单轨铁路列车重新调度的强化学习方法
1. 文章信息
《Reinforcement learning approach for train rescheduling on a single-track railway》是2016年发表在Transportation Research Part B上的一篇文章。
2. 摘要
本文研究内容是如何对实际运营前进行长时间的规划,从而实现最优的铁路网基础设施和车辆利用率。最初的列车时刻表考虑了可能出现的较小干扰,这些干扰可以在列车时刻表内得到补偿。更大的干扰,如事故、车辆故障、乘客登机时间延长和速度限制的改变,会导致列车延误,需要重新安排列车时刻表。本文提出了一种基于强化学习(即q学习)的列车调度方法。本文提出了列车重新调度的q学习原则,包括学习主体及其行为、环境及其状态和奖励。本文首先将所提出的方法应用于一个包含三列列车的单车道轨道的简单重调度问题。对该方法的评价是在斯洛文尼亚一个真实的铁路网上进行的大量实验中进行的。实证结果表明,Q-learning导致的重调度解决方案至少与不依赖学习代理的几种基本重调度方法的解决方案相当,而且往往更好。在合理的计算时间内学习解,这是实时应用的一个关键因素。
3. 引言
铁路系统的可靠性通常是通过列车正点率来评估的,它指的是列车时刻表中规定的列车在最终目的地的实际到达时间和预期到达时间之间的差值。准时是用户在选择交通方式时考虑的最重要的特征之一。
在铁路交通中,由于列车加/减速曲线的变化而造成的短暂延误,其驾驶模式和速度曲线是可以理解的,不可避免。因此,运行时间补充和缓冲时间被引入到时间表中。这些补充只能弥补小的中断,例如由于天气条件而导致的速度变化,但不能弥补较大的延误。中断和意外事件,如事故、车辆故障、基础设施故障、乘客登机导致的长时间停车和改变速度限制,会导致铁路交通更大的延误,需要更详细的交通管理和时间表重新安排。动态列车交通管理是保证列车准点运行的必要条件并尽量减少延误的后果。由控制中心调度人员执行的重调度动作的反应集必须是可行和有效的。列车改期是一个实时过程,调度员只有几分钟的时间对延误作出反应。因此,他们无法检查所有可行的解决方案,通过经验和直觉做出决定找到最优的一个方案。
本文提出了一种基于强化学习(Q-learning)的列车调度问题求解方法。由以往的研究可以发现强化学习已经被有效地应用于交通工程中。
4. 强化学习原则
在解决列车改期问题时,需要考虑的因素很多:所有列车的位置和速度、轨道段的长度、车站的布局或基础设施的容量。由于众多的环境因素对最优解有很强的影响,监督学习方法,即agent从重新调度问题的良好解决方案的例子中学习,是不可行的。另一方面,强化学习结合了动态规划和监督学习的原理,非常成功地解决了这两门学科单独无法解决的问题,特别适合解决列车改期问题。
图1描述了强化学习的一般设置,其中主动学习代理与被动环境解耦。代理通过观察环境的当前状态并决定其行动,主动与环境进行交互。在执行该操作之后,环境将其状态更改为st+1,并向代理发送强化反馈rt+1。

在列车改轨的特殊情况下,agent对应于对列车运行和轨道信号做出决策的调度员,而环境则是包括所有轨道、列车和相应的时刻表在内的铁路系统。环境是被动的,因为所有关于改变其状态的行为的决定都来自代理,即调度程序。环境发送给agent的强化信号与当前列车延迟成反比。强化学习方法利用强化信号学习最优代理策略或决策函数,在给定的可用操作集和当前系统状态下,帮助代理决定最优操作
Q-learning强化学习方法将代理决策策略形式化为效用函数Q (st, at)。它的值对应于在当前观察到的环境状态st中代理行为at的预期效用。行动的效用指的是它改善环境当前状态的潜力,也就是说,它告诉我们行动在给定状态下有多好。当面临状态t的决策时,agent选择效用函数Q (st, at)的最大值为at的行为。在许多动作具有相同效用函数(最大值)值的情况下,代理随机选择其中之一。下式描述了学习过程,即在每次训练迭代中,给定所获得的奖励,更新效用函数Q的过程
