同r做一个窗口_目标检测(Object Detection):R-CNN/SPPnet/R-FCN/Yolo/SSD
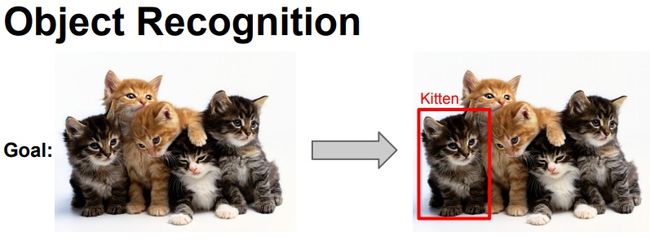
这篇文章我是Survey目标检测(Object Detection)系列论文的一个总结。
包括R-CNN系列、SPP-net、R-FCN、YOLO系列、SSD、DenseBox等。
基本概念
- 目标识别:对给定图像做分类,比如输入一张动物的图片,让算法判断是某种动物或者含有多种动物。
- 目标检测:目标检测通常包括判断物体的位置和大小(Bounding box)、及判断物体的类别。
- Bounding Box:输出边界,以(x, y, 宽,高) 的形式呈现,其中x、y为Bounding Box的左上角坐标。
- IOU:对于两个矩形的Bounding box A和B,IOU = (A∩B)/(AUB),也就是A和B重叠的面积,除以A和B并集的面积。
- ROI:Region of Interest,目标区域,通常指待处理的图像子区域。
目标检测的难点
目标检测最大的难点在于无法提前判断输入图片中有多少目标(Objects),以及每个目标的 Bounding Box。一个粗暴的办法是在图像上选择不同的ROI,针对每个ROI用CNN网络来分类。但是,取多少个ROI,取多大?这是一个有巨大搜索空间的问题。如果暴力解决,将会消耗巨大算例,从时间复杂度上来讲是不现实的。
这个搜索空间到底是多少?
对于一个 m * n 像素的图像,有 m(m+1)n(n+1)/4 种可能,例如一个500 * 500像素的图像。Bounding box可能性的值将是15,687,562,500,不用数了,超过156亿。
此外,一个标准的全连接CNN网络没法直接应用到目标检测。原因是输出层的大小是不固定的,因为不同的图像可能含有不同数量的目标。
为了解决上述问题,在传统目标检测算法的基础上,近些年出现了众多的目标检测新算法,例如R-CNN系列、YOLO系列。下面具体介绍。
常见检测算法分类
- 传统的目标检测算法
- 候选区域生成+深度学习分类算法:
- 通过提取候选区域,并将每个区域交由以CNN为主的深度学习分类方案
- 如R-CNN / Fast-RCNN / Faster-RCNN / SPP-net / R-FCN 等系列方法;
- 深度学习的回归算法:
- YOLO / SSD / DenseBox 等方法;以及最近出现的结合RNN算法的RRC detection;结合DPM的Deformable CNN等
本文重点介绍类别2和3中的方法。上述分类参考文献[1]。
基于候选区域生成+深度学习分类的方法
这类方法的一个前提是需要算法先计算出候选区域(Bounding Boxes),之后是把候选区域交给由深度学习为主的分类模型做分类。
候选区域生成算法
对于候选区域生成,传统的方法包括滑动窗口,但是由于效率问题用的已经不多,目前常见的有Region Proposal系列的方法。
滑动窗口
在待识别的图像上设定一个窗口,将窗口内的图像交给算法识别;在图像上以设定的步长滑动此窗口,并将窗口内图像给算法识别;重复上述过程,直到将所有图像的区域检测完。之后,缩放窗口(改变窗口的大小)并重复上述步骤。
- Andrew Ng曾在Machine Learning课程中介绍过此技术,请看这里。
- 从滑动窗口的定义上可以看出,它的计算代价取决于图像大小、设定的滑动步长和窗口缩放的次数。因此,滑动窗口是一个计算密集型(Computing-intensive)的算法。
Region Proposal
Region Proposal对输入图像生成候选区域,通常比传统的滑动窗口方法获取的质量要更高。常用的方法包括下面几种。
(1)Selective Search [11]
核心思想:使用自底向上的聚类方法,把图像子区域合并为更大区域(同时维护层级结构)。
第1步:使用Felzenszwalb的方法[12]对输入图像做分割,分割为许多小区域,每个区域属于一个物体。
一个完整的Felzenszwalb方法的Demo请见这个GitHub Repository。

第2步:递归合并相似的区域为更大的区域。
使用贪心算法:
- 对于一个图像区域集合,选择最相似的两个区域
- 合并上述两个区域为一个更大的区域
- 重复上述过程,知道仅剩一个区域

