【DenseFusion代码详解】linemod数据集预处理过程
DenseFusion系列代码全讲解目录:【DenseFusion系列目录】代码全讲解+可视化+计算评估指标_Panpanpan!的博客-CSDN博客
这些内容均为个人学习记录,欢迎大家提出错误一起讨论一起学习!
这里分析linemod数据集预处理的代码,位置在datasets/linemod/dataset.py
我们一行一行的分析。
import torch.utils.data as data
class PoseDataset(data.Dataset):
def __init__(self, mode, num, add_noise, root, noise_trans, refine):
self.objlist = [1, 2, 4, 5, 6, 8, 9, 10, 11, 12, 13, 14, 15]
self.mode = mode #mode: train test eval这里首先定义了PoseDataset类,继承了torch.utils.data.Dataset这个抽象类,用于创建自定义数据集。当我们需要用到自定义的数据集时,可以去继承Dataset类并覆盖__len__()和__getitem__()方法,其中__len__()返回数据集的样本个数,getitem(index)返回训练集的第index个样本。
首先__init__()用于初始化,参数含义如下:
mode:模式,共三种,train、test、eval
num:输入的点云个数(这里linemod默认500个)
add_noise:是否加入噪声(实验中将train加入噪声,test和eval不加入)
root:数据集的根目录
noise_trans:噪声超参数(默认0.03,这个参数可以在后续eval的时候自己设置)
refine:refine过程是否开始
self.objlist记录了类别编码,linemod数据集一共13个类别, 1-15编号(没有3、7)。
self.list_rgb = [] #存放rgb图路径
self.list_depth = [] #存放深度图路径
self.list_label = [] #存放语义分割mask图路径
self.list_obj = [] #存放读取的类别编号
self.list_rank = [] #存放读取的图片编号
self.meta = {} #存放每个类别的元数据信息
self.pt = {} #存放每个类别的点云信息
self.root = root #数据集根目录
self.noise_trans = noise_trans #是否加入噪声
self.refine = refine #是否开始了refine过程接下来定义的内容如注释所示,下面通过循环分别读取不同的类别。
item_count = 0 #记录数目
for item in self.objlist:
if self.mode == 'train':
input_file = open('{0}/data/{1}/train.txt'.format(self.root, '%02d' % item))
else:
input_file = open('{0}/data/{1}/test.txt'.format(self.root, '%02d' % item))根据mode分别读取txt文件,该文件位于data/类别/train.txt或test.txt,里面的内容是:

记录了训练数据集和测试数据集的编号,读取文件之后,进入循环:
while 1:
item_count += 1
input_line = input_file.readline() #按行读取
if self.mode == 'test' and item_count % 10 != 0:
continue
if not input_line: #读完了就退出
break
if input_line[-1:] == '\n':
input_line = input_line[:-1]
#加入该RGB路径
self.list_rgb.append('{0}/data/{1}/rgb/{2}.png'.format(self.root, '%02d' % item, input_line))
#加入该深度图路径
self.list_depth.append('{0}/data/{1}/depth/{2}.png'.format(self.root, '%02d' % item, input_line))
#如果是eval模式,就用语义分割之后的标签
if self.mode == 'eval':
self.list_label.append('{0}/segnet_results/{1}_label/{2}_label.png'.format(self.root, '%02d' % item, input_line))
else: #其他的用标准mask
self.list_label.append('{0}/data/{1}/mask/{2}.png'.format(self.root, '%02d' % item, input_line))
#加入该类别号和图片编号
self.list_obj.append(item)
self.list_rank.append(int(input_line))对该txt文件按行读取,将对应的RGB图、深度图、mask图的路径以及类别和编号加入列表中。其中,如果是eval模式,就使用语义分割之后的标签(考虑到实际应用),如果是训练和测试,用的是标准的标签(这样为了使得训练过程更加准确)。结束while循环之后:
#元数据信息
meta_file = open('{0}/data/{1}/gt.yml'.format(self.root, '%02d' % item), 'r')
#加载元数据信息
self.meta[item] = yaml.load(meta_file,Loader=yaml.FullLoader)
