携程客户流失分析项目(个人练习+源代码)
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from time import time
import datetime
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.feature_selection import f_classif, SelectFromModel, VarianceThreshold
from sklearn.ensemble import RandomForestClassifier as RFC
%matplotlib inline
plt.rcParams['font.family'] = ['SimHei'] # 显示中文,解决图中无法显示中文的问题
plt.rcParams['axes.unicode_minus']=False
# 读取文件
df = pd.read_table('userlostprob.txt')
# 查看头五行
df.head()
| label | sampleid | d | arrival | iforderpv_24h | decisionhabit_user | historyvisit_7ordernum | historyvisit_totalordernum | hotelcr | ordercanceledprecent | ... | lowestprice_pre2 | lasthtlordergap | businessrate_pre2 | cityuvs | cityorders | lastpvgap | cr | sid | visitnum_oneyear | h | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 24636 | 2016-05-18 | 2016-05-18 | 0 | NaN | NaN | NaN | 1.04 | NaN | ... | 615.0 | NaN | 0.29 | 12.880 | 3.147 | NaN | NaN | 7 | NaN | 12 |
| 1 | 1 | 24637 | 2016-05-18 | 2016-05-18 | 0 | NaN | NaN | NaN | 1.06 | NaN | ... | 513.0 | NaN | 0.53 | 17.933 | 4.913 | NaN | NaN | 33 | NaN | 14 |
| 2 | 0 | 24641 | 2016-05-18 | 2016-05-19 | 0 | NaN | NaN | NaN | 1.05 | NaN | ... | 382.0 | NaN | 0.60 | 3.993 | 0.760 | NaN | NaN | 10 | NaN | 19 |
| 3 | 0 | 24642 | 2016-05-18 | 2016-05-18 | 0 | NaN | NaN | NaN | 1.01 | NaN | ... | 203.0 | NaN | 0.18 | 3.220 | 0.660 | NaN | NaN | 8 | NaN | 16 |
| 4 | 1 | 24644 | 2016-05-18 | 2016-05-19 | 0 | NaN | NaN | NaN | 1.00 | NaN | ... | 84.0 | NaN | NaN | 0.013 | NaN | NaN | NaN | 1 | NaN | 21 |
5 rows × 51 columns
# 观察标签分布状况
df['label'].value_counts()
0 500588
1 189357
Name: label, dtype: int64
# 查看后五行
df.tail()
| label | sampleid | d | arrival | iforderpv_24h | decisionhabit_user | historyvisit_7ordernum | historyvisit_totalordernum | hotelcr | ordercanceledprecent | ... | lowestprice_pre2 | lasthtlordergap | businessrate_pre2 | cityuvs | cityorders | lastpvgap | cr | sid | visitnum_oneyear | h | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 689940 | 1 | 2238419 | 2016-05-15 | 2016-05-17 | 1 | 19.0 | NaN | NaN | 1.06 | NaN | ... | 406.0 | NaN | 0.48 | 13.573 | 1.660 | 1034.0 | 1.0 | 5 | 119.0 | 18 |
| 689941 | 1 | 2238421 | 2016-05-15 | 2016-05-15 | 1 | 10.0 | 3.0 | 3.0 | 1.06 | 0.33 | ... | 199.0 | 713.0 | 0.51 | 2.880 | 0.513 | 179.0 | 2.0 | 15 | 1472.0 | 12 |
| 689942 | 0 | 2238422 | 2016-05-15 | 2016-05-17 | 0 | NaN | NaN | NaN | 1.07 | NaN | ... | 544.0 | NaN | 0.45 | 15.293 | 2.067 | 0.0 | NaN | 8 | 107.0 | 0 |
| 689943 | 0 | 2238425 | 2016-05-15 | 2016-05-17 | 0 | NaN | NaN | NaN | 1.04 | NaN | ... | 156.0 | NaN | 0.29 | 2.467 | 0.333 | NaN | NaN | 4 | NaN | 0 |
| 689944 | 0 | 2238426 | 2016-05-15 | 2016-05-15 | 0 | NaN | NaN | NaN | 1.02 | NaN | ... | 275.0 | NaN | NaN | 12.600 | 2.653 | NaN | NaN | 2 | NaN | 11 |
5 rows × 51 columns
# 随机查看五行
df.sample(5)
| label | sampleid | d | arrival | iforderpv_24h | decisionhabit_user | historyvisit_7ordernum | historyvisit_totalordernum | hotelcr | ordercanceledprecent | ... | lowestprice_pre2 | lasthtlordergap | businessrate_pre2 | cityuvs | cityorders | lastpvgap | cr | sid | visitnum_oneyear | h | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 477013 | 1 | 820235 | 2016-05-21 | 2016-05-21 | 0 | 15.0 | NaN | 15.0 | 1.05 | 0.36 | ... | 582.0 | 18831.0 | 0.48 | 17.220 | 3.400 | 4242.0 | 1.33 | 446 | 906.0 | 9 |
| 426926 | 0 | 736598 | 2016-05-15 | 2016-05-15 | 0 | 1.0 | NaN | 39.0 | 1.05 | 0.16 | ... | 978.0 | 12199.0 | 0.13 | 5.113 | 0.847 | 642.0 | 1.36 | 732 | 2583.0 | 8 |
| 628554 | 0 | 1072402 | 2016-05-20 | 2016-05-20 | 0 | NaN | NaN | 3.0 | 1.02 | 0.00 | ... | 147.0 | 55214.0 | 0.27 | 15.873 | 3.220 | 10002.0 | 1.11 | 186 | 905.0 | 19 |
| 248275 | 0 | 438633 | 2016-05-18 | 2016-06-09 | 0 | 19.0 | 2.0 | 28.0 | 1.02 | 0.78 | ... | NaN | 3329.0 | NaN | 1.320 | 0.087 | 145.0 | 1.12 | 449 | 17397.0 | 11 |
| 198972 | 0 | 356550 | 2016-05-19 | 2016-05-19 | 0 | 7.0 | NaN | 2.0 | 1.04 | 0.50 | ... | 206.0 | 61467.0 | 0.32 | 20.480 | 5.153 | 13264.0 | 1.08 | 59 | 1522.0 | 20 |
5 rows × 51 columns
# 数据形状
df.shape
(689945, 51)
# 查看数据类型
df.dtypes
label int64
sampleid int64
d object
arrival object
iforderpv_24h int64
decisionhabit_user float64
historyvisit_7ordernum float64
historyvisit_totalordernum float64
hotelcr float64
ordercanceledprecent float64
landhalfhours float64
ordercanncelednum float64
commentnums float64
starprefer float64
novoters float64
consuming_capacity float64
historyvisit_avghotelnum float64
cancelrate float64
historyvisit_visit_detailpagenum float64
delta_price1 float64
price_sensitive float64
hoteluv float64
businessrate_pre float64
ordernum_oneyear float64
cr_pre float64
avgprice float64
lowestprice float64
firstorder_bu float64
customereval_pre2 float64
delta_price2 float64
commentnums_pre float64
customer_value_profit float64
commentnums_pre2 float64
cancelrate_pre float64
novoters_pre2 float64
novoters_pre float64
ctrip_profits float64
deltaprice_pre2_t1 float64
lowestprice_pre float64
uv_pre float64
uv_pre2 float64
lowestprice_pre2 float64
lasthtlordergap float64
businessrate_pre2 float64
cityuvs float64
cityorders float64
lastpvgap float64
cr float64
sid int64
visitnum_oneyear float64
h int64
dtype: object
# 查看数据基本信息
df.info()
RangeIndex: 689945 entries, 0 to 689944
Data columns (total 51 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 label 689945 non-null int64
1 sampleid 689945 non-null int64
2 d 689945 non-null object
3 arrival 689945 non-null object
4 iforderpv_24h 689945 non-null int64
5 decisionhabit_user 385450 non-null float64
6 historyvisit_7ordernum 82915 non-null float64
7 historyvisit_totalordernum 386525 non-null float64
8 hotelcr 689148 non-null float64
9 ordercanceledprecent 447831 non-null float64
10 landhalfhours 661312 non-null float64
11 ordercanncelednum 447831 non-null float64
12 commentnums 622029 non-null float64
13 starprefer 464892 non-null float64
14 novoters 672918 non-null float64
15 consuming_capacity 463837 non-null float64
16 historyvisit_avghotelnum 387876 non-null float64
17 cancelrate 678227 non-null float64
18 historyvisit_visit_detailpagenum 307234 non-null float64
19 delta_price1 437146 non-null float64
