多模态的研究现状与应用场景的调查研究
一、多模态领域的研究现状
1. 多模态表示学习:主要研究如何将多个模态数据所蕴含的语义信息数值化为实值向量。
应用场景:智能音箱;数字座舱;传感器智能等。
算法示例:(a)联合表示(b)协同表示
(a)联合表示:如下图所示,将多模态数据映射到同一个表示空间中。

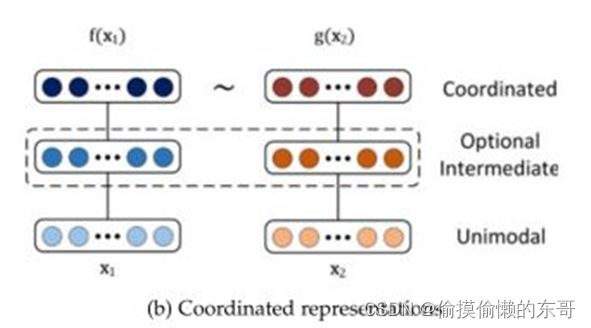
(b)协同表示:如下图所示,将多模态数据分别处理和表示,对各个模态数据的表示进行约束,使相同对象的多模态数据表示服从某种相似性。
2. 模态间映射:主要研究如何将某一特定模态数据中的信息映射至另一模态。
应用场景:“看图作文”;“以题作画”;语音合成;机器翻译;跨模态检索等。
算法示例:
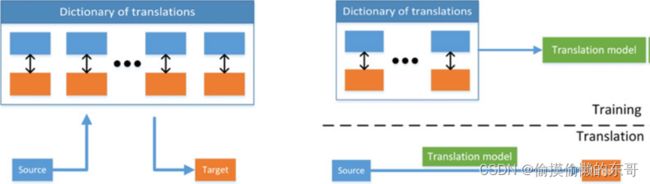
(a) 模版法:模版法的特征是借助于词典进行翻译,词典一般指训练集中的数据对{(x1,y1),…,(xN,yN)}。给定测试样本,模版法直接检索在词典中找到最匹配的翻译结果,并将其作为最终输出。检索可分为单模态检索或跨模态检索:
单模态检索首先找到与x最相似的xi,然后获得xi对应的yi。
多模态检索直接在{y1,…,yN}集合中检索到与x最相似的yi,性能通常优于单模态检索。为进一步增强检索结果的准确性,可选择top-K的检索结果{yi1,…,yik},再融合K个结果作为最终输出。
(b)生成式模型:抛弃词典,直接生成目标模态的数据。分为三个子类别:
基于语法模版:人为设定多个针对目标模态的语法模版,将模型的预测结果插入模版中作为翻译结果。以图像描述为例,模版定义为who did what to whom in place,其中有四个待替换的插槽。通过不同类型的目标/属性/场景检测器可以获得who, what, whom, place等具体单词,进而完成翻译。
编码-解码器:首先将源模态的数据编码为隐特征,后续被解码器用于生成目标模态。以图像描述为例,编码器(一般为CNN+spatial pooling)将图像编码为一个或多个特征向量,进而输入到RNN中以自回归的方式生成单词序列。
连续性生成:它针对源模态与目标模态都为流数据且在时间上严格对齐的任务。以文本合成语音为例,它与图像描述不同,语音数据与文本数据在时间上严格对齐。WaveNet采用了CNN并行预测 + CTC loss解决该类问题。当然,编码-解码器理论上也可完成该任务,但需处理数据对齐问题。
3. 多模态对齐:主要研究如何识别不同模态之间的部件、元素的对应关系。
应用场景:电影画面、口型、语音、字幕的自动对齐;图片的“语义分割”;
算法示例:(a)显示对齐(b)隐式对齐
(a) 显示对齐:*如果一个模型的优化目标是最大化多模态数据的子元素的对齐程度,则称为显示对齐(比如时间维度上的对齐)。分为无监督和有监督方法量个子类别:
无监督对齐(比如weakly-supervised visual grounding):给定两个模态的数据作为输入,希望模型实现子元素的对齐,但是训练数据没有“对齐结果”的标注,模型需要同时学习相似度度量和对齐方式。
有监督对齐(比如Visual grounding):有监督对齐存在标注,可训练模型学习相似度度量。
(b) 隐式对齐:如果模型的最终优化目标不是对齐任务,对齐过程仅仅是某个中间(或隐式)步骤,则称为隐式对齐(比如语言的翻译就是隐式对齐)。
早期基于概率图模型(如HMM)的方法被应用于文本翻译和音素识别中,通过对齐源语言和目的语言的单词或声音信号与音素。但是他们都需要手动构建模态间的映射。
目前最受欢迎的方式是基于注意力机制的对齐,我们对两种模态的子元素间求取注意力权重矩阵,可视为隐式地衡量跨模态子元素间的关联程度。在图像描述,这种注意力被用来判断生成某个单词时需要关注图像中的哪些区域。在视觉问答中,注意力权重被用来定位问题所指的图像区域。很多基于深度学习的跨模态任务都可以找到跨模态注意力的影子。
4. 多模态融合:主要研究如何整合不同模态间的模型与特征。
应用场景:获得更全面的特征;提高模型鲁棒性;保证模型在某些模态缺失时仍能有效工作。
算法示例:(a)非模型的融合策略(b)基于模型的融合策略
- **非模型的融合策略:**传统的融合算法。分为数据融合、决策融合、混合融合三类:
前融合:指在模型的浅层(或输入层)将多个模态的特征拼接起来。
后融合:独立训练多个模型,在预测层(最后一层)进行融合。