#加载三维mesh模型数据
self.pt[item] = ply_vtx('{0}/models/obj_{1}.ply'.format(self.root, '%02d' % item))
#输出该类别加载完毕
print("Object {0} buffer loaded".format(item))加载该类别的元数据信息和三维mesh模型数据,元数据定义了该物体的真实姿态以及边界框,然后结束for循环。
self.length = len(self.list_rgb) #所有物体的个数
#摄像头的中心坐标
self.cam_cx = 325.26110
self.cam_cy = 242.04899
#摄像头的x和y轴长度
self.cam_fx = 572.41140
self.cam_fy = 573.57043
#xmap(480,640) ymap(480,639)
self.xmap = np.array([[j for i in range(640)] for j in range(480)])
self.ymap = np.array([[i for i in range(640)] for j in range(480)])这里定义了摄像头的中心坐标和x轴y轴长度,xmap和ymap都是480*640的矩阵,xmap第一行全为0(640列0),第二行全为1(640列1),...,第480行全为479(640列479);ymap第一列全为0(480行0),第二列全为1(480行1),...,第640列全为639(480行639),直观输出如下:


然后定义了点云个数、噪声、图像预处理等,记录对称物体的序号7、8,也就是第10类(鸡蛋盒)和第11类(胶水):
self.num = num #输入的点云个数,500
self.add_noise = add_noise #噪声
self.trancolor = transforms.ColorJitter(0.2, 0.2, 0.2, 0.05) #改变图像的亮度、对比度、饱和度、色相偏移
self.norm = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])#归一化
#边界列表,可以想象把一个图片切割成了多个坐标
self.border_list = [-1, 40, 80, 120, 160, 200, 240, 280, 320, 360, 400, 440, 480, 520, 560, 600, 640, 680]
self.num_pt_mesh_large = 500 #点云最大数
self.num_pt_mesh_small = 500 #点云最小数
self.symmetry_obj_idx = [7, 8] #标记对称物体的序号以上就是初始化部分。下面是__getitem__的定义,在train.py中的代码段
for i, data in enumerate(dataloader, 0):
这里就会调用__getitem__的部分,首先读取图片信息:
def __getitem__(self, index):
img = Image.open(self.list_rgb[index]) #读取图片
ori_img = np.array(img) #转换成矩阵,但后面没用到因为后面也转换了的
depth = np.array(Image.open(self.list_depth[index])) #读取深度数据 numpy.ndarray(480, 640)
label = np.array(Image.open(self.list_label[index])) #读取标签
obj = self.list_obj[index] #读取类别编号
rank = self.list_rank[index] #读取图片编号 然后读取元数据信息:
if obj == 2:
for i in range(0, len(self.meta[obj][rank])):
if self.meta[obj][rank][i]['obj_id'] == 2:
meta = self.meta[obj][rank][i]
break
else:
meta = self.meta[obj][rank][0]这里的self.meta是初始化过程中读取的所有元数据,它是一个字典,结构如下:
{ 物体类别 (比如1):
{ 图像编号 (比如0004,取int为4):
[
{ 'cam_R_m2c': [ 旋转矩阵,9个数的列表 ] ,
'cam_t_m2c': [ 平移矩阵,3个数的列表 ] ,
'obj_bb': [ 标准的bounding box,4个数的列表 ] ,
'obj_id': 物体类别号
} ] } }
这里将物体2和其他类别分开处理,因为在 \Linemod_preprocessed\data\02\目录下面,除了mask文件夹,还有一个mask_all文件夹,它里面除了有物体2的mask,还有其他物体的mask,因此物体2的元数据中记录了全部物体的信息,所以需要找到 self.meta[obj][rank][i]['obj_id'] == 2 的元数据。
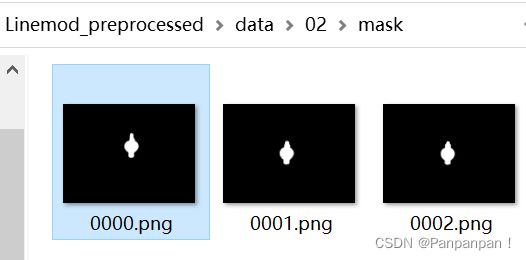
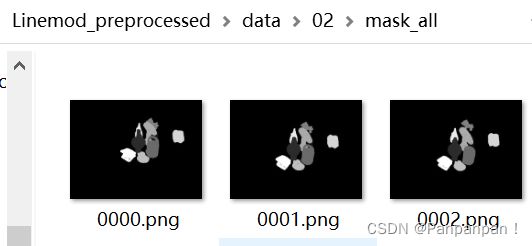
然后是对mask的处理:
mask_depth = ma.getmaskarray(ma.masked_not_equal(depth, 0)) #掩码操作 numpy.ndarray(480, 640)
if self.mode == 'eval':
mask_label = ma.getmaskarray(ma.masked_equal(label, np.array(255)))
else:
mask_label = ma.getmaskarray(ma.masked_equal(label, np.array([255, 255, 255])))[:, :, 0]