20 price_sensitive 463837 non-null float64
21 hoteluv 689148 non-null float64
22 businessrate_pre 483896 non-null float64
23 ordernum_oneyear 447831 non-null float64
24 cr_pre 660548 non-null float64
25 avgprice 457261 non-null float64
26 lowestprice 687931 non-null float64
27 firstorder_bu 376993 non-null float64
28 customereval_pre2 661312 non-null float64
29 delta_price2 437750 non-null float64
30 commentnums_pre 598368 non-null float64
31 customer_value_profit 439123 non-null float64
32 commentnums_pre2 648457 non-null float64
33 cancelrate_pre 653015 non-null float64
34 novoters_pre2 657616 non-null float64
35 novoters_pre 648956 non-null float64
36 ctrip_profits 445187 non-null float64
37 deltaprice_pre2_t1 543180 non-null float64
38 lowestprice_pre 659689 non-null float64
39 uv_pre 660548 non-null float64
40 uv_pre2 661189 non-null float64
41 lowestprice_pre2 660664 non-null float64
42 lasthtlordergap 447831 non-null float64
43 businessrate_pre2 602960 non-null float64
44 cityuvs 682274 non-null float64
45 cityorders 651263 non-null float64
46 lastpvgap 592818 non-null float64
47 cr 457896 non-null float64
48 sid 689945 non-null int64
49 visitnum_oneyear 592910 non-null float64
50 h 689945 non-null int64
dtypes: float64(44), int64(5), object(2)
memory usage: 268.5+ MB
# 描述性统计
df.describe([0.01, 0.1, 0.25, 0.5, 0.75, 0.9, 0.99])
| label | sampleid | iforderpv_24h | decisionhabit_user | historyvisit_7ordernum | historyvisit_totalordernum | hotelcr | ordercanceledprecent | landhalfhours | ordercanncelednum | ... | lowestprice_pre2 | lasthtlordergap | businessrate_pre2 | cityuvs | cityorders | lastpvgap | cr | sid | visitnum_oneyear | h | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 689945.000000 | 6.899450e+05 | 689945.000000 | 385450.000000 | 82915.000000 | 386525.000000 | 689148.000000 | 447831.000000 | 661312.000000 | 447831.000000 | ... | 660664.000000 | 447831.000000 | 602960.000000 | 682274.000000 | 651263.000000 | 592818.000000 | 457896.000000 | 689945.000000 | 5.929100e+05 | 689945.000000 |
| mean | 0.274452 | 6.285402e+05 | 0.193737 | 5.317048 | 1.856094 | 11.710487 | 1.060996 | 0.342119 | 6.086366 | 154.179369 | ... | 318.541812 | 101830.919400 | 0.368237 | 10.648278 | 2.253250 | 12049.409382 | 1.137476 | 153.702414 | 1.855185e+04 | 14.462315 |
| std | 0.446238 | 4.146815e+05 | 0.395226 | 38.524483 | 2.103862 | 17.251429 | 0.045264 | 0.354210 | 12.413225 | 398.456986 | ... | 351.913035 | 122784.313864 | 0.219945 | 15.696682 | 3.538453 | 25601.374138 | 0.204789 | 277.807697 | 2.288603e+05 | 6.301575 |
| min | 0.000000 | 2.463600e+04 | 0.000000 | 0.000000 | 1.000000 | 1.000000 | 1.000000 | 0.000000 | 0.000000 | 0.000000 | ... | 1.000000 | 0.000000 | 0.000000 | 0.007000 | 0.007000 | 0.000000 | 1.000000 | 0.000000 | 1.000000e+00 | 0.000000 |
| 1% | 0.000000 | 3.620588e+04 | 0.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 0.000000 | 0.000000 | 0.000000 | ... | 52.000000 | 244.000000 | 0.010000 | 0.013000 | 0.007000 | 0.000000 | 1.000000 | 1.000000 | 2.100000e+01 | 0.000000 |
| 10% | 0.000000 | 1.398464e+05 | 0.000000 | 1.000000 | 1.000000 | 1.000000 | 1.010000 | 0.000000 | 0.000000 | 0.000000 | ... | 101.000000 | 3518.000000 | 0.050000 | 0.160000 | 0.033000 | 127.000000 | 1.000000 | 4.000000 | 1.610000e+02 | 6.000000 |
| 25% | 0.000000 | 3.123200e+05 | 0.000000 | 2.000000 | 1.000000 | 2.000000 | 1.030000 | 0.000000 | 0.000000 | 0.000000 | ... | 145.000000 | 14999.000000 | 0.170000 | 0.827000 | 0.127000 | 551.000000 | 1.000000 | 17.000000 | 4.710000e+02 | 11.000000 |
| 50% | 0.000000 | 5.996370e+05 | 0.000000 | 3.000000 | 1.000000 | 6.000000 | 1.050000 | 0.250000 | 0.000000 | 2.000000 | ... | 233.000000 | 46890.000000 | 0.400000 | 3.527000 | 0.627000 | 2848.000000 | 1.050000 | 62.000000 | 1.315000e+03 | 15.000000 |
| 75% | 1.000000 | 8.874600e+05 | 0.000000 | 5.000000 | 2.000000 | 14.000000 | 1.090000 | 0.570000 | 4.000000 | 153.000000 | ... | 388.000000 | 138953.000000 | 0.550000 | 13.327000 | 2.747000 | 10726.000000 | 1.210000 | 180.000000 | 3.141000e+03 | 20.000000 |
| 90% | 1.000000 | 1.059705e+06 | 1.000000 | 10.000000 | 3.000000 | 29.000000 | 1.120000 | 0.980000 | 27.000000 | 492.000000 | ... | 611.000000 | 311492.000000 | 0.650000 | 35.567000 | 7.547000 | 30384.900000 | 1.400000 | 392.000000 | 6.634000e+03 | 22.000000 |
| 99% | 1.000000 | 2.226893e+06 | 1.000000 | 27.000000 | 7.000000 | 82.000000 | 1.190000 | 1.000000 | 48.000000 | 1752.000000 | ... | 1464.000000 | 484734.000000 | 0.780000 | 66.007000 | 14.453000 | 138722.000000 | 2.000000 | 1212.000000 | 2.625670e+05 | 23.000000 |
| max | 1.000000 | 2.238426e+06 | 1.000000 | 3167.000000 | 106.000000 | 711.000000 | 3.180000 | 1.000000 | 49.000000 | 13475.000000 | ... | 43700.000000 | 527026.000000 | 0.990000 | 67.140000 | 14.507000 | 194386.000000 | 11.000000 | 9956.000000 | 9.651192e+06 | 23.000000 |
12 rows × 49 columns
# 删除重复值
df.drop_duplicates(inplace=True)
df.shape
(689945, 51)
# 根据缺失值比例进行排序
null = df.isnull().mean().reset_index().sort_values(0)
null_1 = null.rename(columns={'index':'特征', 0:'缺失比'})
null_1
| 特征 | 缺失比 | |
|---|---|---|
| 0 | label | 0.000000 |
| 48 | sid | 0.000000 |
| 4 | iforderpv_24h | 0.000000 |
| 50 | h | 0.000000 |
| 2 | d | 0.000000 |
| 1 | sampleid | 0.000000 |
| 3 | arrival | 0.000000 |
| 8 | hotelcr | 0.001155 |
| 21 | hoteluv | 0.001155 |
| 26 | lowestprice | 0.002919 |
| 44 | cityuvs | 0.011118 |
| 17 | cancelrate | 0.016984 |
| 14 | novoters | 0.024679 |
| 28 | customereval_pre2 | 0.041500 |
| 10 | landhalfhours | 0.041500 |
| 40 | uv_pre2 | 0.041679 |
| 41 | lowestprice_pre2 | 0.042440 |
| 39 | uv_pre | 0.042608 |
| 24 | cr_pre | 0.042608 |
| 38 | lowestprice_pre | 0.043853 |
| 34 | novoters_pre2 | 0.046857 |
| 33 | cancelrate_pre | 0.053526 |
| 45 | cityorders | 0.056065 |
| 35 | novoters_pre | 0.059409 |
| 32 | commentnums_pre2 | 0.060132 |
| 12 | commentnums | 0.098437 |
| 43 | businessrate_pre2 | 0.126075 |
| 30 | commentnums_pre | 0.132731 |
| 49 | visitnum_oneyear | 0.140642 |
| 46 | lastpvgap | 0.140775 |
| 37 | deltaprice_pre2_t1 | 0.212720 |
| 22 | businessrate_pre | 0.298646 |
| 13 | starprefer | 0.326190 |
| 20 | price_sensitive | 0.327719 |
| 15 | consuming_capacity | 0.327719 |