混合融合:同时结合前融合和后融合,以及在模型中间层进行特征交互。
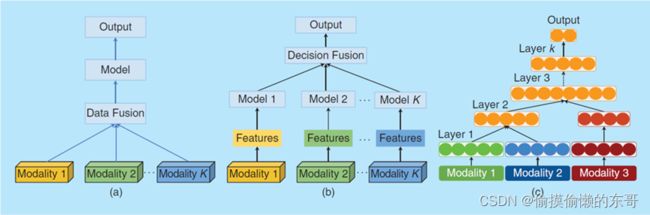
(b)**基于模型的融合策略:**模型的融合算法。分为多核学习、基于概率图模型、基于神经网络模型三类:
多核学习:通常是SVM的扩展。SVM通过核函数将输入特征映射到高维空间,使线性不可分问题在高维空间可分。在处理多个输入时,多核处理多个模态特征,使得每个模态都找到其最佳核函数;
**基于概率图模型:**通常利用隐马尔可夫模型或贝叶斯网络建模数据的联合概率分布(生成式)或条件概率(判别式)。
基于神经网络模型:通常使用LSTM、卷积层、注意力层、门机制、双线性融合等设计序列数据或图像数据的复杂交互。
- 多模态协同学习:主要研究如何将信息富集的模态上学习的知识迁移到信息匮乏的模态,使各个模态的学习互相辅助。
应用场景:多模态的零样本学习;领域自适应等。
算法示例:(a)并行数据协同(b)非并行数据协同(c)混合数据协同
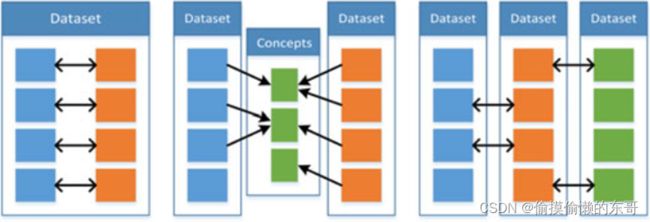
并行方法需要一种模态与另一种模态的每个观测都一对一联系,比如视听语言识别中视觉和听觉信息都来源于一个演讲者。反之,非并行方法不需要,它们一般通过类别重叠实现学习。混合方法中多模态通过共享的模态或者数据集连接。
注意力机制:对输入权重分配的关注,是NLP当中非常重要的概念,它的启发来源于人脑会根据忽略掉不重要的信息,同时吸收到有用的信息。堆叠注意力网络SAN通过多层注意力模型多次对一个图像进行查询,以模拟多阶段推理。通过对动态存储网络进行扩充,使用各自的输入模块对问题和图像编码,并且使用基于注意力的门控单元迭代记忆和检索所需信息。近年来,以共注意力机制(Co-attention)为代表的,在图像和文本间形成对称结构的注意力机制变得更为流行,常见的方法包括平行共注意力方法(Parallel Co-attention)、交替共注意力方法等(Alternating Co-attention)。
双线性汇总:也是近年来流行的多模态信息融合方法。双线性汇总计算待融合的目标向量的外积,从而对向量间任何元素的组合都分别进行权衡并引入更多的模型参数,以实现更强大的信息融合。双线性汇总面临通过向量外积引入的众多参数造成过拟合等问题,需要使用因式分解。
- 多模态领域的研究现状总结
| 应用场合 | 表示 | 映射 | 对齐 | 融合 | 协同学习 |
|---|---|---|---|---|---|
| 语音识别 | |||||
| 视听语音识别 | √ | √ | √ | √ | |
| 事件监测 | |||||
| 动作分类 | √ | √ | √ | ||
| 多媒体事件监测 | √ | √ | √ | ||
| 情感 情绪 | |||||
| 情感 情绪识别 | √ | √ | √ | √ | |
| 情感 情绪合成 | √ | √ | |||
| 媒体描述 | |||||
| 图像描述 | √ | √ | √ | √ | |
| 视频描述 | √ | √ | √ | √ | √ |
| 视觉问答 | √ | √ | √ | √ | |
| 媒体总结 | √ | √ | √ | ||
| 多媒体检索 | |||||
| 跨模态检索 | √ | √ | √ | √ | |
| 跨模态哈希 | √ | √ | |||
| 多媒体生成 | |||||
| (视觉)语音和声音合成 | √ | √ | |||
| 图像和场景生成 | √ | √ |
参考:
[1]多模态机器学习-几种任务入门介绍https://zhuanlan.zhihu.com/p/353681958
[2]Multimodal Fusion(多模态融合技术)https://blog.csdn.net/qq_39388410/article/details/105145074
[3]多模态学习方法综述https://zhuanlan.zhihu.com/p/142455144
[4]多模态学习,带来AI全新应用场景?https://zhuanlan.zhihu.com/p/157610240
[5]多模态学习综述及最新方向https://zhuanlan.zhihu.com/p/389287751
[6]多模态学习https://blog.csdn.net/zhuoqingjoking97298/article/details/122700949