Pairwise Body-Part Attention for Recognizing HOI(面向HOI识别的成对身体部位注意力机制)
ECCV2018 Author:Hao-Shu Fang,Cewu
Lu
摘要
在HOI识别中,卷积方法把人的身体看作是一个整体并对整个身体区域给一个统一的注意力机制。他们忽略了人和物体交互时其实是用身体的一部分进行实现的。在本文中,我们认为在HOI中不同的身体部位应该被赋予不同的注意力,而且在不同身体部位中的相关关系应该要进一步考虑。这是因为我们身体部位总是协同运作的。我们提出了一个新的可以学习集中于重要部件和相关关系的成对身体部位注意力模型。我们在模型中引入了一种新的基于注意力的特征选择方法和一种能够捕获身体部位间成对关联的特征表示方案。提升很大达到了SOTA(mAP:36.1->39.9),开源。
1.介绍
据我们所知,我们的工作是第一次尝试将注意力机制应用于人体部位关联,以识别人类与物体的交互。SOTA!
2.相关工作
我们的工作涉及到计算机视觉的两个活跃领域:人物交互和视觉注意力。
人物交互:人-物交互(HOI)识别是人类行为识别的子任务,也是理解人类实际行为的关键任务。它可以解决两个人姿态几乎相同时动作识别中的歧义问题,并在识别标签中提供更高层次的语义意义。早期的动作识别研究考虑了视频输入。代表性著作包括。在静态图像的动作识别中,以往的研究试图利用人体姿态识别人类动作。(不想写了呜呜呜~,这段还是自己看原文吧)
注意力模型:人类的感知集中在视野的某些部分来获取细节信息,而忽略那些不相关的信息。这种注意机制在计算机视觉学界已经研究了很长时间。早期受人类感知驱动的研究是显著性检测。最近,有一些研究试图将注意机制纳入深度学习框架。这种尝试在许多视觉任务中被证明是非常有效的,包括分类,检测,图像字幕和图像问答。Sharma等人首先将注意力模型应用到动作识别领域,利用LSTM对视频帧的重要部分进行聚焦。我们的工作与几个最近的工作相关。
3.我们的方法
我们的方法利用全局和局部信息推断HOI标签。
全局语境信息已经被许多前人的著作所研究。在3.1节中,我们回顾了先前利用人物和场景特征的深度学习模型1。在1模型的基础上,进一步融合对象特征。这形成了一个强大的基础网络,有效地获取全局信息。但请注意我们改进后的基本网络已经取得了比1提供的模型更好的性能。
在第3.2节中,我们描述了我们的主要算法,将成对的身体部位关联纳入深度神经网络。具体地说,我们提出了一种简单而有效的池化方法,即ROI -成对池化,该方法对每个身体部位的局部特征和它们之间的成对相关性进行编码。我们开发了一个注意力模型来聚焦于有区别的成对特征。最后,我们在3.3节中提出了全局特征和局部成对相关特征的组合。图2显示了我们的网络体系结构的概述。

3.1全局外观特征
场景和人体特征:为了利用人的整体特征和场景特征进行HOI识别,1提出了一种有效的模型,并将其用于构建我们的基础网络。如图2所示,给定一张输入图片,我们把它resize并通过一个VGG卷积层直到Conv5层。在这些共享的特征图里,ROI池化层为每个人和场景给定的bbox提取ROI特征。对于每个被检测到的人,他/她的特征与场景特征连接,并通过FC层,以估计每个HOI在预定义列表上的得分。在HICO数据集,同一图像中可以有多个人。只要观察到相应的HOI,每个HOI标签都标记为正。为了解决多人的问题,我们采用多实例学习(MIL)框架。 MIL层的输入是对图像中每个人的预测,其输出是一个得分数组,该数组取所有输入预测中每个HOI的最大得分。