mask = mask_label * mask_depth #取label和depth都为True的像素作为mask这里先看depth里面是什么,是指从图像采集器到场景中各点的距离(深度),首先ma.masked_not_equal(depth, 0) 使用numpy.ma模块对depth进行掩码操作,masked_not_equal表示对depth中不等于0的值赋予掩码True,等于0的值为False,然后使用 ma.getmaskarray 获取掩码数组,即mask_depth,该数组大小为(480, 640),值为True或者False。
然后看看label里面是什么,它表示物体的mask标签,读取的mask图。如果是eval模式,就读取分割之后的mask,大小为(480, 640);如果是其他模式,就读取标准的mask(/data/01/mask/文件夹),大小为(480, 640, 3)。里面的值为0或者255,255的像素就为该物体的标签。这里为了更直观地看,我将一部分数据输出到excel(迷惑操作但很直观)然后截取了值为255的像素(下图右),跟mask图(下图左)的形状一样:
|
|
|


最后取label和depth都为True的像素作为mask。然后对img进行处理:
if self.add_noise:
img = self.trancolor(img) #加入噪声
img = np.array(img)[:, :, :3]
img = np.transpose(img, (2, 0, 1))首先,如果需要加入噪声,则将img进行trancolor操作,这个在前面初始化的时候有定义,改变图像的亮度、对比度、饱和度、色相偏移。然后将img转换成数组类型,取前三个通道(r,g,b),再交换通道数,将大小(480, 640, 3)转换成(3, 480, 640)。
下面选取image_masked,首先初始化为img:
img_masked = img
if self.mode == 'eval':
rmin, rmax, cmin, cmax = get_bbox(mask_to_bbox(mask_label))
else:
rmin, rmax, cmin, cmax = get_bbox(meta['obj_bb'])
img_masked = img_masked[:, rmin:rmax, cmin:cmax]这里就是计算物体所在区域的两个角点坐标 (rmin,cmin) 和 (rmax,cmax),如果是eval模式,则使用mask_label,如果是其他模式则用元数据里标准的bounding box,对于eval模式用到了mask_to_bbox()函数:
def mask_to_bbox(mask):
mask = mask.astype(np.uint8)
_, contours, _ = cv2.findContours(mask, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
x = 0
y = 0
w = 0
h = 0
for contour in contours:
tmp_x, tmp_y, tmp_w, tmp_h = cv2.boundingRect(contour)
if tmp_w * tmp_h > w * h:
x = tmp_x
y = tmp_y
w = tmp_w
h = tmp_h
return [x, y, w, h]顾名思义,就是根据mask计算bounding box,首先用cv2.findContours找到mask的轮廓,用新版本的OpenCV可能会报错,因为新版的这个函数是两个返回值,如果报错安装旧版的,或者去掉一个返回值就行。cv2.boundingRect就是根据轮廓找矩形边框,用最小的矩形把轮廓包起来,返回的是左上角的坐标以及宽和高。然后用到get_bbox()函数,返回rmin, rmax, cmin, cmax,这里不细讲。最后,用得到的边界框,裁剪image_masked,得到物体所在区域。
target_r = np.resize(np.array(meta['cam_R_m2c']), (3, 3))
target_t = np.array(meta['cam_t_m2c'])
add_t = np.array([random.uniform(-self.noise_trans, self.noise_trans) for i in range(3)])
这三行,第一行获取元数据中的真实旋转R,转换成数组类,然后resize成3*3的矩阵。第二行获得真实平移t,转换成数组类。第三行定义噪声,从[-noise_trans, noise_trans]范围内随机生成三个数值,分别给xyz三个坐标加噪声,也就是平移噪声。
接下来就是随机选取500个点云的过程。
choose = mask[rmin:rmax, cmin:cmax].flatten().nonzero()[0]
if len(choose) == 0:
cc = torch.LongTensor([0])
return(cc, cc, cc, cc, cc, cc)
if len(choose) > self.num:
c_mask = np.zeros(len(choose), dtype=int)
c_mask[:self.num] = 1
np.random.shuffle(c_mask)
choose = choose[c_mask.nonzero()]
else:
choose = np.pad(choose, (0, self.num - len(choose)), 'wrap')首先,mask表示label和depth都为True的像素,选取物体所在区域的mask,flatten()表示展开,也就是第一行后接第二行等等,再取mask不为0的部分作为choose,表示图片上该物体所在区域且具有深度值的像素索引。然后,如果索引个数为0,则返回0值;如果大于500,则随机选取其中500个索引作为新的choose(这种情况占大多数);如果大于0小于500,则用wrap模式填充,这段的实际效果为,如果[1,2,3]填充到10个长度,则为[1,2,3,1,2,3,1,2,3,1]。最终,要么直接返回0值,要么返回500长度的choose。
