识。

在构建知识图谱时,可以从第三方知识库产品或已有结构化数据中获取知识输入,进行知识图谱的融合。当多个知识图谱进行融合,或者将外部关系数据库合并到本体知识库时,需要处理两个层面的问题:
- 模式层的融合,将新得到的本体融入已有的本体库中,以及新旧本体的融合;
- 数据层的融合,包括实体的指称、属性、关系以及所属类别等,主要的问题是如何避免实例以及关系的冲突问题,造成不必要的冗余。
3 知识图谱的价值与应用
3.1 辅助搜索
互联网的终极形态是万物的互联,而搜索的终极目标是对万物的直接搜索。传统搜索引擎依靠网页之间的超链接实现网页的搜索,而语义搜索是直接对事物进行搜索,如人物、机构、地点等。这些事物可能来自文本、图片、视频、音频、IoT 设备等各种信息资源。而知识图谱和语义技术提供了关于这些事物的分类、属性和关系的描述,使得搜索引擎可以直接对事物进行索引和搜索。比如说,在知识图谱的帮助下,我们搜索“苹果CEO”,便会出现“库克”的搜索结果而不是仅仅针对字面进行搜索。
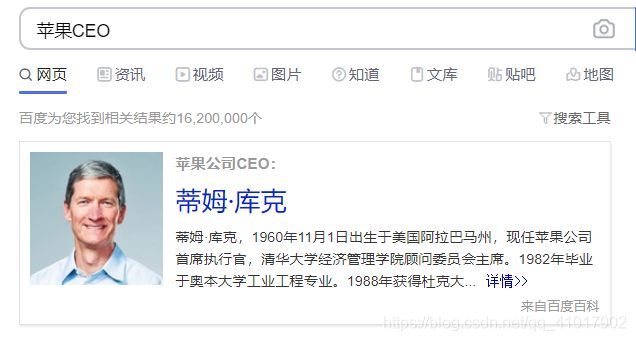
3.2 辅助问答
人与机器通过自然语言进行问答与对话是人工智能实现的关键标志之一。除了辅助搜索,知识图谱也被广泛用于人机问答交互中。在产业界,度秘、Siri的进化版Viv、小爱机器人、天猫精灵背后都有海量知识图谱作为支撑。
3.3 辅助大数据分析
知识图谱和语义技术也被用于辅助进行数据分析与决策。例如,大数据公司 Palantir基于本体融合和集成多种来源的数据,通过知识图谱和语义技术增强数据之间的关联,使得用户可以用更加直观的图谱方式对数据进行关联挖掘与分析。
知识图谱在文本数据的处理和分析中也能发挥独特的作用。例如,知识图谱被广泛用来作为先验知识从文本中抽取实体和关系,如在远程监督中的应用。知识图谱也被用来辅助实现文本中的实体消歧(Entity Disambiguation)、指代消解和文本理解等。
3.4 辅助语言理解
我们先看下面这句话:
The trophy would not fit in the brown suitcase because it was too big (small).
问:What was too big (small)? A: the trophy B: the suitcase
我们来看显然是奖杯太大了,手提箱太小了,所以放不下,但对于没有相关知识的机器来说,辨别到底是哪个太大哪个太小是一件十分困难的事情。正如自然语言理解的先驱 Terry Winograd 所说的,当一个人听到一句话或看到一段句子的时候,会使用自己所有的知识和智能去理解。这不仅包括语法,也包括其拥有的词汇知识、上下文知识,更重要的是对相关事物的理解。在这种情况下,知识图谱可以很大限度的帮助机器理解语言。
3.5 辅助设备互联
人机对话的主要挑战是语义理解,即让机器理解人类语言的语义。另外一个问题是机器之间的对话,这也需要技术手段来表示和处理机器语言的语义。语义技术也可被用来辅助设备之间的语义互联。
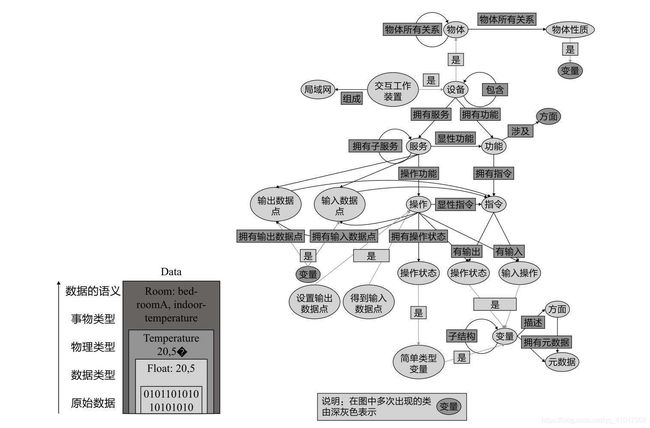
如图所示,一个设备产生的原始数据在封装了语义描述之后,可以更加容易地与其他设备的数据进行融合、交换和互操作,并可以进一步链接进入知识图谱中,以便支持搜索、推理和分析等任务。
参考
- 什么是知识图谱?- 知乎
- 知识图谱入门 (三) 知识抽取
- 《知识图谱方法、实践与应用》 王昊奋 漆桂林 陈华钧主编