合并物体特征:为了在上下文中对HOI有一个连贯的理解,我们进一步改进了基线方法,加入了在1中被忽略的目标特征。
特征表示:给定一个物体bbox,一个简单的方法是提取相应的特征图,然后将其与人和场景的现有特征拼接起来。然而,这种方法对HOI的识别任务并没有很大的改善。这是因为物体和人之间的相对位置没有编码。因此,我们设置ROI是被探测对象与被探测对象的联合box。我们的实验(4.2节)表明这种表示是有效的。
处理多目标:在HICO数据集中,一个图像中可以有多个人和多个物体。对于每个人来说,多个物体可以同时出现在他/她的周围。为了解决这一问题,我们对不同物体和人的多个联合框进行采样,并对每个联合框分别应用ROI池化。在我们的实现中,一个人周围的采样物体总数是固定的。实施细节将在第4节中解释。
提取的目标特征和人、场景特征拼接。这为捕获良好的全局外观特征建立了一个强大的基础网络。
3.2局部pairwise身体部位特征
在本小节中,我们将描述如何使用我们的pairwise身体部位注意模块来获得成对身体部位特征。
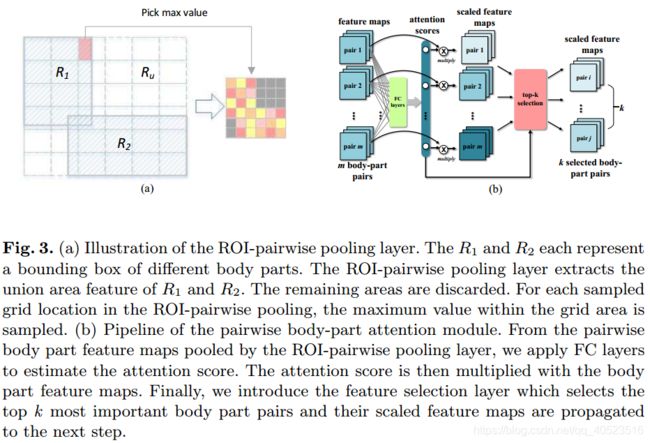
ROI-成对池化:给定一对身体部位,我们在保留他们的相关空间关系的同时提取他们的关节特征图。我们用R1(r1, c1, h1, w1), R2(r2, c2, h2, w2)表示ROI对,用Ru(ru, cu, hu, wu)表示它们的union box,其中(r, c)表示ROI的左上角,(h, w)表示高度和宽度。一种直观的想法是将ROI设置为身体-部件对的联合框,利用ROIpooling层提取特征。但是当两个身体部位距离较远时,如手腕和脚踝,它们的union box会覆盖一大片不相关的身体部位。这些不相关的特征会在训练过程中混淆模型。为了避免这种情况,我们将(两个)身体部位box外的激活值设为零,以消除那些不相关的特征。然后,为了保证Ru表示的大小一致,我们将unionbox Ru的特征图转换为固定大小的H × W特征。它以统一的最大池方式工作:我们首先将hu × wu分成H × W网格,然后,对于每个网格,该网格单元内的最大值被pool到相应的输出单元。图3(a)说明了我们的ROI-成对池的操作。
利用ROI-成对池化层,对两个身体部位的关节特征及其相对位置进行编码。注意身体-部位成对的数量通常很大(n个部位为C(n, 2)),许多成对的身体部位很少相关。我们提出一个注意力模块来自动发现这些不相关的关联。
注意力模块:图3 (b)说明了我们的注意力模块的pipeline。我们的注意力模块把所有可能的经过ROI成对池化厚度pairwise身体部位对P={p1,p2……pm}的特诊图作为输入,其中m = C(n, 2)是身体-部位对的个数。对于每一个成对的身体部分pi,FC层将回归一个注意力得分si。分数S = {s1, s2,…, sm}表示每对身体部位的重要性。
特征选择:如前所述,只有部分身体部位对与HOI相关,不相关的部分会导致神经网络的过拟合。假设我们需要选择k个身体部位对的特征,我们的选择层将保留评分最高k的身体部位对的特征图,去掉剩余的特征图。选择的集合可以表述为:
![]()
注意力分配:不同的特征图具有相同的价值比例范围,但它们对HOI识别的贡献不同。因此,我们应该重新调整特征图,以反映它们的真正影响。数学上,它的模型是乘以相应的注意力得分,可以表示为:
![]()
其中c(j)为Φ中第jth元素的索引,fj为第jth重新缩放的特征图。
讨论:我们只允许k个成对的特征来表示一个交互。S是给一些和输入交互相关的成对身体部位分配更大的值来达到更好的准确率。因此,S使注意力机制无需人的监督。在实验4.4部分,我们验证了学习注意力得分与人类预测一致。