| 47 | cr | 0.336330 |
| 25 | avgprice | 0.337250 |
| 23 | ordernum_oneyear | 0.350918 |
| 42 | lasthtlordergap | 0.350918 |
| 11 | ordercanncelednum | 0.350918 |
| 9 | ordercanceledprecent | 0.350918 |
| 36 | ctrip_profits | 0.354750 |
| 31 | customer_value_profit | 0.363539 |
| 29 | delta_price2 | 0.365529 |
| 19 | delta_price1 | 0.366405 |
| 16 | historyvisit_avghotelnum | 0.437816 |
| 7 | historyvisit_totalordernum | 0.439774 |
| 5 | decisionhabit_user | 0.441332 |
| 27 | firstorder_bu | 0.453590 |
| 18 | historyvisit_visit_detailpagenum | 0.554698 |
| 6 | historyvisit_7ordernum | 0.879824 |
# 绘制密度图
plt.figure(figsize=(8,6))
sns.kdeplot(null_1['缺失比'], shade=True)

# 用条形图观察缺失值
plt.figure(figsize=(8,6))
plt.bar(range(null_1.shape[0]), null_1['缺失比'], label='lost rate')
plt.legend(loc='best')
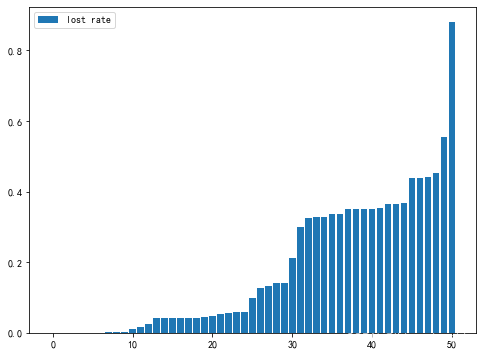
# 删除缺失值过多的列
df = df.drop(['historyvisit_7ordernum'], axis=1)
df
| label | sampleid | d | arrival | iforderpv_24h | decisionhabit_user | historyvisit_totalordernum | hotelcr | ordercanceledprecent | landhalfhours | ... | lowestprice_pre2 | lasthtlordergap | businessrate_pre2 | cityuvs | cityorders | lastpvgap | cr | sid | visitnum_oneyear | h | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 24636 | 2016-05-18 | 2016-05-18 | 0 | NaN | NaN | 1.04 | NaN | 22.0 | ... | 615.0 | NaN | 0.29 | 12.880 | 3.147 | NaN | NaN | 7 | NaN | 12 |
| 1 | 1 | 24637 | 2016-05-18 | 2016-05-18 | 0 | NaN | NaN | 1.06 | NaN | 0.0 | ... | 513.0 | NaN | 0.53 | 17.933 | 4.913 | NaN | NaN | 33 | NaN | 14 |
| 2 | 0 | 24641 | 2016-05-18 | 2016-05-19 | 0 | NaN | NaN | 1.05 | NaN | 3.0 | ... | 382.0 | NaN | 0.60 | 3.993 | 0.760 | NaN | NaN | 10 | NaN | 19 |
| 3 | 0 | 24642 | 2016-05-18 | 2016-05-18 | 0 | NaN | NaN | 1.01 | NaN | 2.0 | ... | 203.0 | NaN | 0.18 | 3.220 | 0.660 | NaN | NaN | 8 | NaN | 16 |
| 4 | 1 | 24644 | 2016-05-18 | 2016-05-19 | 0 | NaN | NaN | 1.00 | NaN | 0.0 | ... | 84.0 | NaN | NaN | 0.013 | NaN | NaN | NaN | 1 | NaN | 21 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 689940 | 1 | 2238419 | 2016-05-15 | 2016-05-17 | 1 | 19.0 | NaN | 1.06 | NaN | 1.0 | ... | 406.0 | NaN | 0.48 | 13.573 | 1.660 | 1034.0 | 1.0 | 5 | 119.0 | 18 |
| 689941 | 1 | 2238421 | 2016-05-15 | 2016-05-15 | 1 | 10.0 | 3.0 | 1.06 | 0.33 | 49.0 | ... | 199.0 | 713.0 | 0.51 | 2.880 | 0.513 | 179.0 | 2.0 | 15 | 1472.0 | 12 |
| 689942 | 0 | 2238422 | 2016-05-15 | 2016-05-17 | 0 | NaN | NaN | 1.07 | NaN | 0.0 | ... | 544.0 | NaN | 0.45 | 15.293 | 2.067 | 0.0 | NaN | 8 | 107.0 | 0 |
| 689943 | 0 | 2238425 | 2016-05-15 | 2016-05-17 | 0 | NaN | NaN | 1.04 | NaN | 0.0 | ... | 156.0 | NaN | 0.29 | 2.467 | 0.333 | NaN | NaN | 4 | NaN | 0 |
| 689944 | 0 | 2238426 | 2016-05-15 | 2016-05-15 | 0 | NaN | NaN | 1.02 | NaN | 0.0 | ... | 275.0 | NaN | NaN | 12.600 | 2.653 | NaN | NaN | 2 | NaN | 11 |
689945 rows × 50 columns
# 异常值观察
df.describe([0.01, 0.25, 0.5, 0.75, 0.99]).T
| count | mean | std | min | 1% | 25% | 50% | 75% | 99% | max | |
|---|---|---|---|---|---|---|---|---|---|---|
| label | 689945.0 | 0.274452 | 0.446238 | 0.000 | 0.00000 | 0.000 | 0.000 | 1.000 | 1.000000e+00 | 1.000 |
| sampleid | 689945.0 | 628540.209625 | 414681.498697 | 24636.000 | 36205.88000 | 312320.000 | 599637.000 | 887460.000 | 2.226893e+06 | 2238426.000 |
| iforderpv_24h | 689945.0 | 0.193737 | 0.395226 | 0.000 | 0.00000 | 0.000 | 0.000 | 0.000 | 1.000000e+00 | 1.000 |
| decisionhabit_user | 385450.0 | 5.317048 | 38.524483 | 0.000 | 1.00000 | 2.000 | 3.000 | 5.000 | 2.700000e+01 | 3167.000 |
| historyvisit_totalordernum | 386525.0 | 11.710487 | 17.251429 | 1.000 | 1.00000 | 2.000 | 6.000 | 14.000 | 8.200000e+01 | 711.000 |
| hotelcr | 689148.0 | 1.060996 | 0.045264 | 1.000 | 1.00000 | 1.030 | 1.050 | 1.090 | 1.190000e+00 | 3.180 |
| ordercanceledprecent | 447831.0 | 0.342119 | 0.354210 | 0.000 | 0.00000 | 0.000 | 0.250 | 0.570 | 1.000000e+00 | 1.000 |
| landhalfhours | 661312.0 | 6.086366 | 12.413225 | 0.000 | 0.00000 | 0.000 | 0.000 | 4.000 | 4.800000e+01 | 49.000 |
| ordercanncelednum | 447831.0 | 154.179369 | 398.456986 | 0.000 | 0.00000 | 0.000 | 2.000 | 153.000 | 1.752000e+03 | 13475.000 |
| commentnums | 622029.0 | 1272.090888 | 2101.871601 | 0.000 | 1.00000 | 115.000 | 514.000 | 1670.000 | 8.796000e+03 | 34189.000 |
| starprefer | 464892.0 | 67.532304 | 19.175094 | 0.000 | 20.00000 | 53.300 | 69.400 | 80.300 | 1.000000e+02 | 100.000 |
| novoters | 672918.0 | 1706.247901 | 2811.690007 | 1.000 | 1.00000 | 157.000 | 692.000 | 2196.000 | 1.157600e+04 | 45455.000 |
| consuming_capacity | 463837.0 | 39.154140 | 23.240147 | 0.000 | 8.00000 | 22.000 | 33.000 | 51.000 | 1.000000e+02 | 100.000 |
| historyvisit_avghotelnum | 387876.0 | 6.510179 | 41.045261 | 0.000 | 1.00000 | 2.000 | 4.000 | 7.000 | 2.900000e+01 | 3167.000 |
| cancelrate | 678227.0 | 1051.604143 | 1509.066134 | 1.000 | 2.00000 | 137.000 | 503.000 | 1373.000 | 6.399000e+03 | 18930.000 |
| historyvisit_visit_detailpagenum | 307234.0 | 37.153603 | 73.402891 | 1.000 | 1.00000 | 6.000 | 18.000 | 44.000 | 2.620000e+02 | 6199.000 |
| delta_price1 | 437146.0 | 79.067012 | 512.942824 | -99879.000 | -1227.55000 | -31.000 | 81.000 | 226.000 | 1.081000e+03 | 5398.000 |
| price_sensitive | 463837.0 | 24.645863 | 26.685606 | 0.000 | 0.00000 | 5.000 | 16.000 | 33.000 | 1.000000e+02 | 100.000 |
| hoteluv | 689148.0 | 95.092708 | 169.981527 | 0.007 | 0.16700 | 10.427 | 36.180 | 107.747 | 9.641130e+02 | 1722.613 |
| businessrate_pre | 483896.0 | 0.372717 | 0.232791 | 0.000 | 0.01000 | 0.150 | 0.390 | 0.570 | 8.000000e-01 | 0.990 |
| ordernum_oneyear | 447831.0 | 11.642061 | 17.137209 | 1.000 | 1.00000 | 2.000 | 6.000 | 14.000 | 8.100000e+01 | 711.000 |
| cr_pre | 660548.0 | 1.062906 | 0.044588 | 1.000 | 1.00000 | 1.030 | 1.060 | 1.090 | 1.190000e+00 | 2.950 |
| avgprice | 457261.0 | 422.458701 | 290.853332 | 1.000 | 91.00000 | 232.000 | 350.000 | 524.000 | 1.491000e+03 | 6383.000 |
| lowestprice | 687931.0 | 318.806242 | 575.782415 | -3.000 | 37.00000 | 116.000 | 200.000 | 380.000 | 1.823000e+03 | 100000.000 |
| firstorder_bu | 376993.0 | 11.697795 | 2.746821 | 1.000 | 3.00000 | 12.000 | 13.000 | 13.000 | 1.700000e+01 | 21.000 |