第3步:使用上一步生成的区域生成候选物体的位置(Bounding box)

关于如何计算相似度等问题这里不介绍,请见文件[11]。
(2)Edge Boxes [14]
不需要学习参数,结合滑窗,通过计算窗口内边缘个数进行打分,最后排序。
主要思想:一个Bounding box里轮廓的数量体现了这个Bounding box含有一个物体的可能性。

第1步:计算Edges(如上图第二行)
- 采用论文Structured Forests for Fast Edge Detection [15]中的方法。
第2步:计算Edge groups(如上图第三行)
第3步:计算Edge groups之间的相似度
第4步:计算Edge groups的权值(取值0或1,表示是否完全被包含在Box中)
第5步:给Boxes打分(如上图第四行),基于被Box完整包含的轮廓(里的Edges)。
第6步:根据Boxes的分数,排序,选出Top N的Boxes作为候选区域。
Edge Boxes方法属于“Window scoring methods”,此类别中表现不错的算法还有Objectness、Bing等。这里不做介绍。
下面看一看历年来常见的Object Detection方案。
R-CNN (CVPR 2014)
R-CNN[16] 最核心的思想是,应用Selective Search方法从图像中提取2000张候选区域(Region proposals)。
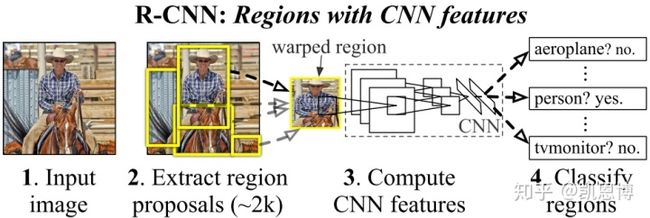
R-CNN有如下步骤(如上图):
- 候选区域生成: 对输入的图像,采用Selective Search 方法生成约2K个候选区域
- 特征提取: 对每个候选区域,使用深度卷积网络(CNN)提取特征,特征向量为4096个维度
- 类别判断: 特征送入每一类的SVM 分类器,判别是否属于该类
- 位置精修: 根据区域的位置和分类信息,使用回归器(Bounding-box regression)修正候选框位置

R-CNN的不足:
- 每张图有2000个候选区域需要分类,窗口之间重复的部分导致了重复的卷积计算
- Selective Search非常耗时,导致每张图的预测时间需要47秒,没法应用到有实时预测的需求场景
- 选择搜索算法是一个固定算法,没有学习过程,可能会生成很差的候选区域
Fast R-CNN (ICCV 2015)
R-CNN的作者接着解决了部分R-CNN中的问题,极大的提升了识别速度,这个新的目标检测方法叫做Fast R-CNN [18]。