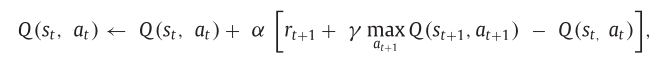
5. 算法设计
通过系统地解释特定设计选择背后的基本原理,介绍了我们用Q-learning训练重新调度的方法。五个基本组件:环境、状态、代理、行动,以及奖励反馈。文中考虑了铁路网络的微观视角,其中列车延误是主要的扰动源。
环境与仿真:影响铁路运营的主要因素有三个。第一个要素是铁路基础设施,第二个元素包括火车,第三个要素规定了铁路运营的安全原则。研究的目的是由调度员找到一个可行的火车时间表修订(在合理的时间框架内)为了检测到延误。第一个假设信号系统确保运输过程的安全控制和交通管制,以预防事故。信号系统采用不同的信号颜色或两种颜色和/或闪烁的灯的组合区分一个区域的两种状态——被占用或被占用,红色表示“停止”(表示区块部分目前被占用),绿色表示“清除”(表示区块部分是空闲的)。第二个假设列车被假设为一个点物体,所以它每次不会占用超过一个块段,第三个假设是车站,使用一些与车站(路口)容量相对应的平行街区部分来建模每个车站(或路口)。第四假设时间是离散的,以匹配列车时刻表的时间分辨率。第五个假设是关于安全原则的。以及防死锁的情况,仿真器和Q-learning算法都是在Microsoft Access和visual Basic for application环境下实现的。环境模拟器的这些基本对象可用于Q-learning算法,通过环境状态进行列车重调度,Q-learning算法通过设置信号在每个模拟步骤中采取行动。
状态:在列车重新调度问题中,考虑三个这样的属性(即相应的参数):列车当前位置、当前基础设施(区段)可用性和时间。
代理和动作集:在探索阶段,agent采取随机行动的概率较高,而在开发阶段,agent的行为遵循效用函数Q的值。对于基础结构中的每个信号元素,有两种可能的操作:将其设置为红色(»Stop«)或绿色(»Go«)颜色。因此,候选动作的数量取决于信号元素的数量| E |,它等于2^| E |,但是许多这些动作在给定时刻都不适用,动作数量常比上限2^ | T |小得多。
奖励函数:列车重新调度的具体奖励函数:rt+1 =−延迟。火车的总延误时间越长,奖励就越小。
6. 实验环境
在斯洛文尼亚铁路基础设施上用一个简单的人工例子和一个复杂的例子上所提出的方法来经验评估。简单的示例旨在说明方法的实用性,而真实的示例旨在评估其在真实环境中的可用性。
图2所示为铁路基础设施布局示例,其中一条轨道包含三个站点A、B、C,其中B站距A站8.8公里,C站距B站5.8公里。A站与B站之间的轨道线被划分为三个区块段(注意它们之间界限处的信号元素),B站与C站之间的轨道线被划分为两个区块段。每个车站可停靠三列火车。

图3描述了我们在实验中使用的三列火车的初始时刻表。铁路布局如图2所示,而三列列车有两种不同的恒定速度:第一列(1,70公里/小时)比其他两列(2和3,100公里/小时)慢。

我们使用α = 0.8, γ = 0.2的参数设置,以及50个训练片段,其中ε = 0,5 (1+ e (10 * (n−0))。4 * 50) 50),其中n表示当前训练集的次数。图4所示为所选的探测函数,保证了训练早期的探测概率高。为了避免局部最优,我们逐渐降低ɛ的值,在整个实验中留下一定的探索空间,直到最终的值0,对应的是对学到的策略的纯粹利用。
每个q学习实验都是一个随机过程,在探索阶段,代理将采取随机行动。为了正确地评估q学习的性能,我们在每个q学习实验中使用不同的随机生成器种子进行10次运行。
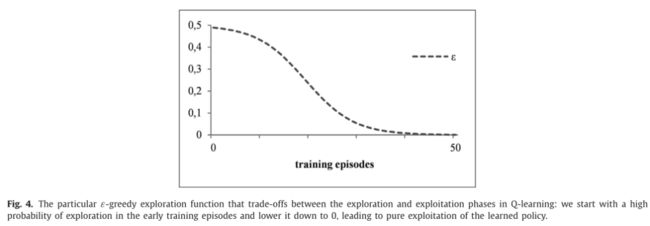