| customereval_pre2 | 661312.0 | 3.048519 | 1.226635 | 0.000 | 0.00000 | 2.000 | 3.000 | 4.000 | 5.500000e+00 | 6.000 |
| delta_price2 | 437750.0 | 77.277208 | 391.413839 | -43344.000 | -949.00000 | -29.000 | 69.000 | 198.000 | 1.018000e+03 | 5114.000 |
| commentnums_pre | 598368.0 | 1415.159561 | 2329.418922 | 0.000 | 1.00000 | 137.000 | 592.000 | 1862.000 | 9.732000e+03 | 34189.000 |
| customer_value_profit | 439123.0 | 3.038409 | 6.625281 | -24.075 | -0.29678 | 0.269 | 0.991 | 3.138 | 2.845100e+01 | 598.064 |
| commentnums_pre2 | 648457.0 | 1313.388737 | 1719.513354 | 0.000 | 3.00000 | 270.000 | 768.000 | 1780.000 | 7.457000e+03 | 34189.000 |
| cancelrate_pre | 653015.0 | 0.344422 | 0.179147 | 0.000 | 0.05000 | 0.230 | 0.320 | 0.420 | 1.000000e+00 | 1.000 |
| novoters_pre2 | 657616.0 | 1787.197614 | 2316.712985 | 1.000 | 5.00000 | 391.000 | 1054.000 | 2413.000 | 1.001800e+04 | 45436.000 |
| novoters_pre | 648956.0 | 1890.698450 | 3116.120062 | 1.000 | 2.00000 | 187.000 | 783.000 | 2453.000 | 1.383900e+04 | 45436.000 |
| ctrip_profits | 445187.0 | 4.208495 | 9.314438 | -44.313 | -0.39300 | 0.340 | 1.347 | 4.320 | 4.075580e+01 | 600.820 |
| deltaprice_pre2_t1 | 543180.0 | 3.283740 | 48.805880 | -2296.000 | -103.00000 | -3.000 | 2.000 | 10.000 | 1.110000e+02 | 3324.000 |
| lowestprice_pre | 659689.0 | 315.954583 | 463.723643 | 1.000 | 38.00000 | 118.000 | 208.000 | 385.000 | 1.750000e+03 | 100000.000 |
| uv_pre | 660548.0 | 107.846076 | 186.731907 | 0.007 | 0.24000 | 12.533 | 42.500 | 124.707 | 1.047787e+03 | 1722.613 |
| uv_pre2 | 661189.0 | 103.352990 | 157.117863 | 0.007 | 0.50000 | 17.563 | 51.287 | 126.200 | 8.567254e+02 | 1722.613 |
| lowestprice_pre2 | 660664.0 | 318.541812 | 351.913035 | 1.000 | 52.00000 | 145.000 | 233.000 | 388.000 | 1.464000e+03 | 43700.000 |
| lasthtlordergap | 447831.0 | 101830.919400 | 122784.313864 | 0.000 | 244.00000 | 14999.000 | 46890.000 | 138953.000 | 4.847340e+05 | 527026.000 |
| businessrate_pre2 | 602960.0 | 0.368237 | 0.219945 | 0.000 | 0.01000 | 0.170 | 0.400 | 0.550 | 7.800000e-01 | 0.990 |
| cityuvs | 682274.0 | 10.648278 | 15.696682 | 0.007 | 0.01300 | 0.827 | 3.527 | 13.327 | 6.600700e+01 | 67.140 |
| cityorders | 651263.0 | 2.253250 | 3.538453 | 0.007 | 0.00700 | 0.127 | 0.627 | 2.747 | 1.445300e+01 | 14.507 |
| lastpvgap | 592818.0 | 12049.409382 | 25601.374138 | 0.000 | 0.00000 | 551.000 | 2848.000 | 10726.000 | 1.387220e+05 | 194386.000 |
| cr | 457896.0 | 1.137476 | 0.204789 | 1.000 | 1.00000 | 1.000 | 1.050 | 1.210 | 2.000000e+00 | 11.000 |
| sid | 689945.0 | 153.702414 | 277.807697 | 0.000 | 1.00000 | 17.000 | 62.000 | 180.000 | 1.212000e+03 | 9956.000 |
| visitnum_oneyear | 592910.0 | 18551.846682 | 228860.311117 | 1.000 | 21.00000 | 471.000 | 1315.000 | 3141.000 | 2.625670e+05 | 9651192.000 |
| h | 689945.0 | 14.462315 | 6.301575 | 0.000 | 0.00000 | 11.000 | 15.000 | 20.000 | 2.300000e+01 | 23.000 |
# 查看异常值的列,这里出现了负数价格,以及出现过高的价格
df[['lowestprice_pre', 'lowestprice']].describe([0.01, 0.25, 0.5, 0.75, 0.99]).T
| count | mean | std | min | 1% | 25% | 50% | 75% | 99% | max | |
|---|---|---|---|---|---|---|---|---|---|---|
| lowestprice_pre | 659689.0 | 315.954583 | 463.723643 | 1.0 | 38.0 | 118.0 | 208.0 | 385.0 | 1750.0 | 100000.0 |
| lowestprice | 687931.0 | 318.806242 | 575.782415 | -3.0 | 37.0 | 116.0 | 200.0 | 380.0 | 1823.0 | 100000.0 |
# 存储异常值的列
col_block = ['lowestprice_pre', 'lowestprice']
# 定义盖帽法函数,去除异常值
def block_upper(x):
upper = x.quantile(0.99)
out = x.mask(x > upper, upper)
return out
def block_lower(x):
lower = x.quantile(0.01)
out = x.mask(x < lower, lower)
return out
# 处理异常值
df[col_block] = df[col_block].apply(block_upper)
df[col_block] = df[col_block].apply(block_lower)
df[['lowestprice_pre', 'lowestprice']].describe([0.01, 0.25, 0.5, 0.75, 0.99]).T
| count | mean | std | min | 1% | 25% | 50% | 75% | 99% | max | |
|---|---|---|---|---|---|---|---|---|---|---|
| lowestprice_pre | 659689.0 | 304.439507 | 287.192512 | 38.0 | 38.0 | 118.0 | 208.0 | 385.0 | 1750.0 | 1750.0 |
| lowestprice | 687931.0 | 305.025771 | 297.382838 | 37.0 | 37.0 | 116.0 | 200.0 | 380.0 | 1823.0 | 1823.0 |
# 深拷贝,不随原数据而改变
df_copy = df.copy(deep=True)
# 去除标签和编号的数据
X = df_copy.iloc[:, 2:]
# 标签列
y = df_copy.iloc[:, 0]
X.head(10)
| d | arrival | iforderpv_24h | decisionhabit_user | historyvisit_totalordernum | hotelcr | ordercanceledprecent | landhalfhours | ordercanncelednum | commentnums | ... | lowestprice_pre2 | lasthtlordergap | businessrate_pre2 | cityuvs | cityorders | lastpvgap | cr | sid | visitnum_oneyear | h | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2016-05-18 | 2016-05-18 | 0 | NaN | NaN | 1.04 | NaN | 22.0 | NaN | 1089.0 | ... | 615.0 | NaN | 0.29 | 12.880 | 3.147 | NaN | NaN | 7 | NaN | 12 |
| 1 | 2016-05-18 | 2016-05-18 | 0 | NaN | NaN | 1.06 | NaN | 0.0 | NaN | 5612.0 | ... | 513.0 | NaN | 0.53 | 17.933 | 4.913 | NaN | NaN | 33 | NaN | 14 |
| 2 | 2016-05-18 | 2016-05-19 | 0 | NaN | NaN | 1.05 | NaN | 3.0 | NaN | 256.0 | ... | 382.0 | NaN | 0.60 | 3.993 | 0.760 | NaN | NaN | 10 | NaN | 19 |
| 3 | 2016-05-18 | 2016-05-18 | 0 | NaN | NaN | 1.01 | NaN | 2.0 | NaN | NaN | ... | 203.0 | NaN | 0.18 | 3.220 | 0.660 | NaN | NaN | 8 | NaN | 16 |
| 4 | 2016-05-18 | 2016-05-19 | 0 | NaN | NaN | 1.00 | NaN | 0.0 | NaN | NaN | ... | 84.0 | NaN | NaN | 0.013 | NaN | NaN | NaN | 1 | NaN | 21 |
| 5 | 2016-05-18 | 2016-05-20 | 0 | NaN | NaN | 1.02 | NaN | 0.0 | NaN | 15.0 | ... | 408.0 | NaN | NaN | 2.880 | 0.427 | NaN | NaN | 1 | NaN | 21 |
| 6 | 2016-05-18 | 2016-05-25 | 0 | NaN | NaN | 1.12 | NaN | 0.0 | NaN | 2578.0 | ... | 145.0 | NaN | NaN | 4.427 | 0.493 | NaN | NaN | 1 | NaN | 22 |
| 7 | 2016-05-18 | 2016-05-20 | 0 | 3.0 | 21.0 | 1.11 | 0.79 | 0.0 | 395.0 | NaN | ... | 204.0 | 10475.0 | 0.53 | 12.713 | 1.987 | 7566.0 | 1.5 | 23 | 1265.0 | 17 |
| 8 | 2016-05-18 | 2016-05-19 | 0 | 13.0 | NaN | 1.08 | NaN | 0.0 | NaN | 2572.0 | ... | 99.0 | NaN | 0.41 | 5.393 | 0.860 | 15.0 | 1.0 | 20 | 596.0 | 20 |
| 9 | 2016-05-18 | 2016-06-08 | 1 | 2.0 | 7.0 | 1.07 | 0.86 | 47.0 | 6.0 | NaN | ... | 191.0 | 18873.0 | 0.52 | 3.093 | 0.287 | 288.0 | 1.0 | 31 | 21926.0 | 7 |
10 rows × 48 columns
# 数据集切分
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
# 删除日期列
col_date = ['d', 'arrival']