训练:因为式(1)不是一个可微函数,它没有需要更新的参数,在反向传播过程中只传递后一层到前一层的梯度。当只选择最上面的k个成对特征图时,特征选择层选择的特征图的梯度将从后一层复制到前一层。将被丢弃的feature maps的梯度值设置为零。在反向传播过程中自动更新注意力得分,并采用端到端方式训练我们的注意力模块。
结合ROI-成对池化层和注意模块,我们的成对身体-部分注意力模块具有以下特性:
——该算法既考虑了人体各部位的局部特征,又考虑了人体各部位之间的高层空间关系。
——对于不同的HOI,我们的身体-部位成对注意模块将自动发现具有区别性的身体部位和成对关系。
3.3结合全局和局部特征
在获得选定的成对的身体部位特征和全局外观特征后,分别通过最后的FC层进行转发,以估计最终的预测结果。预测将对每个检测到的人使用。
4.实验
4.1设置
HICO:我们使用Faster RCNN检测器来获取人和物体的边界框。对于每个图像,3个human建议框和4个物体建议框将被采样以适应GPU内存。如果人或物体的数量少于预期,我们用零填充剩余的区域。对于人体部位,我们首先使用姿态估计器2来检测所有人体关键点,然后根据关键点定义10个人体部位。我们的方法选取的代表性人体部位如图5 (a)所示,每个部分定义为一个边长与检测到的人体躯干大小成比例的规则边界框。对于身体部位成对,不同身体部位之间成对组合的总数为45 (C(10,2))。
我们首先尝试复制malya & Lazebnik1的结果作为我们的baseline。然而,通过我们的努力,我们只能实现35.6 mAP,他们论文中有36.1mAP。我们使用这个模型作为我们的baseline模型。在训练过程中,我们遵循1的设置,初始学习率为1e-5, 30000次迭代,然后1e-6, 30000次迭代。batchsize设置为10。与1的工作类似,网络被微调到conv3层。我们在单个Nvidia 1080 GPU上使用Caffe框架训练我们的模型。在测试期间,一个图像q前向传播需要0.15秒。
由于HICO数据集中的HOI标签高度不平衡,我们采用加权sigmoid交叉熵损失:
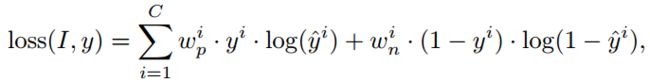
其中,C为独立类的数目,wp和wn为正例和负例的权重因子,ˆy为模型预测,y为图像i的标签,根据1,设置wp = 10, wn = 1。
MPII:
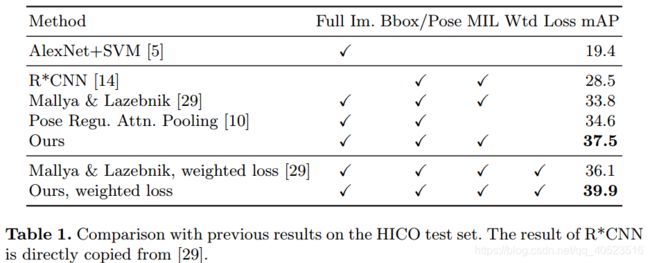
4.2结果


4.4分析
。。。。。。
5.总结
提出了基于身体部位的注意力模块,之前的iCAN也是注意力模块,但是是以人和物的实例为中心,并没有细化到身体部位,还有以姿态估计来提取的,没有加入注意力机制。这篇论文的话就结合了两点,提了3个点,算是很厉害的了。果然就是互相缝合怪!!!
这样的话还是得多看论文,然后吸取别人的创新点,然后开始缝合。重点是怎么缝合才比较牛!!!
[1]Mallya, A., Lazebnik, S.: Learning models for actions and person-object interactions with transfer to question answering. In: ECCV (2016)
[2]Fang, H.S., Xie, S., Tai, Y.W., Lu, C.: RMPE: Regional multi-person pose estimation. In: ICCV (2017)