r语言聚类分析_R语言机器学习 | 10 聚类分析
“物以类聚,人以群分”, 聚类分析(clustering analysis)顾名思义就是根据样本的一些特征对其进行类别的划分。首先,要注意“聚类分析”和“判别分析(discriminant analysis)”的差异,在判别分析中讲到,“分类”是指在有特征(X)有标签(Y)的情况下对样本进行分类;而聚类分析是在只有一系列特征(X1,X2...Xn),没有标签Y的情况下的对样本进行聚类。因此,在机器学习语境下, 聚类属于典型的“无监督学习”,相比之下, 分类(判别)就是“有监督学习”。如何对只有特征而没有标签的一系列样本进行聚类?在心理统计学中通常会介绍“距离”和“相似性”两种聚类的方法。前者我们在距离判别法的介绍中也有所提及,简而言之, 两个点距离越远则相似性越低,越不可能是同一类,而距离越近则相似性越高,越可能是同一类。常见的距离包括欧氏距离、马氏距离等,在距离判别法一讲中都有介绍。相似性则与距离相反,使用的是相关系数、夹角余弦等指标进行度量,相关系数越高,越可能是同一类。 下面介绍两类常见的聚类分析方法:层次聚类和K-means聚类(也叫快速聚类)。
1 层次聚类(hierarchical clustering)
这一种聚类的思想是 利用距离或相似性自行聚类。比如说,先把每个样本看做单独一类,然后每次都把最相似的样本聚在一起,直到最终只剩一个类别(也叫 聚集法,如下图,从下往上看);或者先把所有样本看成一个类别,然后把最不相似的样本分出去,直到每个样本都为一类(也叫 分解法,如下图,从上往下看)。
#数据集cluster.csvPlace V1 V2 V3 V4上海 0.7258 0.9413 1 0.5广东 0.3272 0.7575 1 1北京 0.5346 0.9848 1 0.5辽宁 0.3593 0.9078 1 0.6256天津 0.3246 0.9733 1 0.5山东 0.3297 0.4749 1 0.9375河南 0.2301 0.4621 1 1河北 0.3766 0.5943 1 0.697浙江 0.5025 0.2374 1 0.8882山西 0.3261 0.7396 0.948 0.6125吉林 0.3446 0.7755 0.828 0.5江苏 0.4091 0.4986 1 0.5045黑龙江 0.2892 0.7835 0.808 0.5海南 0.1452 0.6447 0.9475 0.5606福建 0.1406 0.3524 1 0.7102湖北 0.1359 0.4767 0.779 0.8106广西 0.0939 0.6498 0.4435 1陕西 0.165 0.4738 0.827 0.7197安徽 0.1104 0.0802 1 0.9545内蒙古 0.2243 0.5761 0.5995 0.6553宁夏 0.2708 0.3127 0.5425 0.9053新疆 0.3615 0.5624 0 0.8887湖南 0.0618 0.5687 0.4385 0.5甘肃 0.0324 0.1027 0.7605 0.6326江西 0.0549 0.3042 0.352 0.6155四川 0.048 0.2376 0.3855 0.5青海 0.0751 0.0118 0 0.8258云南 0.0731 0.0515 0 0.7775贵州 0.0286 0.06 0.059 0.5西藏 0.0901 0 0 0.3712library(rio);library(tidyverse);library(ape)DM=import('cluster.csv')hc = DM[,-1] %>% scale() %>% dist() %>% hclust(method = 'ward.D2') #这里hclust()中,dist(x)结合ward.D2等价于dist(x)^2结合ward.Dplot(hc,labels = DM[,1],cex=0.8) #画树状图plot(as.phylo(hc), type = 'fan') #画变体的树状图,如“phylogram”, “cladogram”, “fan”, “unrooted”, “radial”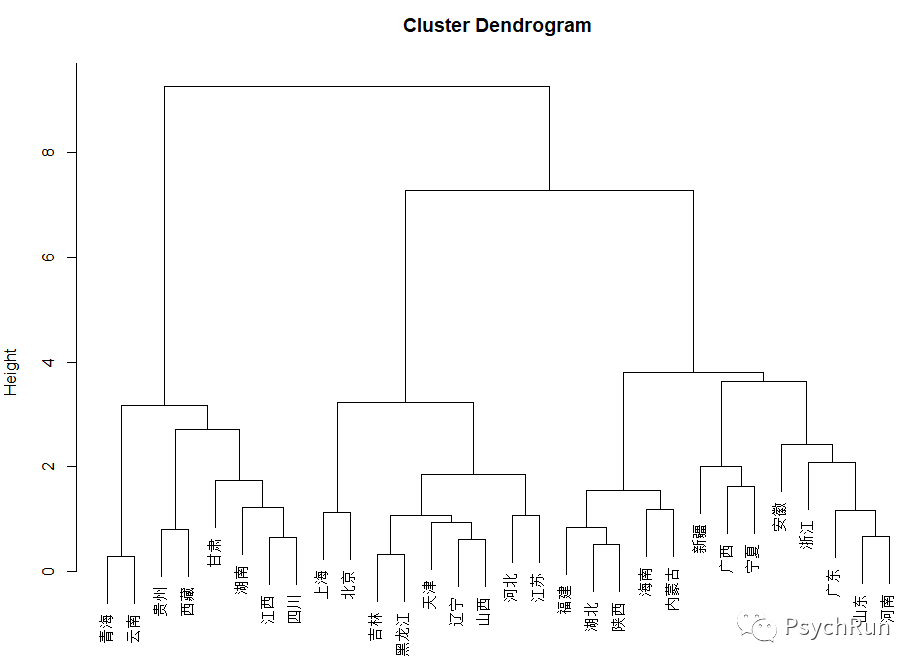
层次聚类的树状图