X_train.drop(col_date, axis=1, inplace=True)
X_train.shape
(517458, 46)
# 对不同类型特征进行选择
col = X_train.columns.tolist()
col_no = ['sid', 'iforderpv_24h', 'h'] # 没有缺失值的数据,除去两个日期特征
col_clf = ['decisionhabit_user'] # 分类特征
col_neg = ['delta_price1', 'delta_price2', 'customer_value_profit', 'ctrip_profits', 'deltaprice_pre2_t1'] # 含有负数的特征
col_35 = ['ordernum_oneyear', 'lasthtlordergap', 'ordercanncelednum',
'ordercanceledprecent', 'ctrip_profits', 'historyvisit_avghotelnum', 'historyvisit_totalordernum', # 缺失值在35以上的特征
'decisionhabit_user', 'firstorder_bu', 'historyvisit_visit_detailpagenum']
col_std = X_train.columns[X_train.describe(include='all').T['std'] > 100].to_list() # 方差大于100的列
col_std.remove('sid')
col_std.remove('delta_price2')
col_std.remove('delta_price1')
col_std.remove('lasthtlordergap')
col_norm = list(set(col) - set(col_no + col_clf + col_neg + col_35))
# 对训练集填充缺失值
X_train[col_clf] = X_train[col_clf].fillna(X_train[col_clf].mode())
X_train[col_neg] = X_train[col_neg].fillna(X_train[col_neg].median())
X_train[col_35] = X_train[col_35].fillna(-1)
X_train[col_std] = X_train[col_std].fillna(X_train[col_std].median())
X_train[col_norm] = X_train[col_norm].fillna(X_train[col_norm].mean())
# 对测试集填充缺失值
X_test[col_clf] = X_test[col_clf].fillna(X_test[col_clf].mode())
X_test[col_neg] = X_test[col_neg].fillna(X_test[col_neg].median())
X_test[col_35] = X_test[col_35].fillna(-1)
X_test[col_std] = X_test[col_std].fillna(X_test[col_std].median())
X_test[col_norm] = X_test[col_norm].fillna(X_test[col_norm].mean())
# 查看缺失数据数
X_train.isnull().any().sum()
0
X_test.isnull().any().sum()
0
X_train.shape
(517458, 46)
X_test.shape
(172487, 48)
# 方差过滤
selector = VarianceThreshold()
X_train_var = selector.fit_transform(X_train)
X_train_var.shape
(517458, 46)
# F检验
f, p_values = f_classif(X_train, y_train)
(p_values > 0.01).sum()
6
# F检验筛选之后的训练集
col_f = X_train.columns[p_values <= 0.01]
X_train = X_train[col_f]
X_train.shape
(517458, 40)
X_test = X_test[col_f]
X_test.shape
(172487, 40)
# 重置索引
X_train = X_train.reset_index(drop=True)
X_test = X_test.reset_index(drop=True)
y_train = y_train.reset_index(drop=True)
y_test = y_test.reset_index(drop=True)
# 建模,生成特征重要性
rfc = RFC(n_estimators=10, random_state=42)
importances = rfc.fit(X_train, y_train).feature_importances_
importances
array([0.0116028 , 0.01896167, 0.01802851, 0.0150776 , 0.01591757,
0.02015549, 0.02034934, 0.0203898 , 0.01943307, 0.0211841 ,
0.01791408, 0.02056686, 0.02291317, 0.02291462, 0.02051174,
0.02323111, 0.02106971, 0.01054197, 0.02306534, 0.01938803,
0.0258305 , 0.02571515, 0.02508617, 0.02485002, 0.02534584,
0.02850795, 0.02408976, 0.02625239, 0.0279376 , 0.02743348,
0.02772216, 0.03058076, 0.02754623, 0.04068007, 0.03904556,
0.03655198, 0.03553142, 0.03861745, 0.04116244, 0.03829647])
# 交叉检验和嵌入法,画出学习曲线
scores = []
thresholds = np.linspace(0, importances.max(), 20)
for i in thresholds:
time0 = time()
X_embedded = SelectFromModel(rfc, threshold=i).fit_transform(X_train, y_train)
score = cross_val_score(rfc, X_embedded, y_train, cv=5, n_jobs=-1).mean()
scores.append(score)
print(datetime.datetime.fromtimestamp(time() - time0).strftime('%M:%S:%f'))
plt.plot(thresholds, scores)
plt.show()
01:12:090613
01:13:526636
01:09:249811
01:08:676264
01:07:224143
01:06:510684
01:14:200829
01:13:976302
01:13:173232
01:07:879761
01:05:081422
01:03:703478
00:57:668075
00:55:913328
00:49:275084
00:47:250707
00:48:596243
00:53:333874
00:45:020932
00:53:343730

# 查看最大分数
max(scores)
0.9507844100831351
# 查看最大分数对应的阈值
thresholds[scores.index(max(scores))]
0.028163774952387383
col_k = X_train.columns[importances > 0.028163774952387383].to_list()
X_train_embedded = X_train[col_k]
X_train_embedded.head()
| ctrip_profits | lasthtlordergap | cityuvs | cityorders | lastpvgap | cr | sid | visitnum_oneyear | h | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1.347 | -1.0 | 3.787 | 0.387 | 2850.0 | 1.137405 | 3 | 1314.0 | 6 |
| 1 | 1.347 | -1.0 | 0.127 | 0.007 | 2850.0 | 1.137405 | 7 | 1314.0 | 13 |
| 2 | 0.767 | -1.0 | 18.973 | 3.600 | 7272.0 | 1.137405 | 457 | 348.0 | 12 |
| 3 | 15.433 | 1986.0 | 1.507 | 0.287 | 47.0 | 1.160000 | 430 | 20273.0 | 8 |
| 4 | 1.347 | -1.0 | 1.433 | 0.167 | 20.0 | 1.000000 | 85 | 83.0 | 13 |
X_test_embedded = X_test[col_k]
X_test_embedded.head()
| ctrip_profits | lasthtlordergap | cityuvs | cityorders | lastpvgap | cr | sid | visitnum_oneyear | h | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 3.940 | 7224.0 | 7.147 | 0.580000 | 539.0 | 1.150000 | 220 | 4542.0 | 4 |
| 1 | 1.347 | 40911.0 | 0.447 | 0.060000 | 3.0 | 1.137687 | 81 | 3156.0 | 3 |
| 2 | 0.887 | -1.0 | 4.313 | 0.460000 | 6532.0 | 1.000000 | 81 | 1026.0 | 17 |
| 3 | 1.347 | -1.0 | 0.460 | 0.053000 | 363.0 | 1.000000 | 27 | 349.0 | 22 |
| 4 | 1.540 | 82256.0 | 0.060 | 2.246314 | 41.0 | 1.170000 | 63 | 811.0 | 10 |
# 画出热力图,查看相关性
plt.figure(figsize=(10,8))
sns.heatmap(X_train_embedded.corr(), annot=True, linewidths=1)
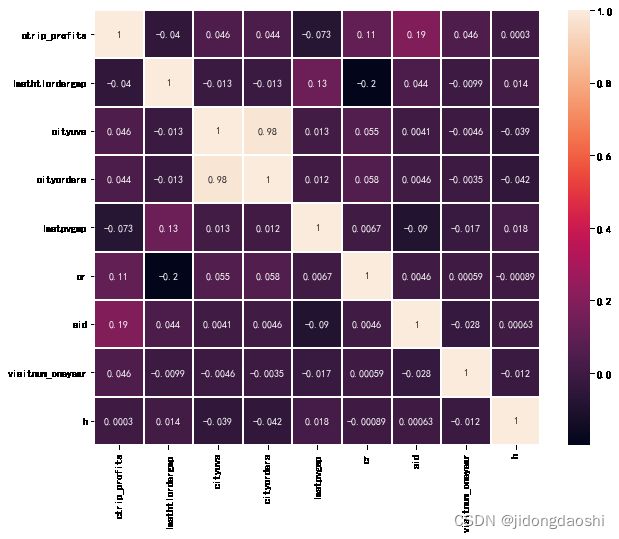
# 删除相关性高的特征
X_train_embedded.drop('cityuvs', axis=1, inplace=True)
X_test_embedded.drop('cityuvs', axis=1, inplace=True)
# 保存清洗之后的数据
X_train_embedded.to_csv('X_train_embedded.csv')
X_test_embedded.to_csv('X_test_embedded.csv')
y_train.to_csv('y_train.csv')
y_test.to_csv('y_test.csv')
# 读取数据
X_train_embedded = pd.read_csv('X_train_embedded.csv', index_col=0)
X_test_embedded = pd.read_csv('X_test_embedded.csv', index_col=0)
y_train = pd.read_csv('y_train.csv', index_col=0)
y_test = pd.read_csv('y_test.csv', index_col=0)
y_train = np.ravel(y_train)
y_train.shape
y_test = np.ravel(y_test)
y_test.shape
(172487,)
# 'lasthtlordergap':'一年内距离上次下单时长'
# 'cityorders':'昨日提交当前城市同入住日期的app订单数'
# 'lastpvgap':'一年内距上次访问时长'
# 'cr':'用户转化率'
# 'sid':'会话id,sid=1可认为是新访'
# 'visitnum_oneyear':'年访问次数'
# 'h':'访问时间点'
import scipy
# 重新合并数据
woe_data = pd.concat([X_train_embedded, pd.Series(y_train, name='label')], axis=1)
woe_data
| ctrip_profits | lasthtlordergap | cityorders | lastpvgap | cr | sid | visitnum_oneyear | h | label | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1.347 | -1.0 | 0.387 | 2850.0 | 1.137405 | 3 | 1314.0 | 6 | 0 |
| 1 | 1.347 | -1.0 | 0.007 | 2850.0 | 1.137405 | 7 | 1314.0 | 13 | 0 |
| 2 | 0.767 | -1.0 | 3.600 | 7272.0 | 1.137405 | 457 | 348.0 | 12 | 1 |
