redis慢查询日志的访问和管理
通过一组命令来实现对慢查询日志的访问和管理
(1)获取慢查询日志
命令:slowlog get
127.0.0.1:6379> slowlog get 1) 1) (integer) 1 2) (integer) 1513709400 3) (integer) 11 4) 1) "slowlog" 2) "get" 2) 1) (integer) 0 2) (integer) 1513709398 3) (integer) 4 4) 1) "config" 2) "set" 3) "slowlog-log-slower-than" 4) "2"
(2)获取慢查询日志列表当前的长度
命令:slowlog len
127.0.0.1:6379> slowlog len (integer) 2
(3)慢查询日志重置
命令:slowlog reset
实际是对慢查询日志列表做清理操作。
127.0.0.1:6379> slowlog len (integer) 6 127.0.0.1:6379> slowlog reset OK 127.0.0.1:6379> slowlog len (integer) 1 #为什么还有1个,因为阈值设的比较小,slowlog reset就属于慢查询
注意事项
慢查询功能可以有效的帮助我们找到Redis可能存在的瓶颈,但在实际使用过程中要注意以下几点:
(1)slowlog-max-len配置建议:线上建议调大慢查询列表,记录慢查询时Redis会对长命令做截断操作,并不会占用大量内存。
增大慢查询列表可以减缓慢查询被剔除的可能。
(2)slowlog-log-slower-than配置建议:默认值超过10毫秒判定为慢查询,需要根据Redis并发量调整该值。
由于Redis采用单线程响应命令,对于高流量的场景,如果命令执行时间在1毫秒以上,那么Redis最多可以支撑OPS不到1000,因此对于高OPS的场景的Redis建议设置1毫秒。
(3)慢查询只记录命令执行时间,并不包括命令排队和网络传输时间。因此客户端执行命令的时间会大于命令实际执行的时间。
因为命令执行排队机制,慢查询会导致其他命令级联阻塞,因此当客户端出现请求超时,
需要检查该时间点是否有对应的慢查询,从而分析出是否为慢查询导致的命令级联阻塞。
(4)由于慢查询日志是一个先进先出的队列,也就是说如果慢查询比较多的情况下,可能会丢失部分慢查询命令,
为了防止这种情况发生,可以定期执行slowlog get命令将慢查询日志持久化到其他存储中(例如,MySQL),
然后可以制作出可视化界面进行查询。
Redis慢查询总结
慢查询分析
1、什么叫慢查询?
类似于mysql中的慢查询语句,当查询语句的执行时间超过设置的时间阈值就是慢查询语句,会放入慢查询日志中。
redis中慢查询只统计命令生命周期中执行命令的时间,所有没有慢查询并不代表客户端没有超时的问题。(客户端命令生命周期:发送命令,命令排队,命令执行,命令返回)。
2、慢查询的配置参数
redis提供了slowlog-log-slower-than和slowlog-max-len配置慢查询。
1)使用slowlog-log-slower-than来设置执行时间的阈值,默认是 10000微妙;
备注:slowlog-log-slower-than=0记录所有的命令,slowlog-log-slower-than<0对任何命令都不进行记录。
2)slowlog-max-len只是说明了慢查询日志最多存储多少条,实际上慢查询命令存储在列表上,slowlog-max-len就是这个列表的最大长度。当命令超过最大列表长度,按照先进先出算法,最早进入对了的移除。
配置方式:可以通过配置文件配置:

也可以通过命令行客户端发送 config set命令动态修改:
config set slowlog-log-slower-than 20000 config set slowlog-max-len 1000
config rewrite(用来把配置的值持久化到本地配置文件中,启动时需指定配置文件,否则持久化失败)
3、慢查询日志的访问和管理
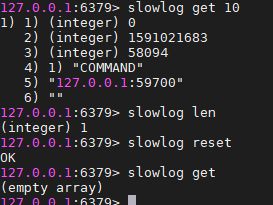
- slowlog get获取的日志分4个属性:id,发生时间戳,执行时间,执行命令+参数
- slowlog reset 用于重置慢查询日志保存列表,就是情况列表中的数据。
注意事项:由于慢查询是一个先进先出的队列,可能会丢失部分慢查询命令,因此线上最好配置在1000以上,同时可以定期执行slowlog get 命令将慢查询日志持久化到其他存储中(比如Mysql)。
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。