Fast R-CNN有如下步骤(如上图):
- 候选区域生成: 对输入的图像,采用Selective Search 方法生成候选区域
- 生成一个卷积特征映射(Feature map):输入为整幅图像
- 对于每个候选区域,利用ROI Pooling从feature map中提取一个定长的feature vector
- 一方面Feature vector被Softmax分类器用来预测类别
- 另一方面Feature vector被用来预测修正的Bounding box位置
Fast R-CNN比R-CNN更快的一个原因是不必每次都向卷积神经网络提供2000个候选区域。相反,每个图像只进行一次卷积运算,并从中生成特征映射。
从下图中的数据可以看出,Fast R-CNN相对R-CNN有明显的速度提升。在右侧的“测试时间”里可以看出,Fast R-CNN的大部分时间都用在了候选区域生成这一环节。因此,这一步也成了Fast R-CNN的性能瓶颈。
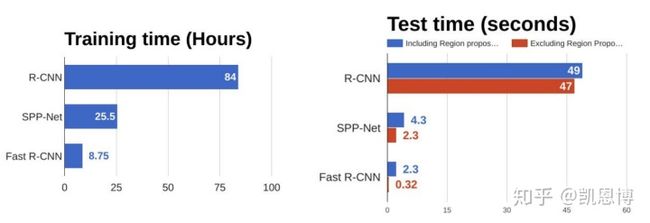
引用一段文献[1]的评论:
Fast-RCNN中,作者巧妙的把Bounding box regression放进了神经网络内部,与region分类和并成为了一个multi-task模型,实际实验也证明,这两个任务能够共享卷积特征,并相互促进。Fast-RCNN很重要的一个贡献是成功的让人们看到了Region Proposal+CNN这一框架实时检测的希望,原来多类检测真的可以在保证准确率的同时提升处理速度,也为后来的Faster-RCNN做下了铺垫。
关于ROI Pooling和Bounding Box Regression的具体讲解,请见参考文献[17]
Faster R-CNN (NIPS 2015)
Fast-RCNN的问题非常明显,基于Selective Search的Region proposal方法相对非常耗时。于是作者提出了Faster-RCNN [20],使用RPN代替Selective Search,而且这是一个端到端的CNN目标检测模型。
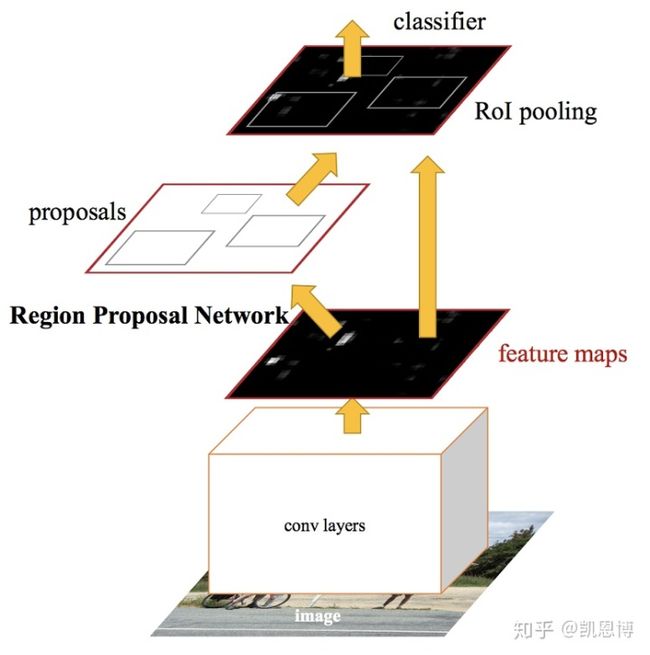
和Fast R-CNN类似,在Faster R-CNN中:
- 生成一个卷积特征映射(Feature map):输入为整幅图像
- 使用一个Region Proposal Network (RPN)生成候选区域
- 对于每个候选区域,利用ROI Pooling从feature map中提取一个定长的feature vector
- 一方面Feature vector被Softmax分类器用来预测类别
- 另一方面Feature vector被用来预测修正的Bounding box位置
这篇文章最大的贡献是发现网络中的各卷积层特征可以用来预测类别相关的Region proposal,不再需要Selective search。因此可以把Region proposal提取和分类、Bounding Box Regression融合进了一个网络模型。相对Fast R-CNN,其检测速率大幅提升(见下图),准确率也与原来的Fast-RCNN接近。
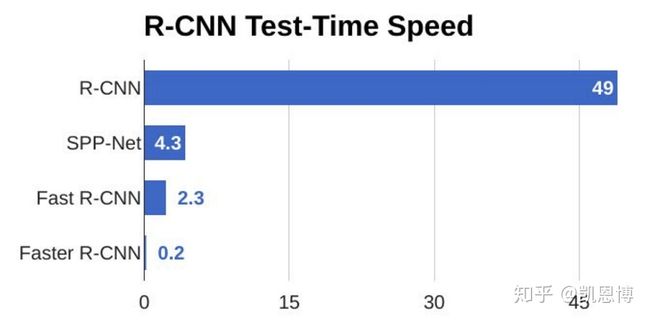
虽然如此,Faster R-CNN最快也仅能达到5 FPS的检测速率,用在高实时要求的场景是很牵强的。
关于RPN和Faster R-CNN训练的具体讲解,请见参考文献[17]
R-CNN/Fast R-CNN/Faster R-CNN对比总结
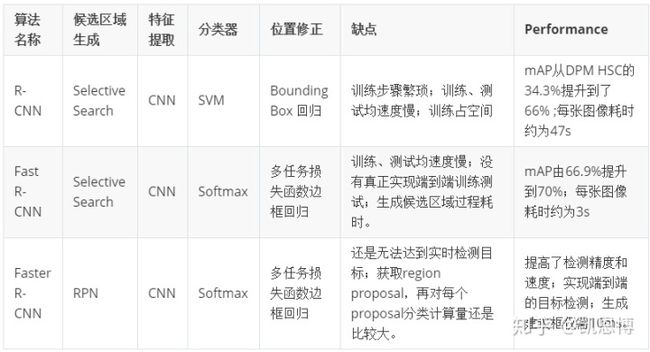
整理上述三节,总结R-CNN、Fast R-CNN、Faster R-CNN的架构和优劣如下[4]:

SPP-net (ECCV 2014)
SPP-net [19] 是针对R-CNN做的优化。此前的模型要求输入固定尺寸的图片。那么在做目标检测时,需要将候选区域做crop或者warp(如R-CNN用到warp)。上述操作会导致图片的变形和信息的丢失,限制识别精度。下图展示了此前的目标检测和SPP-net的架构区别。