| 3 | 15.433 | 1986.0 | 0.287 | 47.0 | 1.160000 | 430 | 20273.0 | 8 | 1 |
| 4 | 1.347 | -1.0 | 0.167 | 20.0 | 1.000000 | 85 | 83.0 | 13 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 517453 | 1.347 | -1.0 | 0.113 | 4347.0 | 1.137405 | 8 | 278.0 | 21 | 0 |
| 517454 | 1.347 | 41045.0 | 0.520 | 2972.0 | 1.330000 | 25 | 1095.0 | 0 | 0 |
| 517455 | 1.347 | 113046.0 | 0.093 | 522.0 | 1.137405 | 120 | 6309.0 | 16 | 0 |
| 517456 | -0.067 | 266544.0 | 0.600 | 28378.0 | 1.000000 | 22 | 100.0 | 9 | 0 |
| 517457 | 1.347 | -1.0 | 0.420 | 2850.0 | 1.137405 | 5 | 1314.0 | 17 | 0 |
517458 rows × 9 columns
# 计算woe
def get_woe(num_bins):
columns = ['min', 'max', 'count_0', 'count_1']
df = pd.DataFrame(num_bins, columns=columns)
df['total'] = df['count_0'] + df['count_1']
df['percentage'] = df['total'] / df['total'].sum()
df['bad_rate'] = df['count_1'] / df['total']
df['good%'] = df['count_0'] / df['count_0'].sum()
df['bad%'] = df['count_1'] / df['count_1'].sum()
df['good-bad'] = df['good%'] - df['bad%']
df['woe'] = np.log(df['good%'] / df['bad%'])
return df
# 计算IV值,返回IV值
def get_iv(df):
iv = np.sum(df['good-bad'] * df['woe'])
return iv
# 返回详细矩阵
def get_bin(X, q):
df = woe_data.copy()
df['qcut'], updown = pd.qcut(df[X], retbins=True, q=q, duplicates='drop')
count_0 = df[df['label']==0].groupby('qcut').count()['label']
count_1 = df[df['label']==1].groupby('qcut').count()['label']
num_bins = [*zip(updown,updown[1:],count_0,count_1)]
woe_df = get_woe(num_bins)
return woe_df
# 作图,查看不同分箱方式
def get_graph(X, n=2, q=20):
df = woe_data.copy()
df['qcut'], updown = pd.qcut(df[X], retbins=True, q=q, duplicates='drop')
count_0 = df[df['label']==0].groupby('qcut').count()['label']
count_1 = df[df['label']==1].groupby('qcut').count()['label']
num_bins = [*zip(updown,updown[1:],count_0,count_1)]
IV = []
axisx = []
while len(num_bins) > n:
pvs = []
for i in range(len(num_bins)-1):
x1 = num_bins[i][2:]
x2 = num_bins[i+1][2:]
pv = scipy.stats.chi2_contingency([x1,x2])[1]
pvs.append(pv)
i = pvs.index(max(pvs))
num_bins[i:i+2] = [(num_bins[i][0], num_bins[i+1][1],
num_bins[i][2] + num_bins[i+1][2],
num_bins[i][3] + num_bins[i+1][3])]
woe_df = get_woe(num_bins)
axisx.append(len(num_bins))
IV.append(get_iv(woe_df))
plt.figure()
plt.plot(axisx, IV)
plt.xticks(axisx)
plt.xlabel("number of box")
plt.ylabel("IV")
plt.show()
col_woe = ['ctrip_profits', 'lasthtlordergap', 'cityorders',
'lastpvgap', 'cr', 'sid', 'visitnum_oneyear', 'h']
for i in col_woe:
print(i)
get_graph(i)
ctrip_profits

lasthtlordergap

cityorders
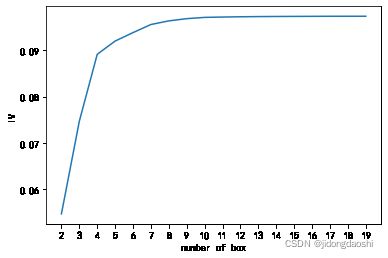
lastpvgap

cr

sid

visitnum_oneyear
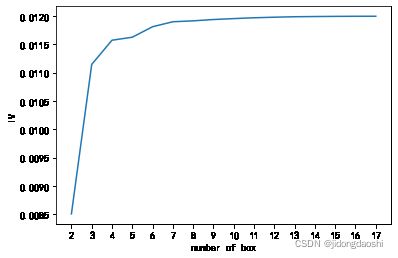
h
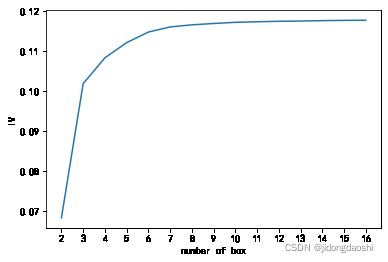
# 发现上次下单时长在2356-29219内的用户流失率比较高
get_bin('lasthtlordergap', 10)
| min | max | count_0 | count_1 | total | percentage | bad_rate | good% | bad% | good-bad | woe | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -1.0 | 2356.0 | 158912 | 48086 | 206998 | 0.400029 | 0.232302 | 0.423198 | 0.338741 | 0.084457 | 0.222603 |
| 1 | 2356.0 | 13291.0 | 30983 | 20754 | 51737 | 0.099983 | 0.401144 | 0.082511 | 0.146201 | -0.063691 | -0.572057 |
| 2 | 13291.0 | 29219.0 | 34175 | 17574 | 51749 | 0.100006 | 0.339601 | 0.091011 | 0.123800 | -0.032789 | -0.307683 |
| 3 | 29219.0 | 56455.0 | 35511 | 16229 | 51740 | 0.099989 | 0.313664 | 0.094569 | 0.114325 | -0.019756 | -0.189714 |
| 4 | 56455.0 | 110984.0 | 37245 | 14499 | 51744 | 0.099997 | 0.280206 | 0.099187 | 0.102138 | -0.002951 | -0.029318 |
| 5 | 110984.0 | 232020.0 | 39177 | 12572 | 51749 | 0.100006 | 0.242942 | 0.104332 | 0.088563 | 0.015769 | 0.163861 |
| 6 | 232020.0 | 527026.0 | 39500 | 12241 | 51741 | 0.099991 | 0.236582 | 0.105192 | 0.086232 | 0.018961 | 0.198753 |
# 发现用户转化率在1.12以下时用户留存较多
get_bin('cr',10)
| min | max | count_0 | count_1 | total | percentage | bad_rate | good% | bad% | good-bad | woe | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1.000000 | 1.120000 | 166695 | 42471 | 209166 | 0.404218 | 0.203049 | 0.443925 | 0.299186 | 0.144738 | 0.394588 |
| 1 | 1.120000 | 1.137405 | 135099 | 47248 | 182347 | 0.352390 | 0.259110 | 0.359781 | 0.332838 | 0.026944 | 0.077841 |
| 2 | 1.137405 | 1.170000 | 15752 | 7000 | 22752 | 0.043969 | 0.307665 | 0.041949 | 0.049311 | -0.007362 | -0.161699 |
| 3 | 1.170000 | 1.330000 | 37674 | 24461 | 62135 | 0.120077 | 0.393675 | 0.100329 | 0.172315 | -0.071986 | -0.540866 |
| 4 | 1.330000 | 11.000000 | 20283 | 20775 | 41058 | 0.079346 | 0.505992 | 0.054016 | 0.146349 | -0.092334 | -0.996724 |
# 发现客户留存结果随着订单数增加而逐渐降低,除了在1.4--2.25的区间中有了明显的回升
get_bin('cityorders',10)
| min | max | count_0 | count_1 | total | percentage | bad_rate | good% | bad% | good-bad | woe | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.007000 | 0.033000 | 44555 | 11516 | 56071 | 0.108359 | 0.205382 | 0.118654 | 0.081124 | 0.037530 | 0.380231 |
| 1 | 0.033000 | 0.093000 | 39744 | 10584 | 50328 | 0.097260 | 0.210300 | 0.105842 | 0.074559 | 0.031283 | 0.350359 |
| 2 | 0.093000 | 0.200000 | 40294 | 11095 | 51389 | 0.099310 | 0.215902 | 0.107307 | 0.078159 | 0.029148 | 0.316952 |
| 3 | 0.200000 | 0.380000 | 37656 | 11761 | 49417 | 0.095500 | 0.237995 | 0.100281 | 0.082850 | 0.017431 | 0.190947 |
| 4 | 0.380000 | 0.753000 | 37170 | 14675 | 51845 | 0.100192 | 0.283055 | 0.098987 | 0.103378 | -0.004391 | -0.043400 |
| 5 | 0.753000 | 1.400000 | 35492 | 16268 | 51760 | 0.100027 | 0.314297 | 0.094519 | 0.114600 | -0.020081 | -0.192649 |
| 6 | 1.400000 | 2.255565 | 49463 | 16530 | 65993 | 0.127533 | 0.250481 | 0.131725 | 0.116445 | 0.015279 | 0.123292 |
| 7 | 2.255565 | 3.260000 | 25531 | 11738 | 37269 | 0.072023 | 0.314953 | 0.067991 | 0.082688 | -0.014697 | -0.195694 |
| 8 | 3.260000 | 6.633000 | 32872 | 18901 | 51773 | 0.100053 | 0.365074 | 0.087541 | 0.133148 | -0.045607 | -0.419350 |
| 9 | 6.633000 | 14.507000 | 32726 | 18887 | 51613 | 0.099743 | 0.365935 | 0.087152 | 0.133049 | -0.045897 | -0.423060 |
# 发现在晚上七点之后访问的用户,流失率较低,白天访问的用户流失率较高
get_bin('h',10)
| min | max | count_0 | count_1 | total | percentage | bad_rate | good% | bad% | good-bad | woe | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.0 | 6.0 | 42287 | 15678 | 57965 | 0.112019 | 0.270474 | 0.112614 | 0.110443 | 0.002171 | 0.019465 |