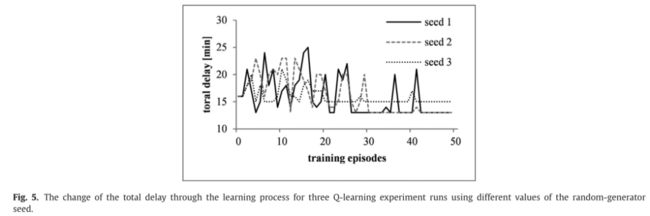
图5描述了使用随机种子的三个不同值进行三次q学习实验的学习曲线。尽管代理测试了不同的列车发车点,因此在训练片段中经历了不同的延迟,但它仍然学会了两个随机种子值的最优策略,以及第三个种子值的接近最优策略。
在前两次运行中获得的总最终延迟值为13分钟,在第三次运行中为15分钟。
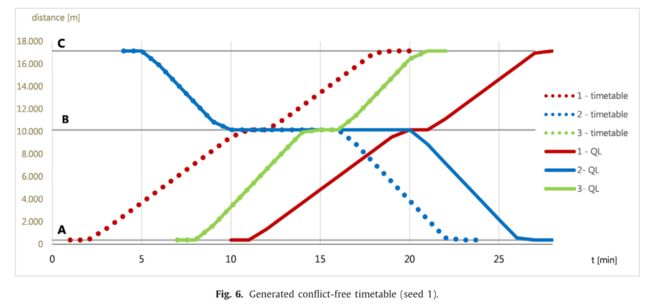
我们可以得出结论,提出的列车重调度q学习算法是高效和有效的,因为agent学习了最优策略,并提出了如图6所示的可行和最优的重调度时刻表。
复杂的现实案例:评估了q学习Q-learning在斯洛文尼亚真实世界铁路轨道的大量列车重新调度任务上的性能,该网络包括23个街区路段、14个车站和26列火车。为了评估Q-learning在不同设置下的性能,我们在100个不同的初始延迟场景下进行了实验,前50种情况是3列火车晚点的情况,后50种情况是5列火车晚点的情况。图10描绘了S3_08延迟场景的两条学习曲线:标记为“QL_avg”的实线描绘了使用不同随机种子值进行10次学习得到的10条学习曲线的平均值,标记为“QL_stDev”的虚线对应标准差,标记为“FIFO”的平虚线对应FIFO策略部署得到的总延迟。这两条学习曲线都表明,随着训练次数的增加,重新调度策略得到了稳定的改善。
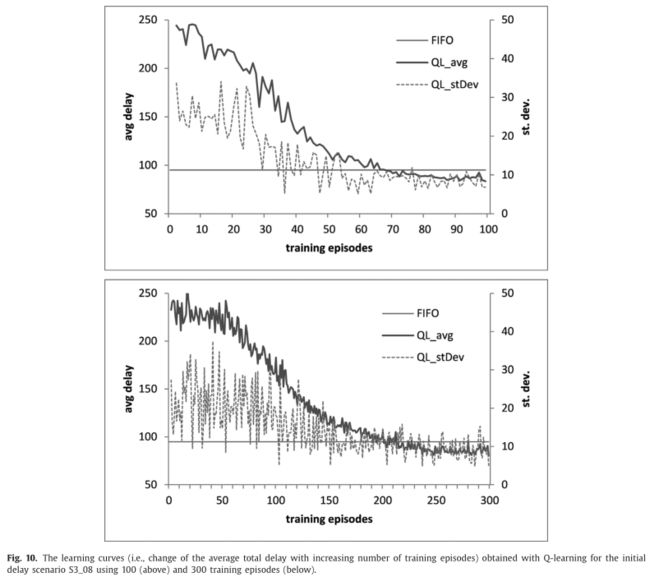
图11中的箱线图比较了随机漫步、FIFO和Q-learning三种方法在50个S3和50个S5延迟场景上的平均性能,结果表明q -学习方法明显优于随机行走方法;与FIFO方法相比,Q-learning的平均性能提升较小,且在统计上不显著,QL得到的中值延迟略好于FIFO方法。

但是,FIFO方法很容易出现死锁,而QL在所有场景中都避免死锁。表1对得到的实证结果进行了进一步的比较分析,结果表明,在超过一半的初始延迟场景中,Q-learning方法显著优于FIFO和随机漫步方法(平均)。
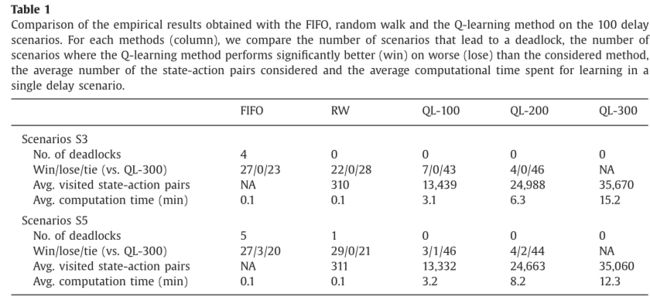
仅仅在三种延迟情况下。与Q-learning的10次重新运行所获得的最小总延迟的比较表明,它总是小于或等于FIFO所获得的延迟。就死锁的鲁棒性而言,Q-learning明显优于先进先出和随机游走。
7. 结论
Q-learning算法是一种无模型方法,代理通过动作和环境反馈进行学习。
因此,所提方法的主要优点是算法对不同铁路布局、列车数量、变化的奖励函数等的适应性。
第二个优点是算法中定义的约束的性质,它可以定义现实世界铁路交通管理和重新调度中存在的任何数量和类型的限制。可以根据需要更改和增加限制,以满足新的要求,例如修改立法。
第三个优点是奖励函数的定义,它可以很容易地改变,算法会根据新的目标找到不同的最优解(例如,不同类型列车的优先级或延误成本的变化,不同的乘客数量)。最后一个但仍然非常重要的优点是学习代理不需要任何预定义的背景知识。文中建议引入与安全相关的背景知识(例如,只有一辆列车可以占用阻塞段,防止死锁),以加快学习过程,尽管代理可以从环境反馈中了解到这种行为是不希望的。对该方法的评价表明,其性能明显优于不利用环境奖励信号随时间改进策略的随机漫步方法。提出的方法也优于标准的先进先出方法的列车重新调度:虽然总延迟的改善是适度的,但对死锁的鲁棒性的改善是明显的,与该方法在现实环境中的适用性非常相关。
最后,本文将重点放在在缺乏初始知识的情况下进行学习,并从头开始对每个扰动进行重新训练。或者,可以重用针对某一干扰学习到的策略,并在学习针对其他干扰的策略时评估其效用。评估重用学到的策略是否以及在多大程度上可以加速学习过程超出了本文使用的评估框架,未来可以进一步研究。