SPP-net通过在卷积特征层上的空间金字塔池化以避免对图片必须固定大小这条限制。SPP-net生成一个固定长度的特征。下面是金字塔池化的原理图:

黑色图片代表卷积之后的特征图,接着我们以不同大小的块来提取特征,分别是4 * 4,2 * 2,1 * 1,将这三张网格放到下面这张特征图上,就可以得到16+4+1=21种不同的块(Spatial bins),从这21个块中,每个块提取出一个特征,这样刚好就是我们要提取的21维特征向量。这种以不同的大小格子的组合方式来池化的过程就是空间金字塔池化(SPP)。比如,要进行空间金字塔最大池化,其实就是从这21个图片块中,分别计算每个块的最大值,从而得到一个输出单元,最终得到一个21维特征的输出。[21]
R-FCN (NIPS 2016)
R-FCN[22] 是一篇对标Faster R-CNN的目标检测论文。其主要贡献在于解决了“分类网络的位置不敏感性(translation-invariance in image classification)”与“检测网络的位置敏感性(translation-variance in object detection)”之间的矛盾,在提升精度的同时利用“位置敏感得分图(position-sensitive score maps)”提升了检测速度。[23]
基于深度学习的回归方法
[今天先Survey这么多,以下三部分待更新]
YOLO
SSD
DenseBox
不同AI框架的Object Detection
TensorFlow
TensorFlow提供TensorFlow Object Detection API用于目标检测。
- 支持的Detector包括Faster R-CNN、SSD、PPN、RetinaNet等
- 其中Feature extractor包括MobileNet V2 、ResNet 101 FPN、ResNet V2
- 支持GPU和TPU
- 支持在Mobile Devices(e.g., Android,with TensorFlow Lite)
此Repository提供了Quick Start Demos和Guidances,建议访问Repo里看详细的说明。
PyTorch
PyTorch中似乎没有(也可能是我没发现)集成的Object Detection API,但是有众多GitHub Repo实现了流行的的算法:
- Faster R-CNN:https://github.com/ruotianluo/pytorch-faster-rcnn
- RetinaNet:https://github.com/kuangliu/pytorch-retinanet
- Yolo V3:https://github.com/ayooshkathuria/pytorch-yolo-v3
- SSD:https://github.com/amdegroot/ssd.pytorch
参考文献
- 视觉目标检测和识别之过去,现在及可能
- Selective Search for Object Detection
- RCNN- 将CNN引入目标检测的开山之作
- Faster R-CNN论文笔记
- R-CNN, Fast R-CNN, Faster R-CNN, YOLO — Object Detection Algorithms
- YOLO: Real-Time Object Detection - Yolo Official Site
- Real-time Object Detection with YOLO, YOLOv2 and now YOLOv3
- 一文读懂目标检测:R-CNN、Fast R-CNN、Faster R-CNN、YOLO、SSD
- Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition:SPP-net/何凯明/TPAMI 2015
- R-FCN: Object Detection via Region-based Fully Convolutional Networks:R-FCN/代季峰.何凯明/NIPS 2016
- Uijlings, Jasper RR, et al. "Selective search for object recognition." International journal of computer vision 104.2 (2013): 154-171. (Slides)
- Felzenszwalb, Pedro F., and Daniel P. Huttenlocher. "Efficient graph-based image segmentation." International journal of computer vision 59.2 (2004): 167-181.
- Object Detection for Dummies Part 1: Gradient Vector, HOG, and SS
- Zitnick, C. Lawrence, and Piotr Dollár. "Edge boxes: Locating object proposals from edges." European conference on computer vision. Springer, Cham, 2014.
- Dollár, Piotr, and C. Lawrence Zitnick. "Structured forests for fast edge detection." ICCV. 2013.
- Girshick, Ross, et al. "Rich feature hierarchies for accurate object detection and semantic segmentation." CVPR. 2014.
- RCNN, Fast-RCNN, Faster-RCNN的一些事
- Girshick, Ross. "Fast r-cnn." ICCV. 2015.
- He, Kaiming, et al. "Spatial pyramid pooling in deep convolutional networks for visual recognition." IEEE transactions on pattern analysis and machine intelligence 37.9 (2015): 1904-1916.
- Ren, Shaoqing, et al. "Faster r-cnn: Towards real-time object detection with region proposal networks." NIPS. 2015.
- SPP-Net论文详解
- Dai, Jifeng, et al. "R-fcn: Object detection via region-based fully convolutional networks." NIPS. 2016.
- 详解R-FCN