| 1 | 6.0 | 10.0 | 46850 | 22957 | 69807 | 0.134904 | 0.328864 | 0.124766 | 0.161720 | -0.036954 | -0.259428 |
| 2 | 10.0 | 12.0 | 34400 | 16455 | 50855 | 0.098279 | 0.323567 | 0.091610 | 0.115917 | -0.024307 | -0.235329 |
| 3 | 12.0 | 13.0 | 19815 | 8752 | 28567 | 0.055206 | 0.306367 | 0.052769 | 0.061653 | -0.008884 | -0.155599 |
| 4 | 13.0 | 15.0 | 38660 | 18137 | 56797 | 0.109762 | 0.319330 | 0.102955 | 0.127766 | -0.024811 | -0.215905 |
| 5 | 15.0 | 17.0 | 42537 | 18293 | 60830 | 0.117555 | 0.300723 | 0.113280 | 0.128865 | -0.015585 | -0.128901 |
| 6 | 17.0 | 19.0 | 40305 | 16122 | 56427 | 0.109047 | 0.285714 | 0.107336 | 0.113571 | -0.006235 | -0.056466 |
| 7 | 19.0 | 21.0 | 49680 | 15527 | 65207 | 0.126014 | 0.238119 | 0.132303 | 0.109380 | 0.022923 | 0.190266 |
| 8 | 21.0 | 22.0 | 31405 | 6631 | 38036 | 0.073505 | 0.174335 | 0.083634 | 0.046712 | 0.036922 | 0.582455 |
| 9 | 22.0 | 23.0 | 29564 | 3403 | 32967 | 0.063710 | 0.103224 | 0.078732 | 0.023972 | 0.054759 | 1.189144 |
# 客户价值并非越高流失率越低,在1.147-1.347时流失率最低的区间
get_bin('ctrip_profits',10)
| min | max | count_0 | count_1 | total | percentage | bad_rate | good% | bad% | good-bad | woe | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -44.313 | 0.147 | 37921 | 13979 | 51900 | 0.100298 | 0.269345 | 0.100987 | 0.098475 | 0.002512 | 0.025192 |
| 1 | 0.147 | 0.500 | 37673 | 13923 | 51596 | 0.099711 | 0.269846 | 0.100327 | 0.098080 | 0.002246 | 0.022645 |
| 2 | 0.500 | 1.147 | 37713 | 14400 | 52113 | 0.100710 | 0.276323 | 0.100433 | 0.101441 | -0.001007 | -0.009980 |
| 3 | 1.147 | 1.347 | 150615 | 44404 | 195019 | 0.376879 | 0.227691 | 0.401102 | 0.312803 | 0.088299 | 0.248641 |
| 4 | 1.347 | 1.587 | 8296 | 3333 | 11629 | 0.022473 | 0.286611 | 0.022093 | 0.023479 | -0.001386 | -0.060856 |
| 5 | 1.587 | 3.220 | 36089 | 15701 | 51790 | 0.100085 | 0.303167 | 0.096108 | 0.110605 | -0.014497 | -0.140493 |
| 6 | 3.220 | 7.327 | 35310 | 16403 | 51713 | 0.099937 | 0.317193 | 0.094034 | 0.115551 | -0.021517 | -0.206054 |
| 7 | 7.327 | 600.820 | 31886 | 19812 | 51698 | 0.099908 | 0.383226 | 0.084915 | 0.139565 | -0.054650 | -0.496877 |
# 通过观察可以发现lastpvgap,sid,visitnum_oneyear的IV值过小,可以去掉这三个特征
X_train_woe = X_train_embedded[['ctrip_profits', 'lasthtlordergap', 'cityorders', 'cr', 'h']]
X_test_woe = X_test_embedded[['ctrip_profits', 'lasthtlordergap', 'cityorders', 'cr', 'h']]
# 最大深度学习曲线
scores = []
time0 = time()
for i in np.arange(5,21,1):
rfc = RFC(n_estimators=10, max_depth=i, random_state=42)
score = cross_val_score(rfc, X_train_embedded, y_train, cv=5, n_jobs=-1).mean()
scores.append(score)
print('花费时间:{}'.format(datetime.datetime.fromtimestamp(time()-time0).strftime('%M:%S:%f')))
print('最大分数为{},最大深度为{}'.format(max(scores), np.arange(5,21,1)[np.argmax(scores)]))
plt.figure(figsize=(10,8))
plt.plot(np.arange(5,21,1), scores)
plt.show()
花费时间:03:27:049065
最大分数为0.8891446300224614,最大深度为20

# 最小分割数学习曲线
scores = []
time0 = time()
for i in np.arange(2,10,1):
rfc = RFC(n_estimators=10, max_depth=20, min_samples_split=i, random_state=42)
score = cross_val_score(rfc, X_train_embedded, y_train, cv=5, n_jobs=-1).mean()
scores.append(score)
print('花费时间:{}'.format(datetime.datetime.fromtimestamp(time()-time0).strftime('%M:%S:%f')))
print('最大分数为{},最小分割数为{}'.format(max(scores), np.arange(2,10,1)[np.argmax(scores)]))
plt.figure(figsize=(10,8))
plt.plot(np.arange(2,10,1), scores)
plt.show()
花费时间:02:16:546873
最大分数为0.8891446300224614,最小分割数为2
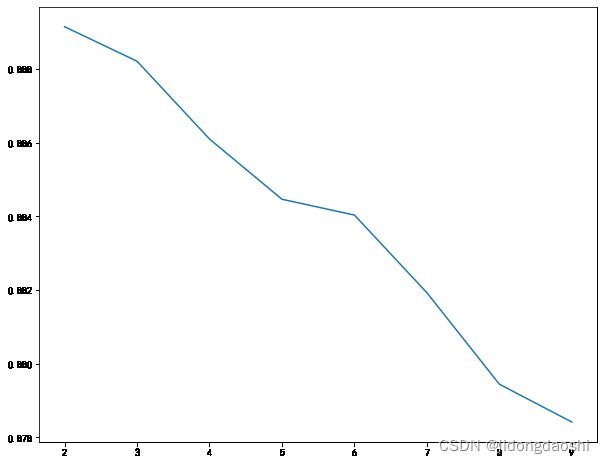
# 最小叶子节点样本数学习曲线
scores = []
time0 = time()
for i in np.arange(1,10,1):
rfc = RFC(n_estimators=10, max_depth=20, min_samples_split=2, min_samples_leaf=i, random_state=42)
score = cross_val_score(rfc, X_train_embedded, y_train, cv=5, n_jobs=-1).mean()
scores.append(score)
print('花费时间:{}'.format(datetime.datetime.fromtimestamp(time()-time0).strftime('%M:%S:%f')))
print('最大分数为{},小叶子节点样本数{}'.format(max(scores), np.arange(1,10,1)[np.argmax(scores)]))
plt.figure(figsize=(10,8))
plt.plot(np.arange(1,10,1), scores)
plt.show()
花费时间:02:13:264602
最大分数为0.8891446300224614,小叶子节点样本数1

# 树数量学习曲线
scores = []
time0 = time()
for i in np.arange(10,201,10):
rfc = RFC(n_estimators=i, max_depth=20, random_state=42)
score = cross_val_score(rfc, X_train_embedded, y_train, cv=3, n_jobs=-1).mean()
scores.append(score)
print('花费时间:{}'.format(datetime.datetime.fromtimestamp(time()-time0).strftime('%M:%S:%f')))
print('最大分数为{},树数量{}'.format(max(scores), np.arange(10,201,10)[np.argmax(scores)]))
plt.figure(figsize=(10,8))
plt.plot(np.arange(10,201,10), scores)
plt.show()
花费时间:00:33:316156
花费时间:01:39:789986
花费时间:03:21:423289
花费时间:05:40:185622
花费时间:08:30:948403
花费时间:11:56:105026
花费时间:15:51:769696
花费时间:20:36:914026
花费时间:25:38:212320
花费时间:31:10:214501
花费时间:37:27:759795
花费时间:44:10:525391
花费时间:51:28:059915
花费时间:59:16:547367
花费时间:07:41:280818
花费时间:16:38:253700
花费时间:26:07:070954
花费时间:36:06:570602
花费时间:48:40:747174
花费时间:00:14:880475
最大分数为0.8988864801364768,树数量100
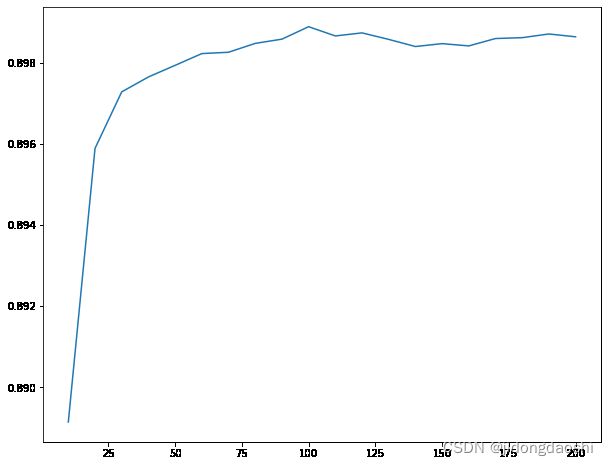
# 选出最佳模型参数
rfc = RFC(n_estimators=100, max_depth=20, random_state=42).fit(X_train_embedded, y_train)
# 查看训练集和测试集上的得分
print('训练集得分为{}'.format(rfc.score(X_train_embedded, y_train)))
print('测试集得分为{}'.format(rfc.score(X_train_embedded, y_test)))
训练集得分为0.9144162424776504
测试集得分为0.8858812548192038
# 查看特征重要性
rfc.feature_importances_
array([0.12193391, 0.12869867, 0.14163503, 0.13799971, 0.10331983,
0.12834216, 0.14547079, 0.09259991])
# 测试集预测概率
y_scores = rfc.predict_proba(X_train_embedded)
y_scores
array([[0.42810513, 0.57189487],
[0.90260411, 0.09739589],
[0.87430575, 0.12569425],
...,
[0.3633656 , 0.6366344 ],
[0.79112542, 0.20887458],
[0.14388709, 0.85611291]])
from sklearn.metrics import roc_curve, auc
fpr, tpr, thresholds = roc_curve(y_test, y_scores[:, 1])
roc_auc = auc(fpr, tpr)
roc_auc
0.9680887508287116
# 绘制roc曲线
def draw_roc(roc_auc, fpr, tpr):
plt.subplots(figsize=(7,5.5))
plt.plot(fpr, tpr, color='orange', label='roc curve(area={})'.format(roc_auc))
plt.plot([0,1], [0,1], color='blue', linestyle='--')
plt.xlabel('fpr')
plt.ylabel('tpr')
plt.xlim([0,1])
plt.ylim([0,1.05])
plt.title('ROC Curve')
plt.legend(loc=4)
plt.show()
draw_roc(roc_auc, fpr, tpr)
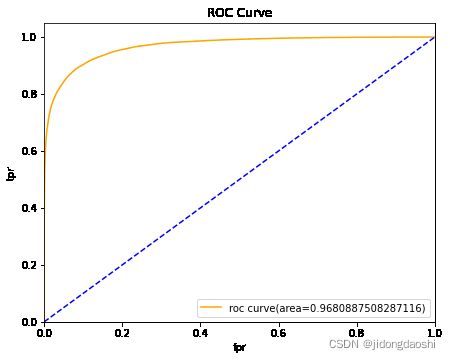
