分布式强化学习总结
DPPO
在ppo基础上的优化
1.在状态中加入了RNN,能够兼顾观察状态的时序性,更加适用与POMDP问题
2.在回报计算中使用了K步奖励法
3.对原来的数据进行归一化
DPPO框架含有一个chief线程,和多个worker线程。多个worker进程可以并行运行
- 全局只有一个共享梯度区和共享PPO模型
- 不同的worker中还有自己的局部PPO模型和局部环境
局部PPO模型的作用:worker使用PPO策略和局部环境进行互动获得数据,并在更新中计算梯度
A3C
我们先看看经典的A3C[1]架构图。
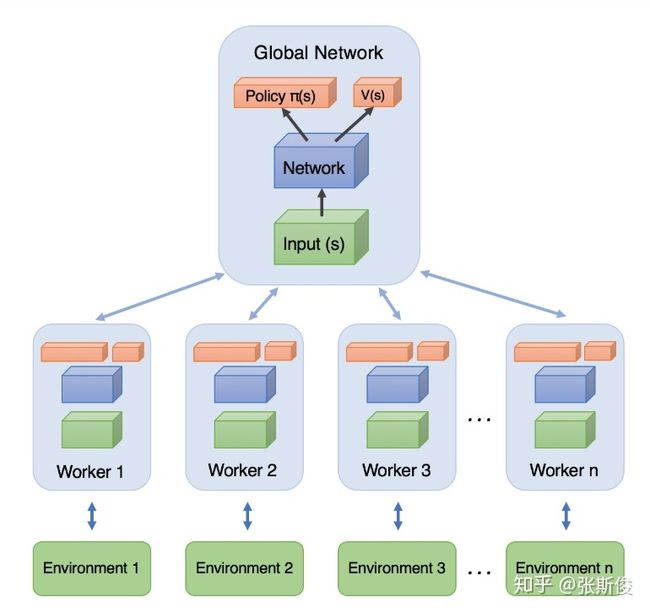
架构图分为两个主要部分:Global Network(全局网络)和 worker(工人)
其实Global network和 worker都是一模一样的AC结构网络。全局网络并不直接参加和环境的互动,工人与环境有直接的互动,并且把学习到的东西,汇报给全局网络。
这有点像一个班长和同学之间的故事。
邪恶的老师给聪明的班长一个任务,让班长一天之内交出一份十万字的莎士比亚全集的读书心得。
这怎么可能?但班长深得班里同学们喜爱。班长决定发动全体同学来完成这个任务。
但怎么分配任务呢?
聪明的班长给每个同学一套莎士比亚全集,然后公布了任务分配的规则:
-
同学们就随便看任何一个你们感兴趣的段落就可以了,就算是重复了也没关系;
-
但同学们需要把读过的提炼成心得,每隔一段时间汇报给班长;
-
班长会负责汇总大家的心得; 但同学提交自己的心得之后,要看一下当前被汇总的最新版本的心得,因为这是集体的智慧,有助于大家提高阅读水平。
-
最后,班长会把最新版本的心得提交给老师。
邪恶的老师看到这篇凝聚了大众智慧的读书心得,感动得流下泪水。而这位聪明的班长在毕业后投身AI事业,发明出A3C算法。
…故事我编不下去了…
相信大家在这个故事中,已经对A3C的思路有个大致的想法。其中有几点需要大家注意的。
在A3C中,worker不仅要和环境互动,产生数据,而且要自己从这些数据里面学习到“心得”。这里的所谓新的,其实就是计算出来的梯度;
需要强调的是,worker向全局网络汇总的是梯度,而不是自己探索出来的数据。
2.GA3C(使用GPU版本的A3C)
- Agent,环境交互接口
- Predictor:状态->动作
- Trainer:训练任务
D4PG
将Actor和Learner分开,经验收集分布式化。
Learner部分是一个完整的DDPG架构,但是它只负责训练学习,不与环境进行互动
IMPALA
最佳的异步强化学习框架(Importance Weighted Actor-Learner Architectural)
痛点:强化学习数据采样效率太低,而且强化学习需要的数据过多(依赖过拟合)
将Agent和Predictor合成一体,由分布式Actor直接执行策略并记录轨迹(数据),然后送给Leaner去训练
Apex-X
将行为和学习分开,可以生成更多的数据并按照优先级进行采样
参考资料:
[1]作者:张斯俊
链接:https://zhuanlan.zhihu.com/p/111336330
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
[2]《深度强化学习学术前沿与应用》