变体的树状图
之后,我们如果要自己规定划分为几类,可以使用identify()进行手动划分,然后输出列表:plot(hc,labels = DM[,1],cex=0.8) #画树状图id = identify(hc) #运行之后,可以在图上点击,手动分类 如分成三类,然后按Ese退出for (i in 1:length(id)) { print (DM[id[[i]],1]) #这样就得出了三类的列表}

2 K-means 聚类
也叫快速聚类、迭代聚类,适用于组别不是非常多的情况。其步骤为:首先确定类别数K,然后取K个“种子”点(下图为K=3),然后看每个样本离哪个种子最近就归到哪一类,归类之后,原来的种子点就被新类的中心代替。之后重复上述的归类步骤,直到每个样本所属的类别不再变动为止。最终的种子就是最终聚类的中心点。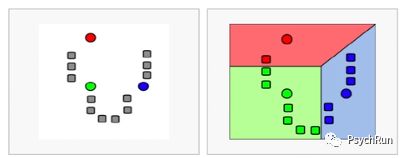
左图:三个圆点为三个种子点;右图:根据距离进行归类

根据归类后的中心点重新聚类
可见,如何选择K是非常重要的(尤其是当高维数据看不出来特点时),而NbClust包可以给出推荐的K值:library(NbClust)#这里使用了欧氏距离,k范围是2-8,方法是complete;其他参数也可以尝试choose_k = NbClust(scale(DM[,-1]),distance = 'euclidean',min.nc = 2,max.nc = 8,method = 'complete',index = 'all')# 有各种指标,然后conclusion是最终推荐的个数,这里的结果是4KM=kmeans(DM[,2:3],4) #分成4类,这里为了可视化方便这里只用两个自变量(多个也可行的)KM$clusterKM$centers #中心点ggplot(DM,aes(x=DM[,2],y=DM[,3],col=as.factor(KM$cluster)))+geom_point() #画图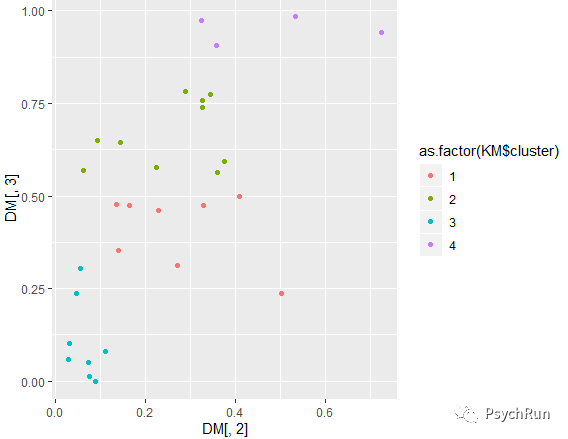
注:部分代码参考自B站R语言手把手聚类分析一节。