# RFM计算
rfm = df[['sampleid','ordernum_oneyear','avgprice','lasthtlordergap']]
rfm.head()
| sampleid | ordernum_oneyear | avgprice | lasthtlordergap | |
|---|---|---|---|---|
| 0 | 24636 | NaN | NaN | NaN |
| 1 | 24637 | NaN | NaN | NaN |
| 2 | 24641 | NaN | NaN | NaN |
| 3 | 24642 | NaN | NaN | NaN |
| 4 | 24644 | NaN | NaN | NaN |
# RFM模型重命名
rfm = rfm.dropna().reset_index(drop=True).rename(columns={'ordernum_oneyear':'F', 'avgprice':'M', 'lasthtlordergap':'R'})
rfm.head()
| sampleid | F | M | R | |
|---|---|---|---|---|
| 0 | 24650 | 21.0 | 363.0 | 10475.0 |
| 1 | 24653 | 7.0 | 307.0 | 18873.0 |
| 2 | 24655 | 1.0 | 343.0 | 32071.0 |
| 3 | 24658 | 33.0 | 1000.0 | 4616.0 |
| 4 | 24662 | 4.0 | 685.0 | 44830.0 |
# 通过计算得出R的单位是分钟,可以将其转换成天
rfm['R'] = round(rfm['R'] / 1440, 0)
rfm.head()
| sampleid | F | M | R | |
|---|---|---|---|---|
| 0 | 24650 | 21.0 | 363.0 | 7.0 |
| 1 | 24653 | 7.0 | 307.0 | 13.0 |
| 2 | 24655 | 1.0 | 343.0 | 22.0 |
| 3 | 24658 | 33.0 | 1000.0 | 3.0 |
| 4 | 24662 | 4.0 | 685.0 | 31.0 |
rfm.describe().T
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| sampleid | 426425.0 | 629380.138599 | 414760.183032 | 24650.0 | 313549.0 | 600907.0 | 887813.0 | 2238403.0 |
| F | 426425.0 | 12.137916 | 17.405419 | 1.0 | 3.0 | 6.0 | 14.0 | 711.0 |
| M | 426425.0 | 421.604962 | 286.987700 | 1.0 | 233.0 | 351.0 | 523.0 | 6383.0 |
| R | 426425.0 | 70.742163 | 84.844780 | 0.0 | 11.0 | 33.0 | 97.0 | 366.0 |
# 这里根据数据分布情况以及常规思路,对RFM进行划分
f_bins = [-1, 3, 5, 7, 10, 720]
m_bins = [-1, 200, 400, 600, 800, 7000]
r_bins = [-1, 3, 7, 30, 180, 370]
rfm['R_score'] = pd.cut(rfm['R'], bins=r_bins, labels=[5,4,3,2,1]).astype('int')
rfm['F_score'] = pd.cut(rfm['F'], bins=f_bins, labels=[1,2,3,4,5]).astype('int')
rfm['M_score'] = pd.cut(rfm['M'], bins=m_bins, labels=[1,2,3,4,5]).astype('int')
rfm
| sampleid | F | M | R | R_score | F_score | M_score | |
|---|---|---|---|---|---|---|---|
| 0 | 24650 | 21.0 | 363.0 | 7.0 | 4 | 5 | 2 |
| 1 | 24653 | 7.0 | 307.0 | 13.0 | 3 | 3 | 2 |
| 2 | 24655 | 1.0 | 343.0 | 22.0 | 3 | 1 | 2 |
| 3 | 24658 | 33.0 | 1000.0 | 3.0 | 5 | 5 | 5 |
| 4 | 24662 | 4.0 | 685.0 | 31.0 | 2 | 2 | 4 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 426420 | 2238388 | 2.0 | 226.0 | 119.0 | 2 | 1 | 2 |
| 426421 | 2238389 | 4.0 | 461.0 | 0.0 | 5 | 2 | 3 |
| 426422 | 2238396 | 5.0 | 193.0 | 44.0 | 2 | 2 | 1 |
| 426423 | 2238397 | 1.0 | 258.0 | 87.0 | 2 | 1 | 2 |
| 426424 | 2238403 | 3.0 | 256.0 | 52.0 | 2 | 1 | 2 |
426425 rows × 7 columns
# 大于平均分时记为1,否则记为0
rfm['R_level'] = (rfm['R_score'] > rfm['R_score'].mean()) * 1
rfm['F_level'] = (rfm['F_score'] > rfm['F_score'].mean()) * 1
rfm['M_level'] = (rfm['M_score'] > rfm['M_score'].mean()) * 1
rfm
| sampleid | F | M | R | R_score | F_score | M_score | R_level | F_level | M_level | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 24650 | 21.0 | 363.0 | 7.0 | 4 | 5 | 2 | 1 | 1 | 0 |
| 1 | 24653 | 7.0 | 307.0 | 13.0 | 3 | 3 | 2 | 1 | 1 | 0 |
| 2 | 24655 | 1.0 | 343.0 | 22.0 | 3 | 1 | 2 | 1 | 0 | 0 |
| 3 | 24658 | 33.0 | 1000.0 | 3.0 | 5 | 5 | 5 | 1 | 1 | 1 |
| 4 | 24662 | 4.0 | 685.0 | 31.0 | 2 | 2 | 4 | 0 | 0 | 1 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 426420 | 2238388 | 2.0 | 226.0 | 119.0 | 2 | 1 | 2 | 0 | 0 | 0 |
| 426421 | 2238389 | 4.0 | 461.0 | 0.0 | 5 | 2 | 3 | 1 | 0 | 1 |
| 426422 | 2238396 | 5.0 | 193.0 | 44.0 | 2 | 2 | 1 | 0 | 0 | 0 |
| 426423 | 2238397 | 1.0 | 258.0 | 87.0 | 2 | 1 | 2 | 0 | 0 | 0 |
| 426424 | 2238403 | 3.0 | 256.0 | 52.0 | 2 | 1 | 2 | 0 | 0 | 0 |
426425 rows × 10 columns
# 合并数据,并根据RFM标签来对用户进行划分
rfm['RFM'] = pd.concat([rfm['R_level'].astype('str') + rfm['F_level'].astype('str') + rfm['M_level'].astype('str')])
rfm['RFM'].replace(['111','101','011','001','110','100','010','000']
, ['重要价值用户','重要发展用户','重要保持用户','重要挽留用户','一般价值用户','一般发展用户','一般保持用户','一般挽留用户'], inplace=True)
rfm
| sampleid | F | M | R | R_score | F_score | M_score | R_level | F_level | M_level | RFM | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 24650 | 21.0 | 363.0 | 7.0 | 4 | 5 | 2 | 1 | 1 | 0 | 一般价值用户 |
| 1 | 24653 | 7.0 | 307.0 | 13.0 | 3 | 3 | 2 | 1 | 1 | 0 | 一般价值用户 |
| 2 | 24655 | 1.0 | 343.0 | 22.0 | 3 | 1 | 2 | 1 | 0 | 0 | 一般发展用户 |
| 3 | 24658 | 33.0 | 1000.0 | 3.0 | 5 | 5 | 5 | 1 | 1 | 1 | 重要价值用户 |
| 4 | 24662 | 4.0 | 685.0 | 31.0 | 2 | 2 | 4 | 0 | 0 | 1 | 重要挽留用户 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 426420 | 2238388 | 2.0 | 226.0 | 119.0 | 2 | 1 | 2 | 0 | 0 | 0 | 一般挽留用户 |
| 426421 | 2238389 | 4.0 | 461.0 | 0.0 | 5 | 2 | 3 | 1 | 0 | 1 | 重要发展用户 |
| 426422 | 2238396 | 5.0 | 193.0 | 44.0 | 2 | 2 | 1 | 0 | 0 | 0 | 一般挽留用户 |
| 426423 | 2238397 | 1.0 | 258.0 | 87.0 | 2 | 1 | 2 | 0 | 0 | 0 | 一般挽留用户 |
| 426424 | 2238403 | 3.0 | 256.0 | 52.0 | 2 | 1 | 2 | 0 | 0 | 0 | 一般挽留用户 |
426425 rows × 11 columns
# 统计各个类型用户的数量
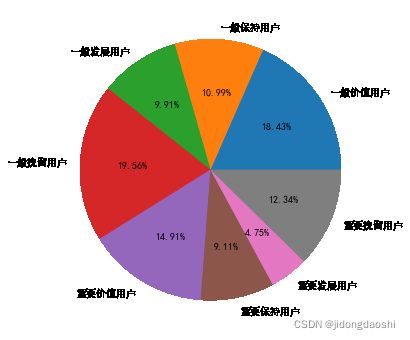
rfm_new = pd.DataFrame(rfm.groupby('RFM', as_index=False)['sampleid'].agg('count'))
rfm_new
| RFM | sampleid | |
|---|---|---|
| 0 | 一般价值用户 | 78592 |
| 1 | 一般保持用户 | 46850 |
| 2 | 一般发展用户 | 42275 |
| 3 | 一般挽留用户 | 83394 |
| 4 | 重要价值用户 | 63595 |
| 5 | 重要保持用户 | 38850 |
| 6 | 重要发展用户 | 20235 |
| 7 | 重要挽留用户 | 52634 |
# 绘制饼状图观察结果
plt.figure(figsize=(12,6))
plt.pie((rfm_new['sampleid'] / rfm_new['sampleid'].sum()).to_list(), labels=rfm_new['RFM'].to_list(), autopct='%0.2f%%')
[Text(0.9207056795449674, 0.6019144886556893, '一般价值用户'),
Text(0.07432600254562635, 1.0974860570164833, '一般保持用户'),
Text(-0.6110720650087508, 0.9146534487804336, '一般发展用户'),
Text(-1.0982775444537256, 0.061534017816936265, '一般挽留用户'),
Text(-0.5691837587192285, -0.9412915854347425, '重要价值用户'),
Text(0.23025758705583027, -1.0756307189752563, '重要保持用户'),
Text(0.6623554620643879, -0.8782284679247601, '重要发展用户'),
Text(1.0183302486279413, -0.4159368999371846, '重要挽留用户')],
[Text(0.5022030979336185, 0.3283169938121941, '18.43%'),
Text(0.04054145593397801, 0.5986287583726272, '10.99%'),
Text(-0.33331203545931853, 0.49890188115296374, '9.91%'),
Text(-0.5990604787929412, 0.03356400971832887, '19.56%'),
Text(-0.31046386839230644, -0.5134317738734958, '14.91%'),
Text(0.1255950474849983, -0.5867076648955943, '9.11%'),
Text(0.3612847974896661, -0.47903370977714177, '4.75%'),
Text(0.5554528628879679, -0.22687467269300973, '12.34%')])