depth_masked = depth[rmin:rmax, cmin:cmax].flatten()[choose][:, np.newaxis].astype(np.float32)
xmap_masked = self.xmap[rmin:rmax, cmin:cmax].flatten()[choose][:, np.newaxis].astype(np.float32)
ymap_masked = self.ymap[rmin:rmax, cmin:cmax].flatten()[choose][:, np.newaxis].astype(np.float32)
choose = np.array([choose])接着,根据得到的choose,选取对应的depth_masked(也就是对应像素的深度值),对应的xmap_masked(对应像素的x坐标),对应的ymap_masked(对应像素的y坐标),然后把choose转换成数组形式且每一个值为一个列表。
下面开始将depth转换成点云数据:
cam_scale = 1.0
pt2 = depth_masked / cam_scale # z轴值
pt0 = (ymap_masked - self.cam_cx) * pt2 / self.cam_fx # x轴值
pt1 = (xmap_masked - self.cam_cy) * pt2 / self.cam_fy # y轴值
cloud = np.concatenate((pt0, pt1, pt2), axis=1) # 拼接
cloud = cloud / 1000.0深度转换成对应点云的公式如下:

分解计算三个坐标的值之后拼接起来组成点云cloud(除以1000我目前不知道为什么,如果大家有知道的欢迎私信我)。以上过程为像素坐标系 --> 相机坐标系。cloud为相机坐标系下的点。
if self.add_noise:
cloud = np.add(cloud, add_t)如果加入噪声,则为每个点的三个坐标都添加add_t。
model_points = self.pt[obj] / 1000.0 #物体第一帧的模型点
dellist = [j for j in range(0, len(model_points))]
dellist = random.sample(dellist, len(model_points) - self.num_pt_mesh_small)
model_points = np.delete(model_points, dellist, axis=0)model_points获取该物体的真实点云,是第一帧的点云,也就是/0000.png对应的点云,下面三行随机删除点云,只留下num_pt_mesh_small个点。
target = np.dot(model_points, target_r.T) #相机坐标系下的真实模型点
if self.add_noise:
target = np.add(target, target_t / 1000.0 + add_t)
out_t = target_t / 1000.0 + add_t
else:
target = np.add(target, target_t / 1000.0)
out_t = target_t / 1000.0target是由model_points经过标准姿态[R|t](target_r和target_t)转换后相机坐标系下的点,也就是说这两者是一样的点只不过坐标系不同。如果加入噪声,则加上平移和add_t,如果不加,就直接加上平移。
return torch.from_numpy(cloud.astype(np.float32)), \
torch.LongTensor(choose.astype(np.int32)), \
self.norm(torch.from_numpy(img_masked.astype(np.float32))), \
torch.from_numpy(target.astype(np.float32)), \
torch.from_numpy(model_points.astype(np.float32)), \
torch.LongTensor([self.objlist.index(obj)])
#str(obj)+'-'+str(rank)最后,返回点云、选取的点云索引、物体所在图像区域、目标点云、物体第一帧点云、物体类别,并转换成tensor形式。
def __len__(self):
return self.length
def get_sym_list(self):
return self.symmetry_obj_idx
def get_num_points_mesh(self):
if self.refine:
return self.num_pt_mesh_large
else:
return self.num_pt_mesh_small接着就是定义该类的属性,长度、获取对称物体编号、获取mesh点的个数,这些信息都是在初始化的时候定义过的。
总结
该部分是为了获取LineMOD数据集中的数据进行训练或测试。读取某个物体的RGB图像、depth图像、mask标签、元数据信息。主要过程为:
- 根据mask求bounding box;
- 根据bounding box获取目标物体所在区域的RGB图像、depth图像;
- 对depth图像随机选取500个像素;
- 将depth转换成点云;
- 获取模型真实点云和目标点云;
- 返回深度图转换后的点云、随机选取的索引、物体所在图像区域、目标点云、物体第一帧点云、物体类别。